- The paper introduces a hybrid approach that integrates source-based and build-based feature extraction to detect vulnerabilities in C/C++ programs.
- It demonstrates that models combining lexical features (e.g., TextCNN with word2vec) and structural insights yield superior precision-recall performance.
- The combined model approach effectively synthesizes control flow graphs with token embeddings to enhance vulnerability detection accuracy.
Automated Software Vulnerability Detection with Machine Learning
This paper presents a robust approach to leveraging machine learning techniques for automated detection of software vulnerabilities, particularly within C and C++ programs. The approach integrates source-based and build-based feature extraction to optimize the detection of potential security flaws at the function level.
Introduction
Software vulnerabilities are persistent challenges in sustaining secure systems, often exploited to cause significant disruption and damage. As traditional static and dynamic analysis tools provide limited rule-based detection, the shift toward data-driven methodologies offers a broader scope for identifying vulnerabilities by learning from extensive open-source datasets. This paper introduces a machine learning framework that capitalizes on the available open-source C/C++ code to discern vulnerability patterns beyond the capabilities of static analysis tools.
Methodology
Build-Based Features: Utilizing LLVM and Clang, the build-based approach extracts features from program intermediate representations (IR) during compilation. This includes Control Flow Graphs (CFG), opcode vectors, and use-def matrices, which capture operational details and data flows conducive to vulnerability detection. The CFG representation provides a macro-level understanding of possible execution flows, while details like opcode vectors reflect micro-level operations.
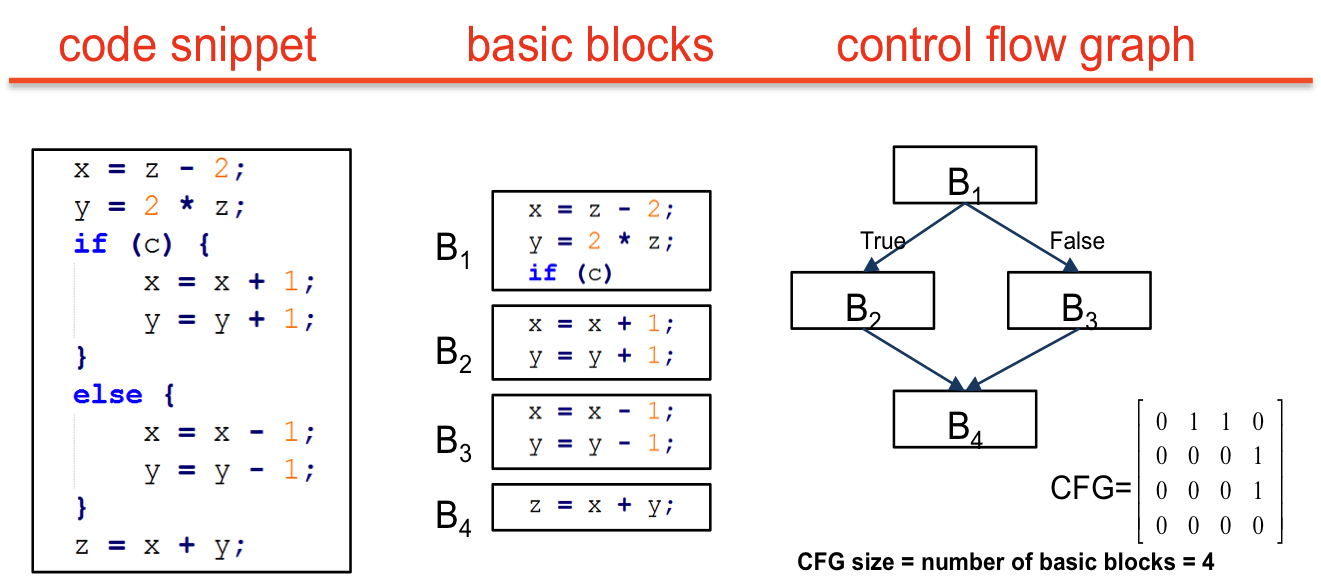
Figure 1: A control flow graph extracted from a simple example code snippet.
Source-Based Features: A custom lexer processes the source code to generate tokens, categorized as literals, operators, names, etc. The paper employs bag-of-words and word2vec embeddings to convert these tokens into structured data inputs for machine learning models, where semantic relationships between tokens can be effectively learned.
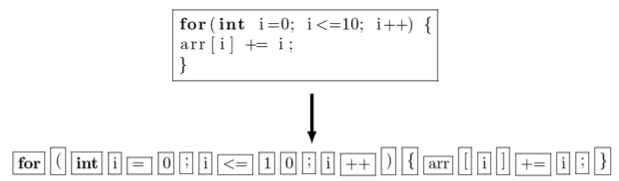
Figure 2: An example illustrating the lexing process.

Figure 3: A word2vec embedding of tokens from C/C++ source code.
Model Implementation
The evaluation centers around three source-based models: bag-of-words combined with extremely randomized trees, TextCNN using word2vec embeddings, and a hybrid model that injects TextCNN-derived features into an extra-trees classifier, demonstrating the best performance. For build-based features, handcrafted vectors from CFGs and opcodes feed into a random forest model. Consequently, a combined model synthesizes both source and build-based features for optimal security flaw detection.
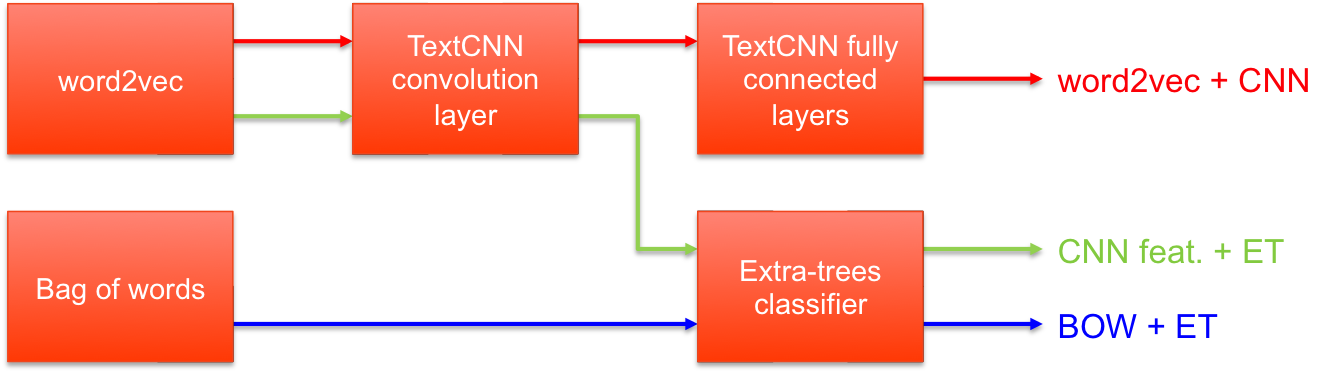
Figure 4: Illustration of the three types of source-based models tested.
Experimental Results
The experiments utilize two primary datasets from Debian and GitHub, ensuring no duplicates across training, validation, and test sets. Source-based models, due to their enriched lexical input, outperform build-based models, with the hybrid TextCNN and extra-trees model showcasing the highest precision-recall area under the curve (AUC).
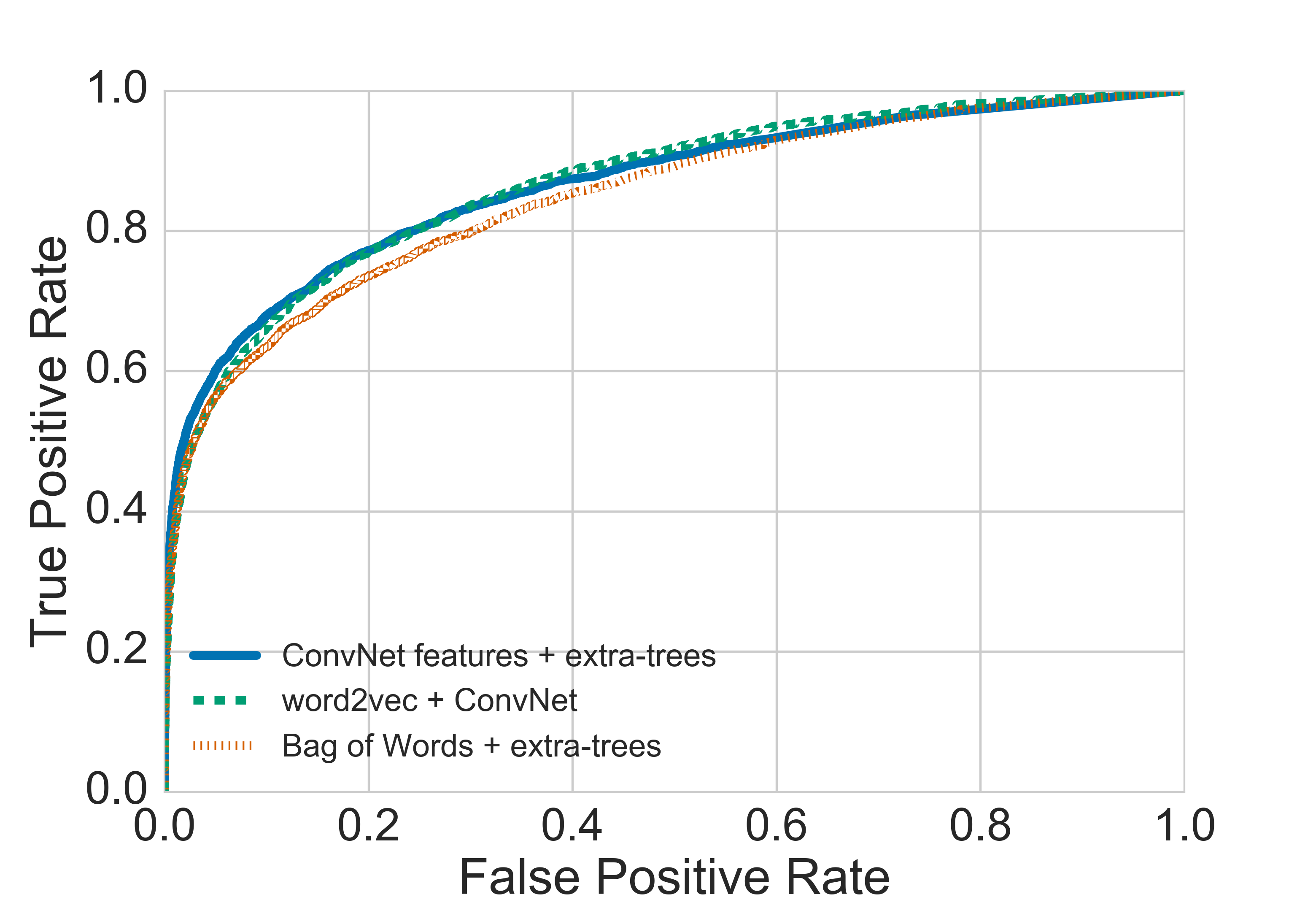
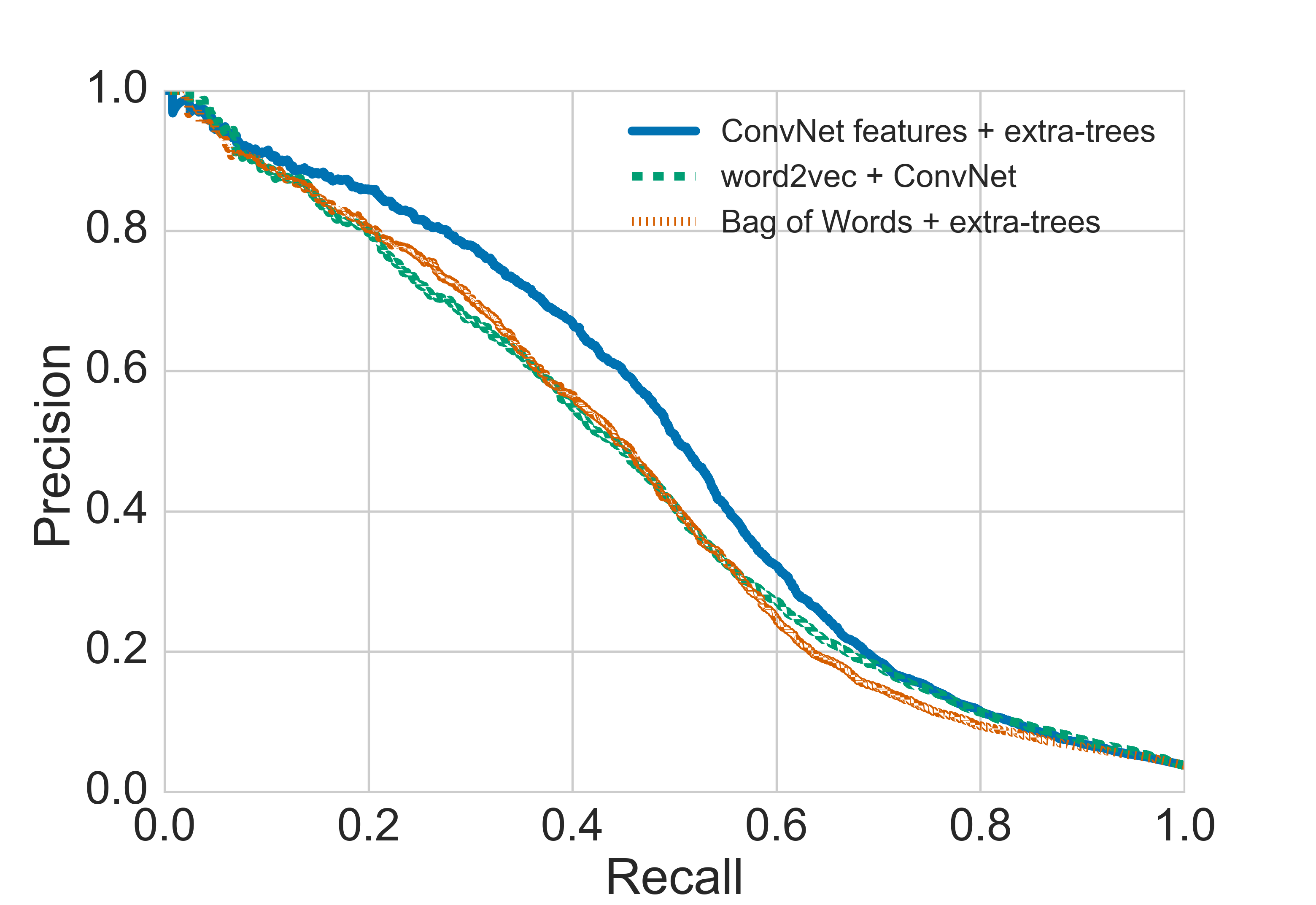
Figure 5: Results of testing different source-based models on a combined Debian+Github source code dataset.
Build-based models achieve significant yet lower AUC values, reinforcing the conclusion that direct source code features offer superior context and information for vulnerability detection.
Comparative Analysis
To validate the efficacy of combining methodologies, the paper also presents consolidated testing across identical datasets, which reveals that combined models incorporate build-based positional and structural insights with source-based lexical intelligence to achieve superior detection performance.
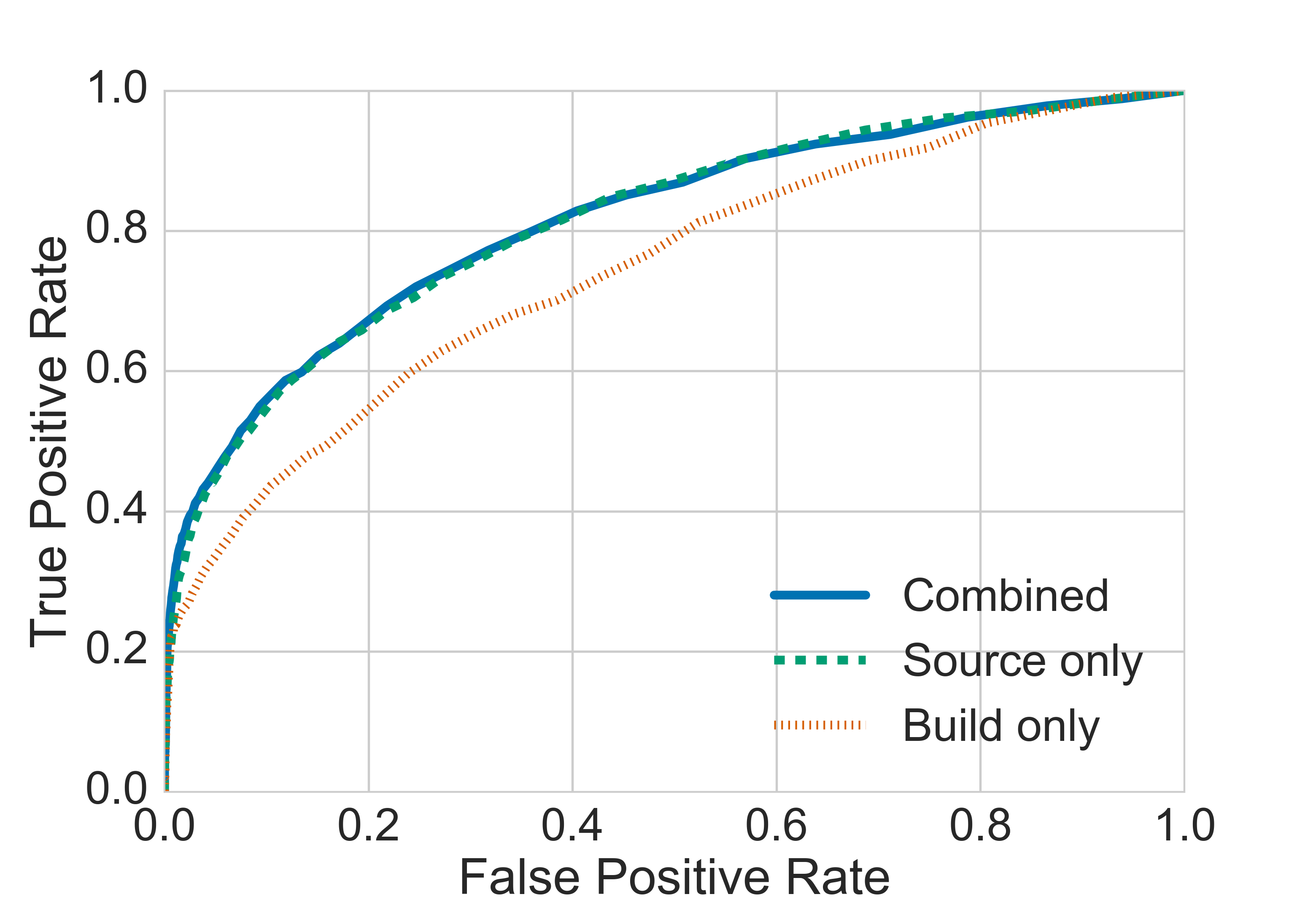
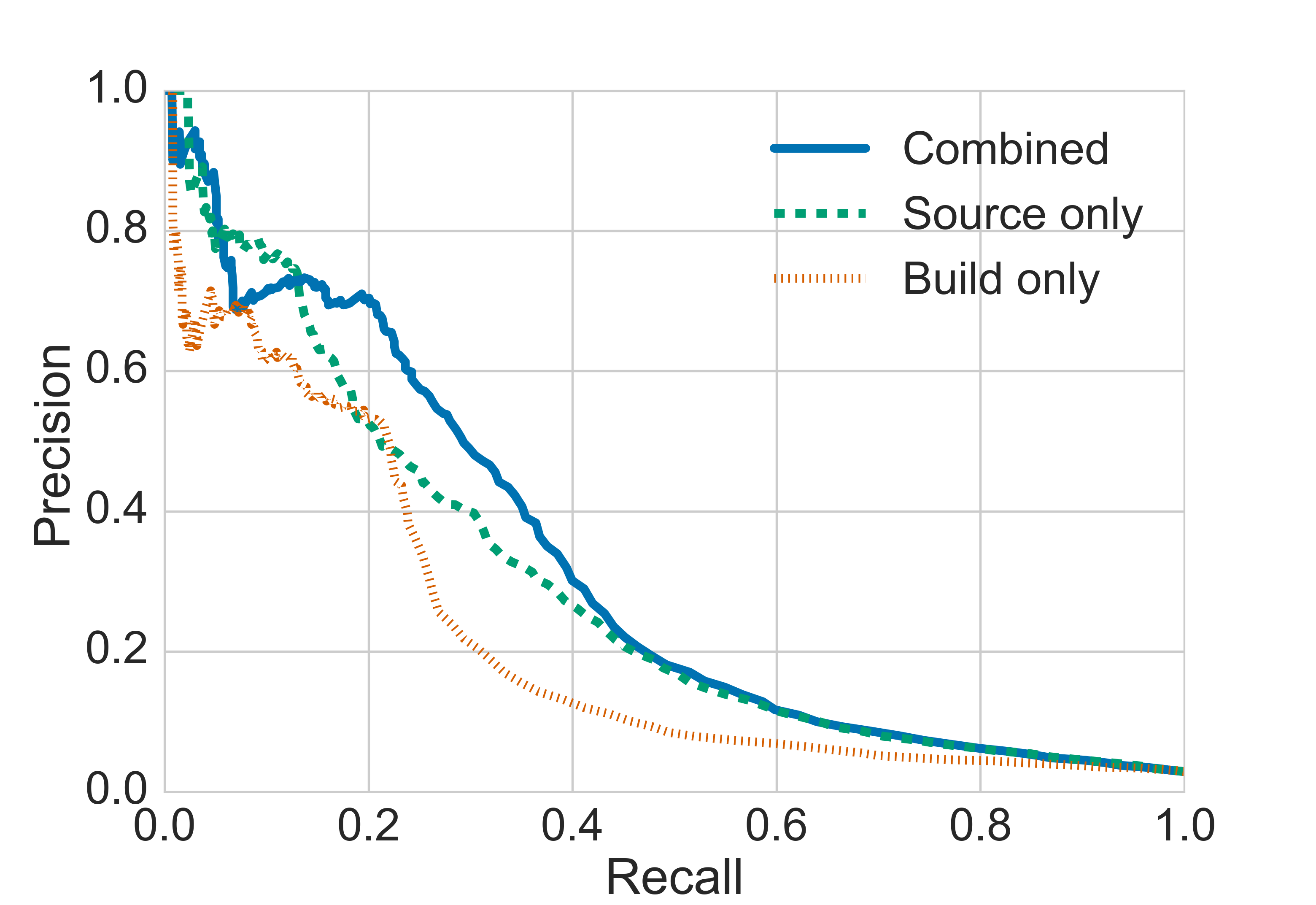
Figure 6: Comparison of build only, source only, and combined models on the Github dataset.
Conclusions
This research delineates a clear path towards enhancing software vulnerability detection through machine learning by integrating language-level src features with build-level IR insights. While static analysis benchmarks frame the current results, future work should aim to diversify training labels such as incorporating real-world exploits to enrich model learning. This direction promises expedited code reviews and efficient vulnerability management, augmenting conventional analysis tools with predictive accuracy and breadth. Additionally, expanding models to other programming languages holds potential for broader impact.
Overall, this paper lays a foundational framework for using machine learning to predict vuln presence in software, underscoring the importance of hybrid model approaches for comprehensive analysis.