- The paper introduces a deep multimodal framework that jointly learns visual and textual representations using a CNN and LSTM integration.
- It employs a hinge-based triplet ranking loss to effectively align image-text pairs, demonstrating improved recall@K and median rank on benchmarks.
- Experimental evaluation on a novel Twitter dataset highlights the model’s robustness and adaptability for real-world cross-media retrieval.
Deep Multimodal Image-Text Embeddings for Automatic Cross-Media Retrieval
Introduction
The integration of social networking platforms with artificial intelligence has created vast opportunities for cross-media retrieval tasks, namely image-text matching. This research focuses on learning a visual-textual embedding space capable of matching images with corresponding sentences, utilizing a deep learning framework specifically designed for simultaneous vision and language representation learning. The objective of the study is to develop a model that effectively bridges the semantic gap between image and text modalities, thereby enhancing image-text similarity inference capabilities.
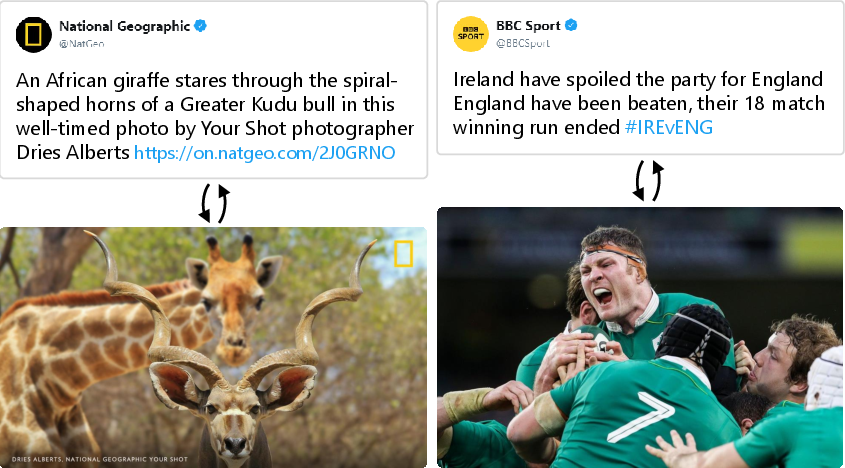
Figure 1: Motivation/Concept Figure: Given an image as input, the automatic retrieval of the closest textual description demonstrates the dataset's application.
Model Architecture
The paper introduces a multimodal neural network composed of a convolutional neural network (CNN) and a long short-term memory (LSTM) network, supplemented by fully-connected layers. This architecture facilitates the simultaneous learning of both vision and language representations. The network's two primary components are designed to transform visual and textual data into a shared feature space, enabling efficient cross-modal matching.
Image Representation: The image subnet leverages a modified ResNet-50, pre-trained on ImageNet, as the feature extractor, followed by a dense layer adapting the image features to align with text domain dimensions. This results in a robust visual feature vector, which is subsequently transformed via fully-connected layers into the shared embedding space.
Text Representation: Textual data is processed through a custom pipeline, starting with stemming and tokenization, followed by one-hot encoding. The LSTM then captures semantic features from the text input, ultimately converting them into feature vectors compatible with the shared embedding space.
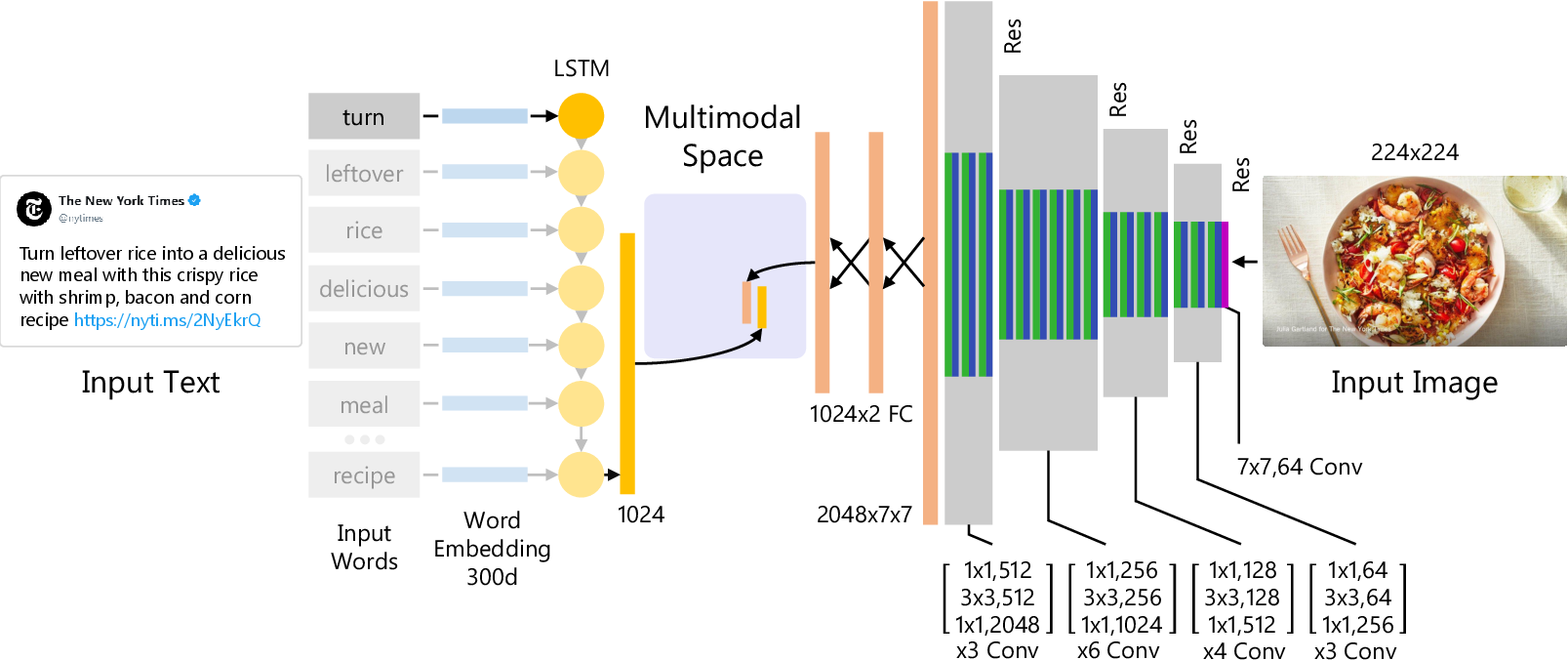
Figure 2: Proposed end-to-end multimodal neural network architecture for learning the image and text representations.
Alignment Objective
The training process involves optimizing the image-text similarity using a hinge-based triplet ranking loss. The loss function is structured to encourage close proximity of correct image-text pairs within the embedding space while penalizing mismatched pairs. This approach ensures a reliable separation between positive and negative examples.
Experimental Evaluation
The model was tested against established benchmarks like MS-COCO to validate its efficacy and generalization across datasets. Extensive experimentation demonstrated that the proposed framework yields competitive results, surpassing several prior methods in sentence and image retrieval tasks. Recall@K and Median Rank metrics were employed to quantify retrieval accuracy, further highlighting the framework's effectiveness.
Data Collection
A novel dataset composed of tweets paired with images was collected from Twitter, presenting unique challenges due to the informal and varied nature of social media text. This dataset proved instrumental in demonstrating the model's robustness and adaptability to real-world image-text matching scenarios.
Conclusion
The paper successfully introduces a sophisticated multimodal architecture for image-text embedding and retrieval, contributing significant advancements to cross-media retrieval methodologies. The introduction of a new, diverse dataset further strengthens the application potential of the model. Future research may explore enhancements in multimodal embeddings and broader applications across different linguistic domains and real-world datasets.