- The paper challenges traditional paradigms by showing that a CNN with random weights can reconstruct images accurately.
- The methodology leverages ranVGG and L-BFGS optimization to synthesize textures and perform style transfers without prior training.
- Empirical results indicate that random-weight architectures can sometimes outperform pretrained networks in deep image representation tasks.
A Powerful Generative Model Using Random Weights for the Deep Image Representation
Abstract and Introduction
The paper explores the capabilities of Convolutional Neural Networks (CNNs) with random weights, bypassing the traditional training paradigm, to perform deep visualization tasks. These include inverting image representations, synthesizing textures, and creating artistic styles. The authors challenge the consensus that trained weights are necessary for these tasks, presenting empirical evidence that the architecture itself, without training, is capable of high-quality generative tasks.
Methodology
The methodologies for this study hinge on using the VGG-19 architecture, a well-regarded CNN design, initialized with random weights, termed ranVGG. The paper replaces trained weights with Gaussian-distributed random values, then evaluates the performance of this architecture across various tasks.
- Inverting Deep Representations
The inversion task reconstructs images from feature representations in ranVGG. The aim is to match the high-level representations derived from random-weight networks to those produced by trained networks. The approach applies L-BFGS optimization to reduce the Euclidean loss between the original and synthesized representation space.

Figure 1: Reconstructions of the monkey from each layer of the random weight CNN, ranVGG. The monkey image is well reconstructed from activations of any of the 16 convolutional layers after the rectifier and the 5 average pooling layers, and we could still see the rough contours from the first two fully connected layers.
- Texture Synthesis
For texture synthesis, the method leverages the gram matrix to capture the style of textures and iteratively refines the output image, contrasting against the trained VGG inception. The untrained architecture surprisingly yields comparable and sometimes superior perceptual textures.

Figure 2: Generated textures using random weights. Each row corresponds to a different processing stage in the random weight network ranVGG. Considering only the lowest layer, conv1_1, the synthesised textures are of lowest granularity, showing very local structure. Increasing the number of layers on which we match the texture representation (conv1_1 plus conv2_1 for the second row, etc), we have higher organizations of the previous local structure. The third row and the forth row well synthesis the textures of the original images. The lowest row corresponds to the result of using the trained VGG to match the texture representation from conv1_1, conv2_1 conv3_1 and conv4_1.
- Style Transfer
Combining content and style from different sources, the paper demonstrates that ranVGG enables impressive style transfer without weight training. The results reflect high fidelity to artistic styles while maintaining essential content characteristics.

Figure 3: Style transfer of Chinese paintings on the untrained ranVGG. We select several Chinese paintings for the style (first column), including The Great Wall by Songyan Qian 1975, a painting of anonymous author. We select the mountain photographs (second column) as the content images. The created images performed on the untrained ranVGG are shown in the third column, which seem to have learned how to paint the rocks and clouds from paintings of the first column and transfer the style to the content to "draw" Chinese landscape paintings.
Results and Analysis
- Inversion Accuracy:
Reconstructions utilizing ranVGG outperform results from models with pretrained weights, showcasing robustness across various convolutional layers and maintaining significant portions of the original image details.
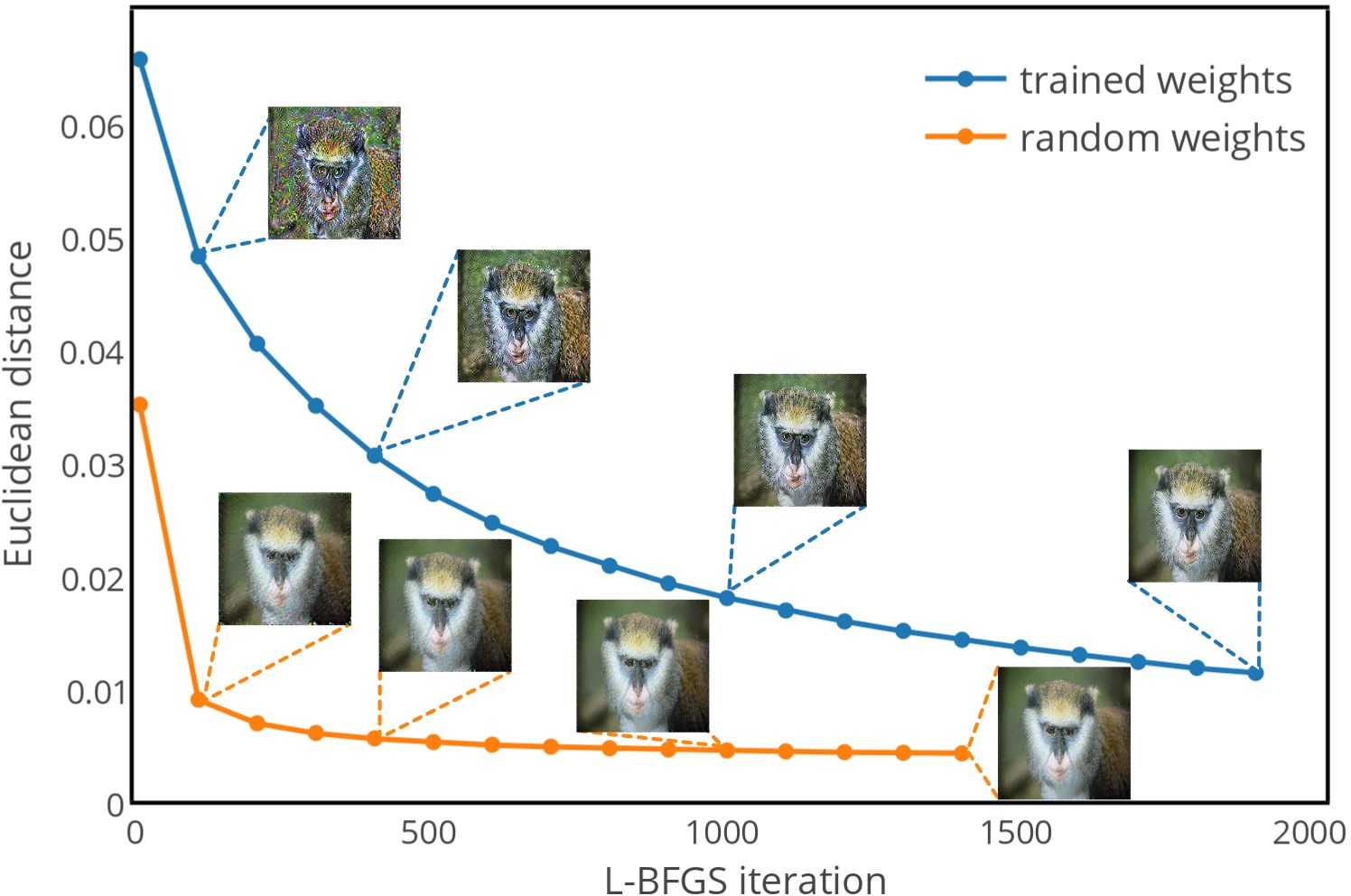
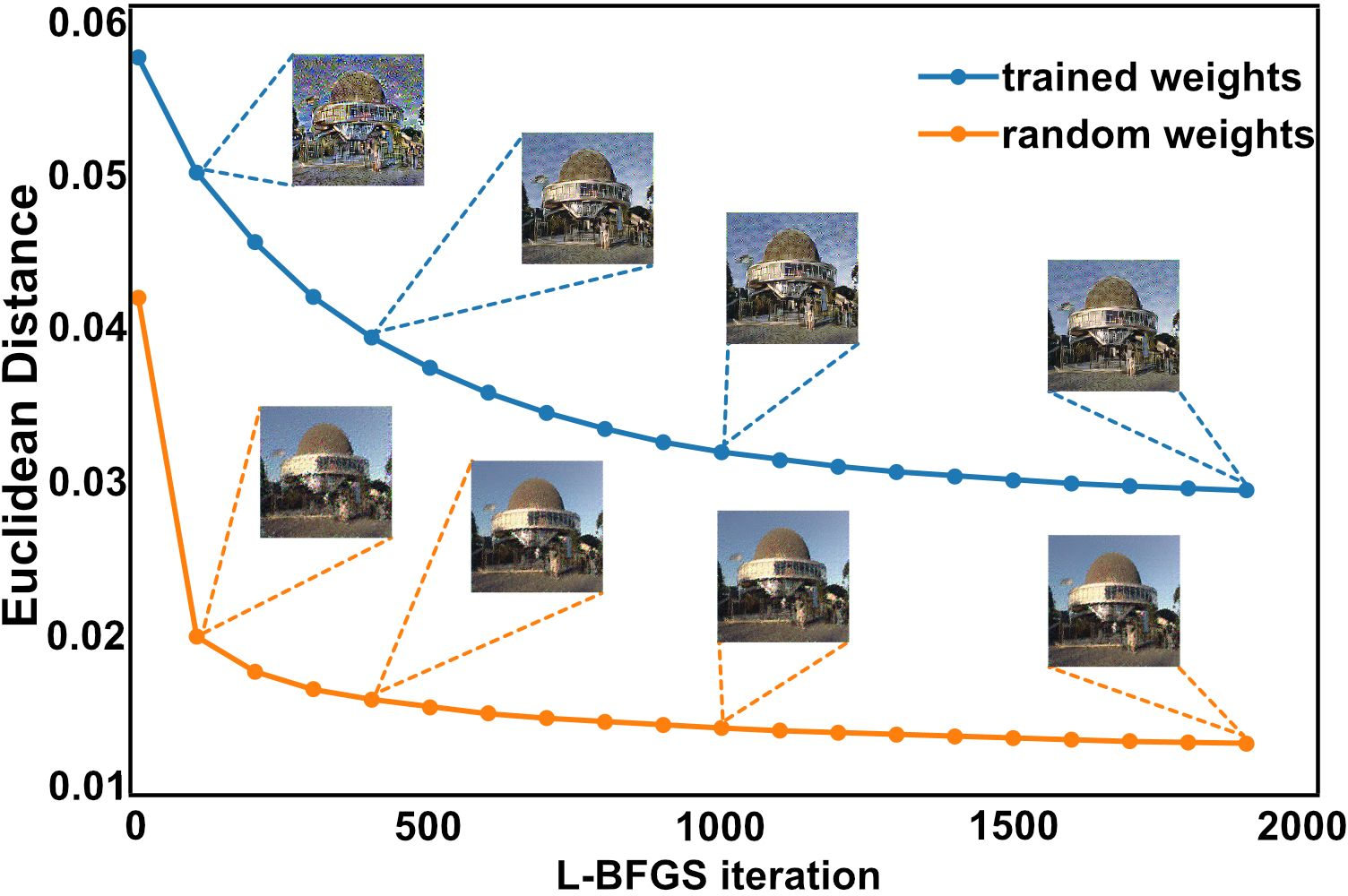
Figure 4: Reconstruction qualities of conv5_1 during the gradient descent iterations, showing comparison of our method on ranVGG and VGG. Illustrations from the 10th L-BFGS iteration. The process on the untrained ranVGG converges quickly and yields higher quality results within 100 iterations as compared with the final results after 2000 iterations on the pretrained VGG.
- Texture Synthesis:
The random weights provide surprisingly coherent texture matches, revealing the inherent strength of network architectures in capturing stylistic attributes without training. The synthesized images retain original patterns without significant loss of perceptual quality.
- Artistic Style Transfer:
The process achieves high perceptual quality outputs, proving competitive with prior methods leveraging trained networks. These results indicate a promising direction for further advancements in understanding network architectures and optimizing computational efficiency.
Conclusion
This research substantiates the hypothesis that the architectural complexity of CNNs fundamentally supports generative tasks, even absent training. This challenges the conventional belief about the indispensability of pre-trained weights for deep image representation tasks. Future research might explore deeper architectural variations and their intrinsic representation capabilities, offering insights into efficient model design and potential reductions in pre-training requirements.