- The paper introduces an end-to-end neural network that learns a digital camera pipeline to restore well-exposed sRGB images from extremely low-light RAW data.
- It employs a U-net with skip connections and a novel multi-criterion loss function balancing pixel-level and perceptual features for superior image quality.
- Experiments on the SID dataset show the method outperforms state-of-the-art approaches with enhanced sharpness, accurate color reproduction, and reduced noise.
Learning Digital Camera Pipeline for Extreme Low-Light Imaging
Introduction
The paper "Learning Digital Camera Pipeline for Extreme Low-Light Imaging" (1904.05939) addresses the challenge of enhancing image quality captured under low-light conditions using a sophisticated data-driven approach. Conventional camera pipelines render sub-optimal images in dark environments due to limited light exposure, resulting in amplified noise and color discrepancies. Accordingly, the authors propose a novel deep learning strategy coupled with a tailored loss function to rectify these deficiencies by transforming low-light RAW image data into well-exposed sRGB images.




Figure 1: Transforming a short-exposure RAW image captured in extremely low light to a well-exposed sRGB image.
Methodology
The core of the proposed method is an end-to-end neural network designed to replace the traditional imaging pipeline. This approach leverages a novel multi-criterion loss function that balances pixel-level and feature-level metrics to produce visually appealing outputs. The algorithm utilizes an encoder-decoder architecture with skip connections, enabling effective learning and preservation of high-frequency image details. Specifically, the network employs a U-net design to facilitate this process, processing the RAW sensor data directly instead of the conventional RGB inputs for superior outcomes.
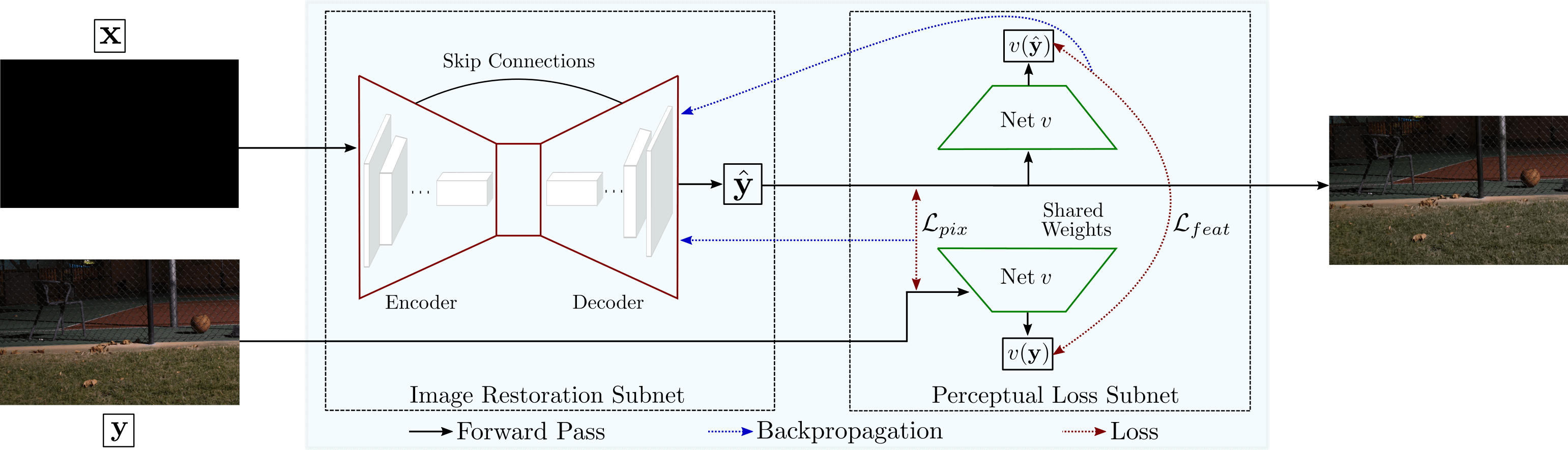
Figure 2: Schematic of our framework. Given as input the RAW sensor data x captured in extremely low ambient light, the image restoration subnet learns the digital camera pipeline and generates a well-exposed sRGB image $\hat{\mathbf{y}$. The perceptual loss subnet forces the image restoration subnet to produce an output as perceptually similar as possible to the reference image y.
Experiments and Results
The authors validate their method using the See-in-the-Dark (SID) dataset, which includes images captured with different cameras under extremely low-light conditions. The results demonstrate that the proposed network significantly outperforms existing methods, including those by Chen et al., both qualitatively and quantitatively. The reconstructed images are sharper, more accurate in color reproduction, and notably devoid of noise and artifacts.

Figure 3: Some sample images from the See-in-the-Dark (SID) dataset \cite{Chen2018}: long-exposure ground truth images (in front), and short-exposure and essentially black input images (in background).
The research also includes a comprehensive psychophysical evaluation involving expert and naive observers, showing a strong preference for images processed by the proposed algorithm over competitive methods. This preference aligns with quantitative assessments using metrics such as PSNR, LPIPS, and PieAPP, where the proposed approach exhibits superior performance.



Figure 4: Qualitative comparison of our approach with the state-of-the-art method \cite{Chen2018} and the traditional pipeline.
Discussion
The capabilities of the proposed pipeline extend beyond merely enhancing image brightness. By exploiting a hybrid loss formulation, it effectively handles color fidelity and texture details, addressing shortcomings inherent in traditional pipelines and previous deep learning approaches. The research demonstrates that combining pixel-level and high-level perceptual cues allows for the creation of images that are not only comparable to human visual preferences but are also structurally accurate and aesthetically pleasing.
Future Work
Looking forward, the authors suggest potential expansions of this work could explore further refinement of the loss function and incorporation of additional datasets representing various low-light conditions. Such developments could refine the model's generalizability across different hardware and capture settings, enhancing its application scope within the field of computational photography and related visual processes.
Conclusion
In conclusion, this research represents a significant step in advancing the capabilities of neural networks in the domain of low-light image processing. By learning and optimizing an entire digital camera pipeline, the proposed framework achieves superior image restorations, providing a robust solution to the inherent limitations faced by traditional imaging systems in challenging lighting environments.

