- The paper introduces REGAL, which leverages a novel embedding method, xNetMF, to enhance network alignment accuracy by 20-30% compared to baselines.
- It employs low-rank matrix approximation via the Nyström method to reduce computational complexity and achieve up to a 30x increase in speed.
- REGAL demonstrates robustness against attribute noise and scalability to networks with millions of nodes, ensuring flexible application across diverse scenarios.
REGAL: Representation Learning-based Graph Alignment
Introduction
The paper "REGAL: Representation Learning-based Graph Alignment" (1802.06257) addresses the complex problem of network alignment by leveraging node representation learning methodologies. Network alignment involves determining corresponding nodes across separate graphs, a task with significant applications in both social and natural sciences. This research proposes the REGAL framework to effectively align nodes through learned embeddings, utilizing a novel embedding technique termed xNetMF.
Methodology
xNetMF for Node Embedding
REGAL introduces xNetMF, a robust embedding formulation designed specifically for cross-network tasks. Unlike traditional graph embedding methods that often rely on node proximity within a single network, xNetMF focuses on enhancing structural identity. It computes embeddings by factorizing a similarity matrix constructed from structural and optionally available node attributes. This similarity, formalized as sim(u,v) = exp(-γ_s ||d_u - d_v||² - γ_a dist(f_u,f_v)), provides a scalable method for capturing node characteristics conducive to alignment across networks.
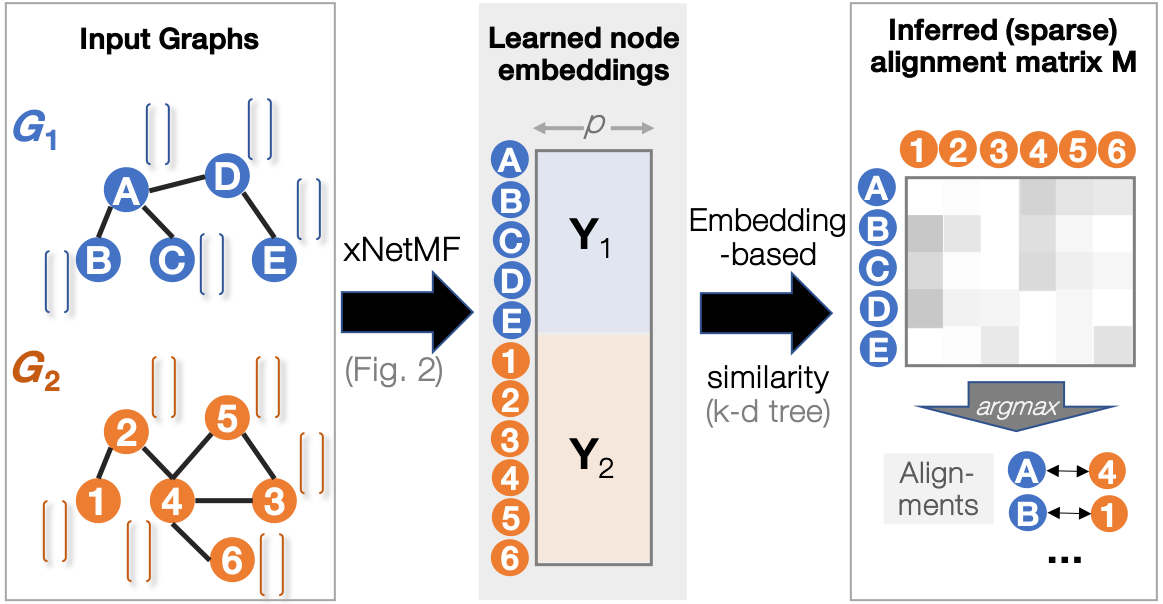
Figure 1: Pipeline of proposed graph alignment method, REGAL, based on our xNetMF representation learning method.
Low-Rank Matrix Approximation
The traditional approach to embedding does not scale well with network size due to its quadratic complexity. To circumvent this, REGAL employs an implicit low-rank approximation of the similarity matrix, leveraging the Nyström method. By selecting landmarks and approximating the full similarity matrix, REGAL reduces computational resources while maintaining effective alignment capabilities.
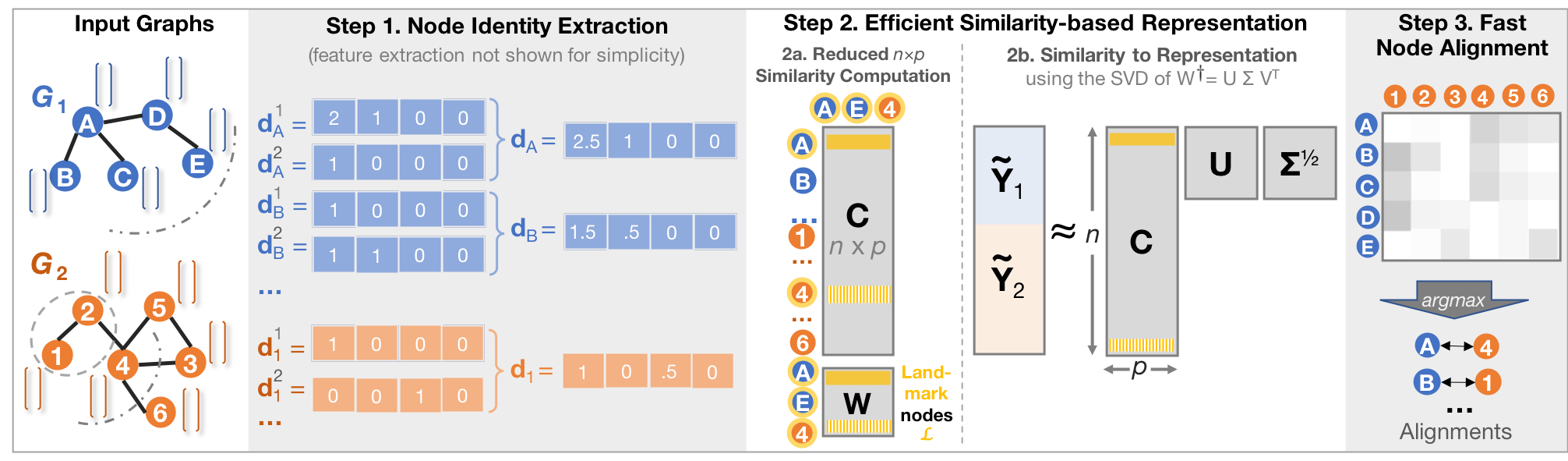
Figure 2: Proposed REGAL approach, consisting of 3 main steps. In the example, for the structural identity, up to K=2 hop away neighborhoods are taken into account (the 1-hop and 2-hop neighborhoods for nodes A and 1 are shown with dashed and dash-dotted lines, respectively). The discount factor is set to delta=0.5. For simplicity, no logarithmic binning is applied on d.
Experimental Results
The implementation of REGAL was evaluated against several baselines, demonstrating superior performance in terms of both alignment accuracy and computational efficiency. Particularly, REGAL was shown to outperform existing methods by 20-30% in accuracy while achieving up to a 30x increase in speed during the representation learning phase.
Robustness and Scalability
REGAL was tested for robustness against various noise levels in node attributes and structures. The framework showed higher resilience compared to alternatives, particularly in scenarios with substantial attribute noise. Scalability tests further confirmed the framework's efficiency, as REGAL was able to handle networks with millions of nodes, achieving sub-quadratic time complexity for embeddings.
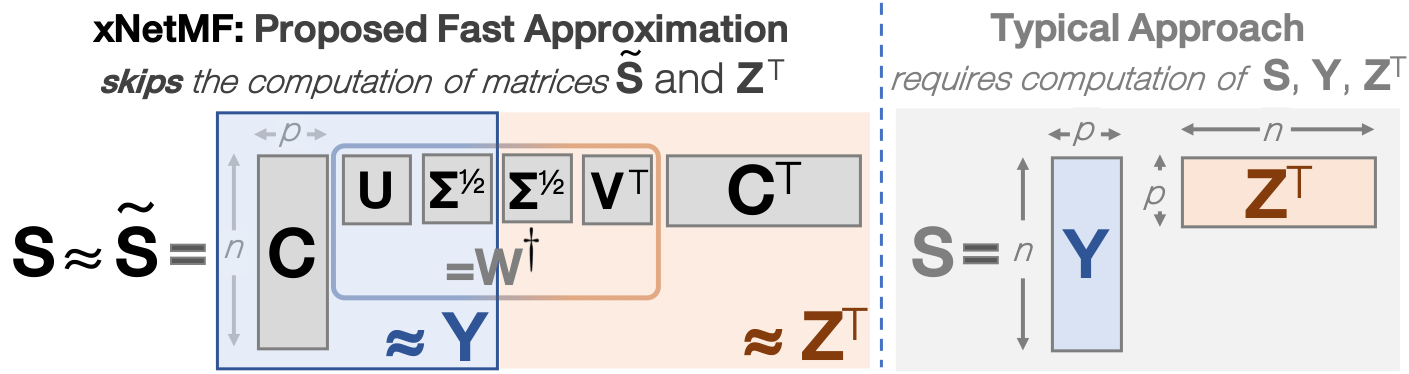
Figure 3: Proposed xNetMF (using the SVD of W\dagger) vs. typical matrix factorization for computing the node embeddings Y. Our xNetMF method leads to significant savings in space and runtime.
Hyperparameter Sensitivity
The REGAL framework was tested for sensitivity against hyperparameters such as discount factor δ, maximum hop distance K, and embedding dimensionality p. Results indicated that its performance remained stable across a variety of settings, negating the need for intensive parameter tuning.
Conclusion
REGAL provides an efficient and flexible solution for network alignment, capitalizing on representation learning techniques that ensure compatibility across disjoint networks. Further exploration could extend this work into weighted networks or those with additional edge attributes. The publicly available implementation of REGAL promises to support a wide array of future research in network science.
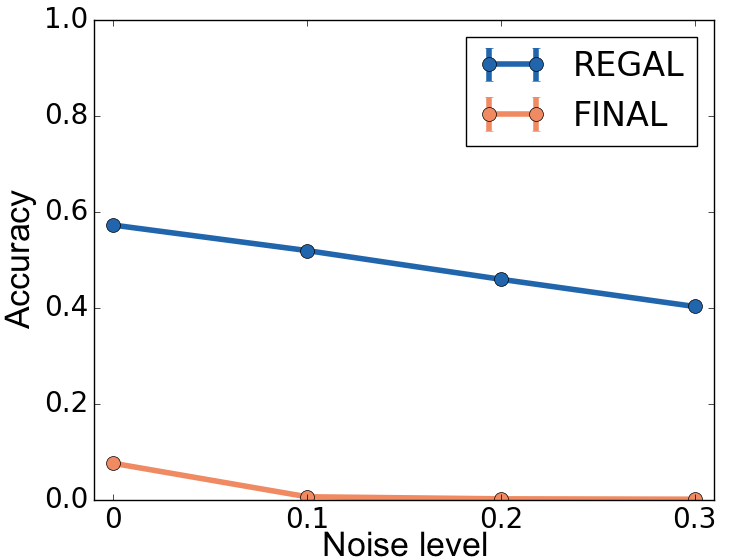
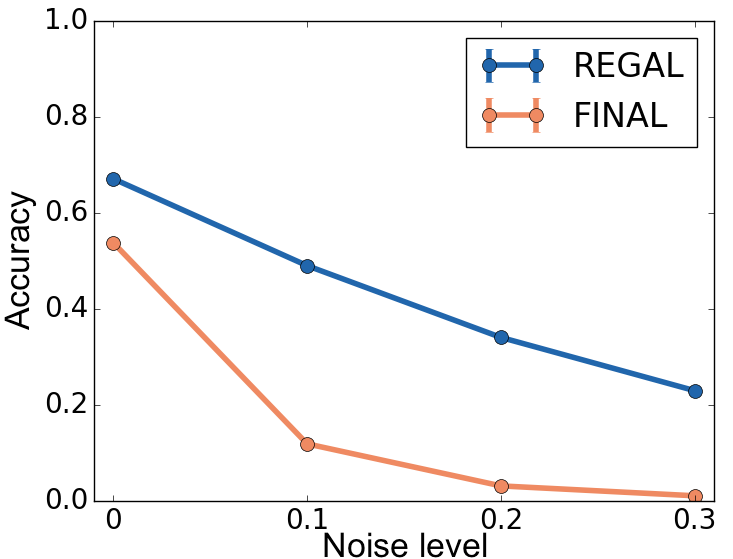
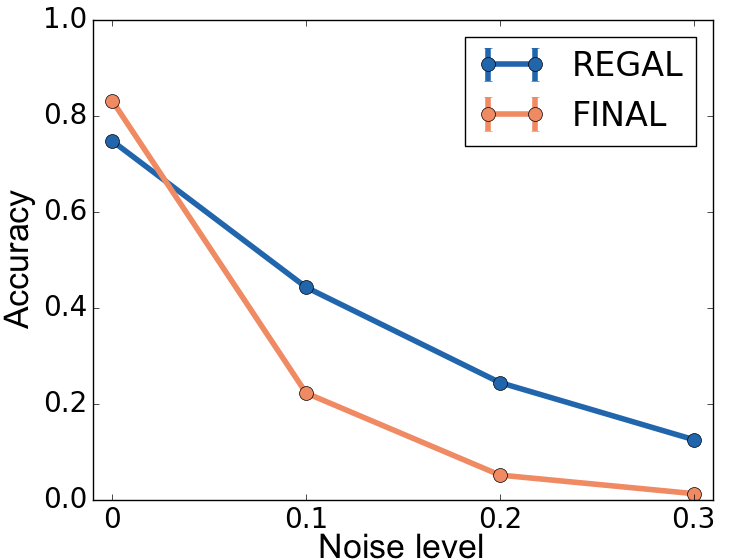
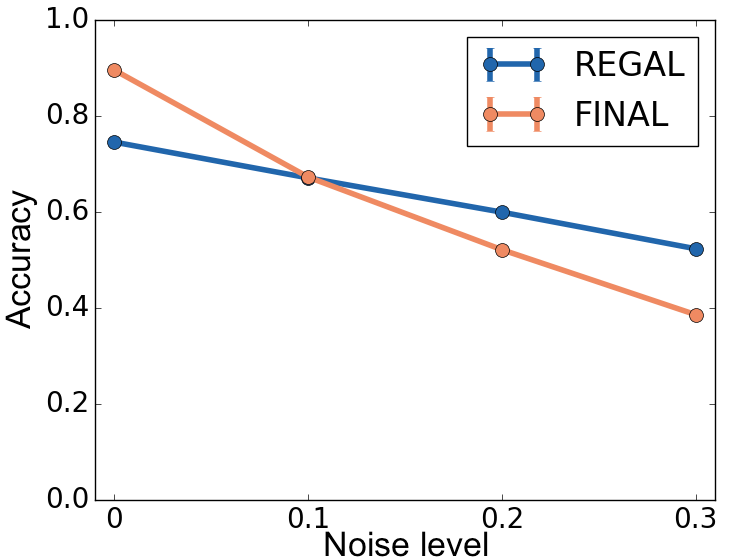
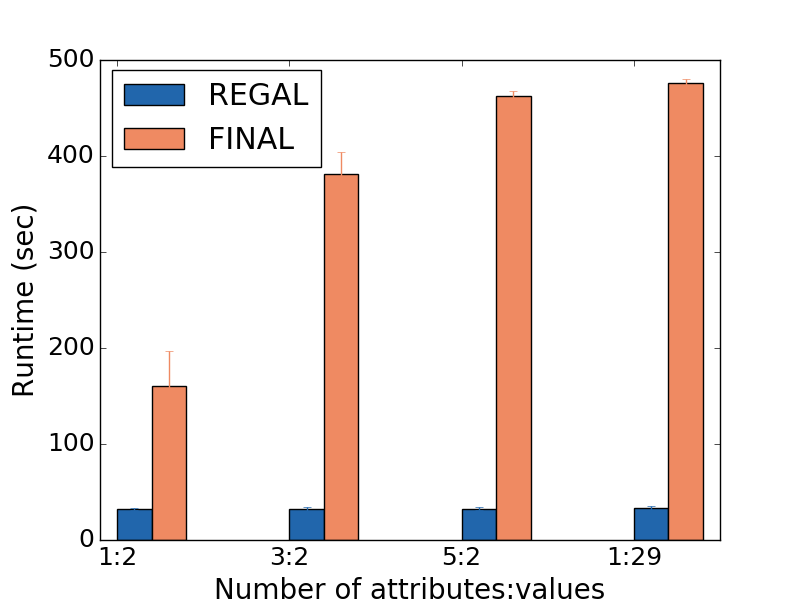
Figure 4: DBLP Network alignment with varying p_a: REGAL is more robust to attribute noise (plots a-d) and runs faster (plot e) than FINAL for various numbers and types of attributes. In (e) the x axis consists of <# of attributes: # of values> pairs corresponding to plots (a)-(d).