- The paper demonstrates that human ratings on sentence formality using a five-point Likert scale show significant inter-rater reliability, evidenced by statistical measures like Cohen’s κ and Krippendorff’s α.
- The methodology included a pilot phase with 100 sentences followed by a more extensive experiment with 500 sentences drawn from diverse sources such as blogs, news, forums, and academic texts.
- The findings highlight the challenges of subjective linguistic assessments and provide a foundation for developing automated formality scoring systems in natural language processing.
This analysis focuses on the inter-rater reliability of sentence formality assessments using a five-point Likert scale. Through a study involving human judgments on sentence formality, the authors aim to lay the groundwork for automatic formality scoring mechanisms. This research is significant in that it extends prior work on formality assessments and explores the challenges in human annotation of subjective linguistic features.
Study Objectives and Methodology
The primary aim of the study is to evaluate the extent of agreement between human raters assessing sentence formality using a structured Likert scale, and to analyze the rating distributions across different sentence categories. The study involves two phases: a warm-up pilot test with 100 sentences and a subsequent larger experimental phase involving a set of 500 sentences drawn from diverse textual categories including blogs, news articles, forums, and academic papers.
Inter-rater Agreement
To gauge the reliability of rater judgments, several statistical measures were deployed, including Cohen's κ, Krippendorff's α, and Spearman's ρ. High values of γ and Kendall's τb indicated meaningful agreement beyond mere chance, particularly emphasizing concordance in the ordinal nature of ratings.
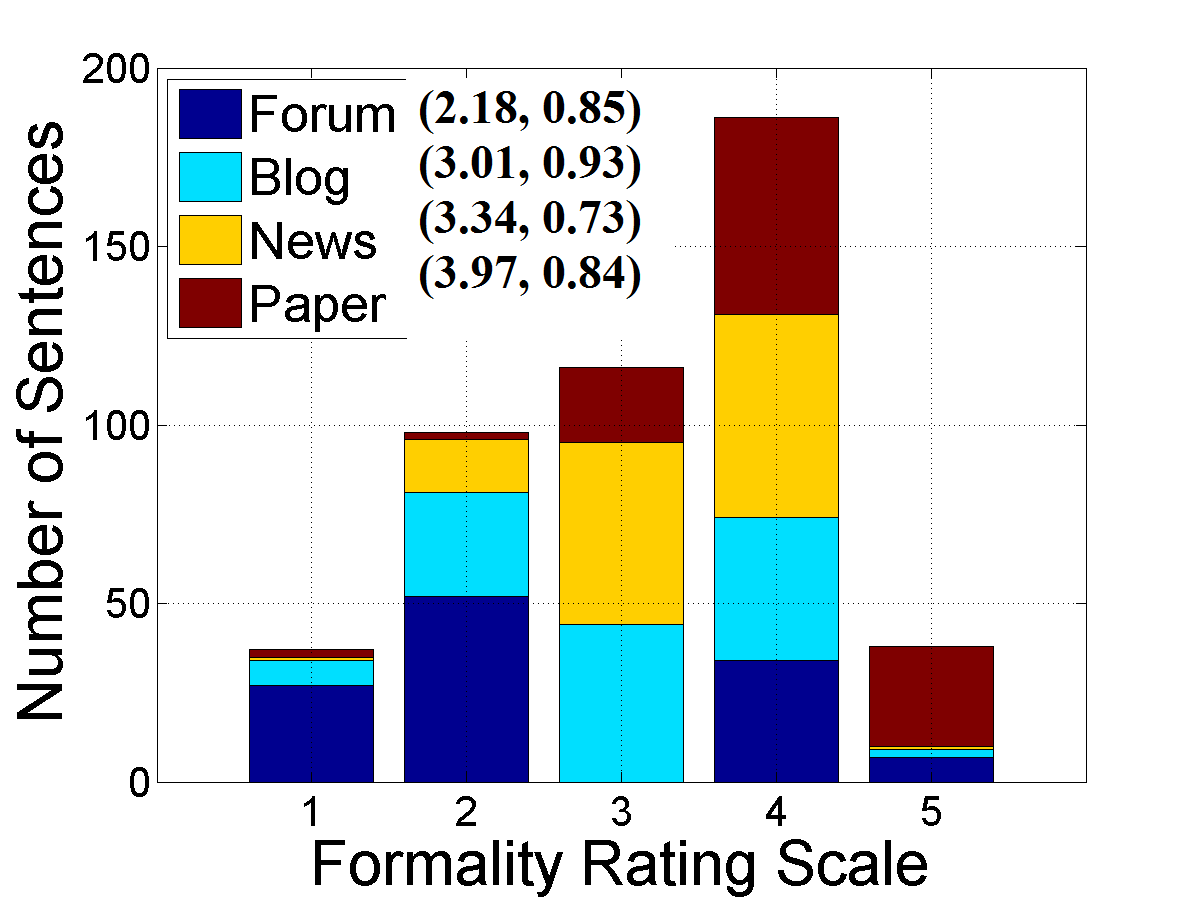
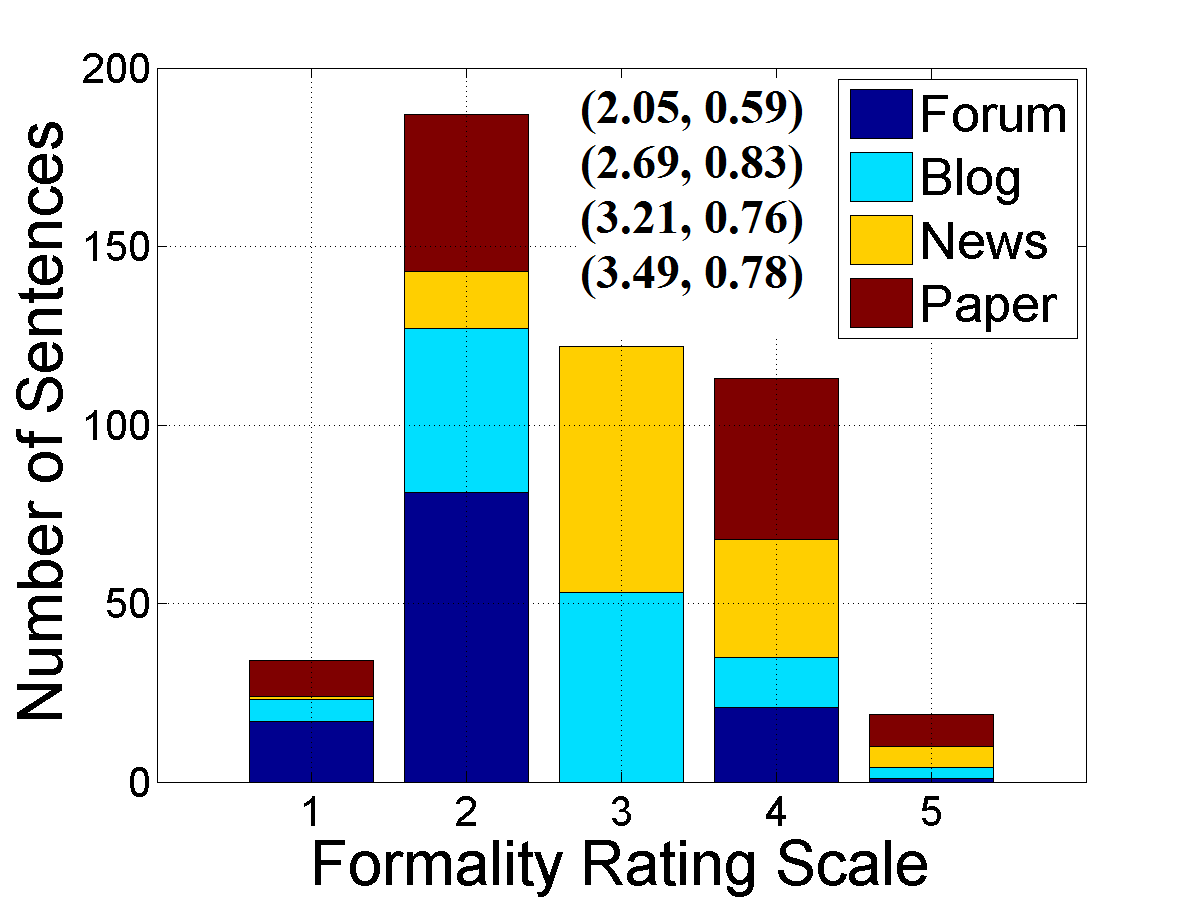
Figure 1: Sentence formality rating histograms for raters, showing mean ratings and standard deviations for the actual set.
Analysis of Rating Distributions
The analysis demonstrated variance in sentence formality ratings between raters, illustrating intrinsic subjectivity and the central tendency bias associated with Likert scales. This bias likely affects the rating accuracy, emphasizing the need for careful consideration when designing formality assessment frameworks.
Different sentence types yielded distinct formality distributions. Academic sentences generally received higher ratings, aligning with the perception of formal writing as dictated by published norms. The Kruskal-Wallis test confirmed significant differences in formality ratings across text categories, affirming that judgments varied systematically.
Implementation of Findings and Difficulties Identified
Generating a formality rating corpus informed by human evaluation sets a foundation for developing machine learning models. The observed inter-rater agreement supports the creation of annotated data potentially utilized for supervised learning algorithms. However, challenges remain, such as X-marked confounding sentences that defy clear classification, often due to syntactic anomalies or incomplete phrasing.
Understanding these difficulties guides future refinements in annotation guidelines and automated scoring algorithm development. Annotation discrepancies highlight the need for comprehensive guidelines to aid raters in consistent evaluations, advancing towards a nuanced automatic detection system.
Conclusion
The paper's insights into human consensus on sentence formality ratings offer crucial information for enhancing computational systems that process and evaluate linguistic formality. Such systems will benefit from these findings to improve natural language processing applications, from content tonality adjustments to the design of interfaces capable of tailoring language across different formality thresholds. Further explorations into automated systems' accuracy in mimicking human judgment of formality could lead to robust computational tools in the future, streamlining formality analyses in diverse contexts and applications.

