Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image
Abstract: We describe the first method to automatically estimate the 3D pose of the human body as well as its 3D shape from a single unconstrained image. We estimate a full 3D mesh and show that 2D joints alone carry a surprising amount of information about body shape. The problem is challenging because of the complexity of the human body, articulation, occlusion, clothing, lighting, and the inherent ambiguity in inferring 3D from 2D. To solve this, we first use a recently published CNN-based method, DeepCut, to predict (bottom-up) the 2D body joint locations. We then fit (top-down) a recently published statistical body shape model, called SMPL, to the 2D joints. We do so by minimizing an objective function that penalizes the error between the projected 3D model joints and detected 2D joints. Because SMPL captures correlations in human shape across the population, we are able to robustly fit it to very little data. We further leverage the 3D model to prevent solutions that cause interpenetration. We evaluate our method, SMPLify, on the Leeds Sports, HumanEva, and Human3.6M datasets, showing superior pose accuracy with respect to the state of the art.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper shows a way to turn a single photo of a person into a full 3D model that captures both how the person is posed (where their arms and legs are) and their body shape (taller, shorter, slimmer, broader, etc.). The method is called SMPLify. It combines a smart image tool that finds body joints in 2D with a realistic 3D human model that can be adjusted to match those joints.
The main questions the researchers asked
- Can we automatically recover a person’s 3D pose and body shape from just one regular photo?
- Do simple 2D joint positions (like where the elbows and knees appear in the picture) contain enough information to guess the 3D body shape?
- How can we avoid impossible 3D results, like arms going through the torso, when we only have a flat (2D) image?
- Can a single system work well on many different people and images without manual setup?
How the method works, in simple terms
Think of this like dressing up a highly realistic 3D action figure so it matches a person in a photo.
- Find the 2D joints in the picture A deep learning program (a CNN called DeepCut) looks at the photo and marks likely positions of key joints in 2D: shoulders, elbows, hips, knees, etc. It also says how confident it is for each joint.
- Start with a realistic 3D body model They use a model called SMPL. You can imagine SMPL as:
- A detailed 3D “mannequin” built from thousands of body scans, so it knows common body shapes (like sliders that control height, build, proportions).
- Hinged joints that can bend and twist to form any pose.
- A way to predict where the 3D joints are and what the body surface looks like when posed.
- “Photograph” the 3D model and match the picture They “pretend” to put a camera in front of the 3D model and project its 3D joints into the photo. Then they adjust the model’s pose and shape so these projected joints line up with the 2D joints found by the CNN. The closer the match, the better.
- Keep the pose natural and the body realistic To make sure the result makes sense, they add simple rules:
- A natural-pose rule: prefers poses people commonly make (learned from motion capture data).
- A joint-bending rule: avoids weird bends like hyperextended elbows/knees.
- A shape rule: keeps body shape within normal human ranges (based on the scan data).
- A no-collisions rule: avoids body parts going through each other. For this, they wrap each limb with “capsules” (think foam tubes around arms and legs). If capsules overlap too much, it adds a penalty so the solver fixes it.
- Solve the puzzle All these ideas are turned into a single score: mismatch to 2D joints + penalties for unnatural things. A standard optimizer then tweaks pose, shape, and camera position to lower the score. If the person is sideways and it’s unclear which way they face, the method tries both and picks the better match. It runs in under a minute per image on a normal computer.
Extra note: SMPL has separate male and female models, but they also trained a gender-neutral version to work automatically when gender isn’t known.
What they found and why it matters
Here are the key takeaways presented simply:
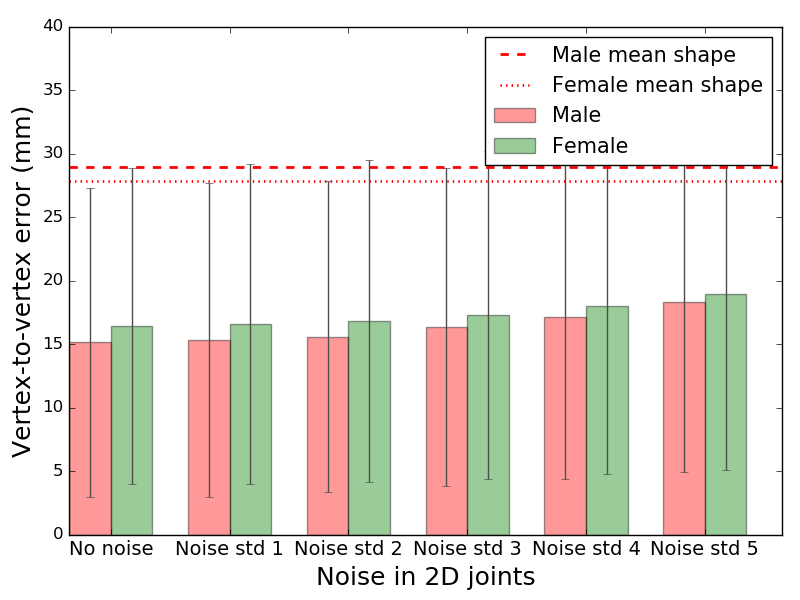
- 2D joints carry surprising information about 3D shape Using only the 2D joint positions, the system can estimate not just the pose but also a reasonable 3D body shape. In tests with synthetic data, it beat just guessing an average body shape, even when the 2D joints were noisy.
- More joints help shape accuracy When more 2D joints are available (not just torso, but also limbs), the guessed 3D shape gets better.
- Fewer impossible poses The “capsule” collision idea reduces unnatural results like arms intersecting the body, which often happen when turning flat 2D into 3D.
- Strong accuracy on benchmarks On well-known datasets (HumanEva-I and Human3.6M), SMPLify produced more accurate 3D poses than several previous methods that also start from 2D joints. On a challenging sports dataset (LSP) with complex poses and backgrounds, it showed good visual results.
- Simple but powerful pipeline Instead of inventing a complicated 3D estimator from scratch, they combined a strong 2D detector (DeepCut) with a realistic 3D body model (SMPL) and let the optimizer do the rest.
Why this is important and what could come next
Being able to build a 3D person from a single photo opens many doors:
- Animation, games, and movies: quickly create 3D characters from photos and pose them.
- Sports and health: analyze posture and movement without special cameras.
- Augmented/virtual reality: fit virtual items (like clothes) to people more realistically.
The authors suggest future improvements: use outlines (silhouettes), multiple cameras, or video frames to add more clues; include face pose and automatic gender; handle multiple people at once; and train systems that predict even richer 3D information directly from images.
Glossary
- Anthropometric constraints: Constraints based on human body measurements that restrict feasible skeletal proportions (e.g., bone lengths). "This prior knowledge typically includes both a
shape'' prior that enforces anthropometric constraints on bone lengths and apose'' prior that favors plausible poses and rules out impossible ones." - Anthropometric tables: Tabulated human body measurements used to statistically model limb-length variation. "model of limb-length variation from extremes taken from anthropometric tables."
- Articulated object: A multi-part object connected by joints whose parts can move relative to each other. "Computing interpenetration of a complex, non-convex, articulated object like the body, however, is expensive."
- Axis-angle representation: A rotation parameterization using a 3D axis and a rotation angle around it. "pose parameters represent the axis-angle representation of the relative rotation between parts."
- Bidirectional distance: A symmetric distance measure evaluating discrepancies in both directions between two shapes or sets. "to minimize the bidirectional distance between capsules and body surface."
- Capsule approximation: Modeling body parts with simple capsule primitives to enable efficient collision checks. "Given a 3D body shape we define a set of ``capsules'' that approximates the body shape."
- Chumpy: An automatic differentiation framework used for optimization in graphics/vision. "We minimize Eq.~(\ref{eq:objective}) using Powell's dogleg method~\cite{nocedal}, using OpenDR and Chumpy~\cite{chumpy,loper14}."
- Convex hull: The smallest convex set containing a shape, used here to approximate body parts for collision penalties. "They use an interpenetration term that models each body part by its convex hull."
- DeepCut: A CNN-based method for detecting 2D human body joints. "we first use a recently published CNN-based method, DeepCut, to predict (bottom-up) the 2D body joint locations."
- Geman-McClure penalty function: A robust loss function that downweights outliers in optimization. "we use a robust differentiable Geman-McClure penalty function, , \cite{geman}."
- GrabCut: A graph-cut-based interactive segmentation algorithm used to extract silhouettes. "and then use GrabCut to segment the person."
- Interpenetration: Physically implausible intersection of body parts in 3D reconstructions. "We further leverage the 3D model to prevent solutions that cause interpenetration."
- Isotropic Gaussian: A Gaussian distribution with equal variance in all directions. "We consider a 3D isotropic Gaussian with for each sphere"
- Kinematic chain: A hierarchical linkage of joints and bones defining how rotations propagate through the body. "according to , the rotation induced by the kinematic chain."
- Mixture of Gaussians: A probabilistic model representing multi-modal distributions as a weighted sum of Gaussians. "We then fit a mixture of Gaussians to approximately 1 million poses, spanning 100 subjects."
- MoSh: A method to fit detailed body shape and pose to sparse motion capture data. "We train a prior over pose from SMPL models that have been fit to the CMU mocap {\em marker} data \cite{cmu} using MoSh \cite{Loper:SIGASIA:2014}."
- Motion capture (mocap) marker data: 3D motion data recorded from markers attached to a subject, used for training pose/shape models. "SMPL models that have been fit to the CMU mocap {\em marker} data \cite{cmu}"
- Objective function: The function being minimized that encodes data fidelity and regularization/prior terms. "We do so by minimizing an objective function that penalizes the error between the projected 3D model joints and detected 2D joints."
- OpenDR: A differentiable rendering framework used to enable gradient-based optimization with images. "using OpenDR and Chumpy~\cite{chumpy,loper14}."
- Over-complete dictionary: A redundant set of basis elements that can sparsely represent signals such as poses. "Many recent methods learn sparse, over-complete dictionaries from the CMU dataset~\cite{cmu}"
- Perspective camera model: A camera projection model that maps 3D points to 2D via perspective projection. "To project SMPL joints into the image we use a perspective camera model, defined by parameters ."
- Pictorial model: A probabilistic graphical model of articulated objects where parts are connected by pairwise constraints. "combine regression forests and a 3D pictorial model to regress 3D joints."
- Pose prior: A probabilistic model that favors plausible human poses and penalizes unlikely ones. "To deal with pose ambiguity, it is important to have a good pose prior."
- Pose-dependent deformations: Shape deformations of the mesh that depend on the current pose to capture non-rigid effects. "SMPL defines pose-dependent deformations; for the gender-neutral shape model, we use the female deformations, which are general enough in practice."
- Powell's dogleg method: A trust-region optimization algorithm combining steepest descent and Gauss-Newton steps. "We minimize Eq.~(\ref{eq:objective}) using Powell's dogleg method~\cite{nocedal}"
- Principal Component Analysis: A dimensionality reduction technique used to construct shape spaces and priors. "singular values estimated via Principal Component Analysis from the shapes in the SMPL training set."
- Procrustes analysis: A procedure to align shapes via similarity transforms before comparing them. "Before computing the error we apply a similarity transform to align the reconstructed 3D joints to a common frame via the Procrustes analysis on every frame."
- Proxy geometries: Simplified shapes used to approximate complex geometry for efficient collision detection. "In graphics it is common to use proxy geometries to compute collisions efficiently~\cite{collision,Thiery:SIGASIA:2013}."
- Ridge regression: A linear regression method with L2 regularization to prevent overfitting. "using cross-validated ridge regression."
- SCAPE: A parametric human body model capturing shape and pose deformations. "the generative model (SCAPE \cite{Anguelov:2005}) is fit to the image silhouettes."
- Silhouettes: Binary figure outlines used as cues for fitting 3D body models. "fit a parametric body model to silhouettes."
- Skinned vertex-based model: A mesh model with skinning weights that deform vertices according to joint rotations. "In this work we use a skinned vertex-based model, SMPL~\cite{SMPL:2015}, and call the system that takes a 2D image and produces a posed 3D mesh, {\em SMPLify}."
- SMPL: A statistical human body model with learned shape and pose parameters. "SMPL is gender-specific; i.e. it distinguishes the shape space of females and males."
- SMPLify: The paper’s system that fits SMPL to 2D detections to recover 3D pose and shape from a single image. "The overall framework, which we call ``SMPLify'', fits within a classical paradigm of bottom up estimation (CNN) followed by top down verification (generative model)."
- Triangulated surface: A 3D mesh composed of triangular faces representing the body surface. "The output of the function is a triangulated surface, , with $6890$ vertices."
- Vertex-to-vertex Euclidean error: An accuracy metric measuring average distance between corresponding mesh vertices. "shows the mean vertex-to-vertex Euclidean error between the estimated and true shape in a canonical pose."
Collections
Sign up for free to add this paper to one or more collections.

