- The paper demonstrates that learning by sorting shuffled video frames effectively captures temporal coherence and improves unsupervised representation learning.
- It details a novel Order Prediction Network (OPN) architecture that leverages pairwise feature comparisons and advanced data augmentation to boost order prediction accuracy.
- Experimental results on UCF-101, HMDB-51, and PASCAL VOC 2007 show that this approach outperforms simple concatenation methods and delivers superior classification performance.
Unsupervised Representation Learning by Sorting Sequences
This essay presents a detailed examination of the paper titled "Unsupervised Representation Learning by Sorting Sequences" (1708.01246). The paper introduces a novel approach to learning visual representations without labeled data using an unsupervised sequence sorting task within videos. Through a detailed exploration of the experimental results and methodology, this essay seeks to elucidate the main contributions and implications of this research.
Introduction to Self-Supervised Sequence Sorting
The authors propose an unsupervised learning technique that leverages temporal coherence in videos as a supervisory signal for representation learning. This novel approach involves a sequence sorting task where a convolutional neural network (CNN) is trained to reorder temporally shuffled frames from a video sequence into their correct chronological order. This task requires the network to develop an understanding of temporal dynamics without explicit semantic labels.
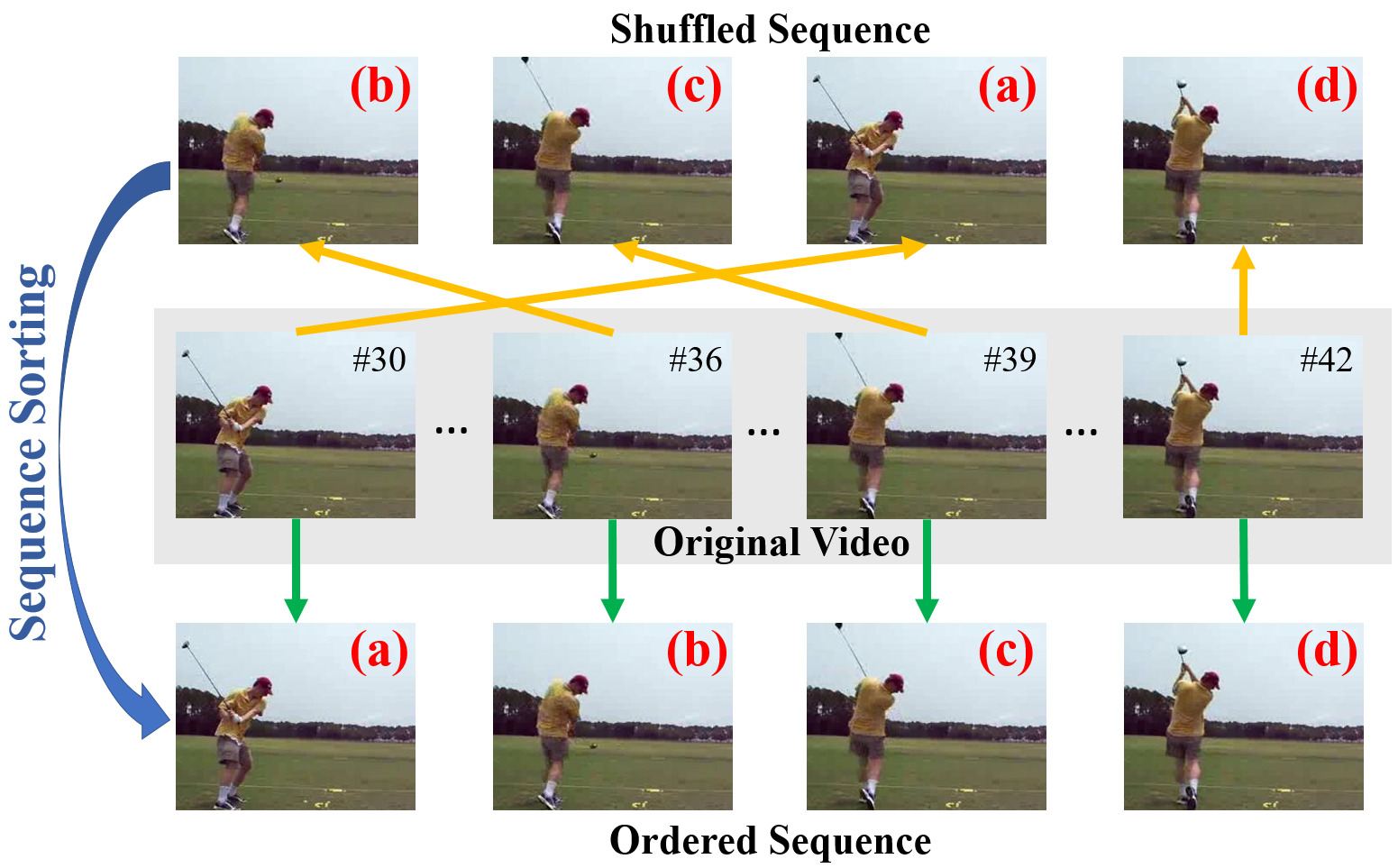
Figure 1: Representations learning by sequence sorting. Appearance variations and temporal coherence in videos offer rich supervisory signals for representation learning.
The primary motivation is to exploit the inherent structure within videos as a source of supervision, thus sidestepping the reliance on large annotated datasets which are costly and time-consuming to produce. By treating sequence sorting as a multi-class classification task, the proposed method aligns with comparison-based sorting algorithms, extracting features from frame pairs to predict order.
Order Prediction Network Architecture
To address the sequence sorting task effectively, the paper introduces an Order Prediction Network (OPN) architecture. The OPN consists of three main components: frame feature extraction, pairwise feature extraction, and order prediction. In contrast to approaches using simple concatenation of frame features, the OPN utilizes pairwise feature comparisons to enhance order prediction accuracy.
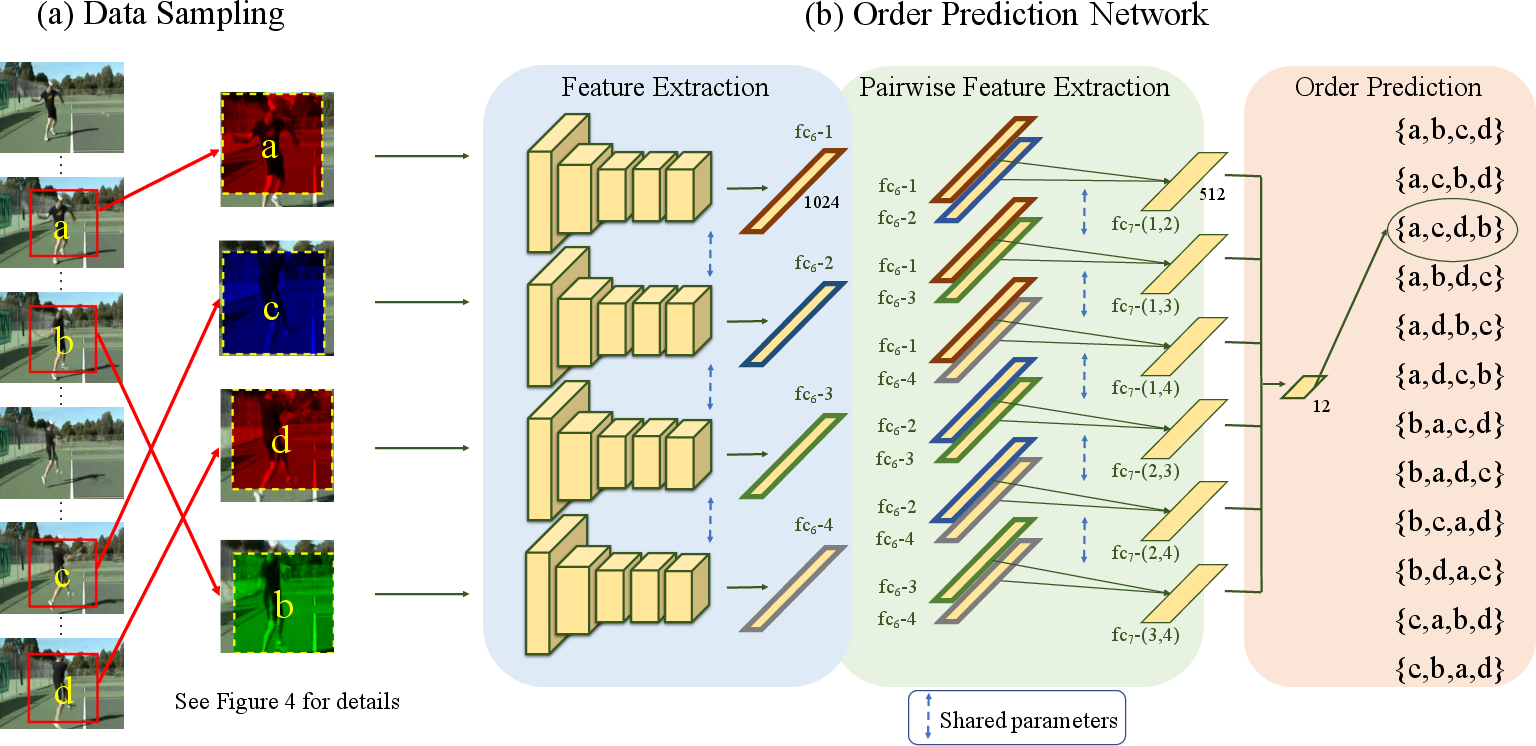
Figure 2: Overview of our approach. Our training strategy consists of two main steps.
Key strategies in the approach include frame selection based on optical flow magnitude and innovative data augmentation techniques, such as spatial jittering and channel splitting, to prevent the network from exploiting low-level features that do not contribute to high-level temporal reasoning. The OPN is shown to perform significantly better than straightforward concatenation methods, demonstrating enhanced learning of temporal features.
The proposed sequence sorting method was evaluated as a pre-training task for action recognition on the UCF-101 and HMDB-51 datasets. The results demonstrate that the OPN achieves superior classification accuracy over existing unsupervised methods. The sequence sorting framework also generalizes well to image classification and object detection tasks on the PASCAL VOC 2007 dataset, underscoring its versatility.
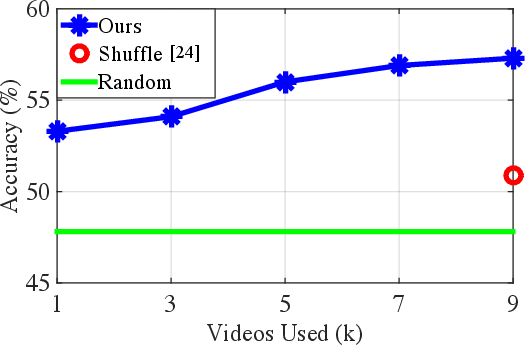
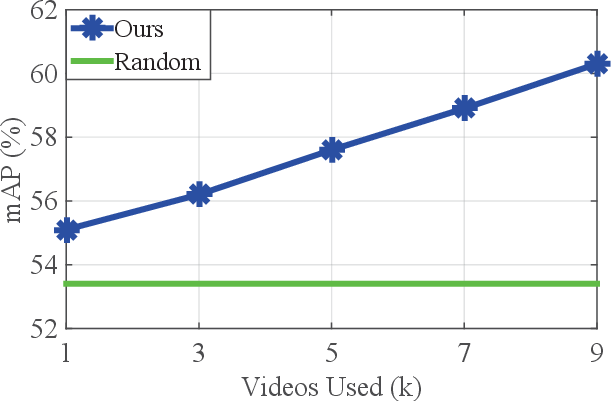
Figure 3: Performance comparison using a different amount of videos. The results show a steady performance improvement when training with more videos.
The OPN's efficacy is further validated through an extensive ablation study, highlighting the advantages of motion-awareness in dataset preparation, spatial jittering, channel splitting, and pairwise feature extraction.
Visualization of Learned Features
Visualization studies illustrate the quality and interpretability of the learned features. Low-level filters show sharper edges and increased variety compared to those from networks trained from scratch, while high-level features activate specific object parts, indicating meaningful semantic comprehension even in an unsupervised setting.




Figure 4: Visualization of Conv1 filters. Filters trained in an unsupervised manner demonstrate sharper and more varied characteristics.
Conclusion
The "Unsupervised Representation Learning by Sorting Sequences" paper presents an efficient and effective unsupervised learning methodology that leverages the temporal coherence in videos. The proposed OPN architecture provides a novel approach to unsupervised sequence sorting, demonstrating strong unsupervised feature learning capable of outperforming existing methods on benchmark datasets. This work contributes to a growing body of literature exploring self-supervised learning and presents promising directions for future research, including long-term video evolution modeling and integration with recurrent neural networks.