LabelFusion: A Pipeline for Generating Ground Truth Labels for Real RGBD Data of Cluttered Scenes
Abstract: Deep neural network (DNN) architectures have been shown to outperform traditional pipelines for object segmentation and pose estimation using RGBD data, but the performance of these DNN pipelines is directly tied to how representative the training data is of the true data. Hence a key requirement for employing these methods in practice is to have a large set of labeled data for your specific robotic manipulation task, a requirement that is not generally satisfied by existing datasets. In this paper we develop a pipeline to rapidly generate high quality RGBD data with pixelwise labels and object poses. We use an RGBD camera to collect video of a scene from multiple viewpoints and leverage existing reconstruction techniques to produce a 3D dense reconstruction. We label the 3D reconstruction using a human assisted ICP-fitting of object meshes. By reprojecting the results of labeling the 3D scene we can produce labels for each RGBD image of the scene. This pipeline enabled us to collect over 1,000,000 labeled object instances in just a few days. We use this dataset to answer questions related to how much training data is required, and of what quality the data must be, to achieve high performance from a DNN architecture.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of “LabelFusion: A Pipeline for Generating Ground Truth Labels for Real RGBD Data of Cluttered Scenes”
Overview
This paper introduces LabelFusion, a tool that helps robots learn to recognize and locate objects in messy, real-world scenes. It solves a big problem in robot vision: deep learning models need a huge amount of labeled examples to work well, but labeling images by hand is slow and expensive. LabelFusion makes it fast to create high‑quality training data by labeling a 3D scene once and then automatically creating labels for thousands of images from that scene.
Goals and Questions
In simple terms, the authors wanted to:
- Build a system that quickly produces lots of accurate labels for robot vision, using real camera data.
- Reduce the amount of human effort needed to make those labels.
- Test what kinds of training data help robot vision work best, by answering questions like:
- Is it better to train with scenes that have many objects and occlusions (things blocking each other), or just one object at a time?
- How many different background environments are needed to recognize objects in new places?
- How many camera views per scene do you need?
How the System Works (Everyday Explanation)
LabelFusion uses an RGBD camera, which is like a regular camera plus a depth sensor. The “RGB” part is color, and the “D” part is distance. Imagine holding a camera and walking around a table full of objects, filming from different angles. Here’s what happens:
- The system builds a 3D model of the scene, like a detailed 3D map, by combining all the video frames. Think of it as making a 3D collage out of lots of pictures.
- The team has 3D models (called “meshes”) of each object, like a digital version of a drill or a box.
- A person gives the computer a rough guess of where each object is by clicking three points on the object in the 3D scene and the same three points on the object’s 3D model. This is like lining up a puzzle piece where you think it goes.
- An algorithm called ICP (Iterative Closest Point) then fine‑tunes that alignment so the object model perfectly matches the points in the 3D scene. ICP is basically a smart “nudging” process that keeps adjusting until the fit is very good.
- Once the objects are correctly placed in the 3D scene, the system “projects” those objects back into each 2D image (like shining a light through a 3D shape onto a wall). This automatically creates pixel‑by‑pixel labels for every image from every viewpoint, and it also records the exact 3D position and orientation of each object (its “6DOF pose,” meaning its location in 3D plus how it’s rotated).
This approach is powerful because you label once in 3D and get thousands of labeled 2D images “for free.”
To make the pipeline easy to use:
- The camera can be hand‑carried or mounted on a robot arm.
- The 3D reconstruction runs in real time on a standard gaming GPU.
- Human effort is minimal: about 30 seconds per object per scene to set the rough alignment; the computer does the rest.
Main Findings and Why They Matter
The team used LabelFusion to produce a huge dataset very quickly:
- 352,000 labeled RGBD images.
- Over 1,000,000 labeled object instances.
- Only a few days of work, with about 30 seconds of human effort per object per scene.
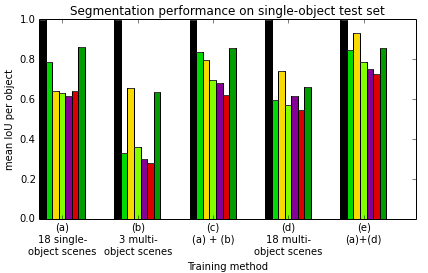
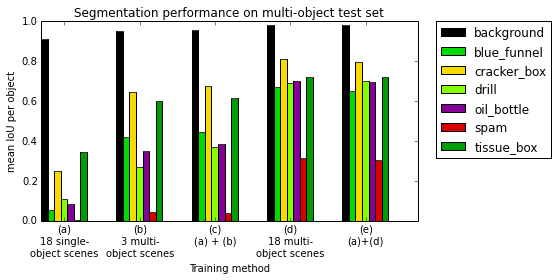
They then trained modern deep learning models for “segmentation” (figuring out which pixels belong to which object) and tested what kinds of training data work best. Key findings:
- Training with multi‑object scenes (where objects overlap and block each other) leads to much better performance on cluttered test scenes than training only on single‑object scenes. In other words, teaching the model with real‑world messiness helps it handle real‑world messiness later.
- Adding more different background environments (like different rooms, tables, and lighting) improves the model’s ability to recognize objects in new places. The gains grow steadily as you add environments, with big benefits up to around a few dozen different backgrounds.
- More camera views per scene help, but there are diminishing returns. For slow, robot‑arm scans of static scenes, performance improves up to around 0.3 frames per second; beyond that, extra frames help less. For faster hand‑carried scans, higher frame rates give more benefit.
These results give practical guidance: if you want a robot to recognize objects well in new, messy places, collect training data with many objects together and in many different environments.
Implications and Impact
LabelFusion makes it much faster and cheaper to create high‑quality training data for robot vision. Instead of labeling each image by hand, you label a 3D scene once and get thousands of labeled images automatically. This lowers the barrier for researchers and companies who need object recognition for tasks like picking items from shelves, sorting parts, or navigating cluttered spaces.
Because the pipeline and dataset are open‑source, others can use and adapt them. The study also offers clear, practical advice on data collection:
- Prefer multi‑object scenes with occlusions.
- Gather data in lots of different environments.
- Use enough views per scene, but don’t overshoot—there are diminishing returns.
Overall, LabelFusion helps robots “see” better by making the training process faster and smarter, bringing reliable robot manipulation in real‑world settings closer to everyday use.
Collections
Sign up for free to add this paper to one or more collections.