- The paper presents a controllable TTS model that integrates a prosody encoder to isolate and manipulate key speech features.
- It leverages acoustic features like pitch, duration, and energy to intuitively adjust and diversify speaking styles.
- Objective and subjective evaluations confirm enhanced prosodic expressivity while maintaining the natural quality of synthesized speech.
Controllable Neural Text-to-Speech Synthesis Using Intuitive Prosodic Features
Introduction
The paper "Controllable neural text-to-speech synthesis using intuitive prosodic features" introduces a method for prosody modeling in neural text-to-speech (TTS) systems, which offers the advantage of generating diverse speaking styles while maintaining naturalness. Modern TTS systems can produce speech closely resembling natural speech; however, producing varied prosodic styles has remained a challenge due to limitations in current seq2seq models like Tacotron which tend to average prosodic styles based on training data. This work addresses these limitations by presenting a model that leverages acoustic speech features to predict and control prosodic dimensions effectively, allowing for more intuitive and meaningful variations in prosody.
Model Architecture
The proposed architecture is based on an encoder-decoder model with attention, similar to Tacotron 2 but enhanced by a prosody encoder that forecasts prosodic features such as pitch, pitch range, duration, energy, and spectral tilt. These features are disentangled and independently controllable, providing intuitive manipulations of the prosodic style.
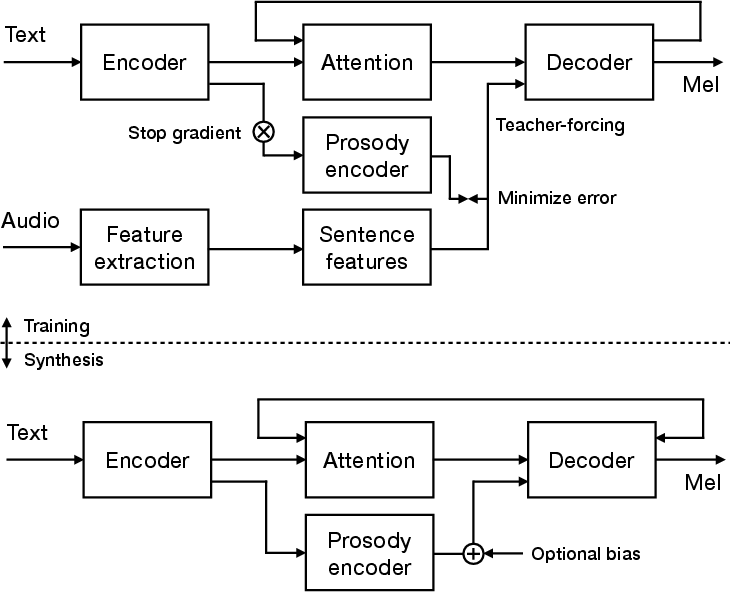
Figure 1: An overview of the proposed prosody modeling encoder-decoder with attention architecture. The model is divided into training and inference phases.
During training, both prosody and text encoders are used to predict ground-truth prosodic features, which are combined with decoder inputs (teacher-forcing). For inference, the prosody encoder generates feature predictions which subsequently condition the decoder output. This configuration accommodates prosody control, allowing modifications through an additional bias mechanism.
Prosodic Features and Their Impact
The prosodic space is defined by features that provide robust and disentangled prosody modeling, which simplifies the correlation between perceived and generated prosody. Acoustic features are extracted using established methods such as automatic speech recognition for phone durations, spectral tilt for voice quality, and combining multiple pitch tariffs for precise pitch estimations. Data normalization ensures that feature values are confined to a consistent range, facilitating the mapping between intended and realized prosody.
The prosodic model predicts features directly from text, suggesting that provided with suitable data, the system can synthesize text with appropriately contextual prosody.
Experimental Evaluation
The experiments involve three-system comparison: baseline Tacotron, and two versions of the prosody control model using different datasets to illustrate performance in capturing and controlling prosodic aspects. Objective assessment showed good correspondence between target and realized prosody across dimensions.
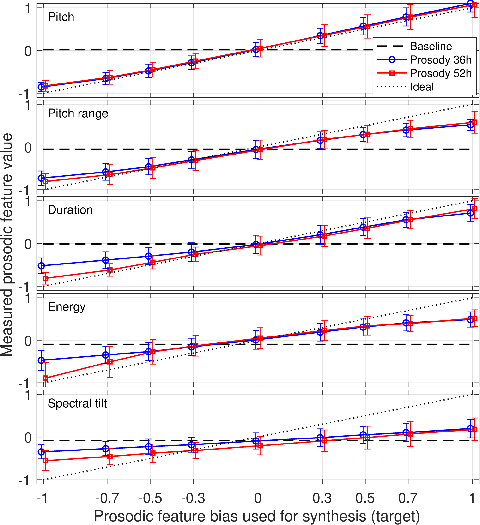
Figure 2: Means and standard deviations of the measured prosodic features with respect to target bias values.
Subjective tests using MOS confirmed similar quality across systems, though the baseline outperformed in AB tests due to simpler prosody prediction mechanisms. Despite the reported degradation at the prosody feature extremes, particularly for systems trained with broader voice coverage, prosody-modified synthesis versions were preferred in real use cases, demonstrating practical enhancement in prosodic expressivity.
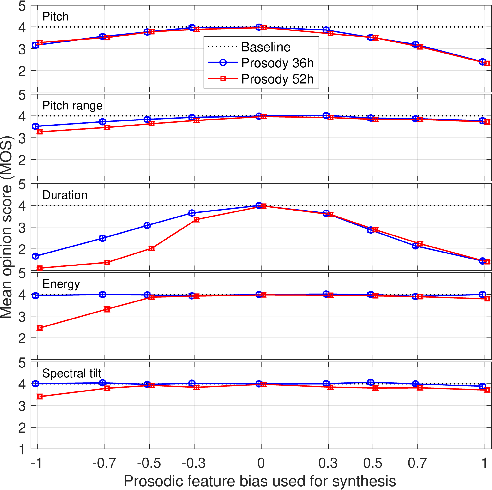
Figure 3: Means and 95\% confidence intervals of MOS measured over all features and target bias values.
Discussion
The proposed model excels at generating various speaking styles, enhancing synthetic speech's prosodic control. The architecture ensures substantial coverage of prosodic dimensions and independence from acoustic nuisances, providing a holistic synthesis with controllable attributes. Challenges mainly stem from achieving finer-grained control, currently only viable at sentence level, opening pathways for future explorations in cascade generation approaches or finer grain decoder-level interventions.
Conclusions
This research proposes a competent neural TTS system equipped for intuitive prosody control, evidenced to generate speech maintaining a balance of quality and versatility in prosodic variation. The model reveals significant advancements towards automatic prosody synthesis crucial for applications where speech expressivity and nuance are paramount, opening further exploration avenues in synchronized text-to-speech modeling and enhanced user experience improvements.

