- The paper introduces a novel inverse framework that extracts drum physical parameters using PDE-based modeling, scattering transforms, and CNN regression.
- It leverages time–frequency scattering to capture stable, higher-order modulations critical for delineating membrane vibration characteristics.
- Experimental results confirm robust parameter estimation and audio reconstruction, enabling continuous, physically informed sound synthesis.
wav2shape: Reconstruction and Identification of Drum Physical Parameters from Audio
Context and Motivation
The challenge of inferring physical attributes—such as membrane shape, modal parameters, and damping—from audio recordings is central in musical acoustics and digital audio synthesis. Existing drum transcription approaches are largely taxonomic, segmenting percussive sounds into discrete classes and overlooking the rich continuous variability caused by instrument geometry and playing technique. This limits both MIR capabilities and generative synthesis accuracy. The "wav2shape: Hearing the Shape of a Drum Machine" (2007.10299) paper develops a principled inverse framework that marries PDE-based physical modeling, feature engineering via scattering transforms, and supervised representation learning to estimate physically interpretable parameters of drum sounds from audio samples.

Figure 1: Diverse drums spanning cultures and centuries, illustrating the geometric and material variation that underpins timbral diversity.
Physical Modeling of Drum Sound Synthesis
The work formalizes membrane vibration as a fourth-order PDE with resonant (wave speed, stiffness) and dissipative (air drag, boundary coupling) terms. The solution is obtained via the Functional Transformation Method (FTM), yielding a modal representation whose coefficients directly encode physical shape and material properties: fundamental frequency (ω), sustain (τ), frequency-dependent damping (p), inharmonicity (D), and aspect ratio (α). These parameters enable fine-grained synthesis with transparent physical control.
The authors implement a real-time VST plugin utilizing this parametric model. User-controllable GUI elements (Figure 2) map directly to the latent physical parameters, facilitating intuitive exploration of drum timbres.

Figure 2: wav2shape real-time VST plugin GUI, exposing physically interpretable controls (e.g., sustain, roundness, inharmonicity).
Standard descriptors (MFCC, CQT) fail to robustly encode nonstationary percussive signals. Instead, the paper leverages the scattering transform—a cascade of wavelet modulus and averaging operations—which yields features that are stable to deformation, invariant to affine transforms (e.g., gain, bias), and capable of demodulating fast phase variation inherent to drum attacks. Second-order coefficients, in particular, capture higher-order spectrotemporal modulations critical for distinguishing membrane physics.
Regression Architecture: Deep Convolutional Network
Scattering coefficients are log-transformed and provided as input to a 1D CNN (wav2shape) comprising four convolutional blocks followed by fully connected layers. The network is trained using Adam with MSE loss to estimate the 5D vector of physical parameters from audio samples. Hyperparameters for scattering scale (J) and order (N) are extensively tuned.
Experiments demonstrate that second-order (N=2) scattering coupled with J=8, ε=10−3 scaling achieves superior regression accuracy. Validation loss is an order of magnitude lower (~0.013) than uniform random guessing in the normalized parameter space (0.87), confirming effective generalization beyond the training set. The distribution of regression errors by parameter reveals best performance for ω and τ, with diminished precision for D and p, attributable to modal truncation and physical influence profiles.
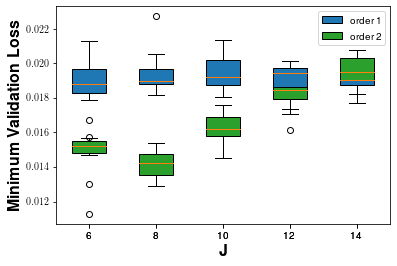
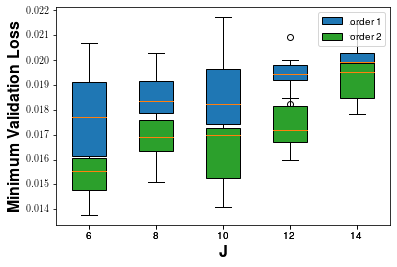
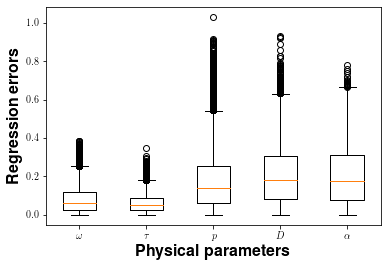
Figure 3: Training curves and regression error breakdown over physical parameters under different scattering hyperparameters.
Stroke Location Interpolation and Feature Linearization
Evaluating the system's ability to generalize to off-center drum strokes, scattering coefficients are linearly interpolated over the membrane surface. Heatmaps of Laplacian norms (Figure 4) demonstrate that the scattering domain is approximately locally linear with respect to excitation location—an improvement over the Fourier modulus domain—facilitating transfer beyond the central stroke regime.
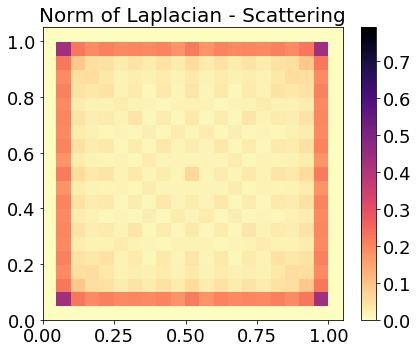
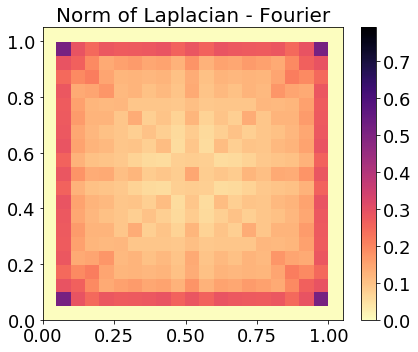
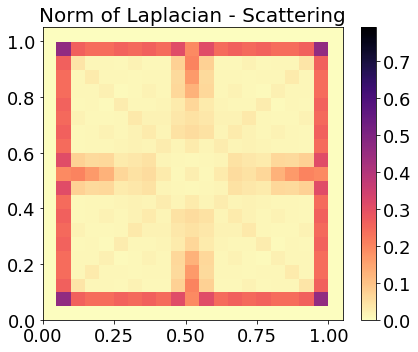
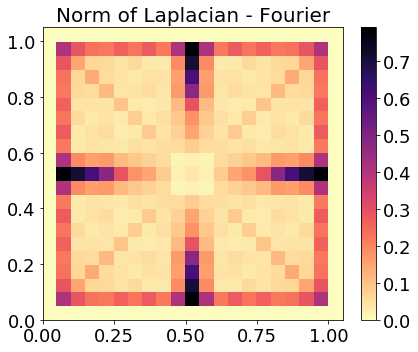
Figure 4: Laplacian heatmaps comparing scattering and Fourier features; scattering exhibits reduced curvature and higher fidelity for interpolated sound localization.
Regression accuracy on interpolated scattering features, though lower than direct synthesis, remains substantially better than chance, suggesting the network's learned mapping is robust to moderate spatial variance.
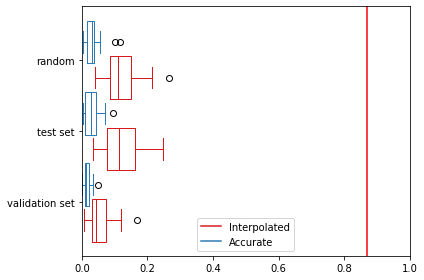
Figure 5: Prediction error distributions for synthesized and interpolated scattering features across dataset splits.
Inversion: Audio Reconstruction from Scattering Representations
The paper advances beyond parameter estimation by reconstructing time-domain audio from scattering features using gradient-based optimization (reverse-mode autodiff in PyTorch/Kymatio). Reconstruction quality is controlled by scattering scale and order: deeper (order 2) representations enable sharper and less artifact-prone audio, particularly for larger time-averaging scales. This paves the way for transforming wav2shape from a discriminative regression model to a generative audio model controllable via interpretable physics.
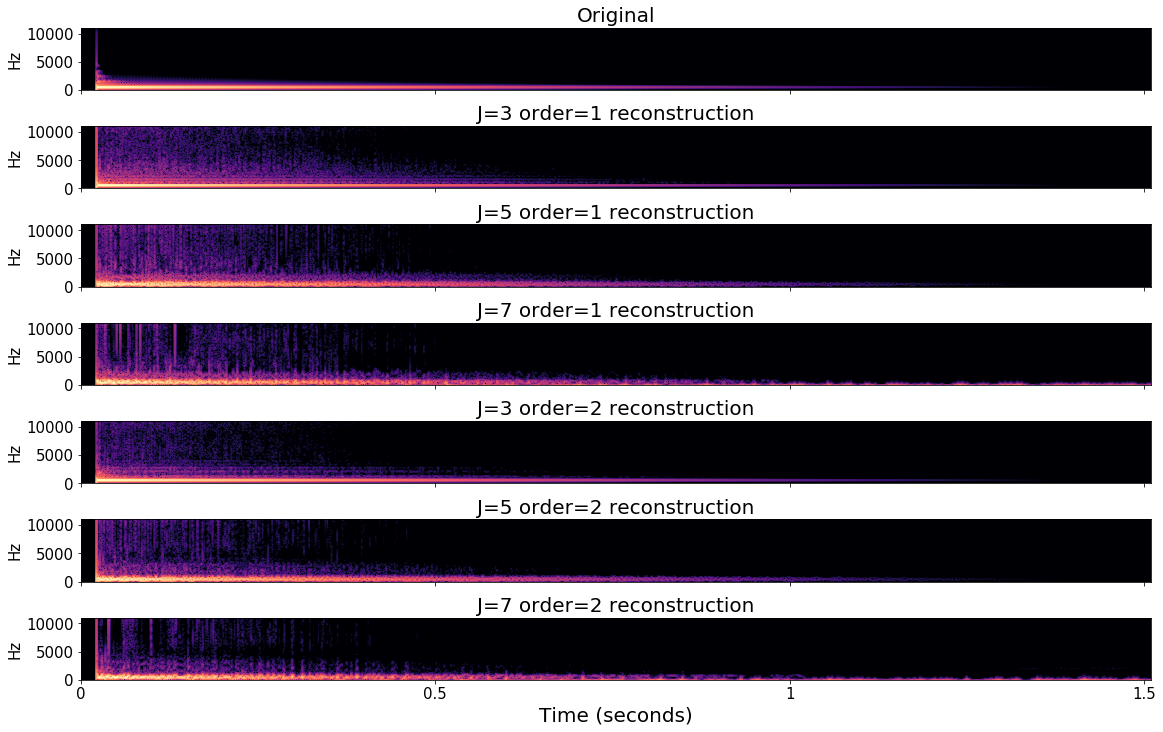
Figure 6: Spectrograms of original and reconstructed drum sounds from first and second-order scattering features at varying scales, exhibiting trade-offs between sharpness and invariance.
Implications and Future Directions
Practically, wav2shape enables physically informed audio synthesis, sound classification, and model-based MIR tasks with a high degree of expressive control. Theoretically, this work substantiates the utility of scattering representations for bridging nonlinear physical acoustics and deep learning. The demonstrated robustness to off-center strokes implies the potential extensibility to arbitrary playing technique, though interpolation error remains a limiting factor.
Critical challenges for future research include:
- Enhancing regression fidelity for inharmonicity and geometric shape parameters across modes.
- Addressing generalization limitations for arbitrary stroke locations and drum geometries (e.g., circular).
- Reducing reliance on large simulated datasets via sim2real transfer, potentially leveraging unsupervised or reinforcement learning paradigms.
- Integrating scattering-based generative audio models (GANs, inverse networks) for physically interpretable audio synthesis in production environments.
Conclusion
wav2shape (2007.10299) comprises a robust framework for the supervised recovery of physically meaningful drum shape parameters from audio, leveraging scattering transforms and deep neural architectures. Its ability to generalize across a physically simulated parameter space and reconstruct time-domain audio from interpretable features underscores the utility of hybrid physical–data-driven modeling in musical acoustics. The approach opens avenues for continuous, physically grounded control of percussive sound synthesis, and motivates future integration of physical modeling with advanced generative and learning methodologies in both research and applied audio technology contexts.