Towards Enhancing Fine-grained Details for Image Matting
Published 22 Jan 2021 in cs.CV | (2101.09095v1)
Abstract: In recent years, deep natural image matting has been rapidly evolved by extracting high-level contextual features into the model. However, most current methods still have difficulties with handling tiny details, like hairs or furs. In this paper, we argue that recovering these microscopic details relies on low-level but high-definition texture features. However, {these features are downsampled in a very early stage in current encoder-decoder-based models, resulting in the loss of microscopic details}. To address this issue, we design a deep image matting model {to enhance fine-grained details. Our model consists of} two parallel paths: a conventional encoder-decoder Semantic Path and an independent downsampling-free Textural Compensate Path (TCP). The TCP is proposed to extract fine-grained details such as lines and edges in the original image size, which greatly enhances the fineness of prediction. Meanwhile, to leverage the benefits of high-level context, we propose a feature fusion unit(FFU) to fuse multi-scale features from the semantic path and inject them into the TCP. In addition, we have observed that poorly annotated trimaps severely affect the performance of the model. Thus we further propose a novel term in loss function and a trimap generation method to improve our model's robustness to the trimaps. The experiments show that our method outperforms previous start-of-the-art methods on the Composition-1k dataset.
The paper introduces a dual-path network that separates semantic and textural details to enhance fine-grained feature preservation.
It employs a novel trimap generation method and a background enhancement loss to robustly handle noisy trimaps.
Experimental results demonstrate state-of-the-art performance with improved SAD, MSE, and connectivity metrics on benchmark datasets.
Enhancing Fine-Grained Details for Image Matting
This paper introduces a novel approach to deep image matting by explicitly separating the task into semantic and textural components. It addresses the challenge of preserving fine-grained details, such as hairs and furs, which are often lost due to the downsampling operations in conventional encoder-decoder architectures. The authors propose a dual-path network comprising a Semantic Path (SP) for high-level contextual information and a Textural Compensate Path (TCP) for fine-grained textural details. They also introduce a trimap generation method and a background enhancement loss to improve the model's robustness to inaccurate trimaps.
Methodology
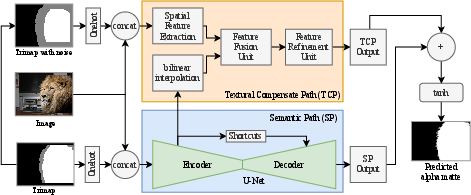
The proposed network architecture consists of two parallel paths: the Semantic Path (SP) and the Textural Compensate Path (TCP) (Figure 1). The network takes a 6-channel input, which is a concatenation of the 3-channel RGB image and the one-hot encoded 3-channel trimap. The final alpha matte is obtained by summing the outputs of the two paths and applying a tanh function.
Figure 1: An overview of the proposed network architecture, highlighting the Semantic Path (SP) and Textural Compensate Path (TCP) which are combined to predict the final alpha matte.
Semantic Path (SP)
The Semantic Path is designed to capture high-level contextual representations using a modified U-Net architecture [ronneberger2015u]. The encoder is based on ResNet-34 [he2016deep], and the decoder mirrors the encoder's structure. Skip connections with two convolution layers in each are used to adapt low-level features to high-level features. The SP can function independently and provides a baseline for comparison.
Textural Compensate Path (TCP)
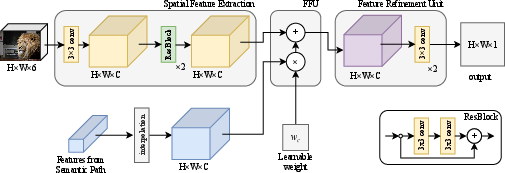
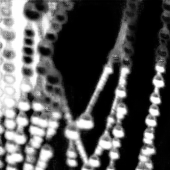
The Textural Compensate Path (TCP) is designed to preserve spatial details often lost in downsampling operations. It operates without downsampling to extract pixel-to-pixel high-definition information (Figure 2). The TCP comprises three main components: a spatial feature extraction unit, a feature fusion unit (FFU), and a feature refinement unit. The spatial feature extraction unit consists of a convolution layer followed by two residual blocks. Intermediate features from the SP are resized and fused with the output of the spatial feature extraction unit using the FFU. The FFU multiplies the features from the semantic path by a learnable weight wc to control its influence. The feature refinement unit then refines the fused features to generate the output of the TCP (Figure 3).
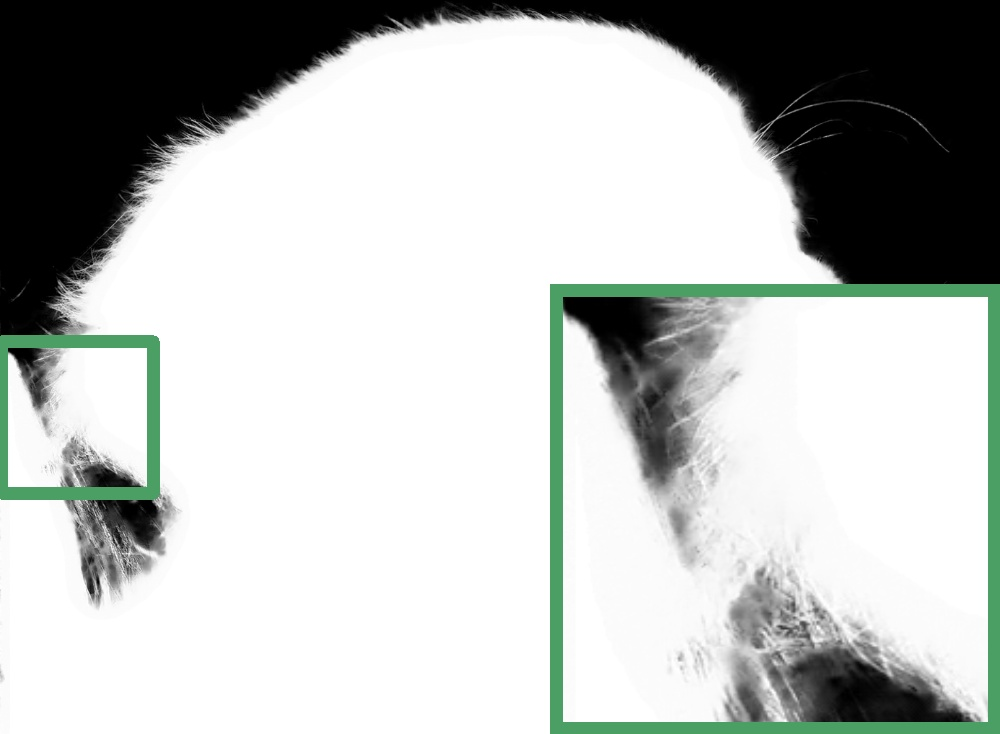
Figure 2: Visualization of detail loss after downsampling and upsampling, demonstrating the importance of preserving fine-grained spatial details for accurate alpha matting.
Figure 3: Detailed architecture of the Textural Compensate Path (TCP), including the Spatial Feature Extraction Unit, Feature Fusion Unit (FFU), and Feature Refinement Unit.
Improving Robustness to Trimaps
The paper addresses the challenge of noisy trimaps by introducing a novel trimap generation method and a background enhancement loss. For trimap generation, the initial trimap is generated based on the ground-truth alpha map, and random morphological operations are applied to the unknown region to simulate noise in user-provided trimaps (Figure 4). The trimap of point p is first decided by its corresponding alpha value αp:
Figure 4: Examples of the trimap generation method, illustrating the original image, alpha matte, and generated trimaps for the semantic and textural compensate paths.
This loss term recognizes the "pure" background inside the unknown region, providing contextual guidance for the network. The full loss function is a weighted sum of the alpha-prediction loss (La) and the background enhancement loss (Lbg): L=w1⋅La+w2⋅Lbg.
Experimental Results
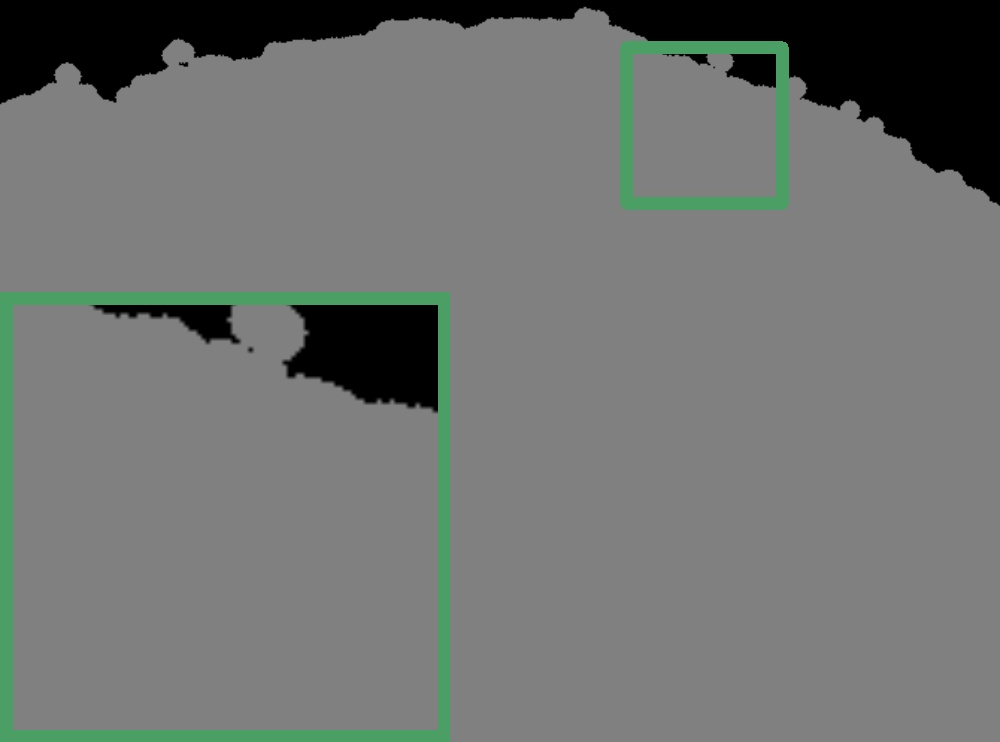
The model was trained on the Adobe Deep Image Matting Dataset and tested on the Composition-1k dataset [xu2017deep]. The ablation study demonstrates that the TCP significantly improves performance compared to the baseline model. The trimap generation methods and the Background Enhancement Loss further enhance the overall results. The model outperforms other state-of-the-art methods in terms of Sum of Absolute Distance (SAD), Mean Squared Error (MSE), and Connectivity metrics (Table 1). Figure 5 illustrates a scenario where some areas that should be absolute backgrounds are predicted as absolute foregrounds by the baseline model.
Figure 5: Comparison of alpha matte predictions between the baseline model and ground truth, showing areas incorrectly predicted as foregrounds.
Figure 6 shows a qualitative example of the model's performance on an image with a low-quality trimap, where the trimap contains no foreground region. The results demonstrate that the model can successfully detect foreground regions even without direct trimap guidance. Figure 7 presents example results on images from the Adobe Deep Image Matting Dataset, comparing the proposed method with Closed-Form Matting [levin2007closed], Deep Image Matting [xu2017deep], and IndexNet [lu2019indices].
Figure 6: Results on an image with a low-quality trimap, comparing the proposed method with IndexNet [lu2019indices].
Figure 7: Qualitative comparison of the proposed method against other state-of-the-art techniques on the Adobe Deep Image Matting Dataset.
Conclusion
This paper presents a novel perspective on deep image matting by explicitly addressing the importance of low-level, high-resolution features for recovering fine-grained details. The proposed dual-path framework, comprising a downsampling-free Textural Compensate Path and an encoder-decoder-based Semantic Path, effectively combines fine-grained details with high-level contextual information. The introduction of a novel Background Enhancement Loss and trimap generation method further enhances the model's robustness. The experimental results demonstrate that the proposed framework significantly outperforms the baseline and achieves state-of-the-art performance on the Composition-1k dataset.