- The paper presents hardware-aware ML frameworks that integrate energy, runtime, and resource metrics into deep learning model optimization.
- It introduces predictive techniques like NeuralPower and Bayesian optimization to accurately model and enhance hardware performance.
- Using co-optimization and NAS methods, the study offers practical insights for designing efficient DL models across diverse platforms.
Hardware-Aware Machine Learning: Modeling and Optimization
The paper "Hardware-Aware Machine Learning: Modeling and Optimization" presents a comprehensive evaluation of state-of-the-art methodologies focused on hardware-aware modeling and optimization for machine learning applications. The authors address several critical challenges faced in designing Deep Learning (DL) models that are both accurate and efficient concerning hardware constraints and performance metrics like latency and energy consumption.
Introduction
DL's proliferation across diverse platforms, ranging from mobile devices to data centers, necessitates a keen understanding of hardware implications to optimize models for deployment effectively. Given DL models' complexity, it is pivotal to consider hardware constraints such as energy consumption and latency during the model design phase. Platforms like mobile devices face significant limitations regarding battery life, necessitating energy-efficient DL models. This has given rise to methods for hardware-aware hyper-parameter optimization, aiming to tune model architectures for optimal accuracy and efficiency before training. The paper explores predictive modeling techniques to assess hardware performance—facilitating optimal DNN deployment by accounting for both the computational and hardware constraints.
Historically, the reduction of ML model complexity has been approached through pruning and quantization methods. While effective in decreasing FLOPs for DL models, these techniques often overlook hardware metrics, thus missing optimal designs for power or energy efficiency. Pruning involves weight reduction post-training, whereas quantization reduces bit-width to decrease computational expense. Despite their utility in simplifying models, they don't necessarily align with hardware-specific metrics like energy consumption, which are crucial for real-world applications.
Hardware-aware Runtime and Energy Modeling for DL
Energy-efficient DL models are optimized through predictive frameworks like Eyeriss and Paleo. These models compute runtime and energy consumption by factoring in memory access overheads and operations like MAC and bit-width influences. Eyeriss focuses on ASIC platforms, offering predictive models informed by real GPU executions to estimate runtime and energy requirements.
The NeuralPower Framework
NeuralPower introduces a robust adaptive framework for predicting runtime, power, and energy across CNNs deployed on GPUs (Figure 1). Employing polynomial regression models trained on actual GPU data, NeuralPower significantly outperforms Paleo in runtime prediction accuracy by capturing more relevant hyper-parameters tailored to each layer type. This framework's flexibility allows adaptation across various DL deployment platforms.

Figure 1: Overview of NeuralPower \cite{cai2017neuralpower}.
Hardware-aware Optimization for DL
Model-based Optimization
Model-based optimization, particularly Bayesian optimization (Figure 2), plays a crucial role in hardware-aware hyper-parameter optimization by guiding design space exploration towards Pareto-optimal configurations. This method iteratively refines the probabilistic model based on observed data, efficiently navigating the constraints of both accuracy and hardware performance.
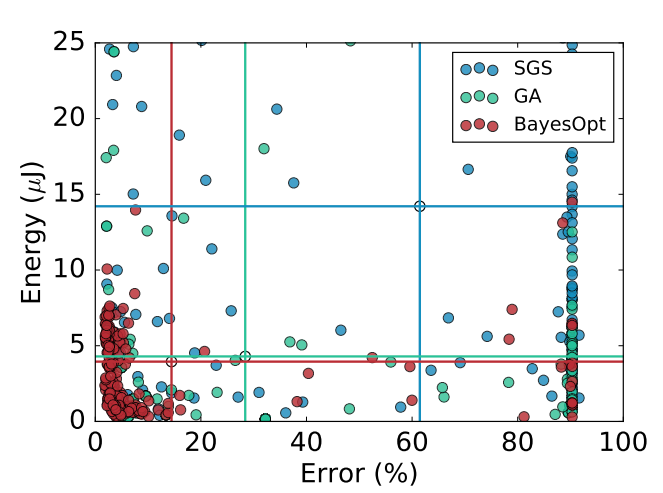
Figure 2: Model-based optimization (denoted as BayesOpt) outperforming alternative methods such as random search and genetic algorithms \cite{reagen2017case}.
Multi-layer Co-optimization
Minerva’s automated multi-layer co-optimization significantly reduces power consumption for DL models by addressing algorithm, architecture, and circuit levels. With numerous design stages, Minerva achieves massive power savings without sacrificing model accuracy, optimizing DNNs for mobile and IoT devices.
HyperPower Framework
HyperPower extends Bayesian optimization by integrating hardware constraints directly into its acquisition function (Figure 3). This hardware-aware approach prioritizes configurations satisfying power and memory budgets, thus accelerating convergence towards optimal designs.

Figure 3: Overview of HyperPower flow and illustration of the Bayesian optimization procedure \cite{stamoulis2017hyperpower}.
Neural Architecture Search (NAS) methodologies, such as DPP-Net (Figure 4), leverage cell-based design to optimize both DL accuracy and runtime. By focusing the probabilistic model's exploration on smaller, repetitive structures within DL models, NAS-based designs achieve notable Pareto-optimal configurations that align closely with hardware constraints.
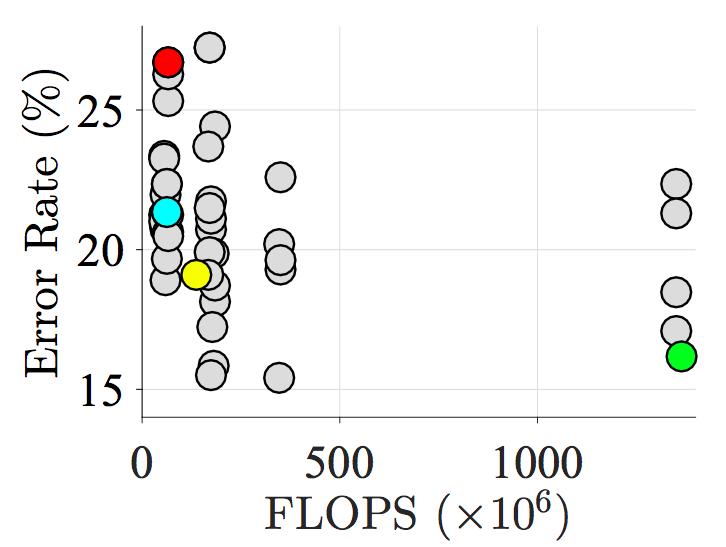
Figure 4: Pareto-optimal candidates identified by the platform-aware NAS-based method \cite{dong2018dpp}.
Unexplored Research Directions
Hardware-aware Modeling
Future research must explore modeling architectures for unconventional DNN topologies and cross-platform models that account for variability effects across diverse hardware platforms. These advancements will facilitate broader applicability and efficiency in deploying DL models.
Hardware-aware Optimization
The expansion of hardware-aware optimization methodologies to incorporate multi-objective formulations and co-design principles will drive innovation. Co-optimization of DL models and hardware presents opportunities for more holistic design solutions, enhancing performance across different hardware systems.
Conclusion
The research outlined in this paper demonstrates the critical importance and potential of expanding hardware-aware machine learning methodologies. Predictive modeling and innovative optimization techniques lay the foundation for DL models that are both efficient and effective, paving the way for widespread deployment across various hardware platforms and applications. The trajectory of hardware-aware ML will continue to evolve, addressing emerging challenges and opportunities as DL technologies further integrate with real-world systems.