- The paper proposes a unified framework that fuses AtteNet’s robust traffic light recognition with IA-TCNN's dilated causal convolutions for interaction-aware trajectory prediction.
- The motion prediction module achieves state-of-the-art average and final displacement error metrics on datasets such as ETH, UCY, and L-CAS.
- Real-world experiments using the extended FSC dataset validate the system's capacity to improve decision-making for safe autonomous street crossing.
Multimodal Interaction-aware Motion Prediction for Autonomous Street Crossing
The paper presents a framework for enabling mobile robots to safely cross street intersections by predicting intersection safety through multimodal data integration. This work introduces a system composed of a traffic light recognition network and an interaction-aware motion prediction network, both of which are crucial for making informed decisions about crossing.
System Architecture
The proposed system architecture integrates two primary components: AtteNet for traffic light recognition and IA-TCNN for motion prediction.
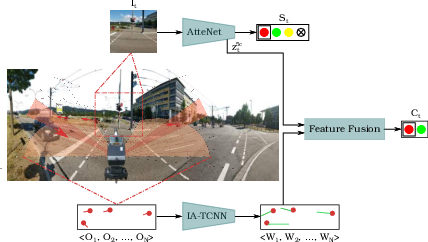
Figure 1: Schematic representation of our proposed system for autonomous street crossing. Our approach is comprised of two main modules; a traffic light recognition network and an interaction-aware motion prediction network. Feature map outputs of both modules are utilized to predict the safety of the intersection for crossing.
- AtteNet: This network is designed to recognize traffic light states robustly across varying illumination conditions. It incorporates Squeeze-Excitation (SE) blocks to emphasize relevant features and suppress irrelevant ones, enhancing feature map recalibration.
- IA-TCNN: The architecture uses dilated causal convolutions to predict future states of dynamic agents (e.g., pedestrians, vehicles) without predefined interaction modeling. It provides simultaneous trajectory estimates leveraging all observed agents, optimizing prediction through an innovative sequence-to-sequence modeling method.
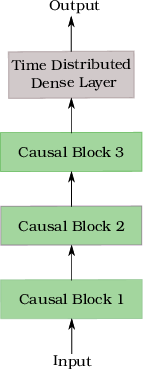

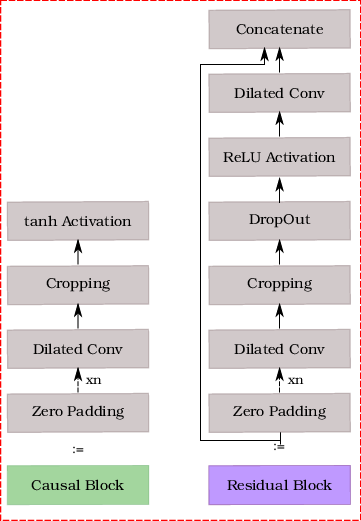
Figure 2: Illustration of the proposed network architecture for interaction-aware motion prediction. We propose two variants of our architecture: (a) IA-TCNN and (b) IA-DResTCNN. The legend enclosed in red dashed lines shows the constituting layers for each block.
The system fuses outputs from these networks to form a robust road-crossing predictor that considers traffic light status, observed motions, and predicted trajectories.
Motion Prediction
For motion prediction, IA-TCNN utilizes trajectory data to model complex agent interactions without explicit priority assignments. This is achieved through temporal convolutional layers with dilations, which enhance receptive field sizes without increasing network depth significantly.
The network predicts future trajectories over intervals longer than the observed trajectory, demonstrating superior predictive performance compared to recurrent neural network approaches such as LSTMs. This is verified across various datasets, including ETH, UCY, and L-CAS, where it achieves state-of-the-art metrics on average and final displacement errors.
Traffic Light Recognition
AtteNet, the proposed traffic light recognition network, is built upon ResNet-50 architecture but includes enhancements such as SE blocks and usage of ELUs for activation. These design choices contribute to higher robustness against noisy inputs and a significant improvement in classification accuracy. Evaluations on publicly available datasets (e.g., Nexar, Bosch) highlight its superiority over traditional networks like SqueezeNet and DenseNet, especially in precision and recall metrics across traffic light states.
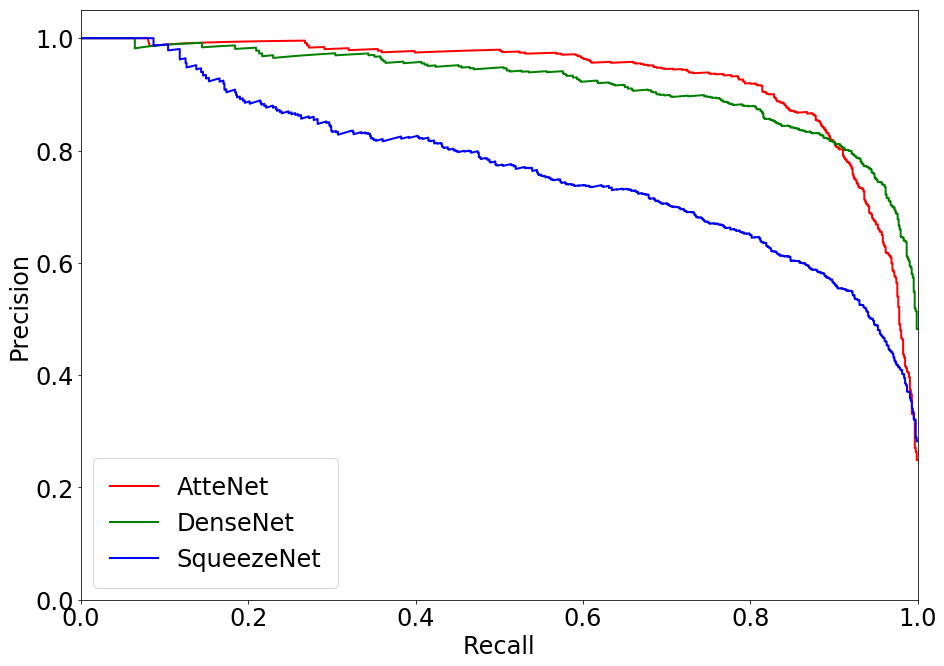
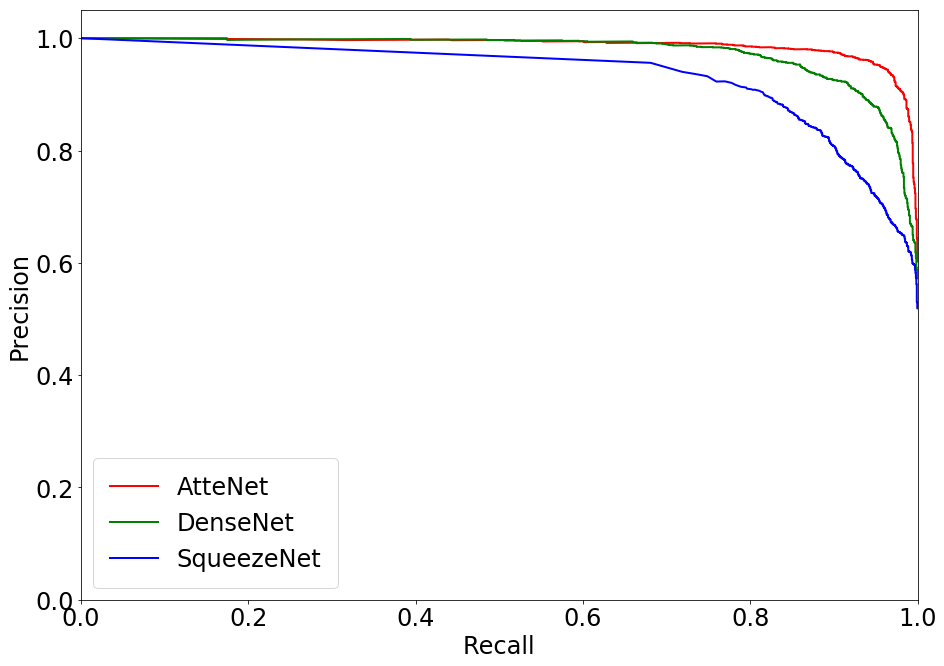
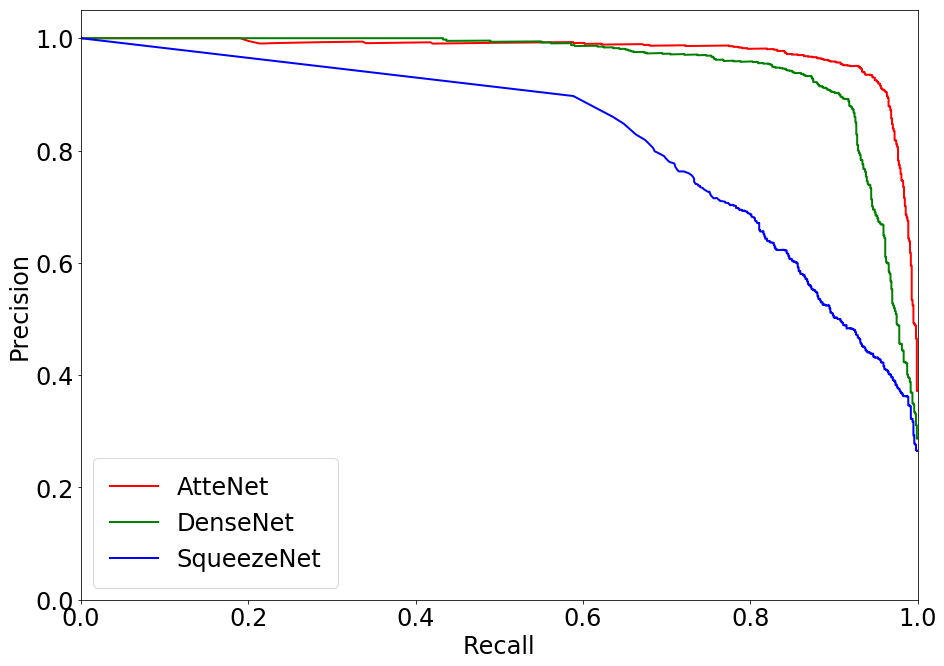
Figure 3: Precision-Recall plots comparing the performance of various methods on the Nexar dataset. The proposed AtteNet outperforms the compared approaches for all traffic light states.
Crossing Safety Prediction
Predictive performance for intersection safety combines learned outputs from both subnetworks in a fusion mechanism. This fusion incorporates uncertainty modeling to bolster robustness against individual network prediction errors.
Real-world validation experiments executed on a robotic platform affirm the framework's viability for autonomous street crossing in urban environments. The extended Freiburg Street Crossing dataset, augmented with new sequences and annotations of varying intersection types, serves as an evaluation ground to further substantiate the findings.
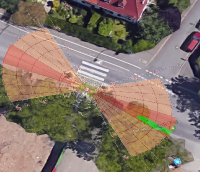







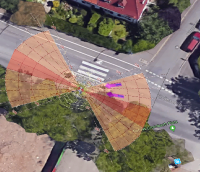

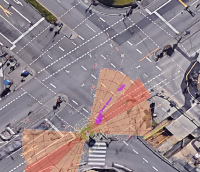

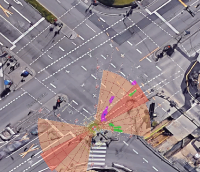
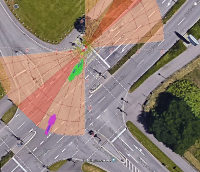
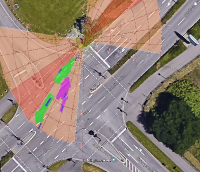
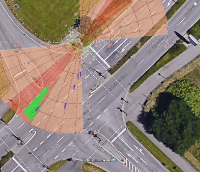


Figure 4: Depiction of various crossing scenarios from the FSC dataset. Detected dynamic objects are represented by arrows, where magenta arrows signify objects moving towards the robot, and green arrows signify objects moving away from the robot.
Conclusion
This research advances the autonomous navigation capability of mobile robots by integrating perception for traffic dynamics and signal recognition into a unified decision-making model. It demonstrates strong performance across multiple challenging domains and provides a foundation for future systems seeking to operate safely and efficiently in mixed-traffic environments. Future work is suggested in enriching the spatial-awareness dimension of the model, particularly through semantic understanding and structural map integration.

