- The paper presents a multi-GPU gradient boosting algorithm that significantly accelerates training using efficient data compression and quantile-based feature quantization.
- It integrates end-to-end GPU parallelism for key operations like gradient calculation and decision tree construction, achieving nearly threefold speedup over competitors.
- The approach demonstrates scalability by processing 115M instances rapidly, paving the way for future extensions to distributed and terabyte-scale data challenges.
XGBoost: Scalable GPU Accelerated Learning
Introduction
The paper "XGBoost: Scalable GPU Accelerated Learning" focuses on enhancing the efficiency and scalability of the XGBoost library through the implementation of a multi-GPU gradient boosting algorithm. This advancement enables rapid and large-scale training on multi-GPU systems by leveraging GPU memory efficiently via data compression techniques. Theoretical considerations are paired with practical implementations to demonstrate the method's applicability, processing up to 115 million training instances in under three minutes on standard cloud infrastructure.
Methods
The core methods introduced involve end-to-end GPU parallelism for several pivotal stages in the gradient boosting process, including prediction, gradient calculation, feature quantization, and decision tree construction. The proposed method employs a quantile-based decision tree algorithm, augmented with parallel GPU computations for optimizing performance and memory utilization.
Feature Quantile Generation
The algorithm utilizes a quantile representation of feature space inputs, which streamlines the computation-intensive decision tree construction into a gradient summation task, completing this operation entirely on the GPU.
Data Compression
A data compression step is integrated into the pipeline, reducing memory consumption significantly by packing quantized matrix values. This is accomplished using bitwise operations, allowing for efficient runtime decompression.
Decision Tree Construction
A detailed multi-GPU decision tree construction process is outlined, as shown in Algorithm 1. GPUs independently handle subsets of data, calculating partial gradient histograms that are merged across devices, optimizing for split gains via a parallel prefix sum.
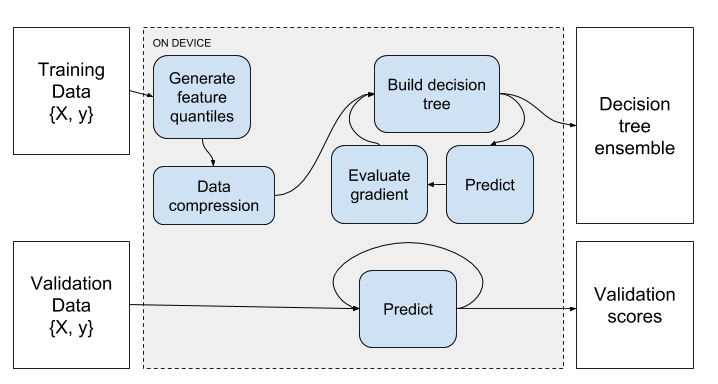
Figure 1: Gradient Boosting Pipeline.
Evaluation
The evaluation section compares the algorithm to competitors (LightGBM and CatBoost) using multiple datasets processed on an AWS instance with 8 Tesla V100 GPUs. The implementation shows strong numerical results, particularly with the largest dataset (115M rows), achieving close to three times the speedup against its nearest competitor. The scalability is further demonstrated by illustrating how runtime decreases with the addition of more GPUs on the airline dataset, maintaining efficient resource usage.
Implications and Future Work
Practically, these improvements allow for considerably faster processing times on massive datasets, making XGBoost an ideal choice for high-dimensional data tasks involving regression, classification, and ranking. Theoretically, the integration of GPU acceleration into robust machine learning libraries like XGBoost provides a path for further innovation in computationally efficient model training.
Future developments will extend this work to distributed systems, accommodating datasets beyond on-device memory limitations, potentially up to the terabyte scale. Moreover, plans to apply similar GPU-accelerated methods to large-scale linear modeling are indicative of the continued evolution of the XGBoost framework.
Conclusion
The advancements presented in this paper significantly enhance the capabilities of the XGBoost library via GPU acceleration, establishing a foundation for handling more extensive and complex datasets efficiently. Through continued development, the framework is poised to remain a leading tool in machine learning for both current and emerging data challenges.

