- The paper introduces the R-CED network that learns a direct mapping from noisy to clean speech spectra using a fully convolutional architecture.
- It demonstrates that bypassing pooling layers and using skip connections significantly enhances denoising performance in harsh babble noise conditions.
- Experimental evaluations on the TIMIT corpus show improved SDR, STOI, and PESQ scores while reducing model size for embedded hearing aid applications.
A Fully Convolutional Neural Network for Speech Enhancement
This paper addresses the problem of enhancing speech quality in environments dominated by babble noise, particularly for applications in hearing aids. The authors propose a method utilizing Convolutional Neural Networks (CNNs) for speech denoising, circumventing the common challenge of model size faced by fully connected and recurrent networks. Specifically, the Redundant Convolutional Encoder Decoder (R-CED) network is introduced as a lightweight, effective solution for embedded systems such as hearing aids.
Problem Statement
The task is to develop a mapping function f that transforms noisy speech spectra into clean spectra with minimal artifacts, optimizing the ℓ2 norm between the denoised output and the original clean spectra. Traditional methods focus on noise modeling, which often fails under babble noise conditions due to the mixture of overlapping speech signals. The paper instead aims to learn a direct mapping using a CNN-based approach.

Figure 1: Speech Enhancement Using a CNN.
Convolutional Network Architectures
Convolutional Encoder-Decoder Network (CED)
The CED network utilizes symmetric encoder and decoder layers, each defined by sequences of convolution, batch normalization, ReLU activation, and pooling operations. Notably, the final layer is modified to a convolution layer, which makes the network fully convolutional.
Redundant CED Network (R-CED)
The proposed R-CED network avoids pooling layers, using only convolution and batch normalization, which allows it to handle input spectra directly in higher dimensions, akin to kernel methods. The architecture prioritizes redundancy and compression through an asymmetrical increase and decrease in the number of filters towards the decoder end.
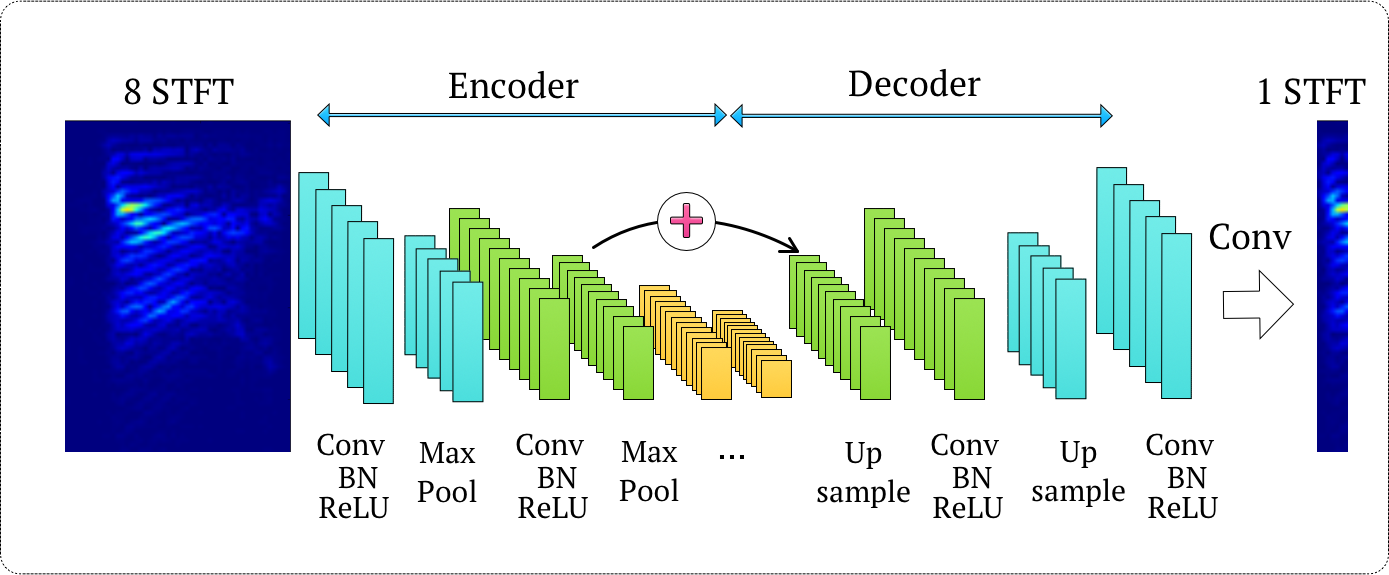
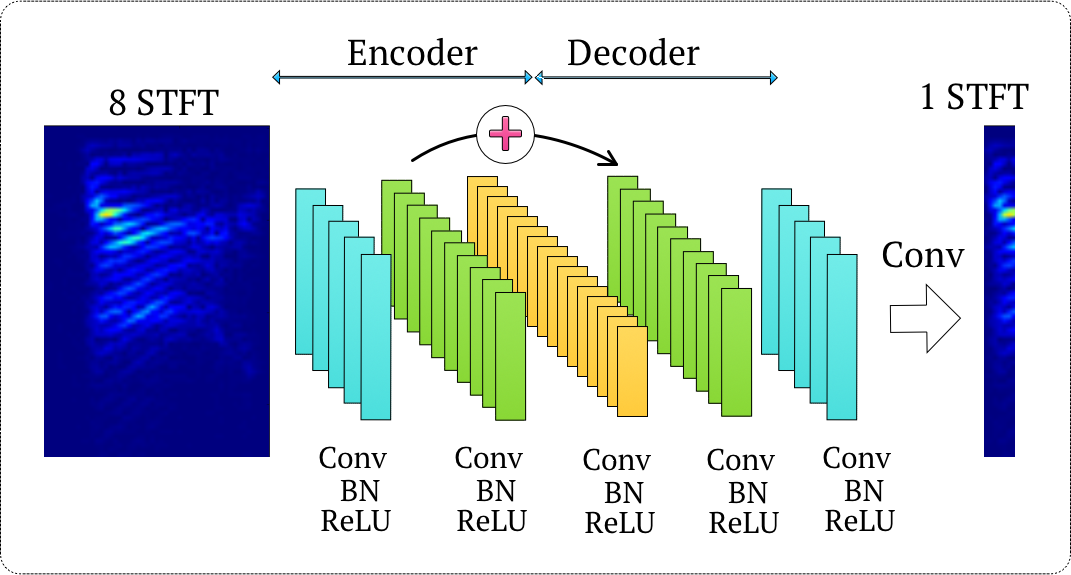
Figure 2: Modified Convolutional Encoder-Decoder Network (CED).
Experimental Setup
Experiments were performed using the TIMIT corpus with 27 noise types superimposed at 0 dB SNR. The evaluation metrics included Signal-to-Noise Ratio (SDR), Short-Time Objective Intelligibility (STOI), and Perceptual Evaluation of Speech Quality (PESQ), providing a balanced view of objective and subjective quality measures.
Results
Three primary tests were conducted: comparing CNN against FNN and RNN, evaluating CED versus R-CED architectures, and optimizing R-CED performance.
- Test 1: CNNs achieved equivalent performance to FNN and RNN with a drastically reduced parameter count, thus making them suitable for embedded systems.
- Test 2: R-CED outperformed CED in terms of denoising capability, particularly when skip connections were implemented.
- Test 3: Higher CNN performance was directly related to network size and depth, with the CR-CED architecture showing the most promise within the tested configurations.



Figure 3: Noisy Spectrogram.
Conclusion
The application of CNNs to speech denoising in low-resource settings is validated through the presented work, demonstrating significant improvements in model efficiency without sacrificing performance. The R-CED structure with bypass connections provides effective speech enhancement suitable for real-time applications in hearing aids. Future work will focus on optimizing R-CED for computational cost, which remains vital for further deployment in constrained environments.