- The paper introduces an adaptive method that dynamically selects the optimal DNN based on input features to improve accuracy by 7.52% and reduce inference time by 1.8x.
- It employs a cascade of k-NN models with correlation-based feature selection to efficiently determine the best pre-trained model for each input.
- The approach enhances real-time performance on embedded platforms by achieving higher accuracy, reduced energy consumption, and faster inference.
Adaptive Selection of Deep Learning Models on Embedded Systems
The paper "Adaptive Selection of Deep Learning Models on Embedded Systems" presents an innovative approach for improving the efficiency of deep learning inference on resource-constrained embedded systems. This approach dynamically selects the optimal Deep Neural Network (DNN) based on the specific input and accuracy requirements, thereby enhancing performance in terms of both accuracy and inference time.
Introduction
In the context of embedded systems, deploying deep learning models poses significant challenges due to limited computational resources. Existing methods often rely on model compression or offloading computations to the cloud, which may lead to precision loss or privacy issues, respectively. To address these, the paper proposes an adaptive method for on-device model selection, which determines the best DNN model to use for a given input by considering the trade-off between accuracy and inference time.



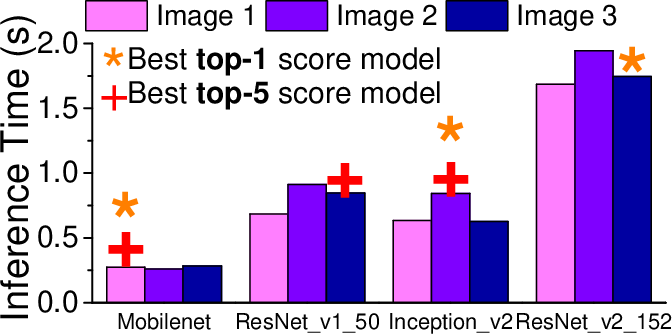
Figure 1: The inference time (d) of four CNN-based image recognition models when processing images (a) - (c). The target object is highlighted on each image.
Approach
The proposed solution involves training a predictive model (termed as \premodel) offline, which then selects the optimal pre-trained DNN model for new, unseen inputs during runtime. The system utilizes machine learning techniques to develop this predictive model, taking into account extracted features from the input data such as edge length, brightness, and aspect ratio.

Figure 2: Overview of our approach.
Model Description
The \premodel consists of a cascade of k-Nearest Neighbour (\NN) models, where each \NN predicts whether a specific image classification model should be used. The model considers various features extracted from images, which are systematically reduced and optimized to ensure efficient inference without significant accuracy loss.

Figure 3: Our \premodel, made up of a series of \NN models. Each model predicts whether to use an image classifier or not, our selection process for including image classifiers is described.
Training and Deployment
Training the \premodel involves generating labeled training data to evaluate candidate DNN models' performances. This step is computationally intensive but only needs to be performed once. The paper details a correlation-based feature selection method to optimize the feature set used for training.
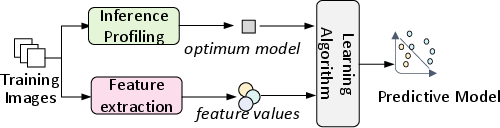
Figure 4: The training process. We use the same procedure to train each individual model within the \premodel for each evaluation criterion.
Results
The adaptive model selection approach demonstrates a 7.52% improvement in inference accuracy and a 1.8x reduction in inference time compared to the most capable single DNN model. This is achieved on the NVIDIA Jetson TX2 platform using the ImageNet ILSVRC 2012 validation dataset. The method also extends to energy efficiency, reducing energy consumption by more than 2x compared to some sophisticated models.
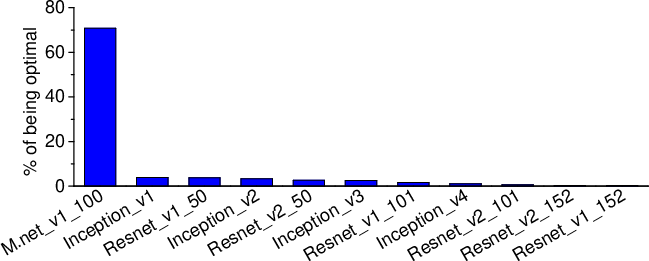
Figure 5: How often a \CNN model is considered to be optimal under the \topone score on the training dataset.
Discussion
The findings underscore the potential for adaptive model selection in real-world applications, especially where privacy, latency, and resource constraints are significant concerns. While the current research focuses on image classification, the methodology is applicable to other domains, such as audio and natural language processing, if appropriate features are selected.
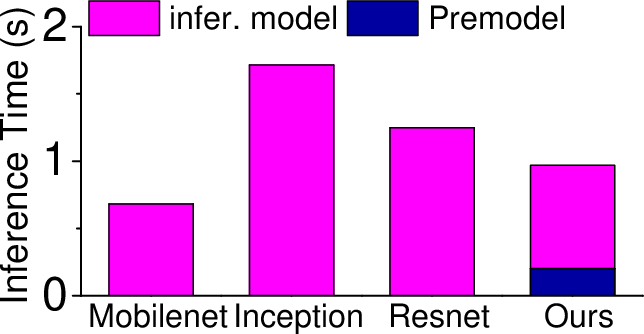
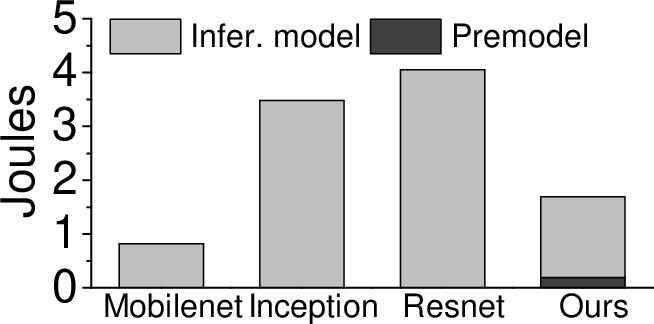
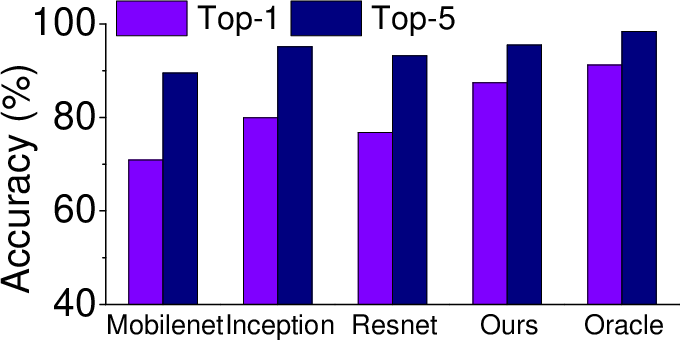
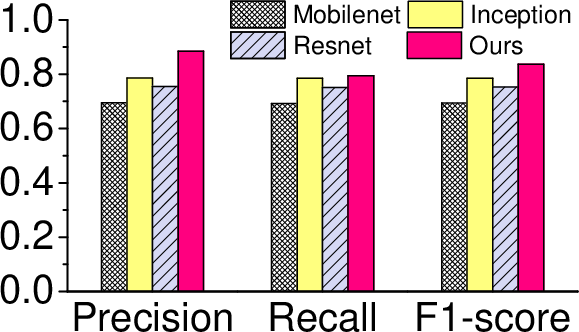
Figure 6: Overall performance of our approach against individual models for inference time (a), energy consumption (b), accuracy (c), precision, recall and F1 score (d). Our approach gives the best overall performance.
Conclusion
The research contributes a practical and effective strategy for deploying deep learning inference on embedded systems. By adaptively selecting models based on input characteristics, the approach balances the demands for accuracy, inference time, and energy consumption, demonstrating its robustness and scalability in real-world embedded applications.
This paper sets the stage for further exploration into adaptive models and their deployment across various platforms and domains, offering a comprehensive solution to the challenges faced in embedded AI applications.