- The paper introduces a novel comparative measure integrating similarity (Jaccard) and distance measures with an OWA operator.
- It rigorously proves key properties like self-identity, symmetry, separability, and transitivity, ensuring robust fuzzy set analysis.
- Demonstrated on real datasets, the measure enhances automated classification and ranking in data-driven systems.
Analysing Fuzzy Sets Through Combining Measures of Similarity and Distance
The paper "Analysing Fuzzy Sets Through Combining Measures of Similarity and Distance" (1409.1046) introduces a novel approach for the analysis and comparison of fuzzy sets by integrating the measures of similarity and distance through an Ordered Weighted Average (OWA) operator. This integration aims to overcome the limitations and ambiguities of using these measures independently, particularly in settings where large numbers of fuzzy sets are generated from real data. The paper presents the properties, derivation, and application of this combined measure, demonstrating its benefits over traditional methods.
Background and Motivation
Fuzzy sets (FSs) are utilized to manage uncertainty in various applications by assigning membership values between 0 and 1 to elements within a set. While measures of similarity (SMs) assess the similarity of FSs based on their membership values, measures of distance (DMs) evaluate the positional distance between FSs. Each measure provides unique insights; however, when considered independently, they can produce misleading results, especially in complex systems with numerous FSs derived from data. For example, SMs may fail to convey distance information when FSs are disjoint, while DMs can yield ambiguous results when one FS is a subset of another.
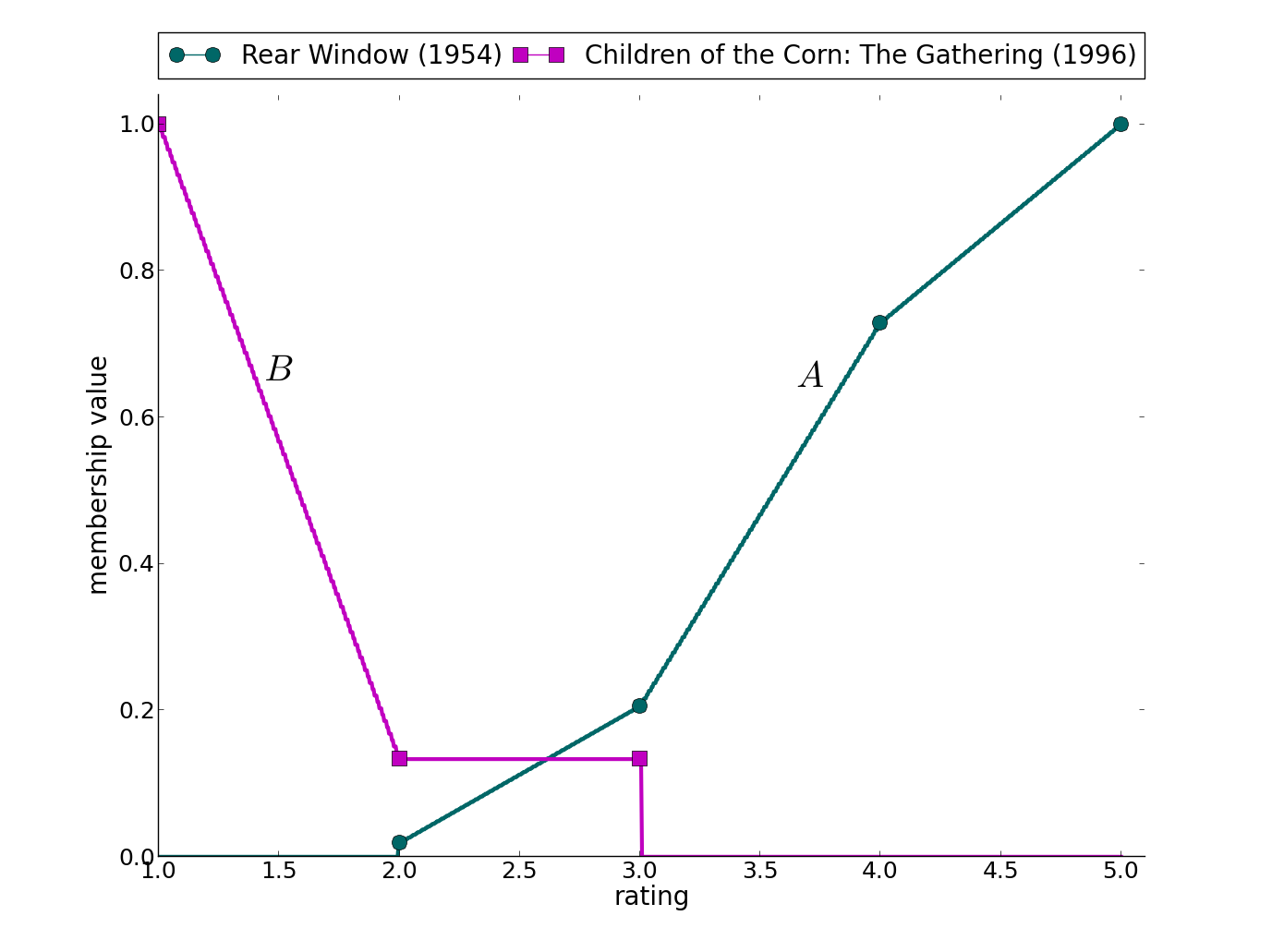
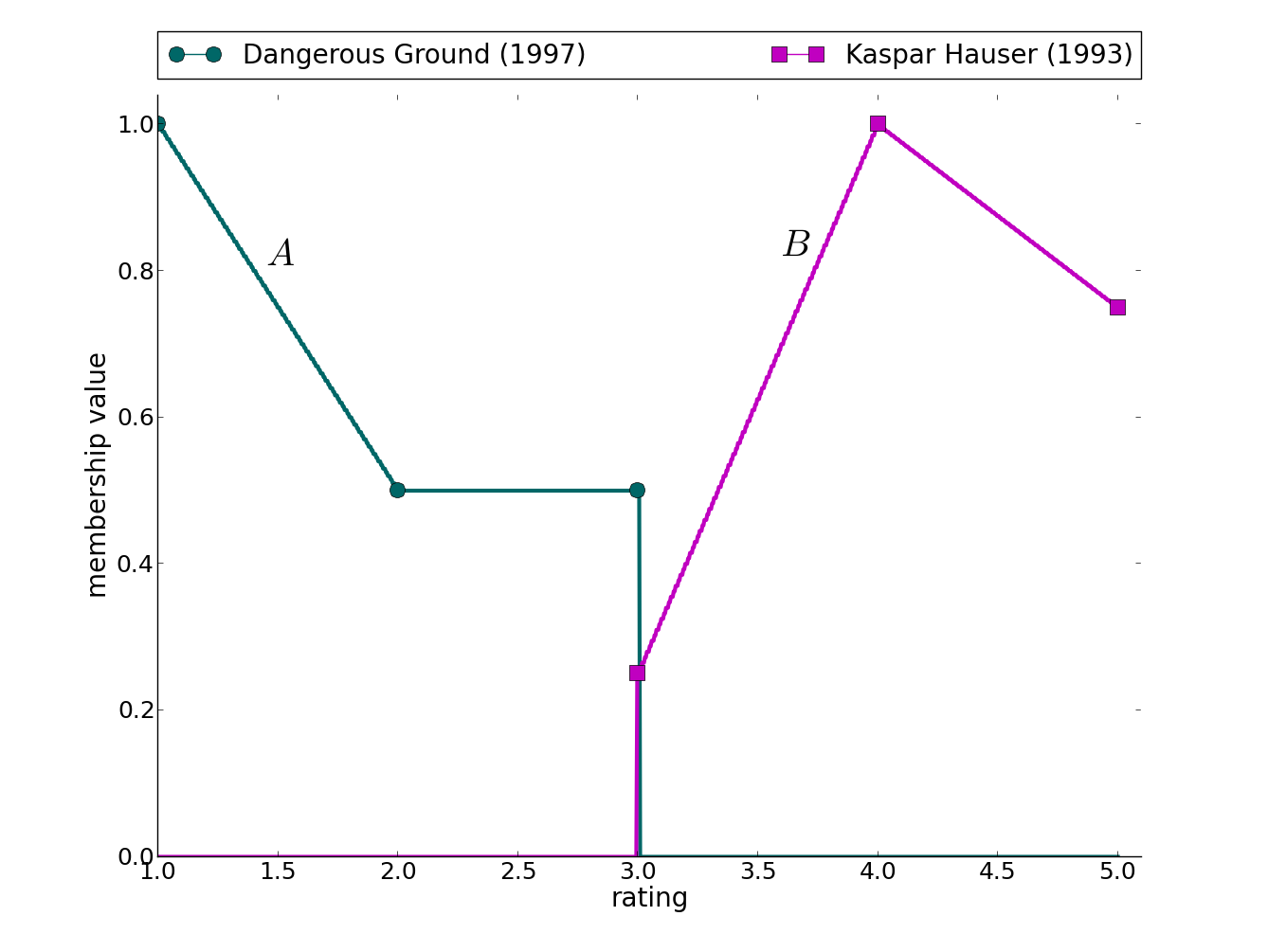
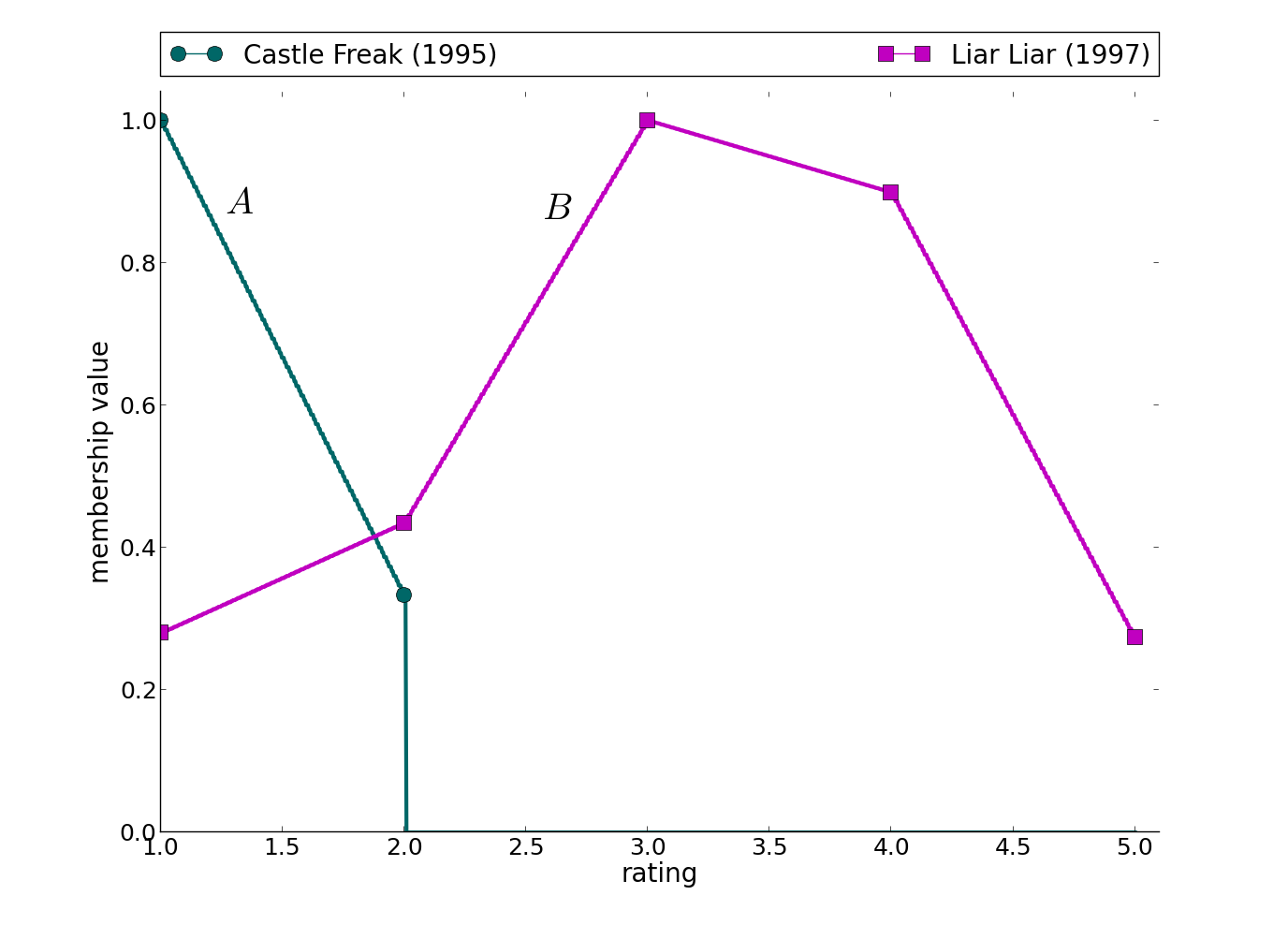
Figure 1: Real-data driven fuzzy sets constructed from the Movie Lens dataset to demonstrate properties of similarity and distance measures.
The paper proposes a fusion of SMs and DMs into a single comparative measure, enabling the analysis of FSs with enhanced detail and reduced ambiguity.
Comparative Measure Construction
The construction of the comparative measure leverages an OWA operator to aggregate SMs and DMs. The measure is designed to produce results within the interval [−1,1], where values close to 0 imply identical FSs, and values of ±1 indicate maximal dissimilarity/distance. Importantly, the negativity or positivity of the result provides directional information about FS positioning.
The measure is formally defined as:
c(A,B)={F((1−s(A,B)), (λd(A,B))),d(A,B)≥0 F(−(1−s(A,B)), (λd(A,B))),otherwise
where F represents the OWA aggregation, s(A,B) denotes the Jaccard similarity measure, d(A,B) represents the directional distance measure, and λ is the maximal possible distance within the universe of discourse (UoD).
Properties and Application
The theoretical properties of the combined measure, such as self-identity, symmetry, partial symmetry, separability, transitivity, and triangle inequality, are rigorously proven, ensuring it is robust for practical applications.
Demonstrations highlight the comparative measure's efficacy in real-world scenarios, such as classification alignment and ranking within datasets. In Fig. 1, the comparative measure successfully distinguishes FS relationships across different domains, including films rated on a scale of 1 to 5 in the Movie Lens dataset, providing meaningful automated analyses without human intervention.
Implications and Future Directions
The integration of SMs and DMs into one comparative measure offers a robust tool for automatic FS comparison. This advancement is particularly significant for applications involving dynamic and extensive FS datasets, such as data-driven decision-making systems and semantic analysis.
Future research could explore the extension of this approach to type-2 FSs and the development of fuzzy measures that inherently express similarity and distance with uncertainty, reflecting the intrinsic nature of FSs.
Conclusion
This paper presents a significant contribution to the field of fuzzy logic by resolving inherent ambiguities within FS analysis, thus enhancing the capability and reliability of automated systems dealing with uncertainty. By employing the proposed comparative measure, researchers and practitioners can drive more nuanced, informed analyses in various domains involving FSs.