- The paper demonstrates that applying SR methods significantly boosts object detection accuracy with improved mAP scores at finer resolutions.
- It integrates VDSR and RFSR with YOLT and SSD frameworks, highlighting distinct benefits in computational efficiency and detection performance.
- The study underscores practical cost-effective solutions by enhancing the detection of vehicles, planes, and boats in high-resolution satellite images.
The paper "The Effects of Super-Resolution on Object Detection Performance in Satellite Imagery" investigates the impact of super-resolution (SR) techniques on the performance of object detection algorithms applied to satellite imagery. It proposes a thorough study involving SR methods such as Very Deep Super-Resolution (VDSR) and Random Forest Super-Resolution (RFSR) in conjunction with object detection frameworks like YOLT and SSD. The primary focus is on enhancing the resolution of satellite images to gauge improvements in detecting various objects like vehicles, planes, and boats.
Introduction and Motivation
Super-resolution aims to augment low-resolution images to a higher resolution, often hypothesized to improve the detection of small objects in challenging satellite imagery due to increased distinguishable features. This paper explores whether augmentation beyond native resolution enhances object detection accuracy. Given the high costs associated with satellites, the study speculates on the cost-effectiveness of coupling SR algorithms with smaller satellites that capture coarser resolutions.
Super-Resolution Techniques
VDSR and RFSR Approaches
VDSR, known for its deep convolutional neural network architecture, significantly increases image resolution by transforming low-resolution features into high-resolution outputs using a residual image learning approach. RFSR, on the other hand, is a custom ensemble method leveraging random forest regressors, offering computational simplicity with high inference speeds.

Figure 1: Examples of 15 cm GSD super-resolved output from RFSR and VDSR versus the original 30 cm GSD native imagery.
Training VDSR requires augmented patches from YCbCr-converted images, while RFSR utilizes a residual schema involving shift-based normalization for robust edge enhancement. The paper records substantial training times for VDSR on GPU, contrasting with the CPU-based training efficiency of RFSR.

Figure 2: Ground truth 30 cm imagery (right), and simulated 60 cm input imagery (left).
Object Detection Framework
SIMRDWN Integration
YOLT and SSD models within the SIMRDWN framework facilitate rapid object detection across large-scale satellite images. The study reported superior performance from YOLT due to its deep learning architecture, significantly outperforming SSD in detecting smaller objects.

Figure 3: Example output of YOLT model at native 30 cm resolution. Cars are in green, buses/trucks in blue, and airplanes in orange.
Performance metrics such as mean average precision (mAP) are computed at various resolutions, highlighting the degradation when transitioning from 30 cm to 480 cm resolution.
SR Impact on Object Detection
The study presents comprehensive evaluations indicating significant enhancements in detection performance, particularly when resolving from native 30 cm to 15 cm, using SR methods. Statistical analysis reveals improved mAP scores most pronounced at higher resolutions, demonstrating SR's efficacy in enhancing feature distinction essential for object discrimination.
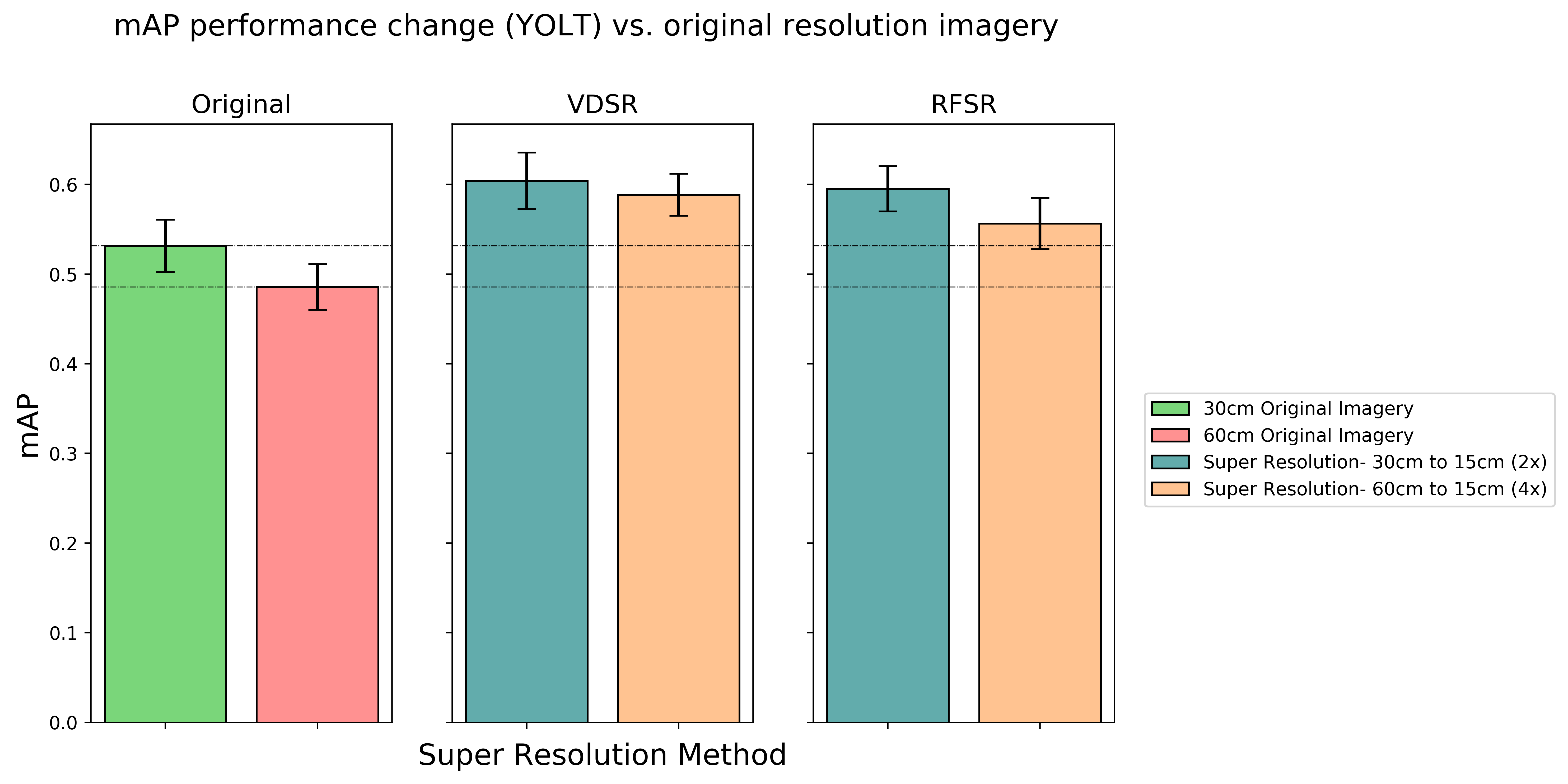
Figure 4: Performance boost of enhancing 30 and 60 cm imagery to 15 cm GSD.
Nonetheless, SR shows limitations in coarser resolutions, emphasizing the diminishing returns associated with illusory feature recovery from severely degraded inputs.
Conclusion
The paper concludes that SR techniques effectively enhance the detection of objects in satellite imagery at finer resolutions, offering substantial practical implications in satellite imaging. The integration of SR methods into object detection workflows presents a promising approach towards cost-effective satellite data processing and maximization of detection accuracy. Future research could explore end-to-end training paradigms and hybrid models combining SR techniques with novel object detection architectures.