Universal Transformers
This presentation explores Universal Transformers, a groundbreaking architecture that enhances standard Transformers with computational universality through recurrent processing. By iteratively refining representations at each sequence position using self-attention and incorporating adaptive dynamic halting, Universal Transformers achieve superior generalization on algorithmic tasks, set new benchmarks on language understanding problems, and demonstrate practical improvements in machine translation—all while bridging theoretical expressivity with real-world performance.Script
Standard Transformers process sequences in a single fixed pass through their layers. But what if a model could decide for itself how many computational steps each part of a sequence needs? Universal Transformers introduce recurrence into the Transformer architecture, giving the model the power to iterate and refine its understanding.
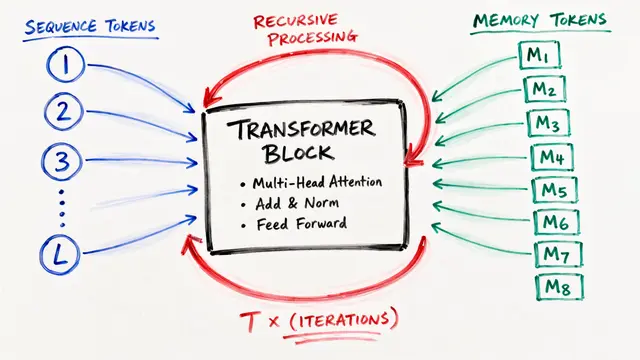
The key insight is simple but powerful. Instead of passing information through a fixed number of layers, Universal Transformers iteratively refine representations at each sequence position. A dynamic halting mechanism allows positions requiring more reasoning to compute longer, while simpler elements stop early. This makes the model Turing-complete in theory, yet efficient in practice.
Let's see how this iterative refinement actually operates.
At each step, the model applies self-attention across all positions, allowing information to flow globally through the sequence. Then a recurrent transition function refines each position's representation. This process repeats, with each iteration deepening the model's understanding. Unlike traditional recurrent networks that process sequentially, Universal Transformers maintain parallelism by updating all positions simultaneously in each recurrent step.
The results demonstrate both theoretical elegance and practical power. On algorithmic tasks like sequence copying and reversal, Universal Transformers generalize to lengths never seen during training—something fixed-depth models struggle with. For language understanding, they set new records on complex reasoning problems requiring multiple supporting facts. In machine translation, the iterative refinement captures linguistic structures more effectively, yielding measurable quality improvements.
This visualization reveals the model's intelligence in allocating computation. Darker regions indicate longer processing times. Notice how the model automatically spends more steps on complex reasoning positions—those requiring integration of multiple facts—while breezing through simpler content. This adaptive behavior emerges from training, not hand-crafted rules, showing that the model learns not just what to compute, but how much computation each decision demands.
Universal Transformers demonstrate that making models computationally universal doesn't mean sacrificing practical performance. By learning when to think longer, they bridge the gap between theoretical expressivity and real-world effectiveness. Visit EmergentMind.com to explore this paper further and create your own research videos.