- The paper demonstrates that a model-based framework using Kalman filtering and codebook estimation significantly enhances speech intelligibility in binaural hearing aids.
- It leverages a detailed speech production model to separate source and filter components, ensuring naturalness and effective improvement in challenging auditory scenarios.
- Evaluation with PESQ and STOI metrics, along with subjective tests, confirms notable advancements, supporting practical deployment in real-world devices.
Model-based Speech Enhancement for Intelligibility Improvement in Binaural Hearing Aids
The paper explores a binaural speech enhancement framework designed to improve speech intelligibility for individuals using hearing aids, especially in complex auditory environments like the classic "cocktail party" scenario. The approach leverages model-based signal processing techniques to enhance speech signals captured by binaural hearing aids.
Framework and Approach
Speech Production Model
Central to this framework is the incorporation of the speech production model, which is crucial for both intelligibility enhancement and ensuring the naturalness of enhanced speech. The model divides the speech signal into a source component, representing vocal cord vibration, and a filter component, representing the vocal tract. This separation allows for effective parameterization and manipulation of the speech signal during enhancement.
Kalman Filter Integration
A key feature of the proposed framework is its reliance on the Kalman filter, which is tailored to handle the dynamics of speech production. The Kalman filter is adept at predicting and smoothing time-evolving signals, making it highly suitable for real-time speech enhancement tasks.
Parameter Estimation
For accurate application of the Kalman filter, precise estimation of relevant parameters is necessary. The paper proposes a binaural codebook-based method to estimate short-term predictor (STP) parameters and a directional pitch estimator to determine clean speech pitch. Both methodologies exploit information from both ears for robust parameter approximation, contributing to more natural and intelligible speech outputs.
Evaluation Metrics
The framework is rigorously evaluated against objective measures such as the Perceptual Evaluation of Speech Quality (PESQ) and Short-Time Objective Intelligibility (STOI), demonstrating significant improvements over existing methods. The framework also undergoes subjective listening tests to assess perceived quality and intelligibility improvements, noting a substantial boost, even in single-channel conditions.
Implementation Considerations
Computational Complexity
The computational complexity associated with the Kalman filter and parameter estimation tasks necessitates careful consideration of the available processing resources in typical hearing aid devices. Despite this, the paper highlights potential optimization strategies and efficient implementation pathways that can mitigate processing overheads while retaining enhancement efficacy.
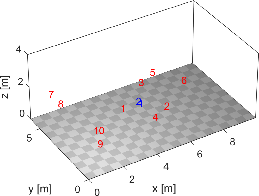
Figure 1: Set-up 2 showing the cocktail scenario where 1 (red) indicates the speaker of interest and 2-10 (red) are the interferers and 1,2 (blue) are the microphones on the left ear and right ear respectively.
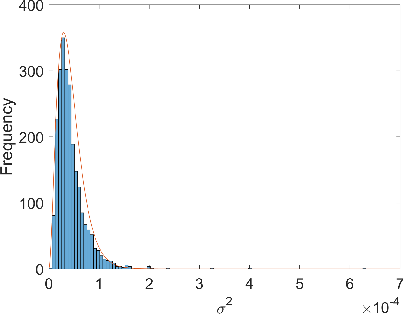
Figure 2: Plot showing the histogram fitting for noise excitation variance. Curve (red) is obtained by fitting the histogram with a Gamma distribution with two parameters.
Deployment in Hearing Aids
Deployment of the proposed framework in real-world hearing aids additionally depends on ensuring minimal latency and energy consumption, both of which are critical for user satisfaction and device performance. The proposed methodologies are designed with these constraints in mind, pushing towards practical integration into consumer devices.
Conclusion
The model-based approach described in this paper shows promise for significant improvements in speech intelligibility and quality for hearing aid users, particularly in environments with multiple speakers and background noise. Future research directions include further optimization for computational efficiency and exploring adaptive mechanisms that cater to varying auditory environments and individual user needs. The integration of machine learning concepts with the current model-based strategies also poses an exciting avenue for expanding the capabilities of hearing aid technology.