- The paper establishes convergence of archetypal analysis for compact supports by proving that AA solutions converge to the continuum minimizer with quantifiable rates.
- It introduces a penalized variant for unbounded distributions that controls archetype variance, assuring bounded and stable solutions.
- Numerical experiments validate the theoretical findings with evidence of robust convergence across initializations and under different data distributions.
Consistency Properties of Archetypal Analysis
Archetypal Analysis: Problem Definition and Prior Work
Archetypal analysis (AA) is an unsupervised learning method that constructs a convex polytope, with k vertices (archetype points), to summarize multivariate data XN⊂Rd. The optimal polytope minimizes the root mean squared distance from the data points to the convex hull of the archetypes, constrained so that the polytope lies within the convex hull of the data. Formally, for A⊂Rd with ∣A∣=k, the optimization is:
A⊂RdminF(A),A⊂co(XN),F(A)=(N1i=1∑Nd2(xi,co(A)))1/2.
AA was introduced by Cutler and Breiman (1994); its boundary-constrained nature makes it sensitive to outliers. Subsequent literature has developed robust extensions and efficient algorithms, including alternating minimization and matrix factorization comparisons [see references within (2010.08148)].
Consistency Results for Archetypal Analysis with Compact Support
A central question addressed is the consistency of AA: If data x1,x2,… are i.i.d. from measure μ, do the archetype solutions AN converge as N→∞? For measures with compact support, the paper rigorously establishes:
Fμ(AN)−Fμ(A⋆)≲(NlogN)1/α
For uniform distributions on convex sets with positive density, this rate is O((logN/N)1/d).
Archetypal Analysis for Unbounded Support Distributions
For distributions with unbounded support, direct AA fails to be consistent, as the convex hull of sampled points grows without bound. The paper proposes a penalized variant:
Fν,α(A)=(Fν2(A)+αV(A))1/2
where V(A) is the variance of the archetype pointset and α>0 is a penalty parameter, limiting the spread of the archetypes and ensuring the solution doesn't escape to infinity.
- Existence: For square-integrable ν, minimizers exist and are bounded.
- Consistency: The penalized AA is consistent; solutions for finite samples converge (subsequences) to a minimizer of the continuum penalized problem.
- Asymptotics as penalty increases: As α→∞, the archetypes collapse to the data mean, matching intuition.
Numerical Experiments: Empirical Convergence and Dependence on Distribution
Numerical experiments confirm theoretical results:
- Convergence of archetype polytope for uniform disk: Archetype points converge to regular k-polygons inscribed in the disk, as predicted analytically.
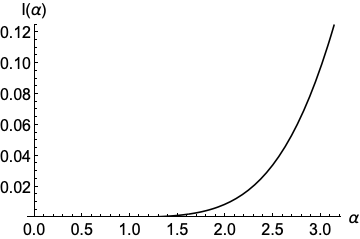
Figure 2: The function I:[0,π]→R that determines the squared objective value for the regular k-polygon inscribed in the unit disk.
- Effect of penalty parameter for normal/annular distributions: The area of co(A) shrinks as α increases.
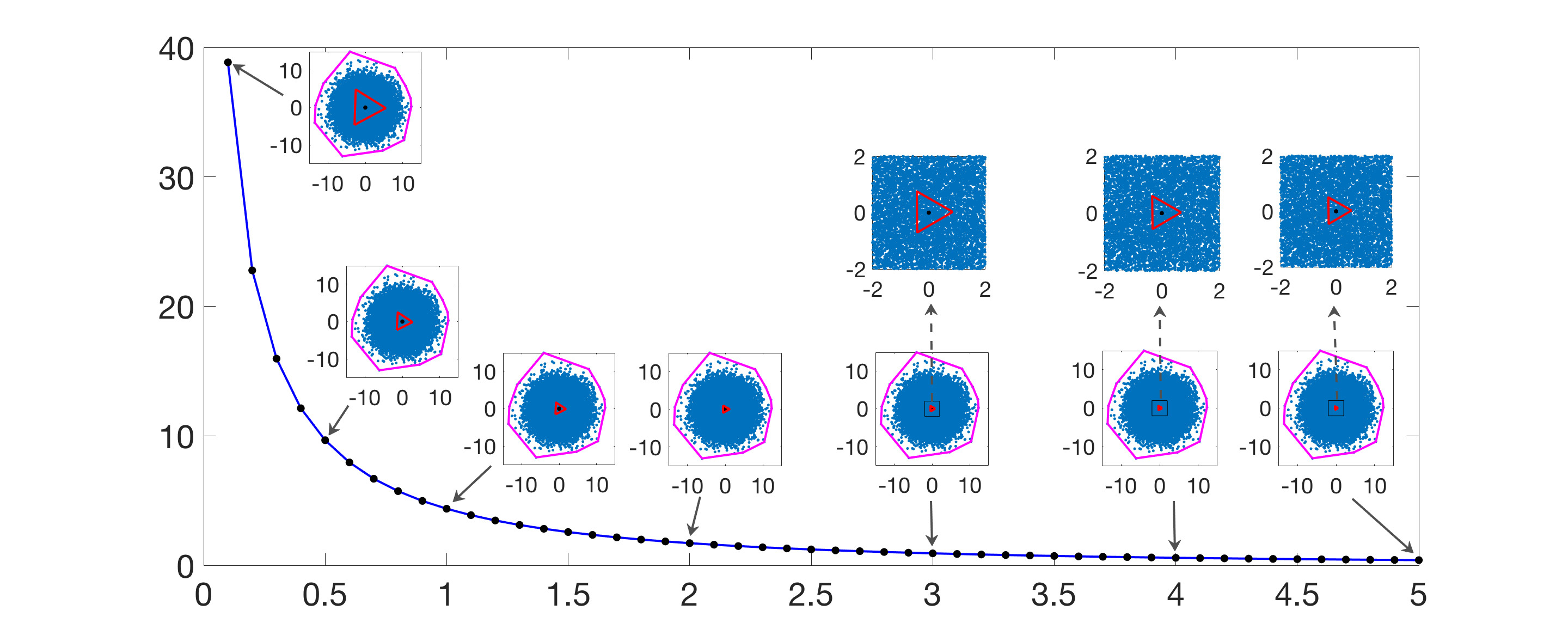
Figure 3: The area of co(A) as α is varied for N=30,000 random data points generated from a normal distribution.
- Robustness to initialization and sample randomness: Multiple experiments with various initializations confirm that final solutions are insensitive to starting points, provided constraints and penalty are in place.
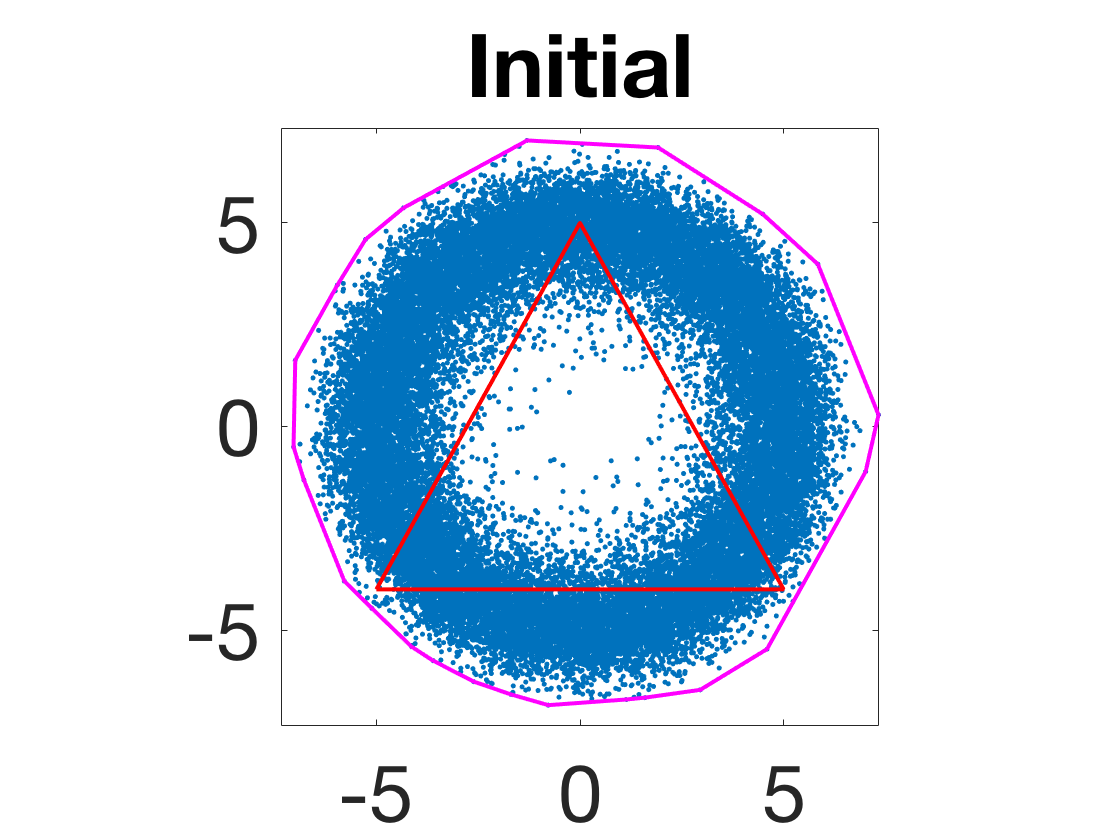
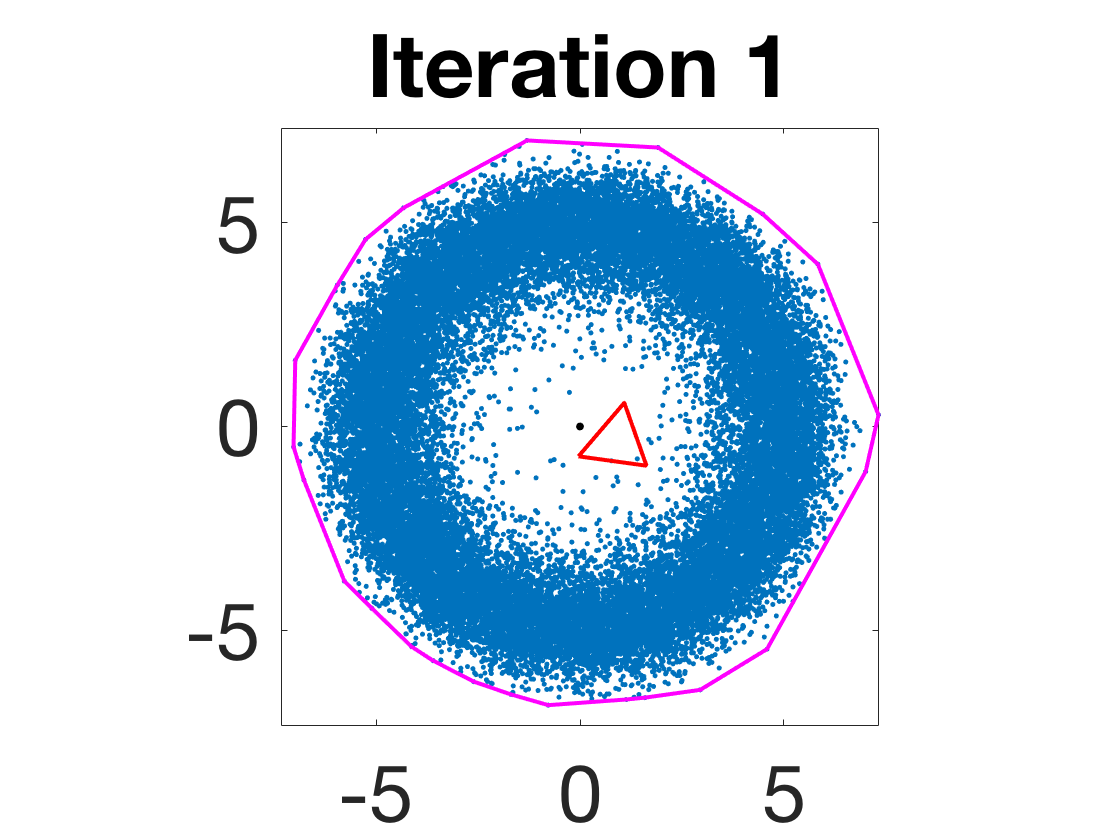
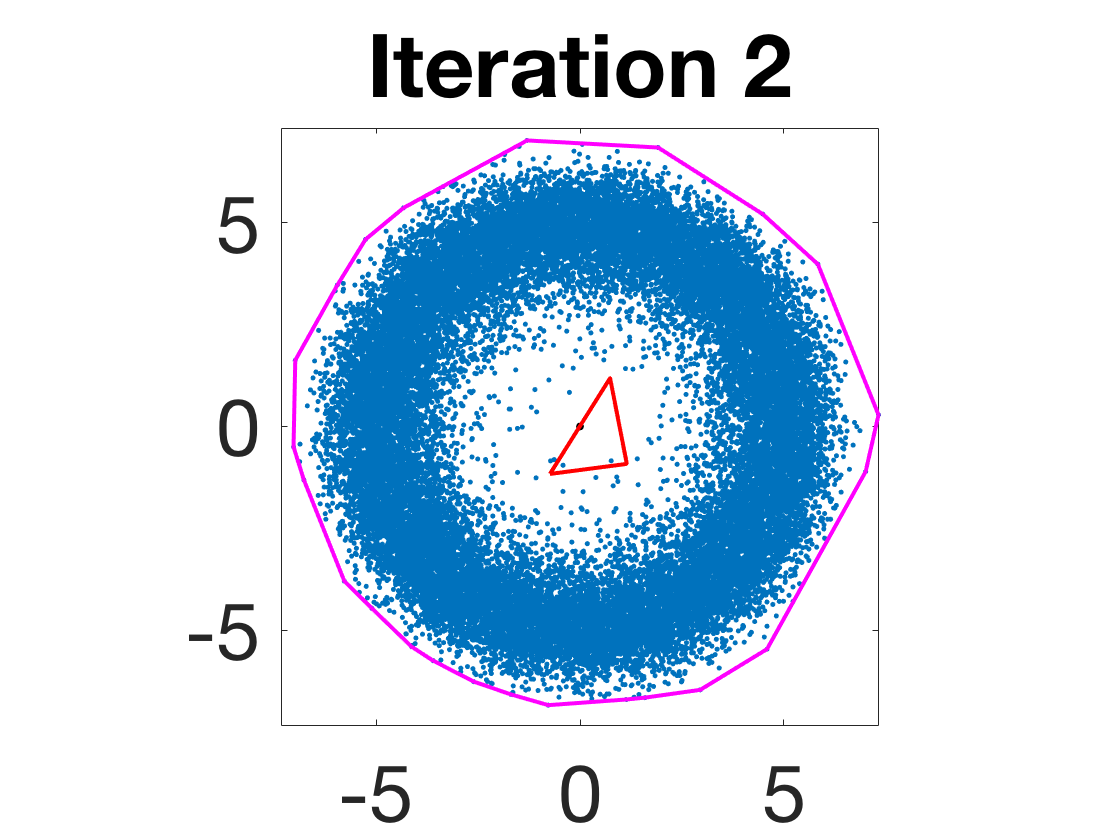
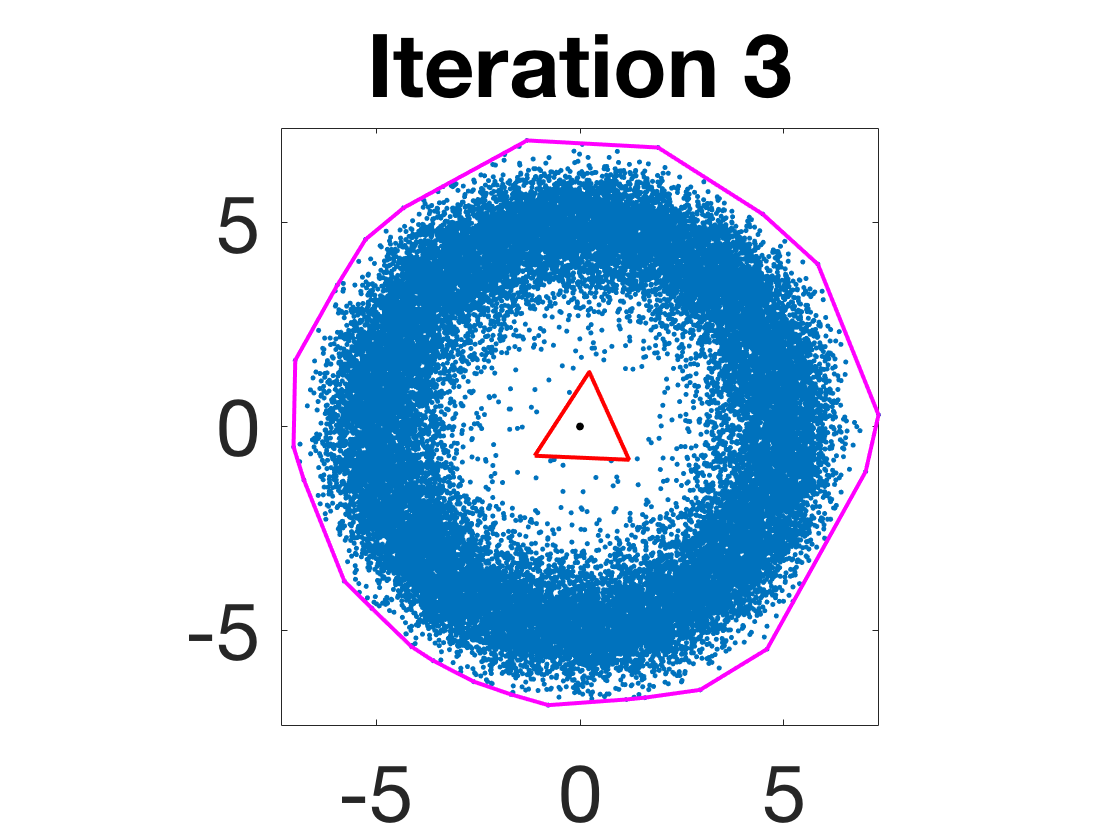
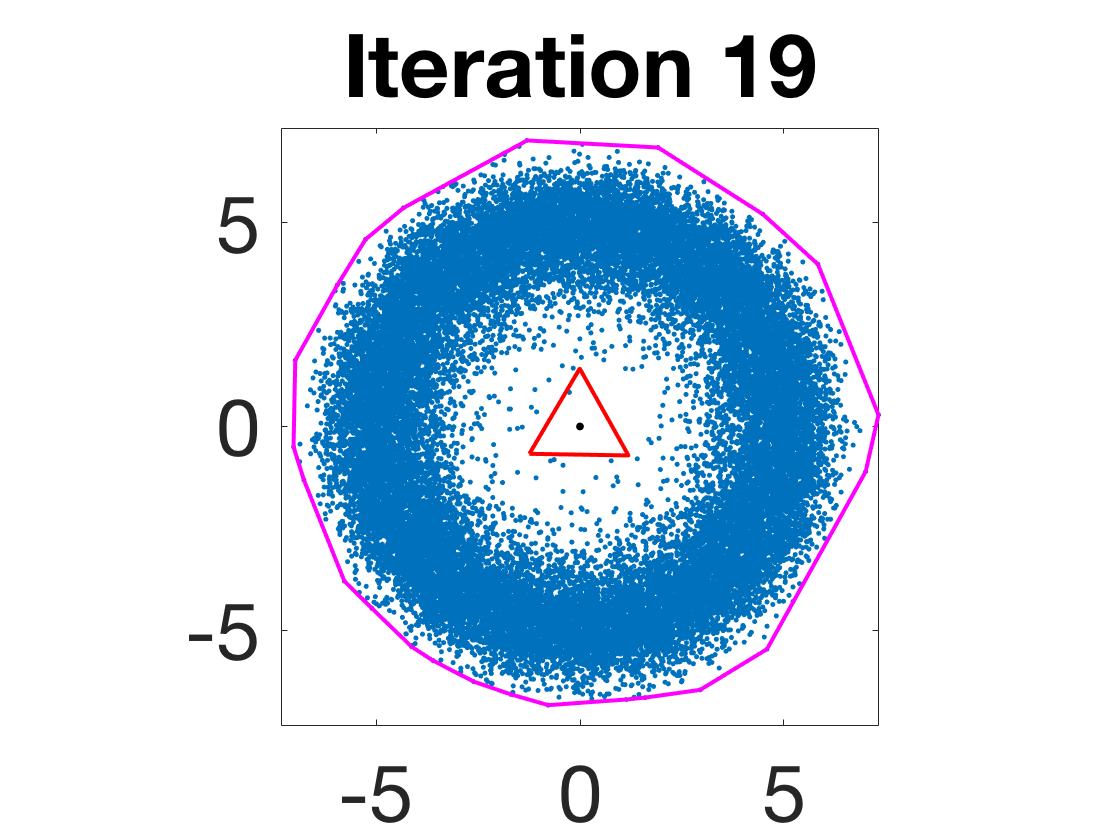
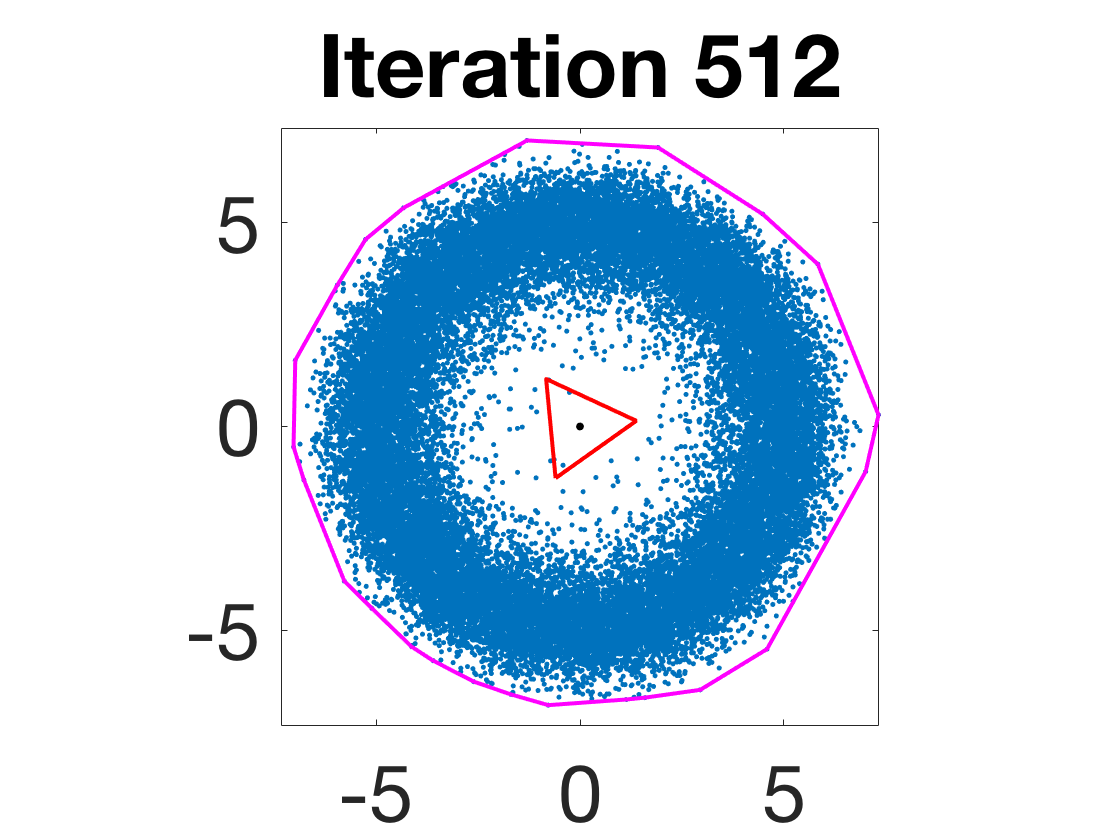
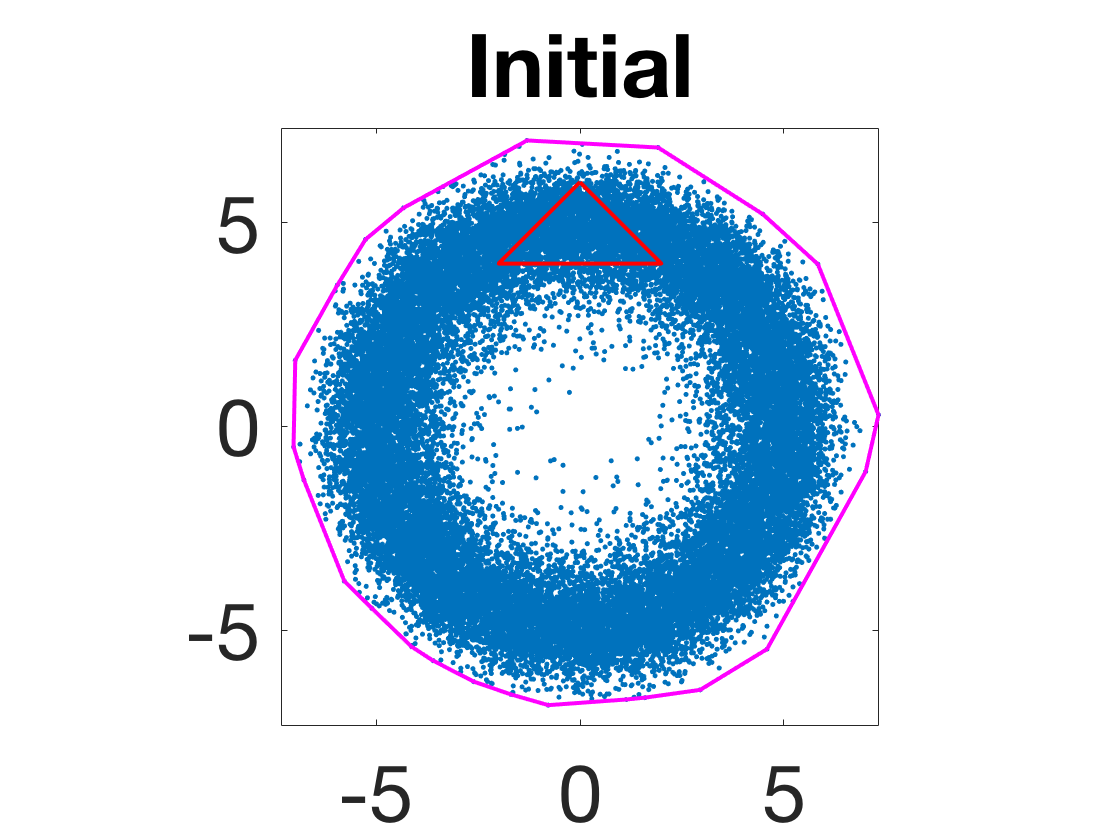
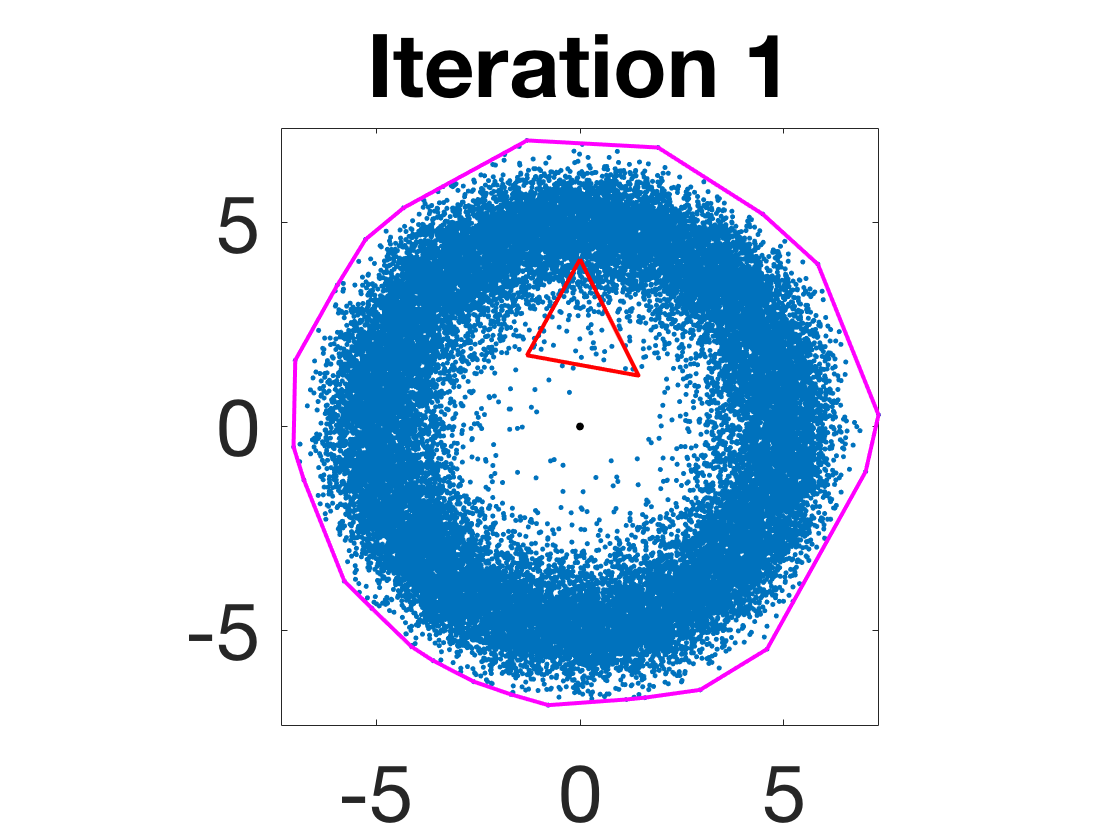
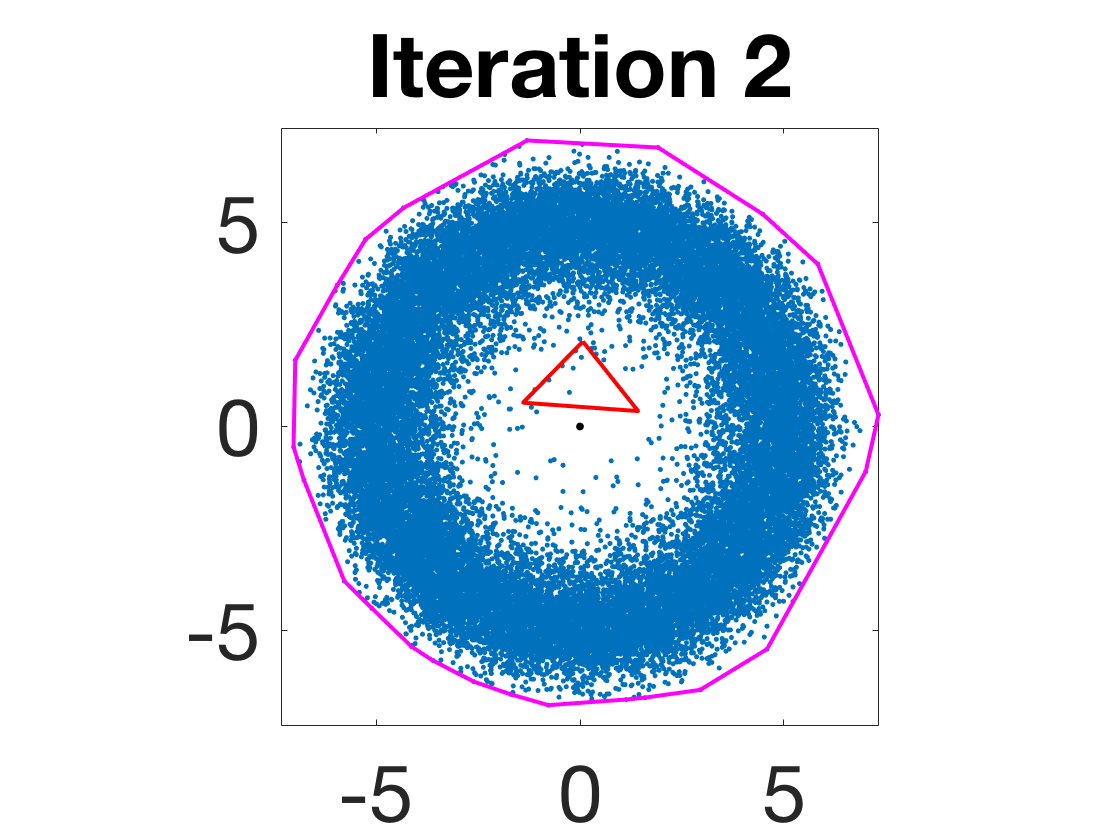
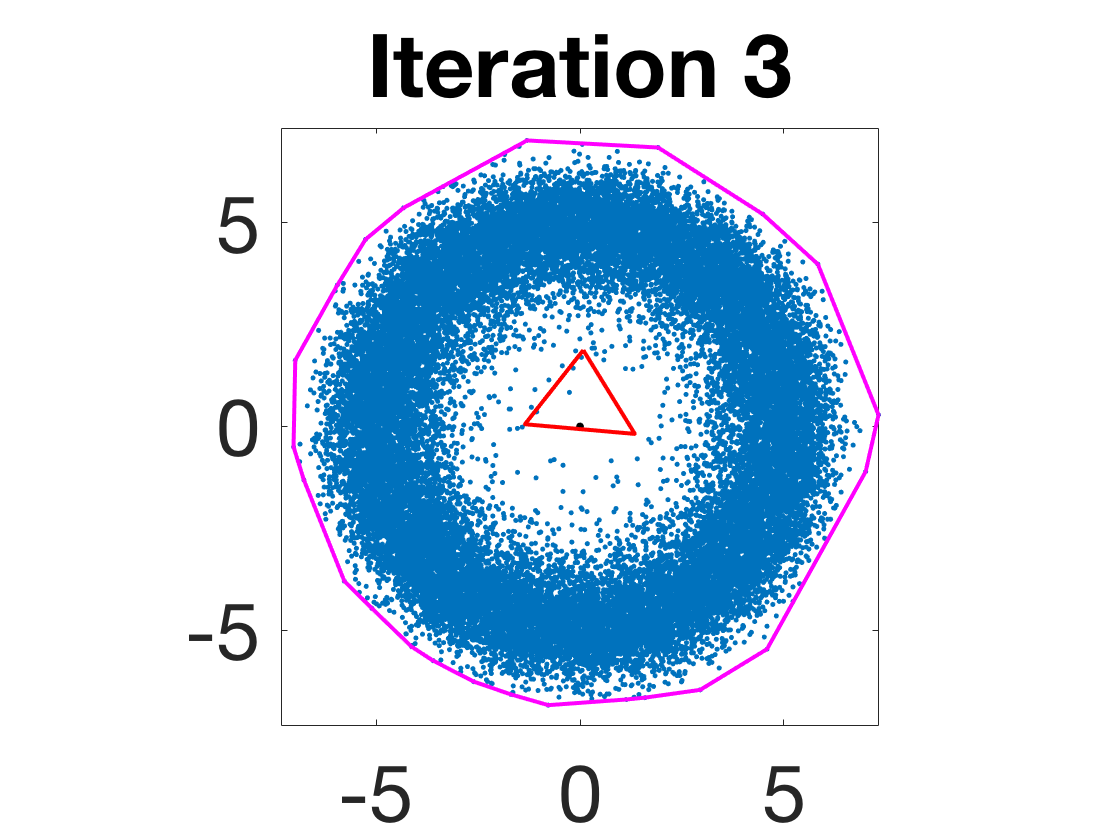
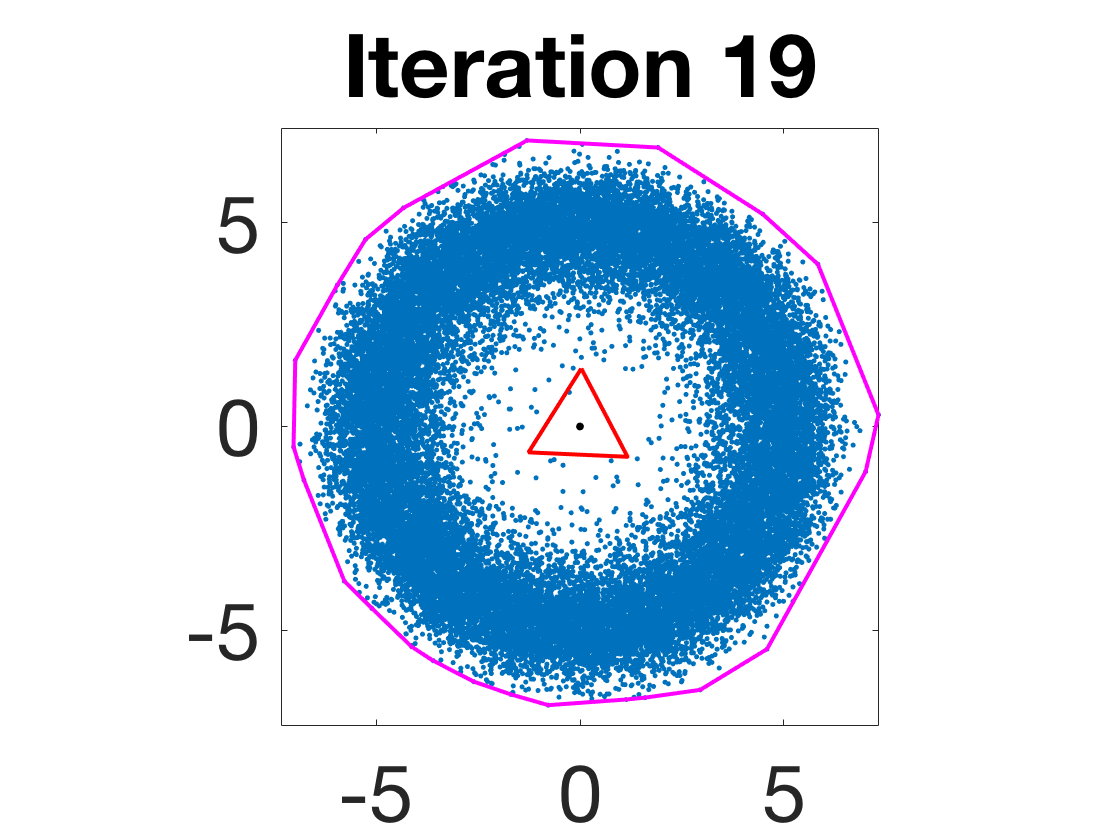
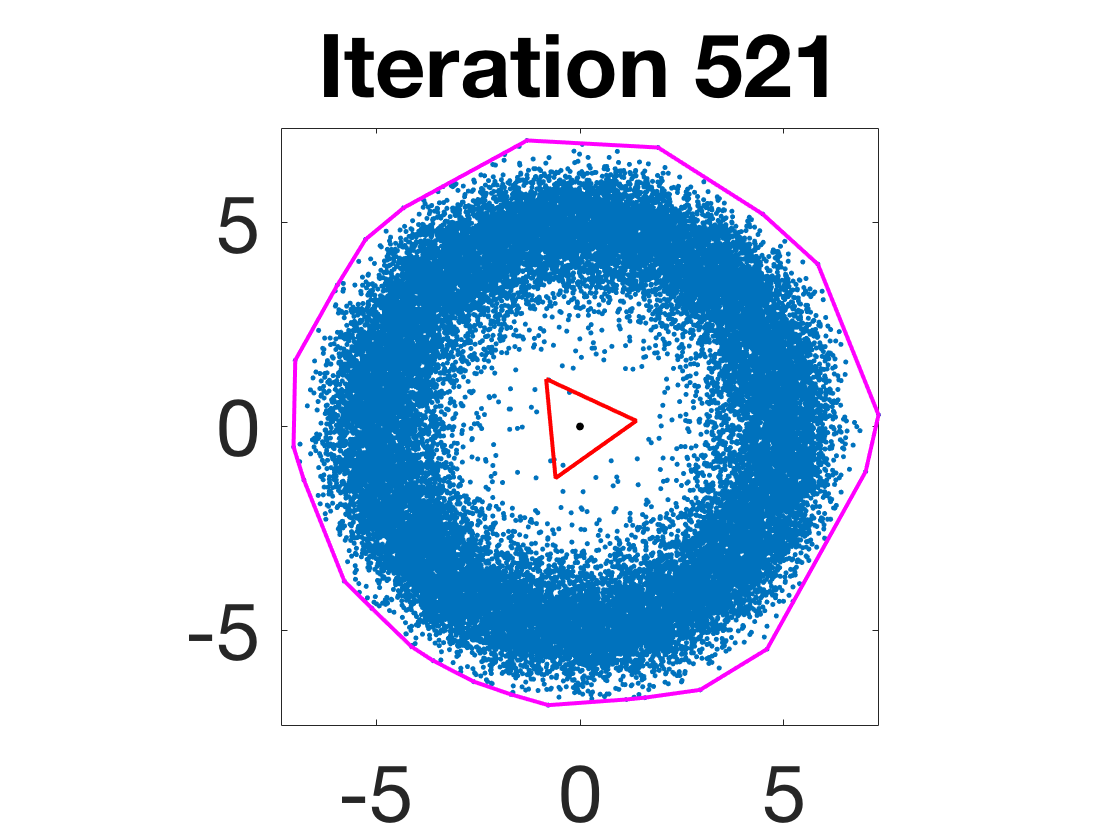
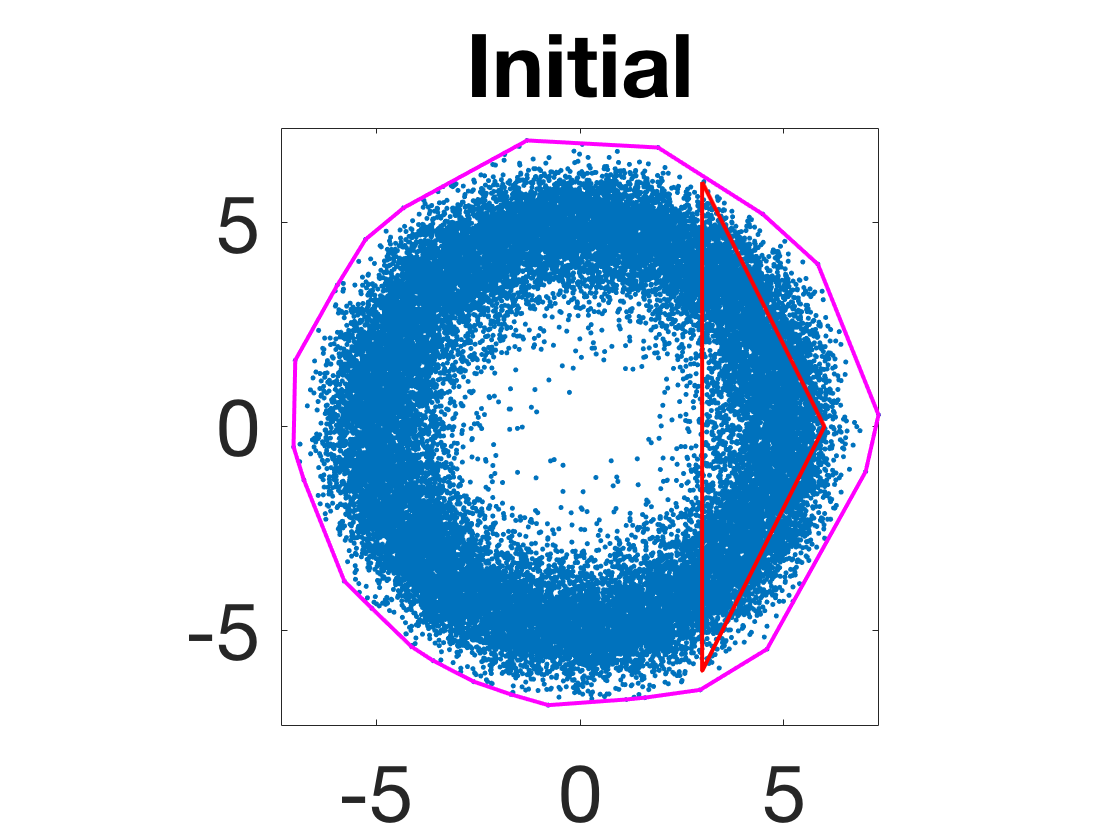
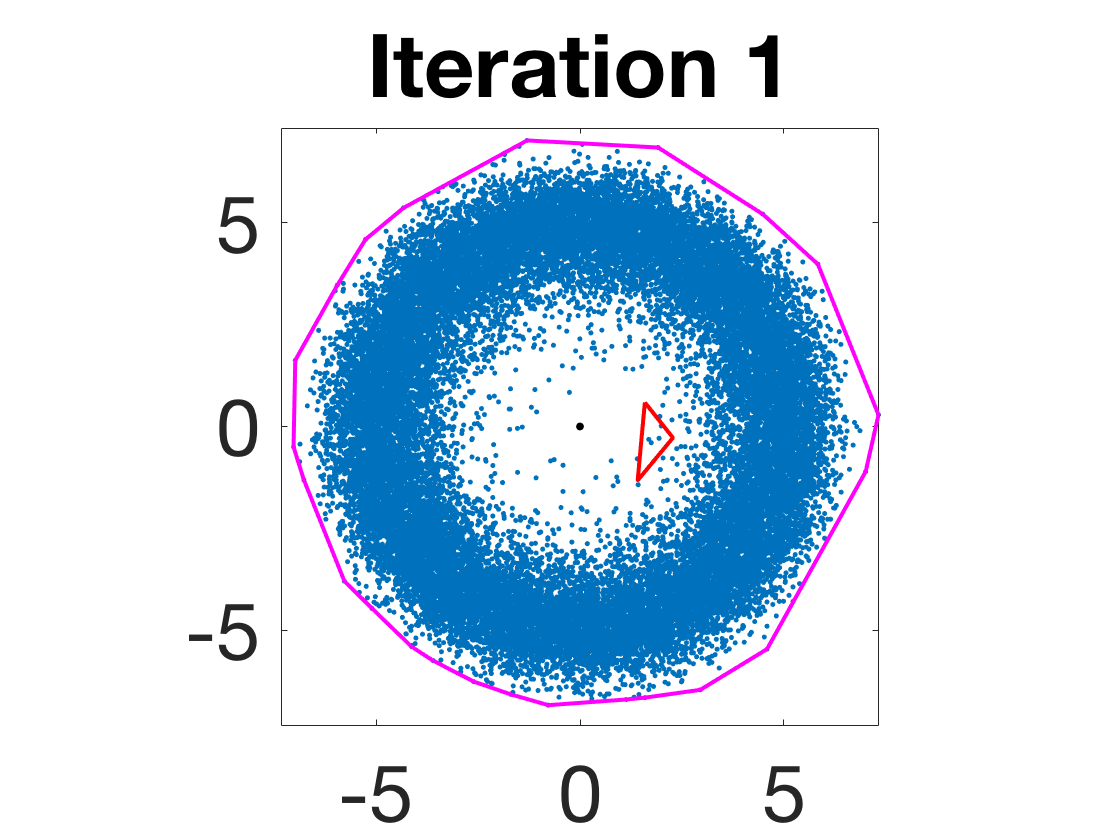
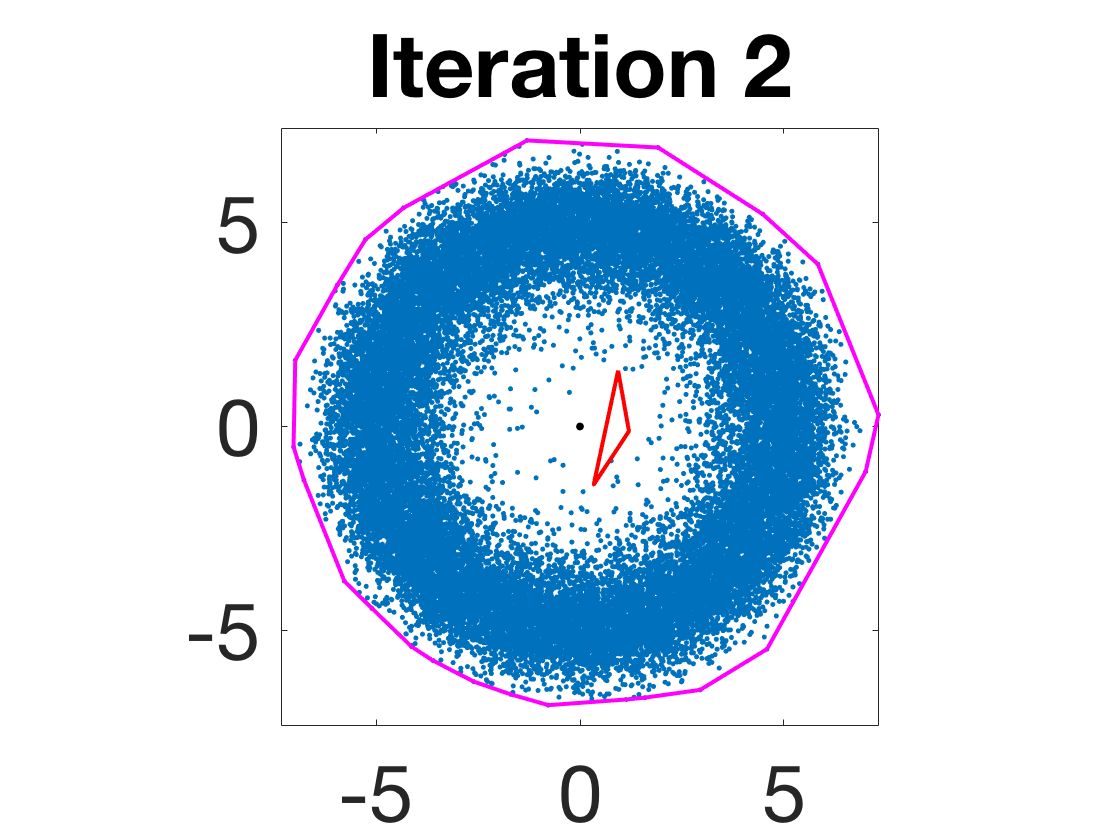
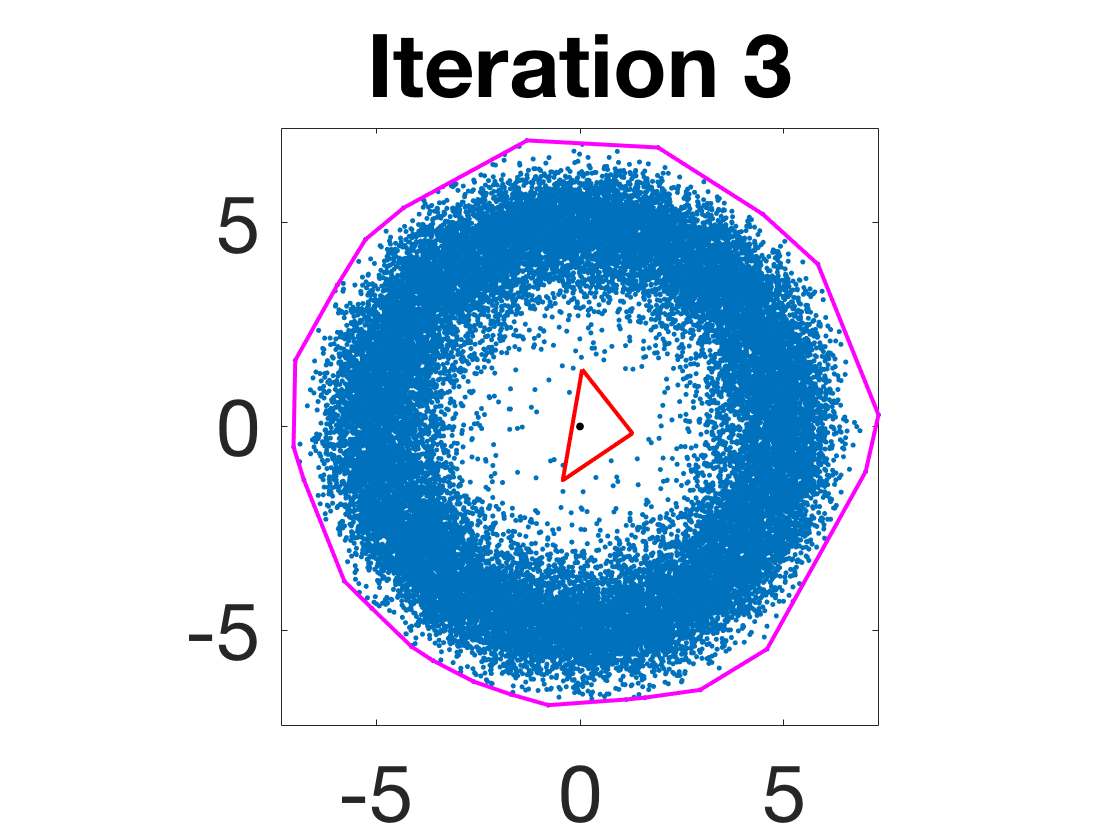
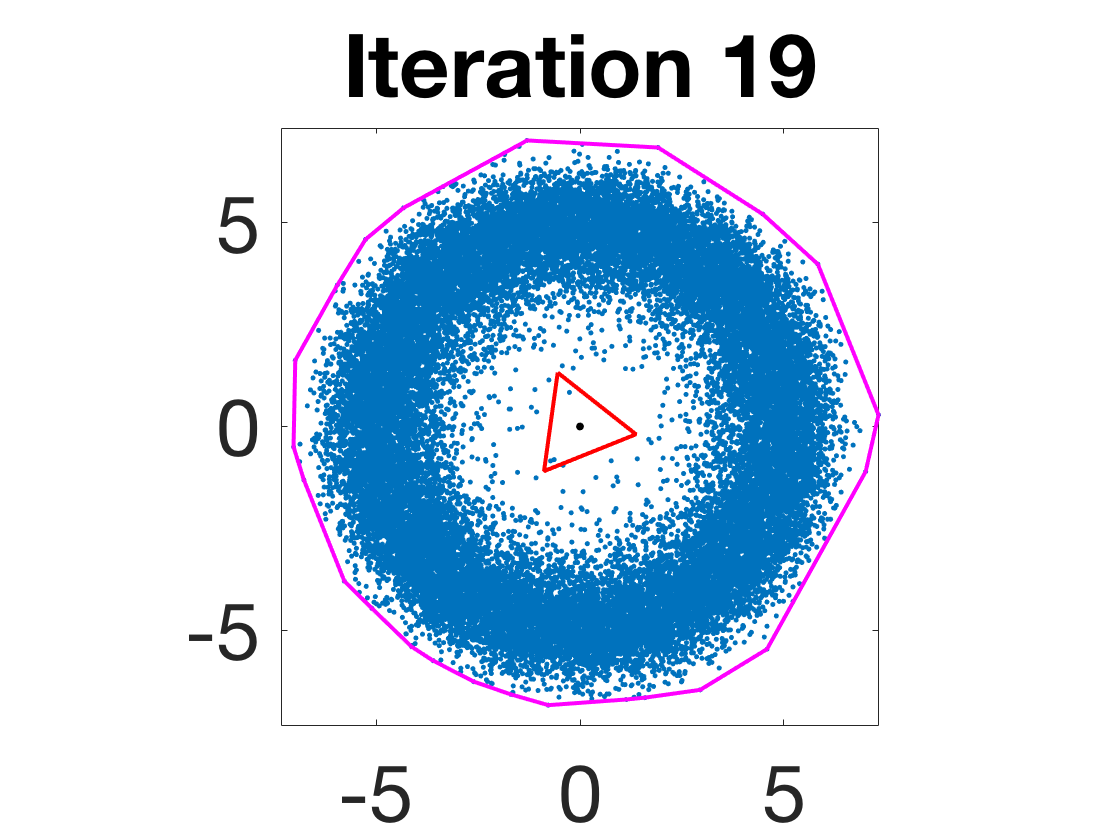
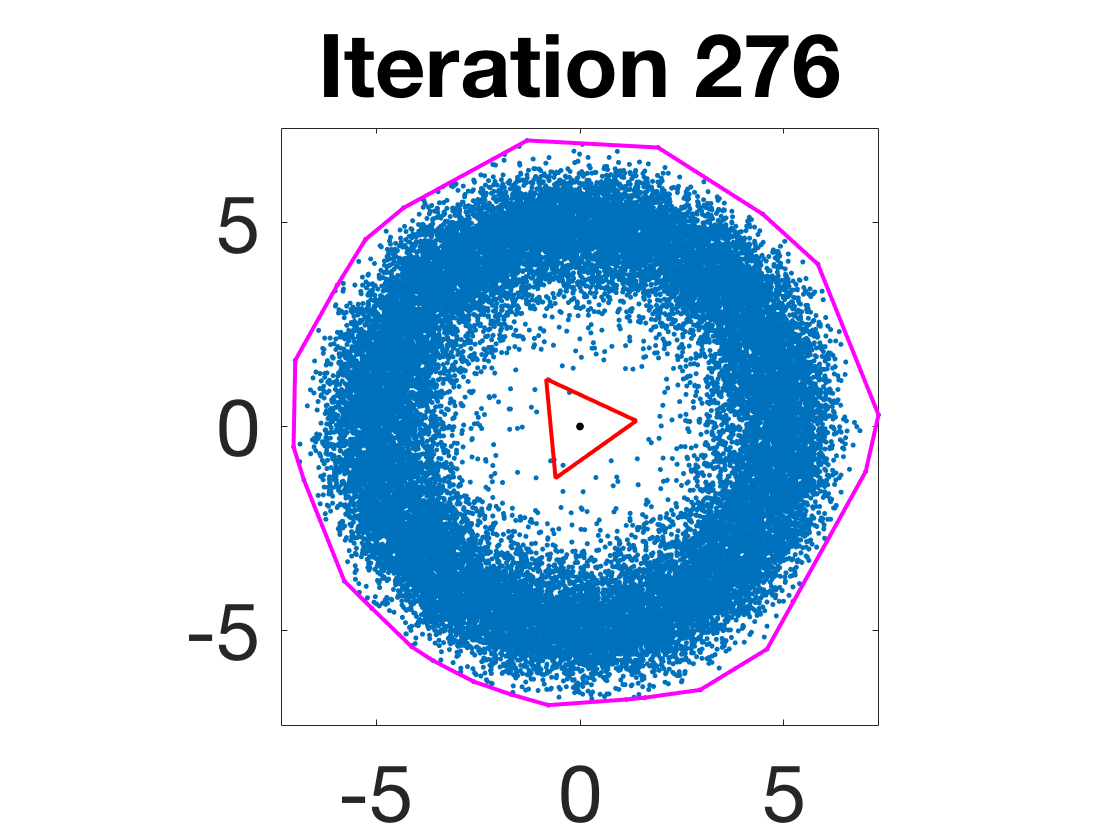
Figure 4: Snapshots of the iterates for different initializations; final column displays converged archetype polytope.
- Behavior for Gaussian mixture: In high-anisotropy scenarios, archetypes remain consistent and contain the mean as α grows.
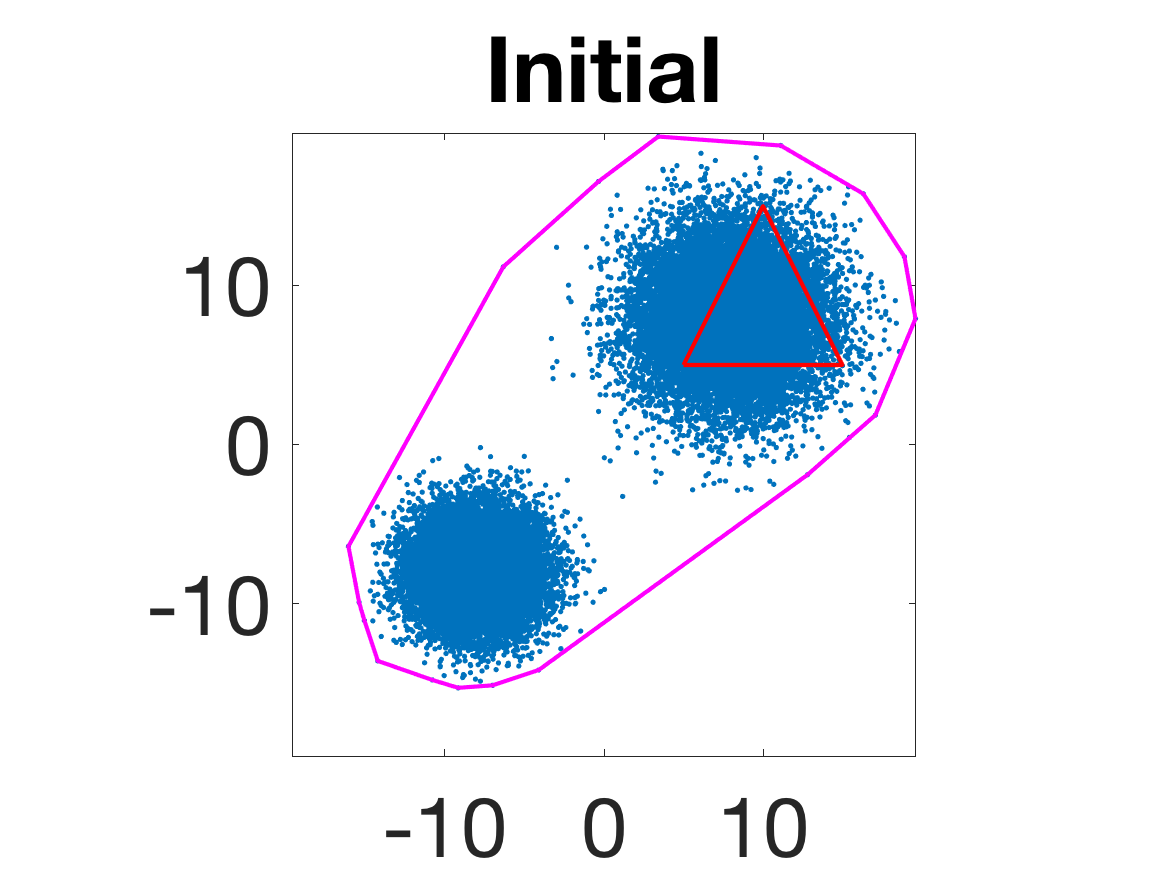
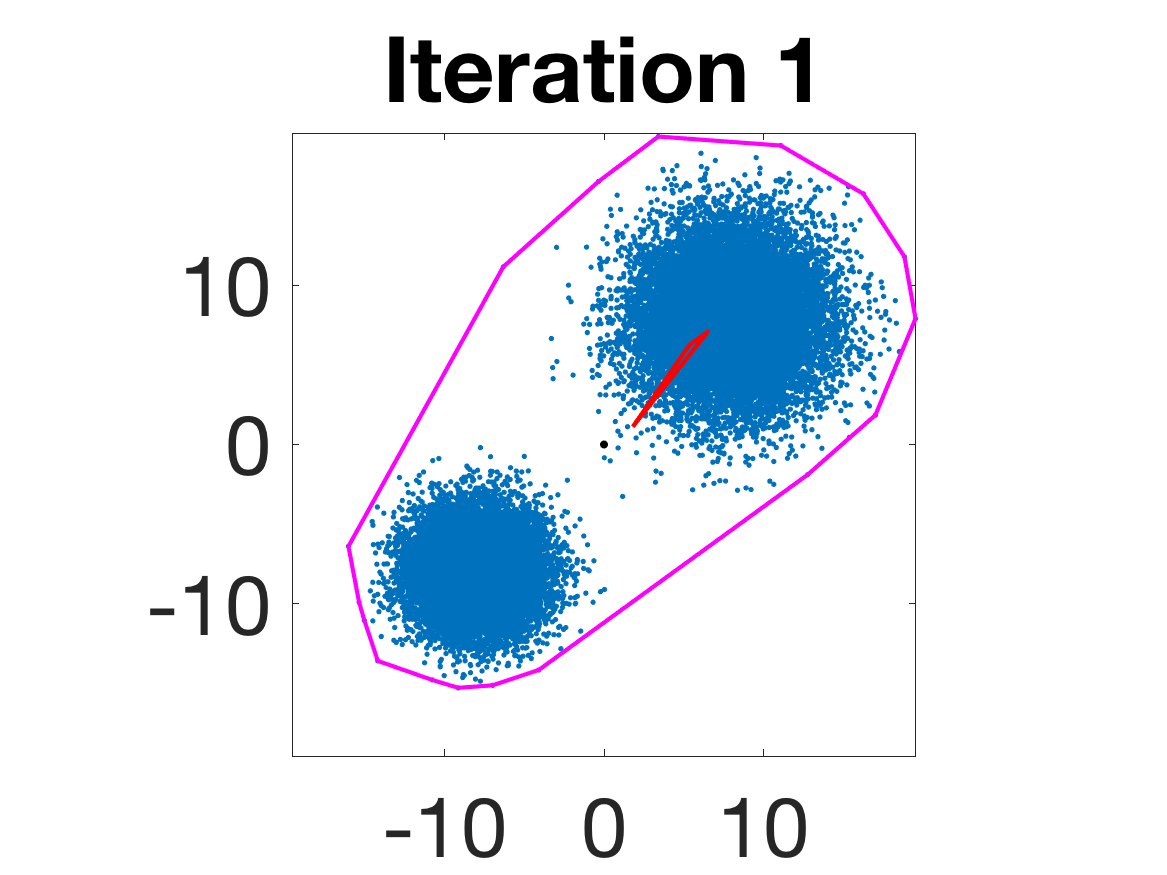
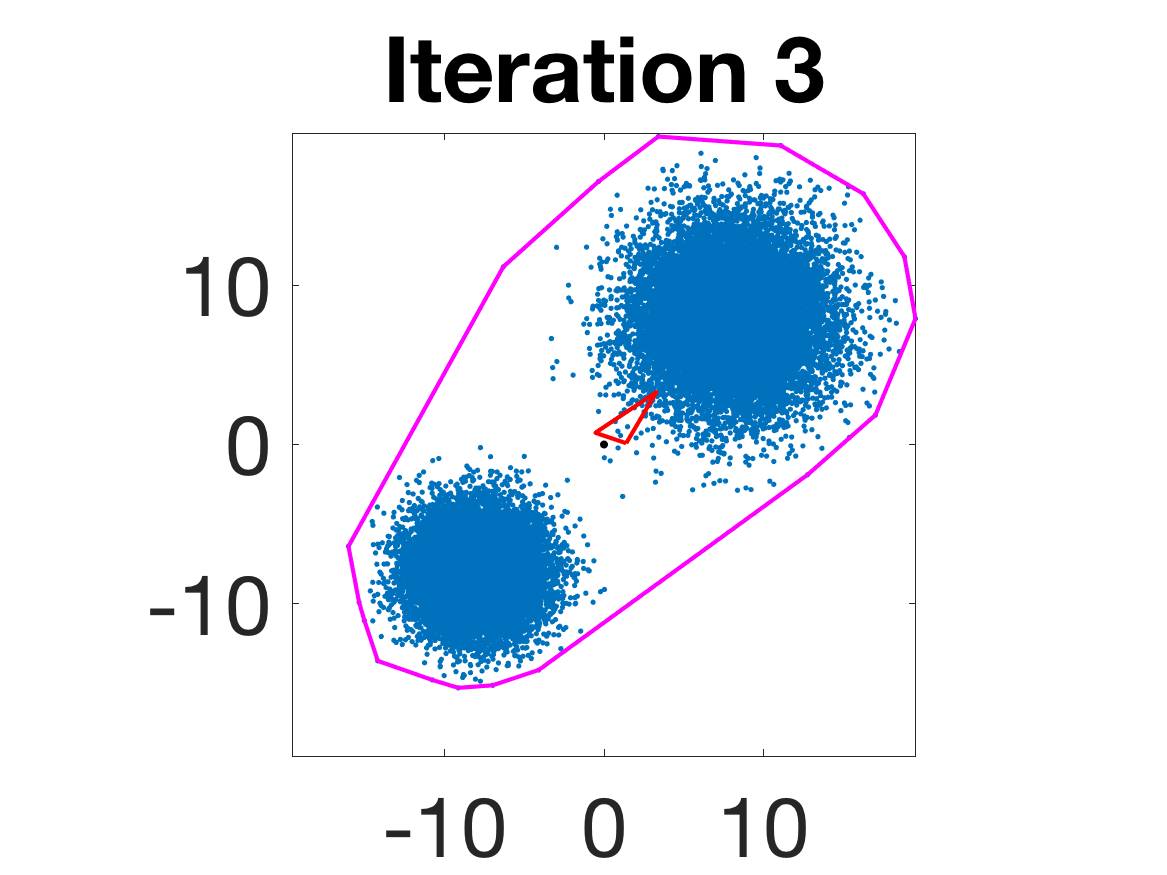
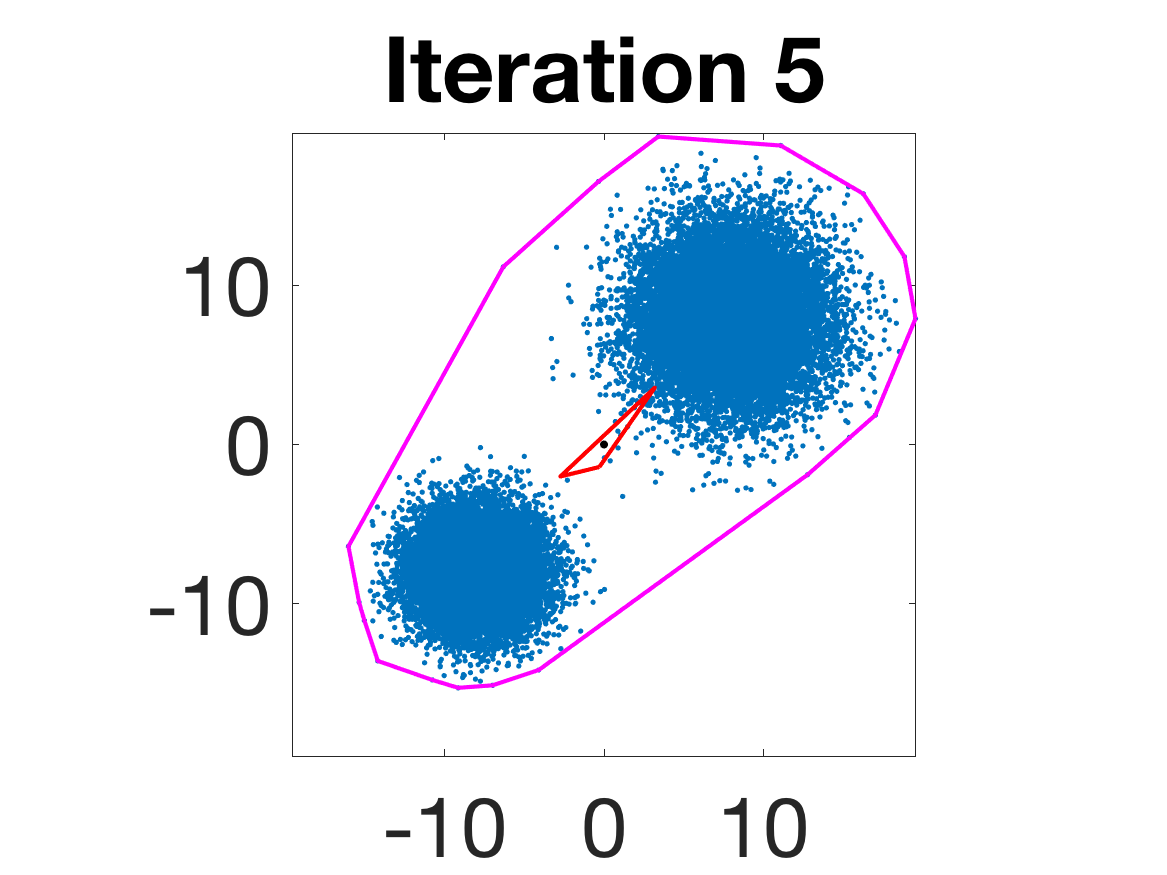
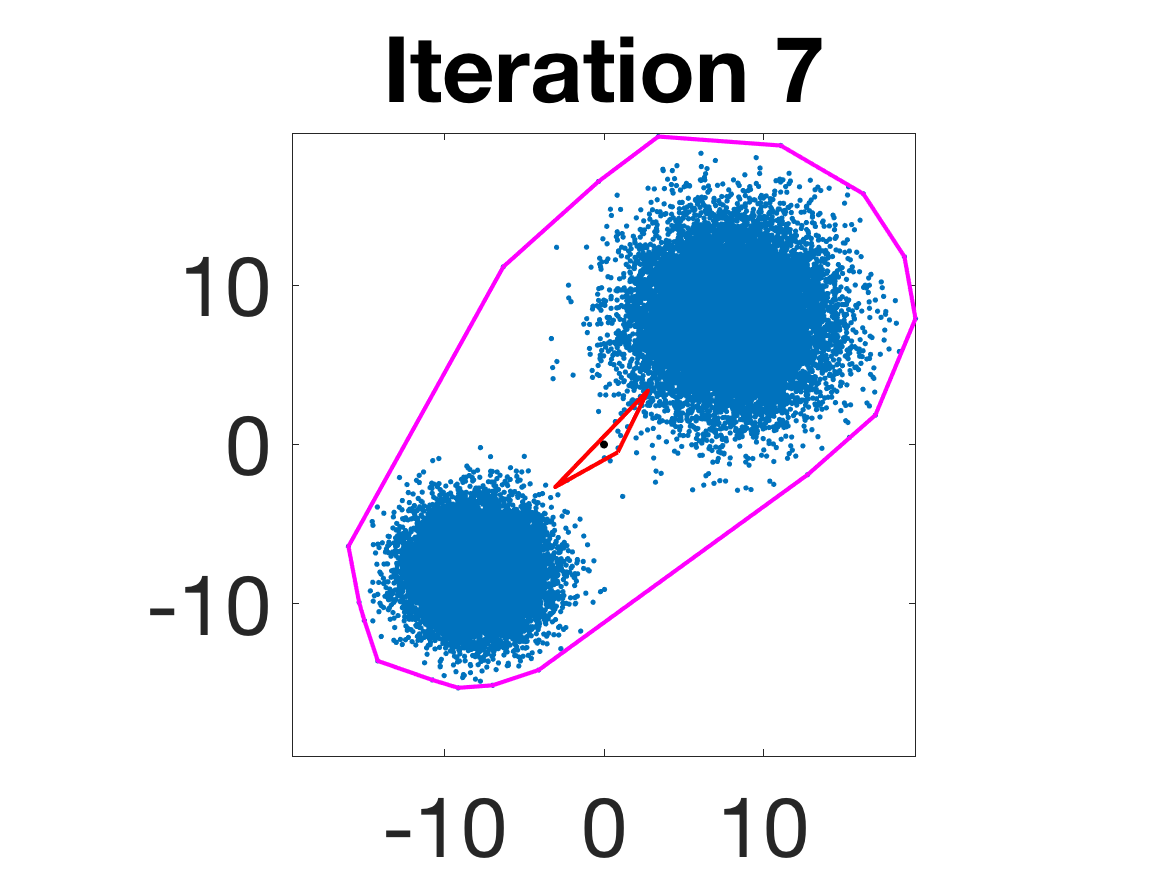
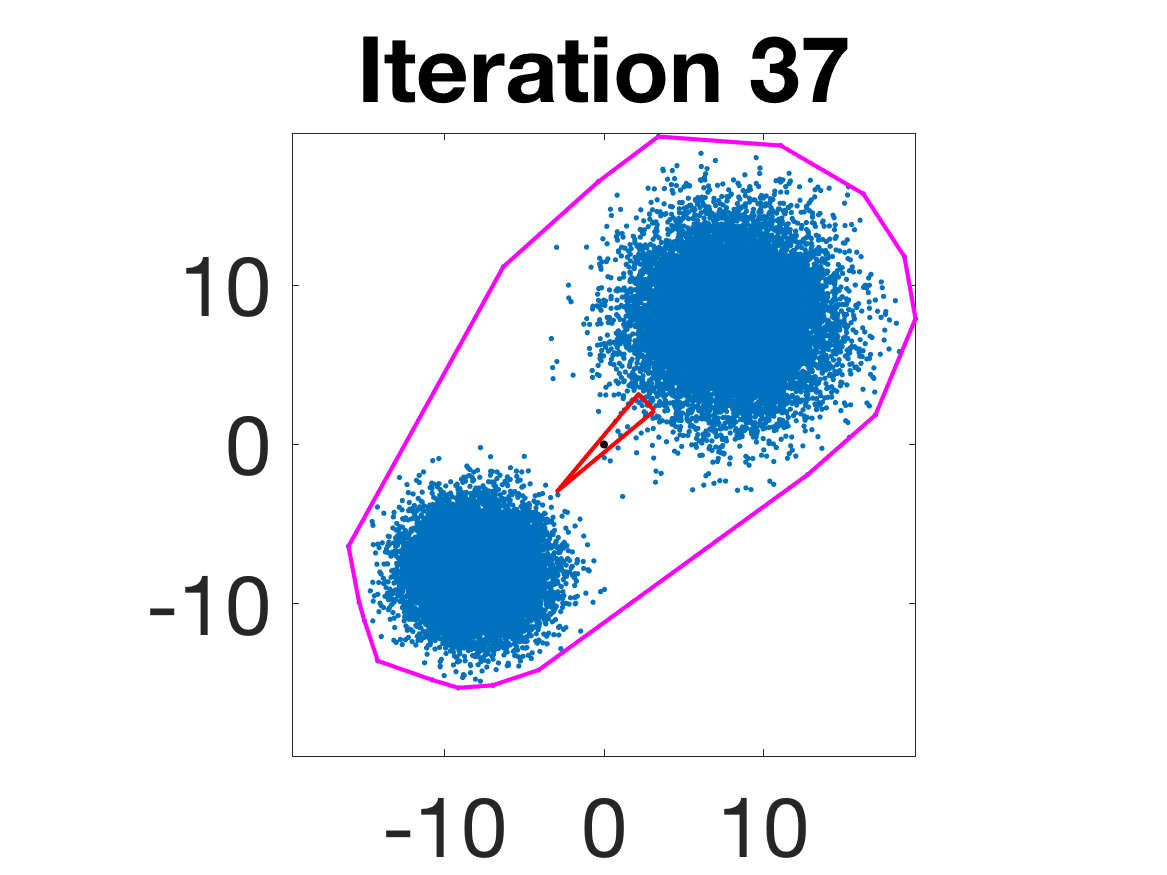
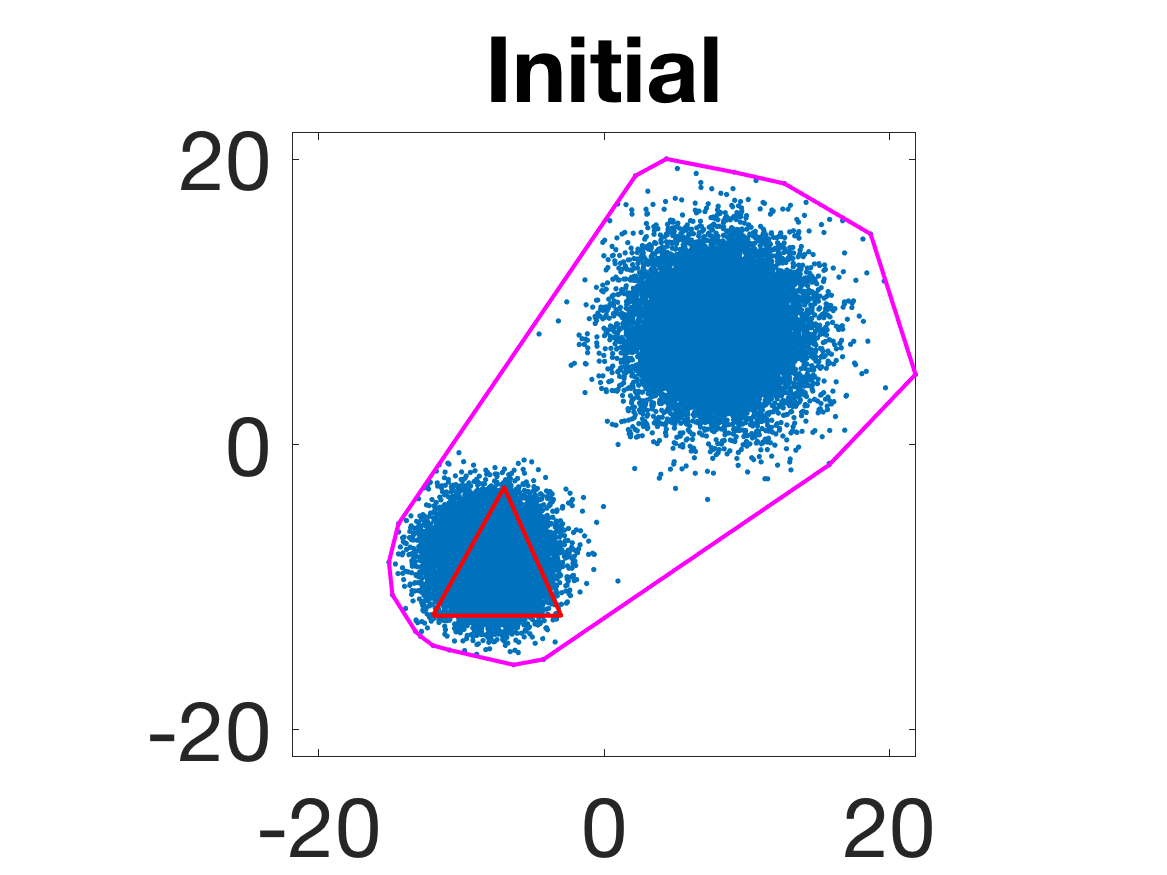
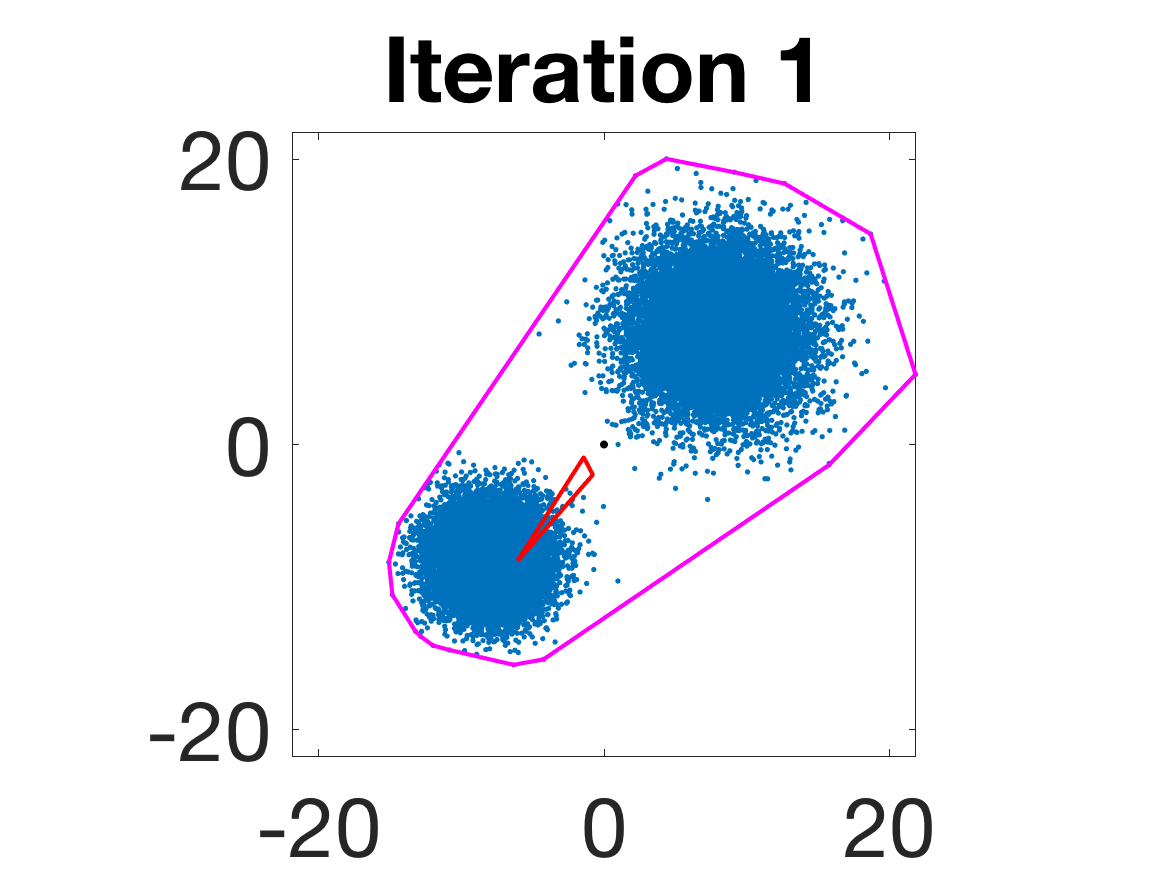
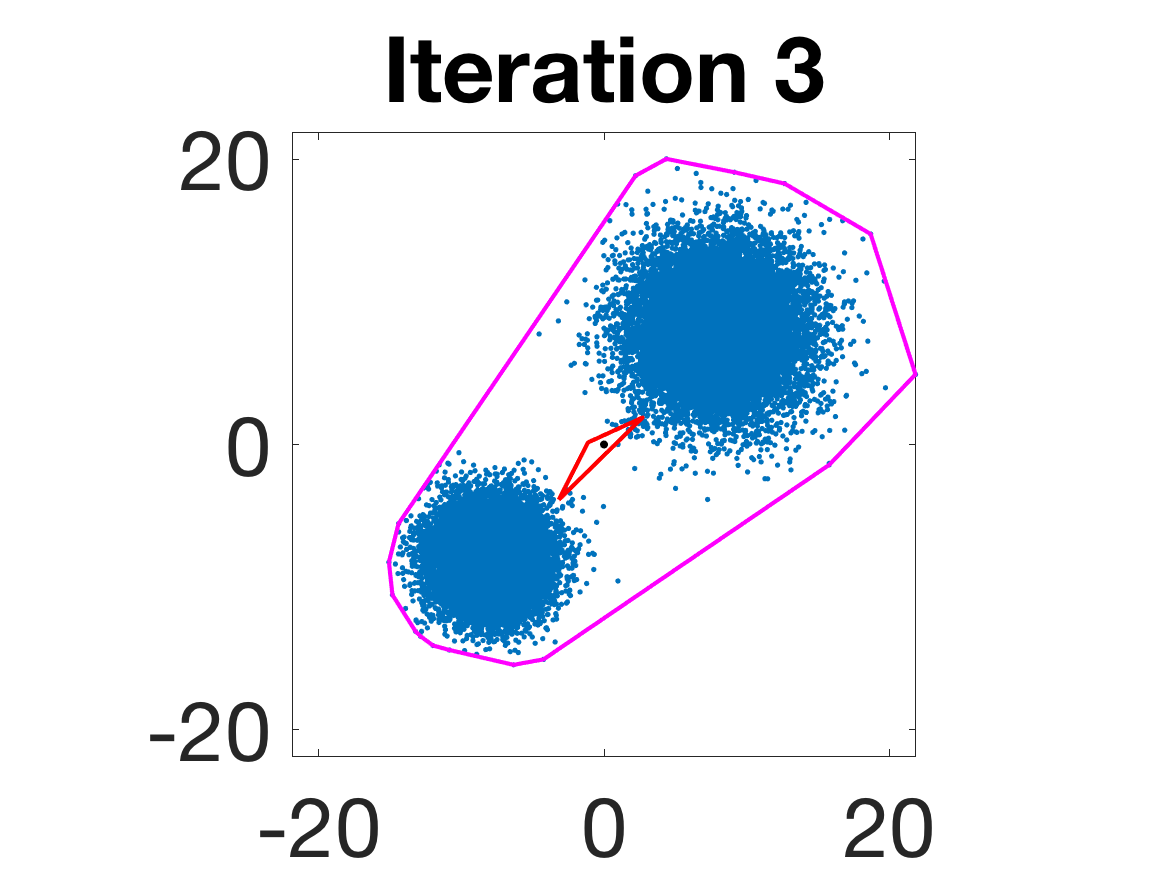
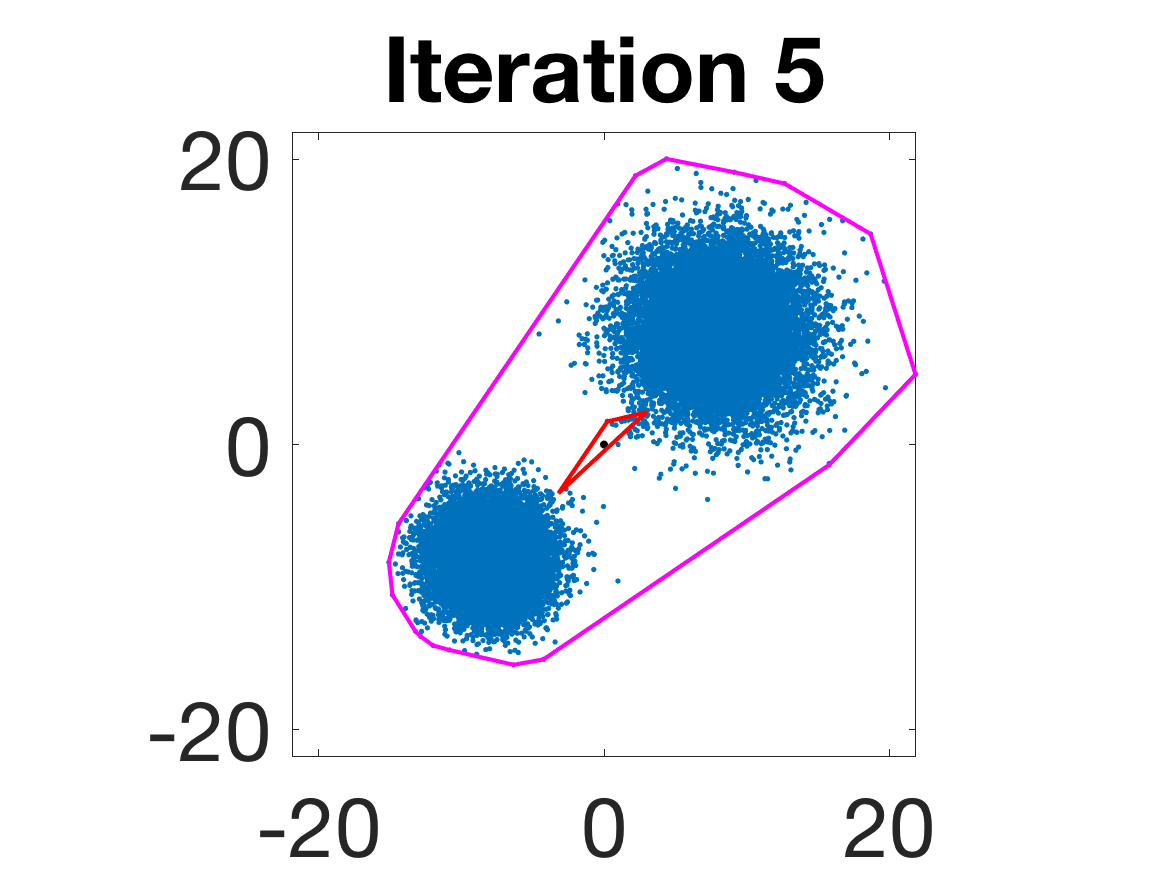
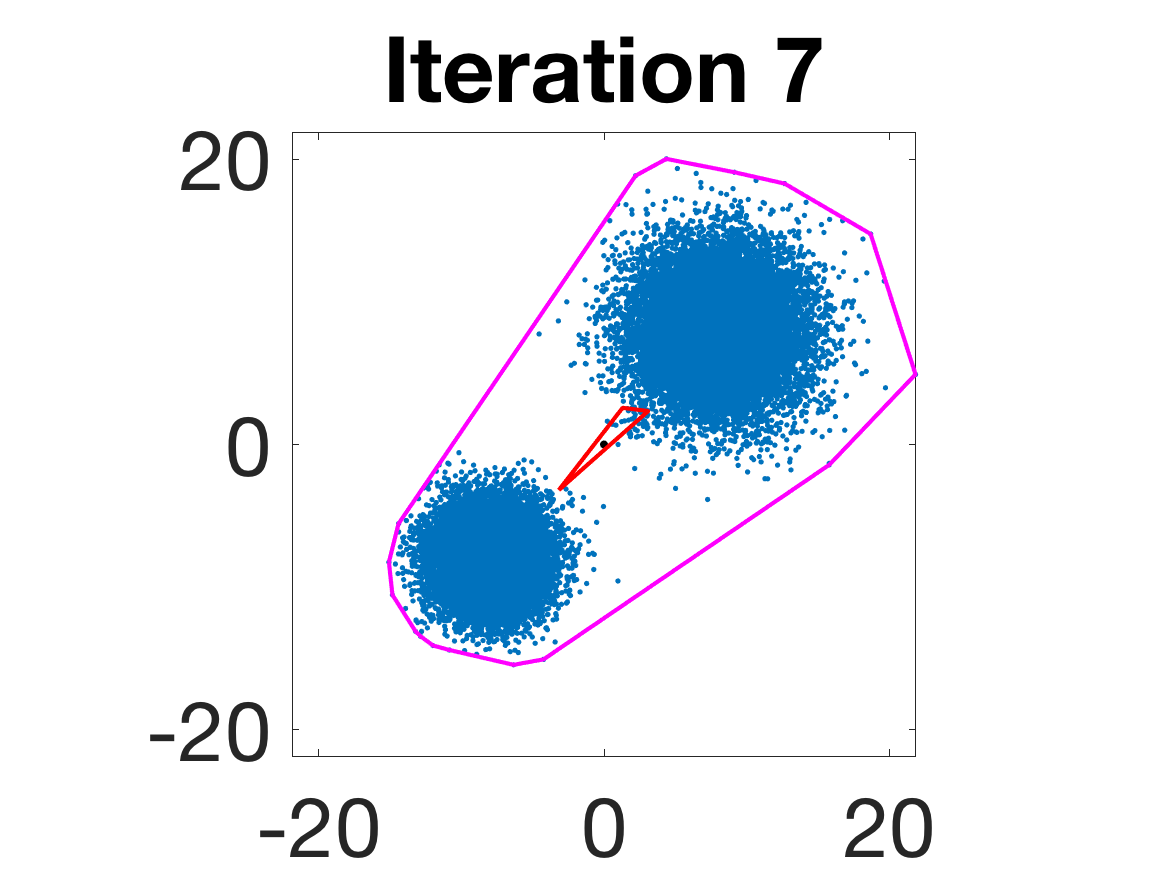
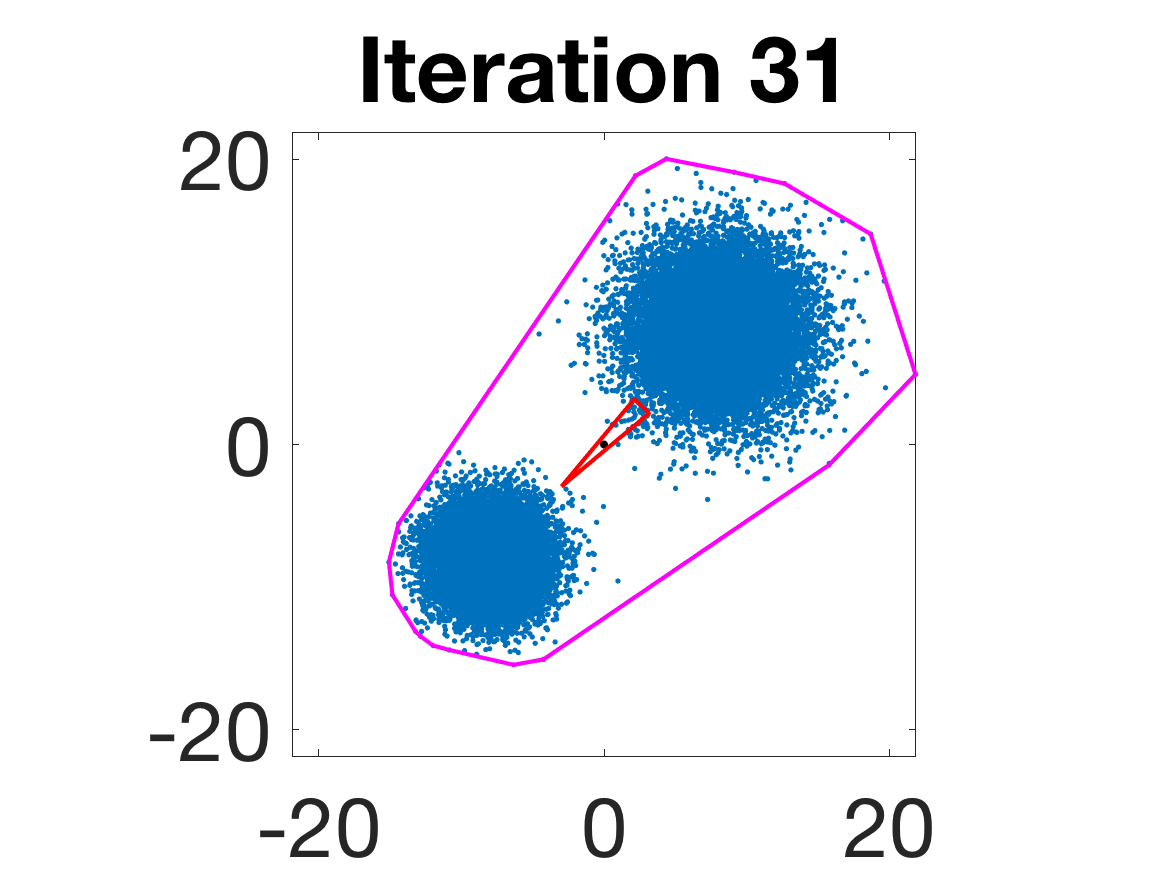
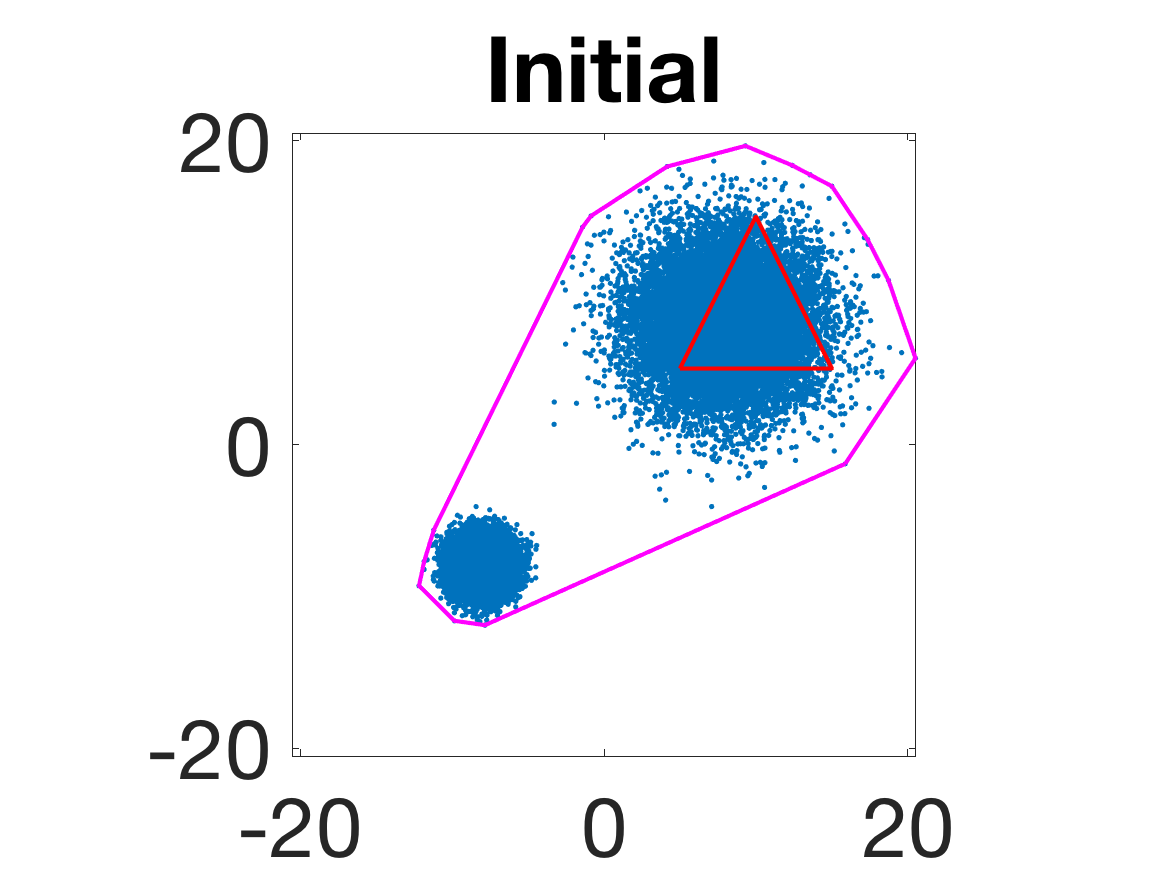
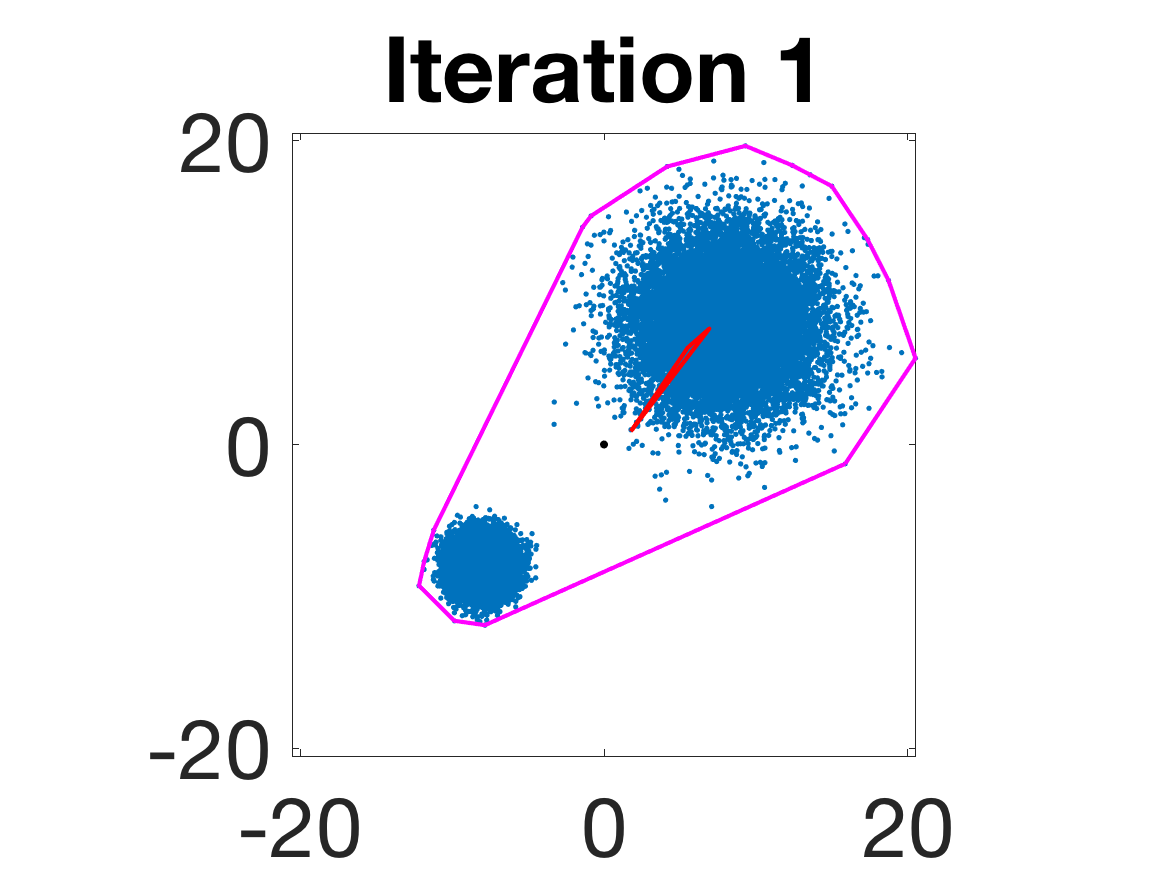
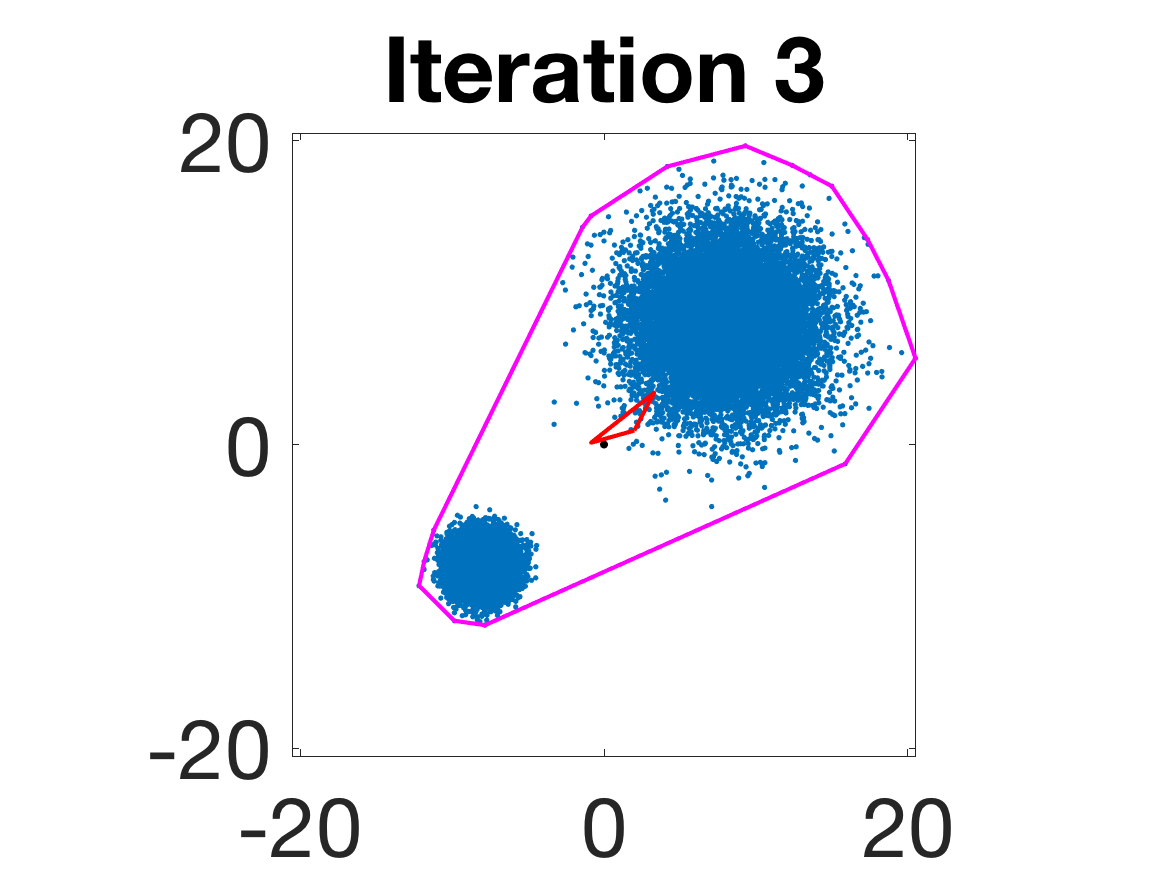
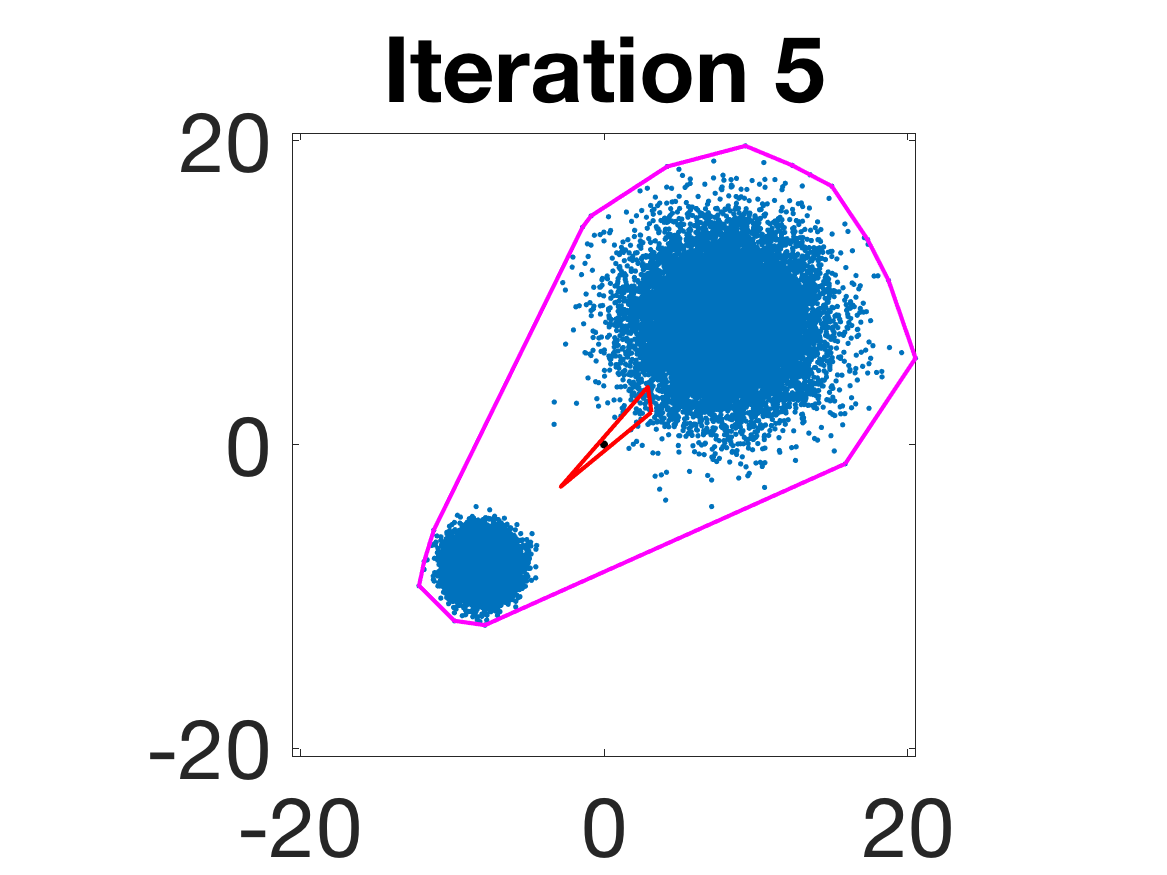
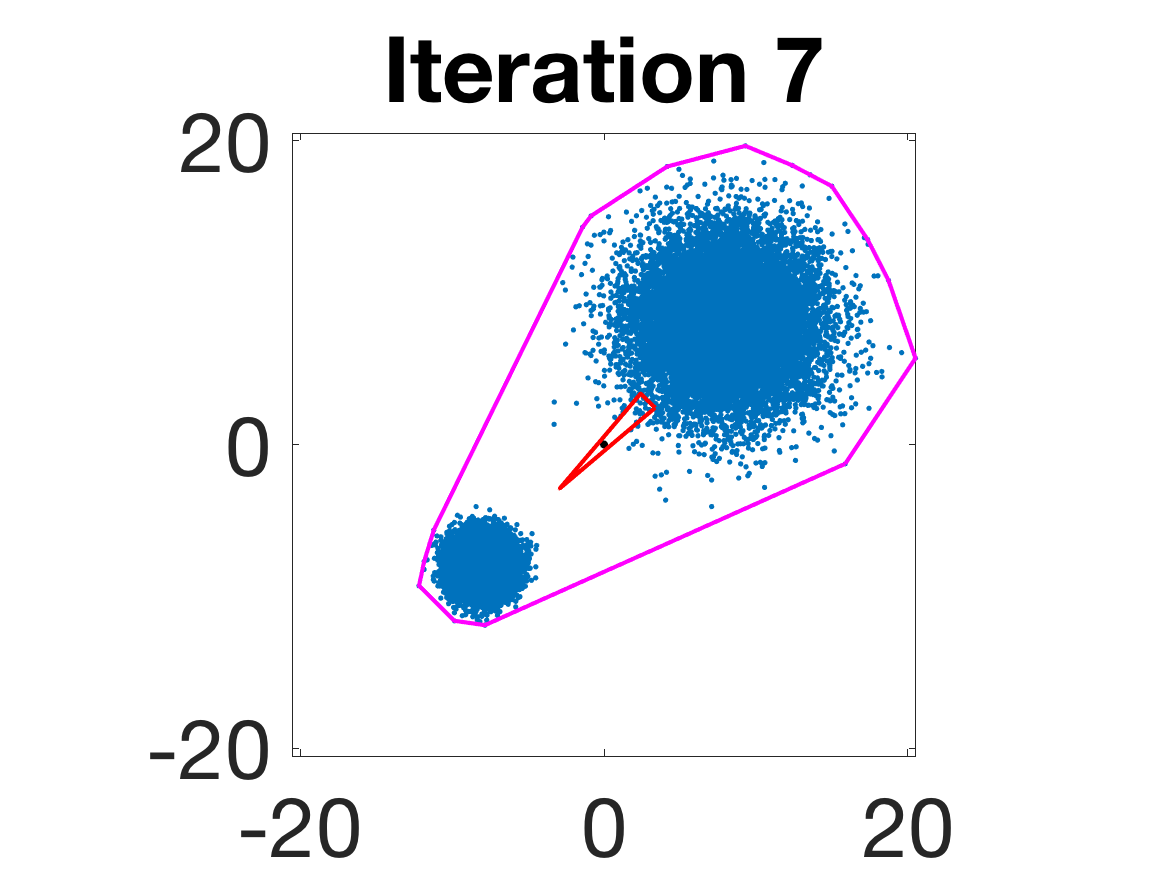
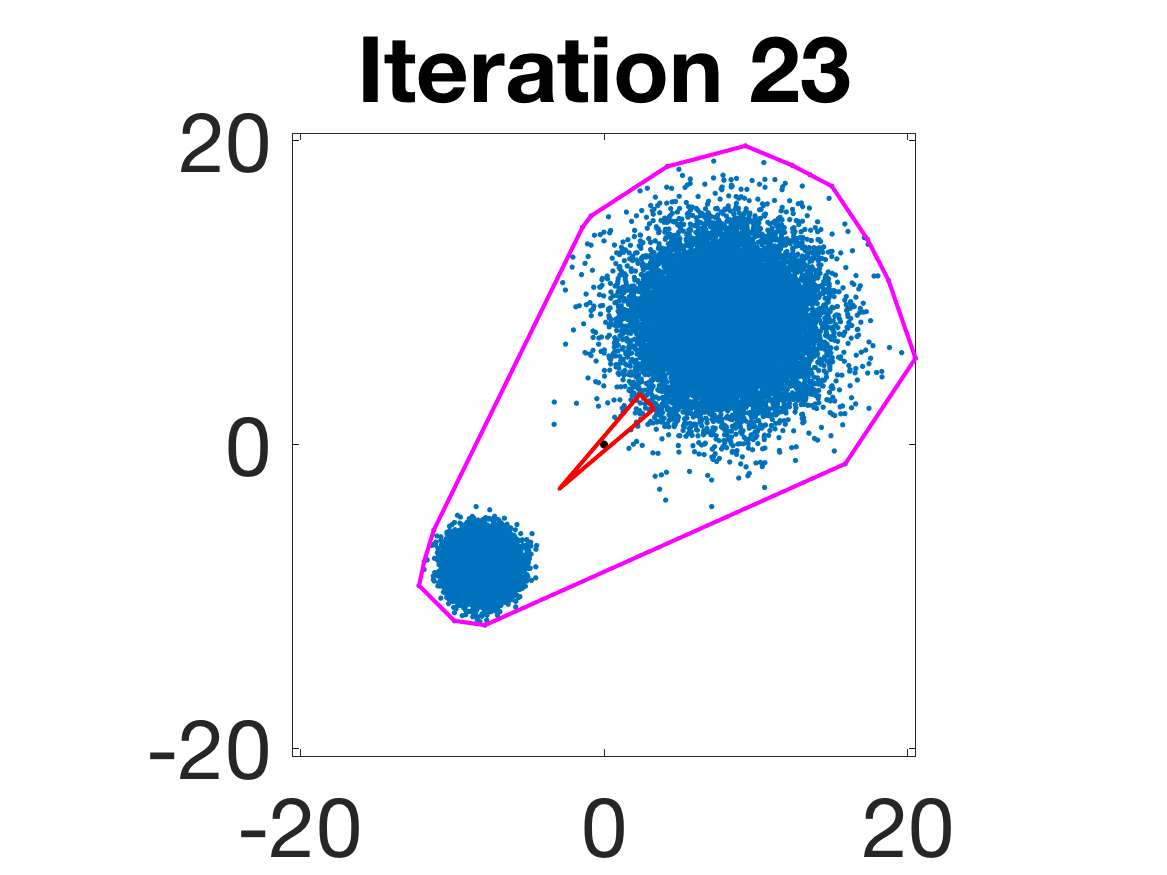
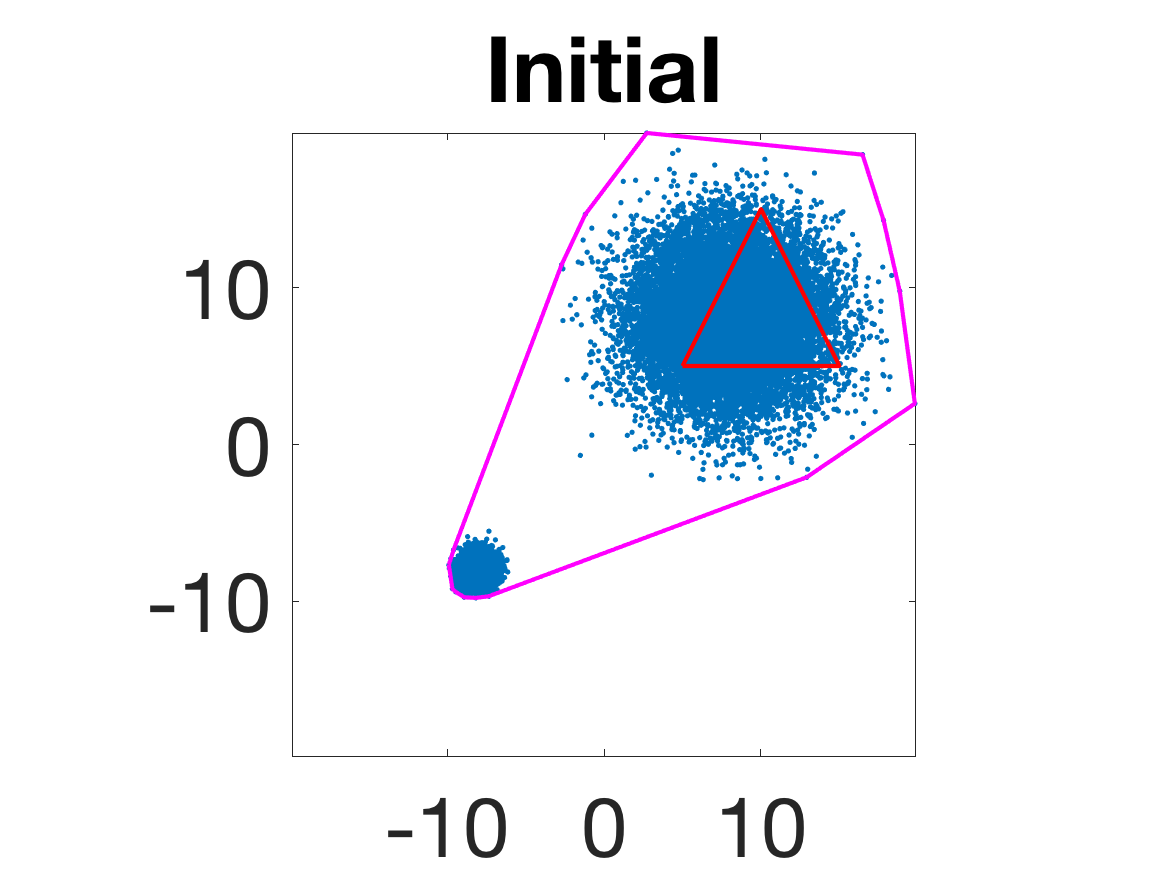
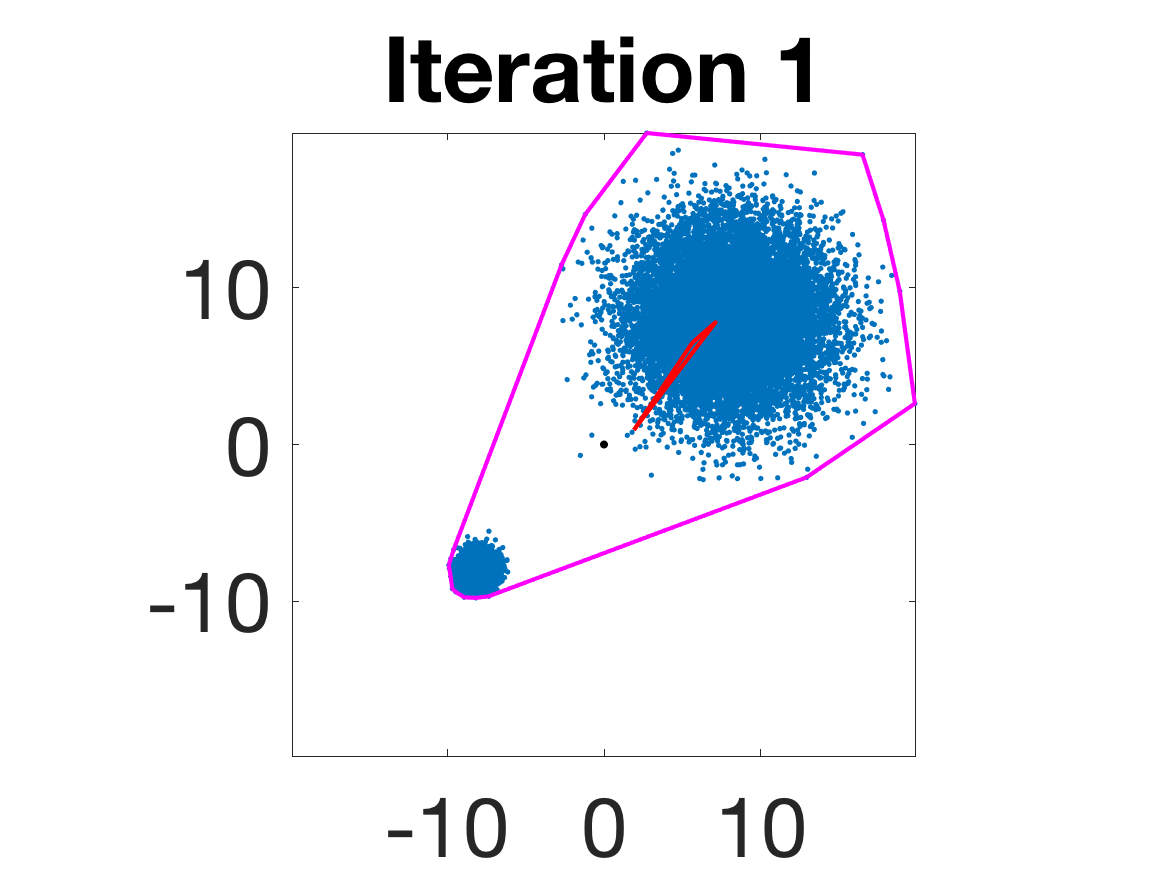
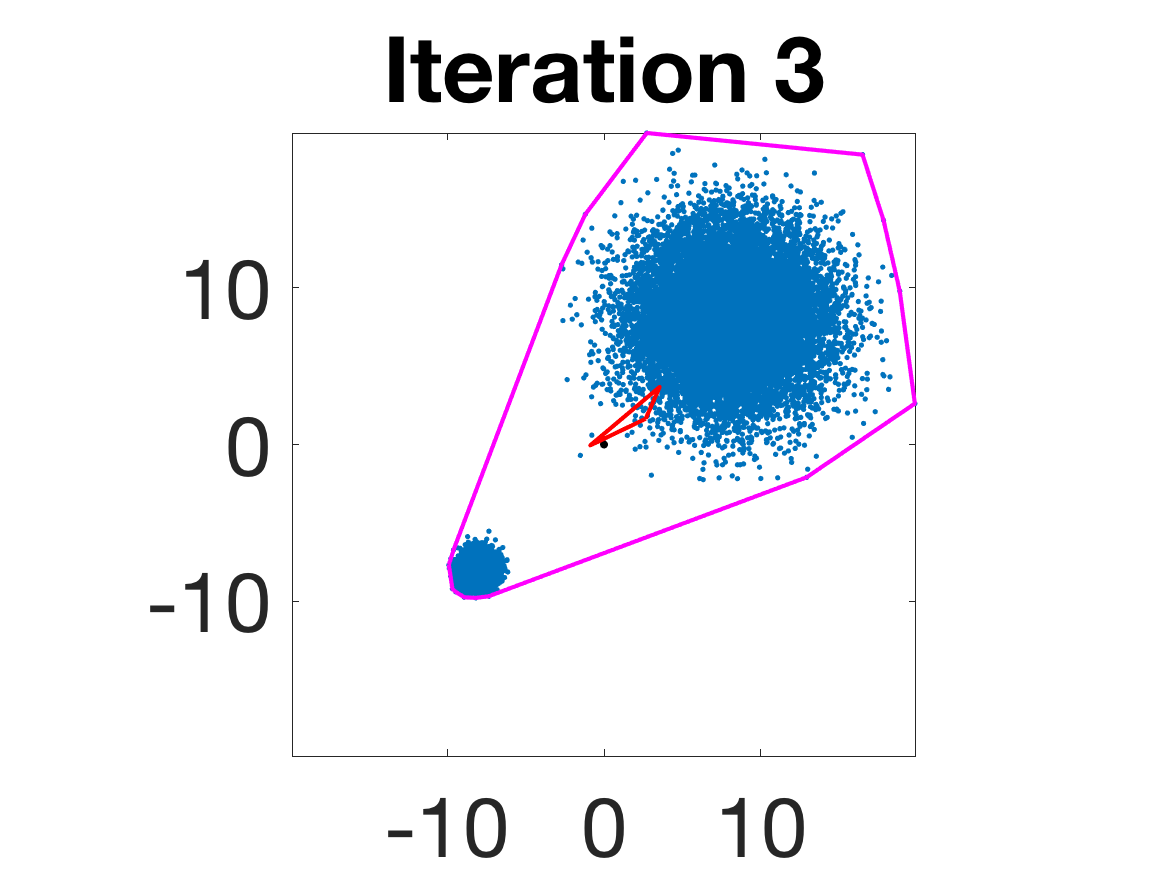
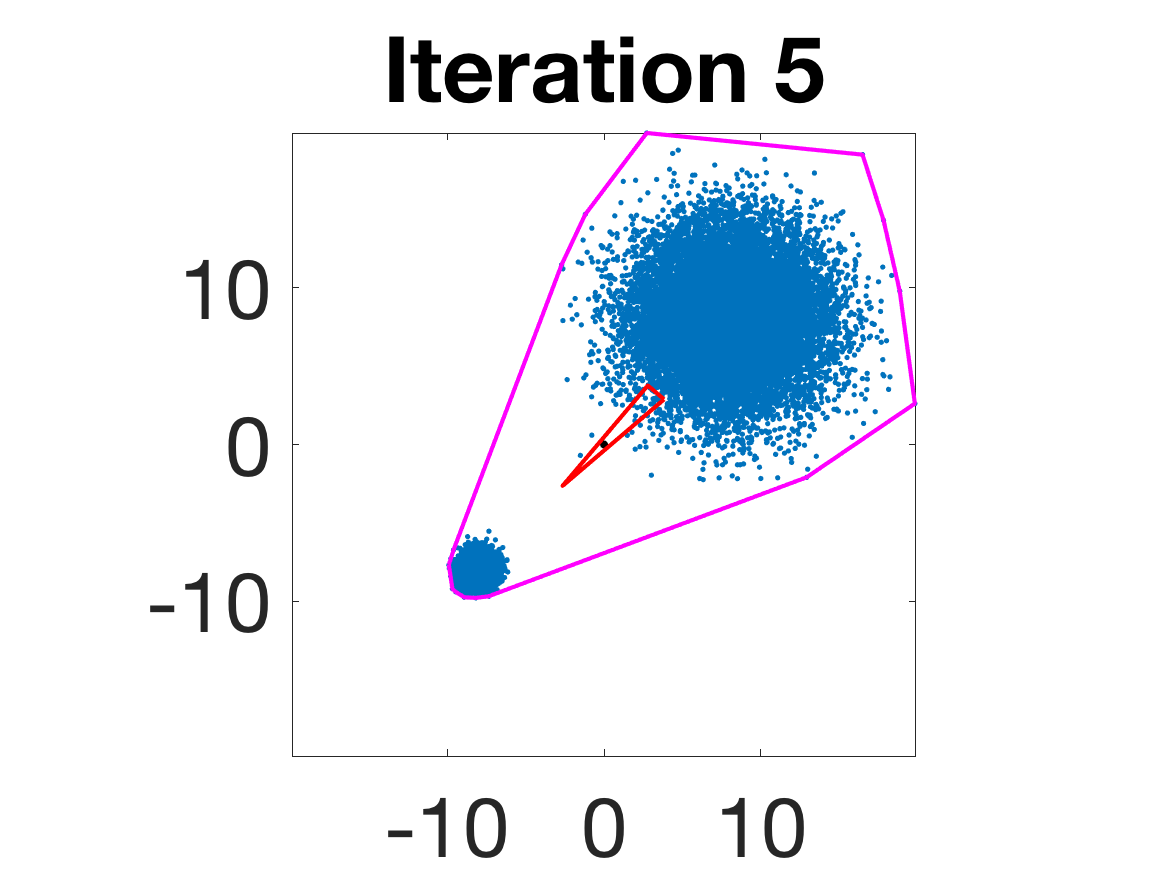
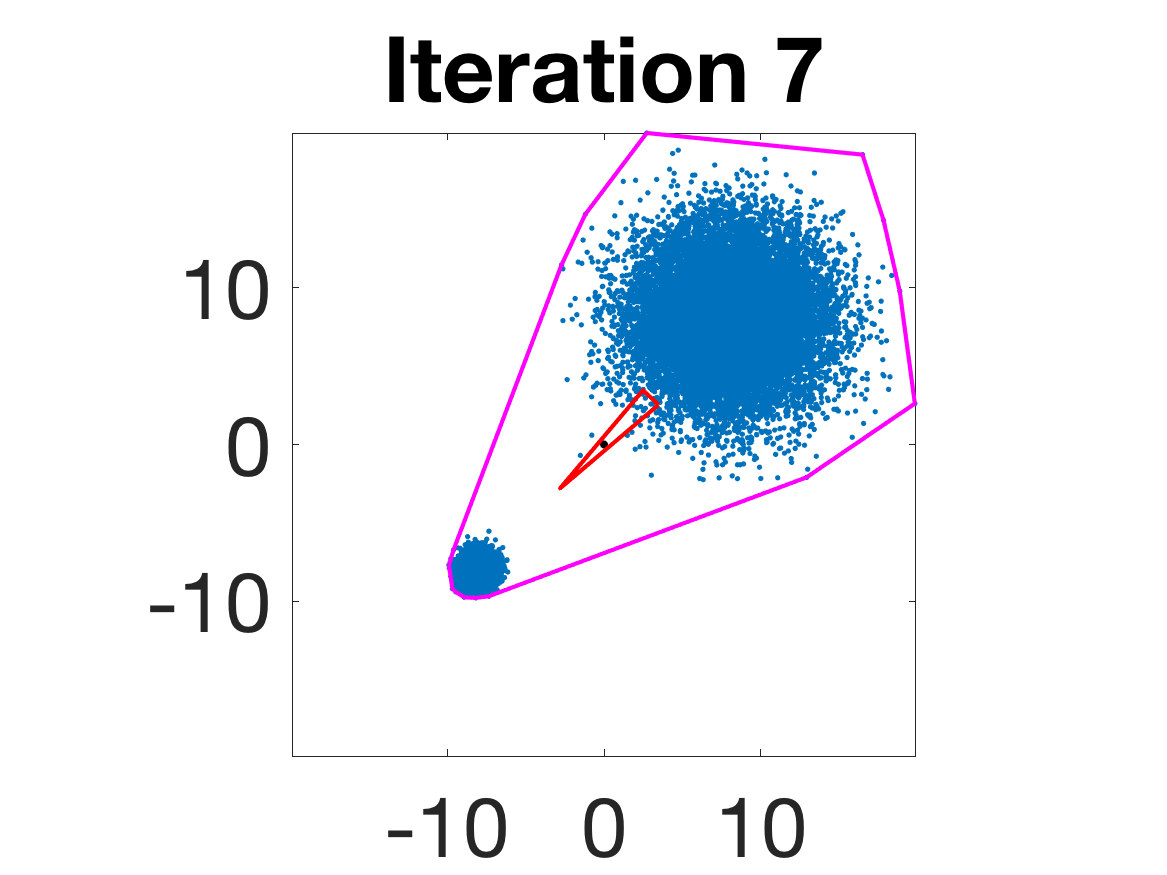
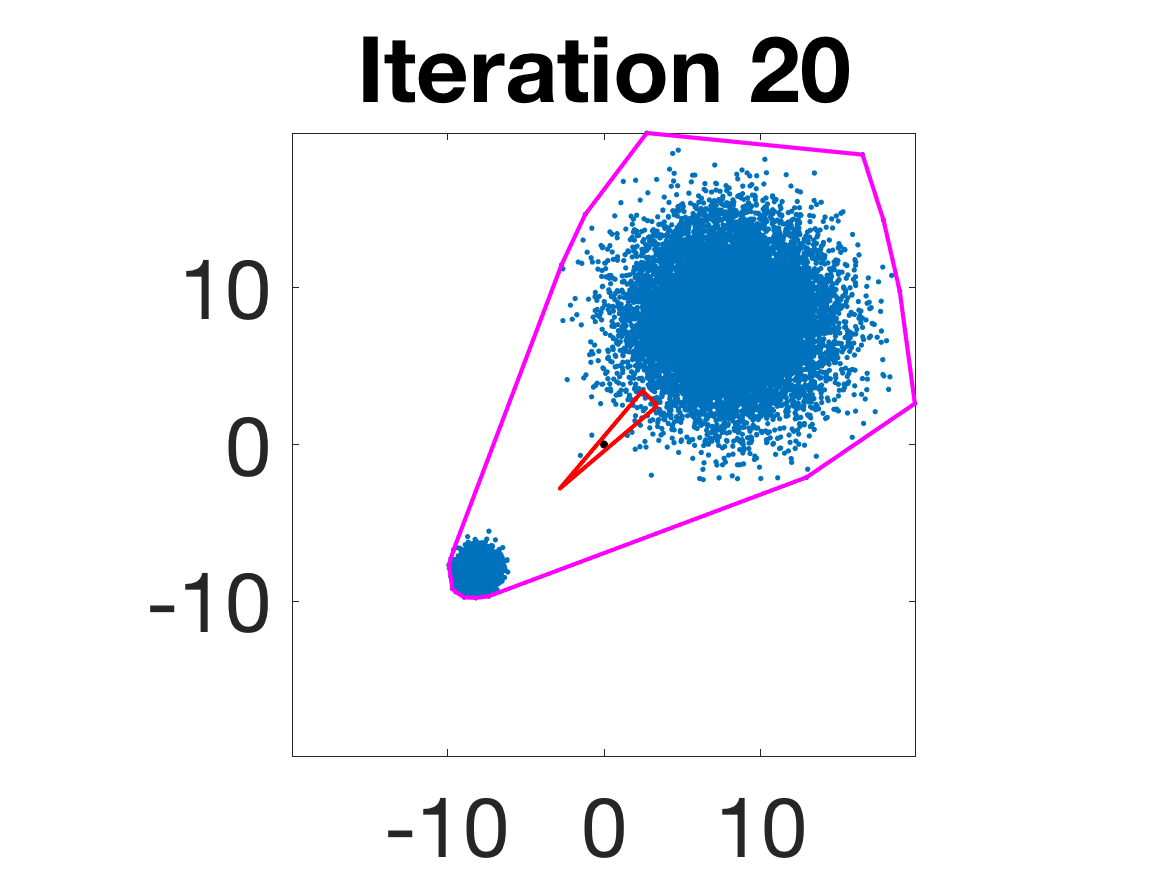
Figure 5: Snapshots of the iterations for different sampled data from a Gaussian mixture model; final iterate contains the global mean.
Implications, Theoretical Impact, and Prospects
The paper establishes strong theoretical foundations for AA, paralleling rigorous results for k-means and other unsupervised clustering methods. It precisely quantifies convergence and rates for AA under realistic sampling assumptions and extends AA to robust, regularized formulations for general distributions. These results imply that in large-scale unsupervised settings, AA provides stable, interpretable extremal summaries of data, provided either compact support or judicious regularization.
The experimental analysis demonstrates practical robustness and scalability of the proposed numerical methods, and the theoretical framework suggests possibilities for further penalty design (including k-means-type and volume penalties), connections to convex geometry, and alternative distance metrics (e.g., Wasserstein).
Future directions include adaptive sampling for efficient computation and extension to nonlinear AA (e.g., neural network-based formulations), as well as rigorous consistency and convergence results for emerging robust AA variants and deep archetypal models.
Conclusion
This work delivers a rigorous statistical analysis of the consistency of archetypal analysis for both compact and noncompact distributions. It provides convergence guarantees, asymptotic rates, and robust regularized approaches supported by empirical evidence. The theoretical results enable AA to serve as a stable unsupervised tool for extremal data summarization, with strong guarantees in diverse settings, and pave the way for innovative forms of data summarization and representation in AI research (2010.08148).


