- The paper introduces ERE, a novel method that emphasizes recent experience in SAC to significantly boost sample efficiency.
- It employs a dynamic sampling strategy modulated by a parameter η to balance recent and historical data without leading to overfitting.
- Comparative analysis shows that SAC+ERE and SAC+ERE+PER achieve faster learning rates while maintaining robustness in continuous-action environments.
Boosting Soft Actor-Critic with Emphasizing Recent Experience
Introduction
Soft Actor-Critic (SAC) has set a benchmark in continuous-action deep reinforcement learning (DRL) by successfully leveraging maximum entropy reinforcement learning principles to improve exploration and robustness. Despite its promising outcomes, SAC utilizes a uniform sampling technique from the replay buffer which does not prioritize the importance of recent experiences. This oversight may result in function approximators that do not optimally focus on the regions of state-action space where the current policy operates. The paper introduces a novel method named Emphasizing Recent Experience (ERE) to address this disparity, providing a refined off-policy sampling technique that emphasizes recent data while preserving historical information.
Advances in Experience Replay
Experience replay serves as an integral component of off-policy DRL algorithms, enabling the efficient utilization of past experiences. Standard methods sample experiences uniformly from a replay buffer, yet prioritized experience replay (PER) has demonstrated improved performance by sampling based on the temporal-difference error. Further innovations include ACER, which combines on-policy and off-policy updates, and RACER, which selectively removes less impactful experiences. ERE methodology offers a straightforward yet powerful adjustment to SAC, incorporating recent experiences aggressively while ensuring updates are sequenced to prevent overwriting new data with outdated information.
Emphasizing Recent Experience in SAC
ERE introduces a dynamic sampling strategy within SAC by weighting recent data more heavily during updates, gradually narrowing the sampling range throughout a mini-batch sequence. This formulation inherently emphasizes data from regions of the state-action space recently explored by the policy, enhancing the sample efficiency and learning speed especially in initial training stages.
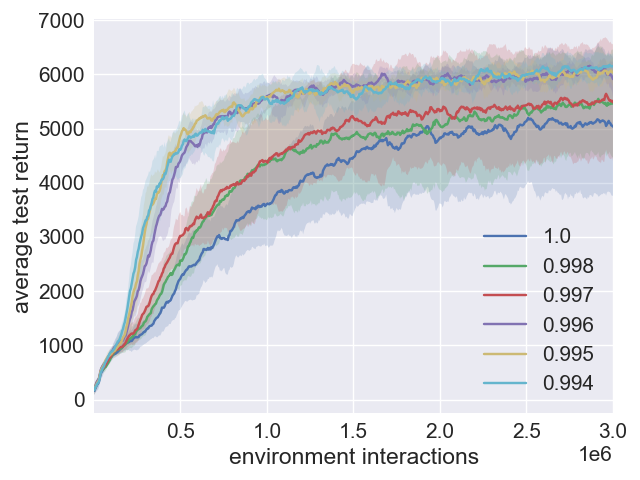
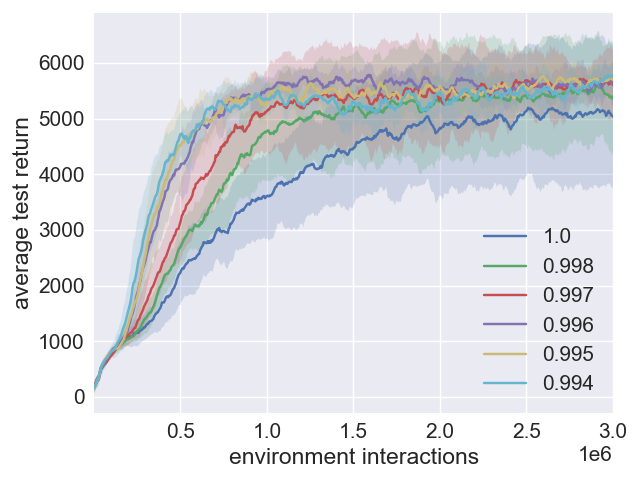
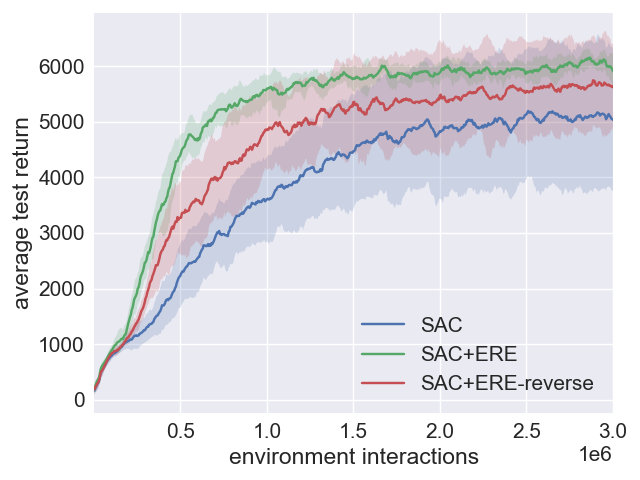
Figure 1: Comparison plots illustrating the impact of SAC+ERE with varying η values.
The parameter η dictates the sampling emphasis, offering flexibility based on the agent's learning speed. To prevent overfitting from overly recent data, this parameter is modulated over time to eventually align with uniform sampling. Combined with the annealing process, SAC+ERE shows significant advancements in sample efficiency and maintains the robustness traditionally associated with SAC.
Comparative Analysis with PER Variants
When integrated with PER, SAC+ERE+PER combines emphasis on recent experiences with PER's error-based prioritization, often achieving superior initial learning rates. Although SAC+PER alone exhibits inconsistent outcomes across different environments due to more complex hyperparameter optimization requirements, SAC+ERE+PER demonstrates potential for enhanced performance in certain scenarios by bridging the advantages of both approaches.
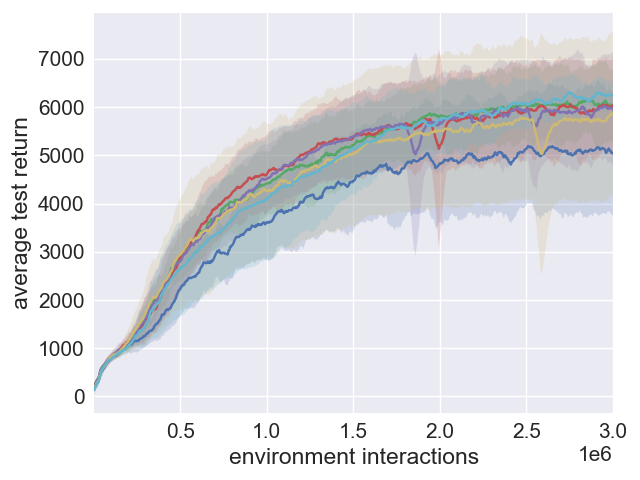
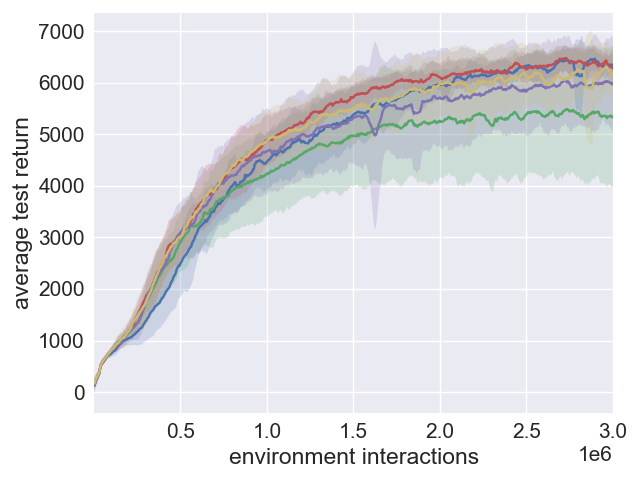
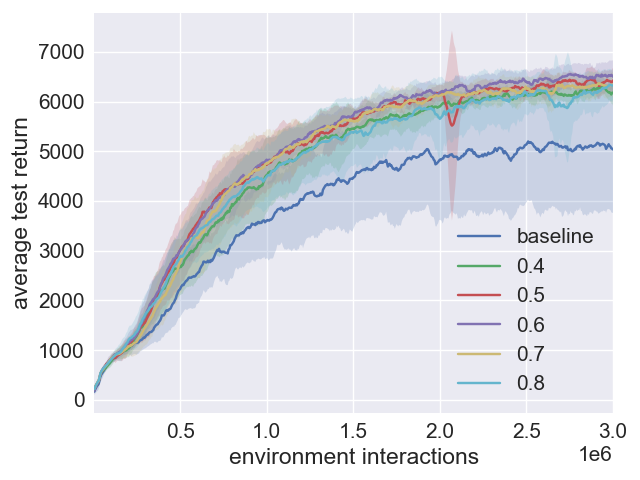
Figure 2: Performance effects of beta values in SAC+PER configurations.
Despite the implementation and computational overhead associated with PER, ERE remains computationally lightweight and simple to incorporate, making it an attractive enhancement for SAC and potentially other off-policy algorithms.
Practical and Theoretical Implications
The paper’s propositions carry profound implications for DRL. Practically, ERE offers a method to significantly boost learning efficiency in SAC without compromising on robustness—a critical feature for various continuous-action environments. This methodological improvement extends to broader applications across off-policy DRL algorithms, hinting at improved sample efficiency in diverse environments beyond Mujoco. Theoretically, understanding and refining sampling strategies in experience replay buffer management will continue to shape the future trajectory of reinforcement learning, prompting further exploration into hybrid strategies like SAC+ERE+PER.
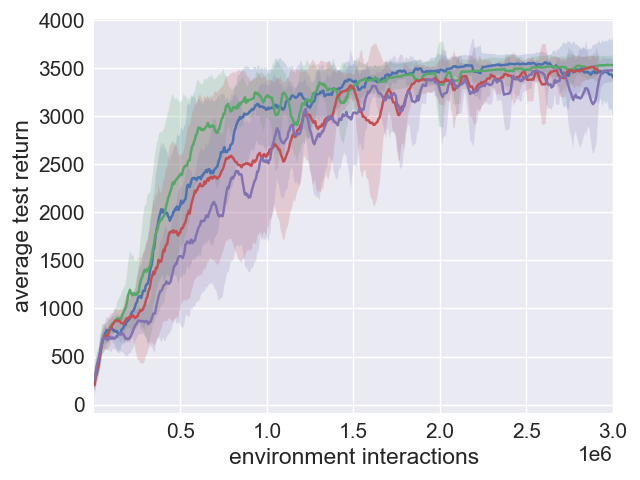
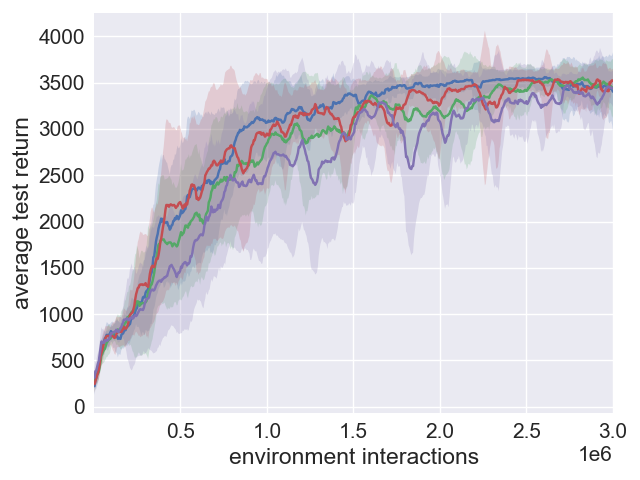
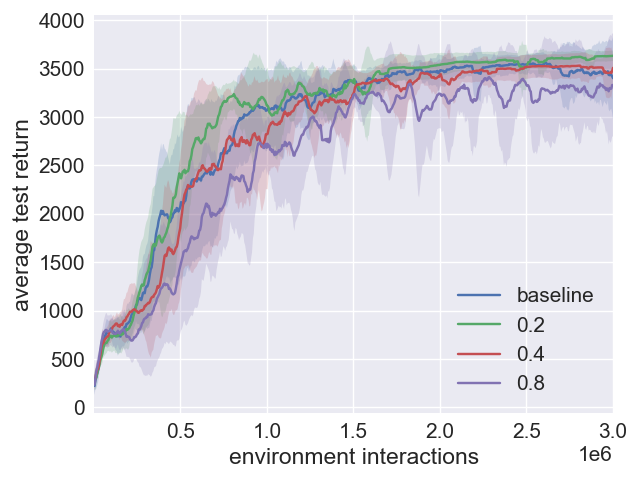
Figure 3: Analysis of performance robustness in SAC and SAC+ERE.
Conclusion
"Boosting Soft Actor-Critic: Emphasizing Recent Experience without Forgetting the Past" effectively leverages recent advances in experience replay to refine and enhance the SAC algorithm. Through intelligent sampling strategies, ERE significantly elevates learning efficiency while preserving model reliability, establishing a foundation for further exploration in experience replay dynamics within DRL frameworks. As research progresses, these insights contribute to optimizing reinforcement learning algorithms for a wider array of complex tasks and environments.


