δ-mem: Efficient Online Memory for Large Language Models
This lightning talk introduces δ-mem, a breakthrough approach to giving large language models persistent, dynamic memory without the computational burden of extended context windows or retrieval systems. By maintaining a compact 8×8 associative memory state that directly modulates attention during inference, δ-mem achieves dramatic performance improvements on memory-intensive tasks while adding less than 0.12% parameters and minimal computational overhead. We'll explore how this elegant mechanism works, examine its impressive benchmark results, and consider what it means for the future of continually learning AI systems.Script
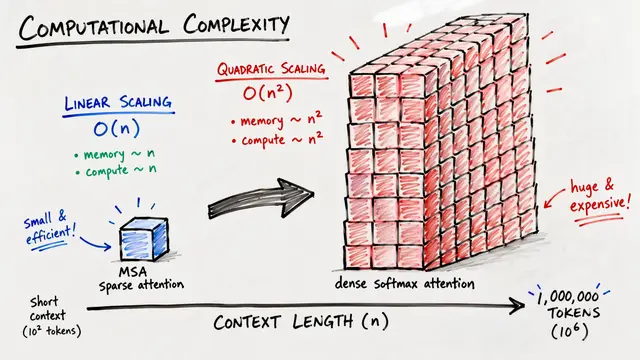
What happens when a language model needs to remember a conversation from yesterday, or track facts across a multi-turn dialogue, without exponentially expanding its context window? Existing solutions either burn compute on massive prompts or lose critical information through compression and retrieval noise.
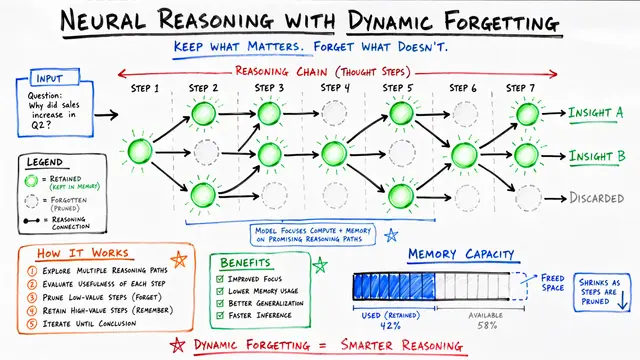
Delta mem introduces a compact associative memory that lives outside the input sequence entirely. It maintains an 8 by 8 matrix that reads out memory signals, injects low rank corrections directly into attention, and updates itself online using a delta rule inspired by classical neural memory.
On memory agent bench, delta mem achieves 1.31 times the performance of the frozen backbone, and on one memory intensive subtask, it nearly doubles the score from 26 to 50. Critically, it does this while maintaining strong results on general benchmarks, proving there's no tradeoff between memory augmentation and base capability.
The efficiency story is remarkable. Delta mem adds only 4.87 million parameters, about 0.12 percent of the backbone, and inference throughput remains nearly identical to the vanilla model. Unlike retrieval systems or parameter heavy memory banks, the cost is independent of context length, because all operations touch only that compact 8 by 8 state.
In ablation studies where the explicit history was removed entirely, delta mem still recovered context relevant information and outperformed baselines by wide margins. The memory state itself had learned to store what mattered, compensating for the absence of raw text and proving that associative learning can replace brute force context.
Delta mem offers a blueprint for lifelong, continually learning language models that adapt dynamically without retraining or context explosion. If you're curious about efficient memory architectures or building persistent AI systems, explore the full paper and create your own video breakdowns at emergentmind.com.