- The paper introduces query-based splits that more accurately test text-to-SQL generalization by ensuring no duplicate SQL queries across data partitions.
- The authors standardize datasets and correct SQL canonicalization errors, improving consistency and evaluation reliability.
- Evaluation shows baseline models struggle with query splits, highlighting challenges in synthesizing novel SQL structures from natural language.
Improving Text-to-SQL Evaluation Methodology
The paper "Improving Text-to-SQL Evaluation Methodology" (1806.09029) addresses critical issues in the evaluation processes of text-to-SQL systems. The authors identify existing limitations and propose enhancements to improve generalization assessment and robustness of such systems.
Introduction to Text-to-SQL Evaluation Challenges
A robust evaluation of text-to-SQL systems requires accurately measuring how well models generalize to unseen, realistic data. The traditional method often entails splitting datasets based on questions, allowing identical SQL queries to appear in both training and test sets but formulated differently in natural language. This primarily evaluates the system's ability to paraphrase known SQL queries but does not thoroughly test its capacity to generate novel queries.
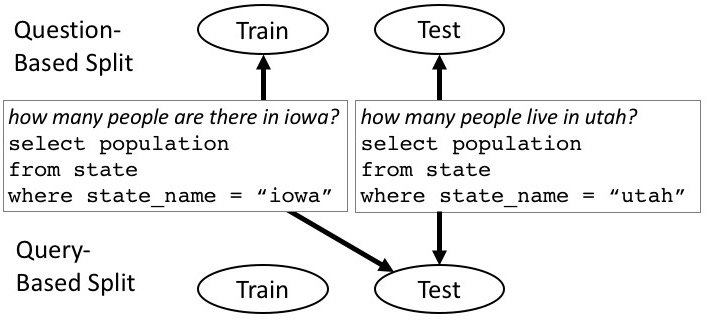
Figure 1: Traditional question-based splits allow queries to appear in both train and test. Our query-based split ensures each query is in only one.
Contributions and Innovations
- Dataset Improvement and Standardization: The authors directly address inaccuracies in existing datasets, correcting errors that affect SQL canonicalization and variable annotation. Existing datasets are standardized for consistency, and a new dataset, "Advising," introduces more complexity by using human-generated questions about university courses.
- Novel Data Split Methodology: In addition to question-based splits, the authors propose "query-based splits," where no SQL query appears in more than one dataset partition. This split better evaluates a system's ability to generalize query structure from one domain to another, beyond mere question paraphrasing.
- Variable Anonymization Challenge: Discussed is the common practice of anonymizing variables, which can obscure system capability regarding specific entities in questions. The study argues for maintaining variable opacity to preserve particular challenges in text-to-SQL tasks.
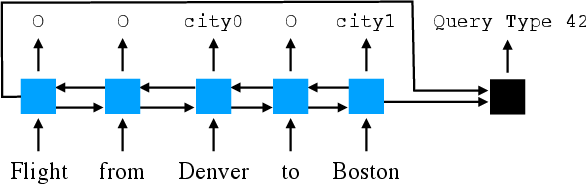
Figure 2: Baseline: blue boxes are LSTM cells and the black box is a feed-forward network. Outputs are the query template to use (right) and which tokens to fill it with (left).
Analytical Evaluation and Findings
The authors conduct rigorous evaluation across various datasets, utilizing a newly proposed template-based, slot-filling baseline system alongside seq2seq models with attention and copying mechanisms. The performance was gauged under traditional and newly suggested query splits, with noticeable performance declines on query splits, highlighting their challenge.
- Human-Generated vs. Automatically Generated Data: Human-generated datasets like ATIS and Advising exhibit more complexity with joins and nesting, providing a stricter evaluation standard compared to automatically generated datasets such as WikiSQL.
- Dataset Diversity and Complexity: The introduction of statistical measures demonstrates that increased dataset size doesn't naturally equate to diversity. Therefore, evaluating on diverse datasets with varying complexities is crucial for a comprehensive assessment of system capabilities.
- Model Performance: The baseline system revealed moderate performance on traditional splits but underperformed on the query splits, underscoring the complexity and learning requirements of SQL synthesis from natural language.
Conclusion
The authors successfully show that effective text-to-SQL evaluation requires testing on both question-based and query-based dataset splits. The study encourages future dataset development to prioritize human-like complexity, and methodological evaluations should integrate both types of data splits to enhance the generalizability of text-to-SQL systems. These insights guide a broader understanding of system capabilities and foster improved methodologies in deploying natural language interfaces to databases in practical applications.