Mesh Splatting for End-to-end Multiview Surface Reconstruction
Abstract: Surfaces are typically represented as meshes, which can be extracted from volumetric fields via meshing or optimized directly as surface parameterizations. Volumetric representations occupy 3D space and have a large effective receptive field along rays, enabling stable and efficient optimization via volumetric rendering; however, subsequent meshing often produces overly dense meshes and introduces accumulated errors. In contrast, pure surface methods avoid meshing but capture only boundary geometry with a single-layer receptive field, making it difficult to learn intricate geometric details and increasing reliance on priors (e.g., shading or normals). We bridge this gap by differentiably turning a surface representation into a volumetric one, enabling end-to-end surface reconstruction via volumetric rendering to model complex geometries. Specifically, we soften a mesh into multiple semi-transparent layers that remain differentiable with respect to the base mesh, endowing it with a controllable 3D receptive field. Combined with a splatting-based renderer and a topology-control strategy, our method can be optimized in about 20 minutes to achieve accurate surface reconstruction while substantially improving mesh quality.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making high-quality 3D models (called meshes) from regular photos taken from different angles. The authors propose a new way to train meshes so they become accurate, smooth, and not overly heavy (they use fewer triangles), while still learning detailed shapes. Their key idea is to temporarily turn a mesh into a “soft,” semi-transparent stack of layers so it can be trained like a 3D volume, then keep the benefits of a clean, editable mesh at the end.
What problem are they trying to solve?
Many existing methods fall into two camps:
- Volumetric methods: They model the whole 3D space and train by “looking” through it from many camera views (this is called volumetric rendering). These methods are stable and learn good detail, but later you must convert the volume into a mesh, which can add errors and often makes meshes too dense.
- Pure mesh methods: They directly optimize the surface (the mesh), which is great for clean, simple models you can edit. But they only “see” a thin layer, so they struggle to learn fine details from images and often need extra tricks like estimating shading or normals, which can be unreliable.
The paper asks: Can we get the best of both worlds—train meshes with strong image supervision like volumes, but keep the mesh’s quality and editability?
Key ideas and questions
- How can we make a mesh behave more like a volume during training, so it sees more 3D context and learns details better?
- Can this be done end-to-end (from images to final mesh) without a separate, error-prone “meshing” step?
- Can we keep the mesh clean and efficient—fewer triangles, good topology (connections), and smooth surfaces?
- Can training be fast, practical, and accurate?
How does the method work? (Simple explanation with analogies)
Think of a mesh as a thin shell made of many small flat pieces (triangles). The authors “soften” this shell:
- Soft mesh layers: They make several thin, semi-transparent layers around the original mesh, like stacking sheets of tracing paper around it. Each layer is offset slightly outward or inward along the surface direction (its normal).
- Transparency and “distance”: Each layer’s transparency is computed based on how far it is from the base mesh. Layers closer to where the real surface should be appear more prominently in training, guiding the base mesh to move toward the correct shape.
- Mesh splatting renderer: Instead of the usual volume renderer, they use a fast “splatting” approach for triangles. Imagine painting triangles onto the image, front-to-back, and blending them using alpha (transparency). A small neural network predicts the color at each point, and everything is differentiable—so the mesh can be updated directly from image differences.
- Topology control: “Topology” means how parts of the surface connect—holes, handles, separate pieces. They use a two-step strategy:
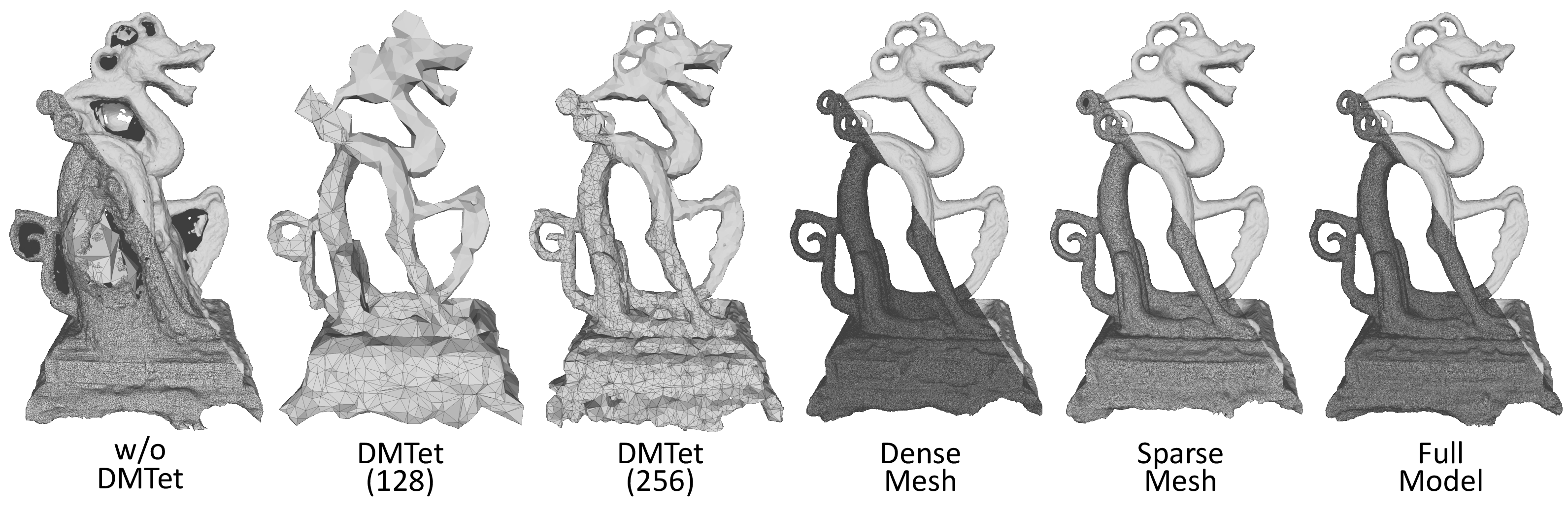
- Early: A tetrahedral grid (DMTet) acts like training wheels to stabilize the overall shape.
- Later: Continuous Remeshing regularly reweaves the triangle network to keep triangles evenly shaped and control how many there are. This makes the final mesh cleaner and practical.
To make the ideas concrete:
- Volumetric rendering is like looking through foggy layers: you see everything along a viewing ray and blend what you see, closer to farther.
- The “receptive field” is how much 3D context the model can use. A single opaque surface has a tiny receptive field (just the boundary). Multiple semi-transparent layers give a thicker region to learn from, so details are easier to capture.
- Signed distance is simply “how far inside or outside is this point from the base surface,” with a sign telling which side you’re on.
What did they find, and why does it matter?
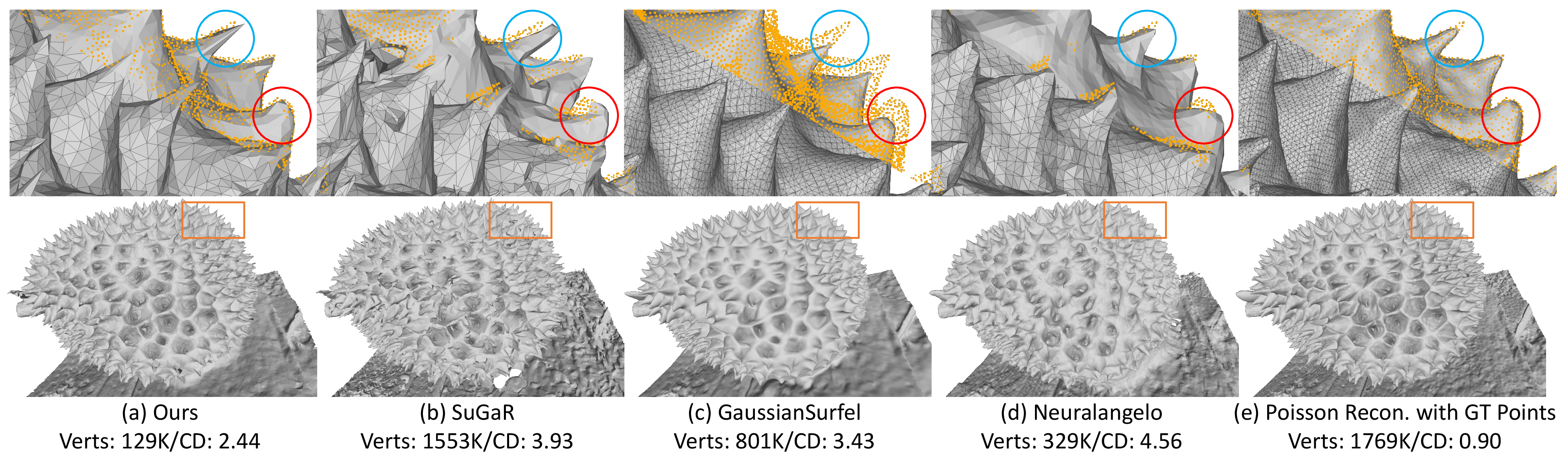
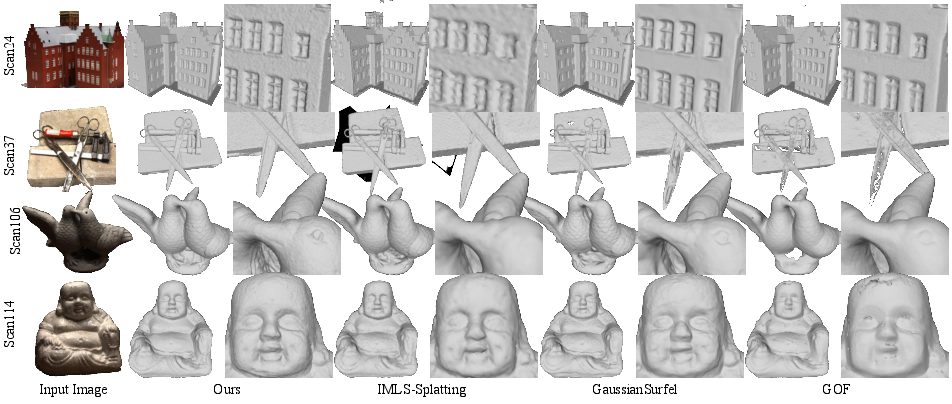
- Accuracy with fewer triangles: On popular datasets (DTU and BlendedMVS), their method reaches top or near-top accuracy while using fewer mesh vertices. That’s good because smaller meshes are faster and easier to use in games, films, and VR.
- End-to-end meshes avoid meshing errors: Since they train the mesh directly with image supervision, they don’t need a separate step to convert a volume to a mesh. This avoids the usual problems of dense, messy meshes and misalignments that other pipelines suffer from.
- Training is fast: About 20 minutes per scene on a single GPU, thanks to the splatting-based renderer.
- Multi-layer softening is crucial: Ablation tests show that removing the soft layers and relying only on shading supervision leads to worse detail. The semi-transparent layers are key to learning fine geometry from images.
- Hybrid topology control is best: Starting with DMTet for stability and then switching to Continuous Remeshing produces cleaner meshes and better global shape than using either one alone.
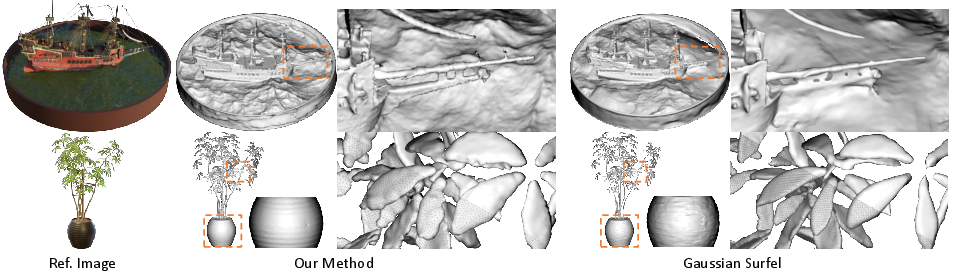
They also tried scene-level examples and synthetic cases with thin structures. Their method handles many thin details better than some competitors, but very tiny features (like cables or hair) can still be challenging.
Why is this important?
This approach blends the strengths of two worlds: volumetric training’s powerful image-based learning and mesh optimization’s clean, editable outputs. That means:
- Better 3D assets for real applications: Film, games, and VR benefit from meshes that are both accurate and efficient.
- Fewer downstream fixes: Cleaner topology and fewer triangles reduce time spent on mesh cleanup and make physics simulation more reliable.
- Practical pipelines: End-to-end training that avoids error-prone meshing steps can speed up content creation and improve quality.
A few helpful terms
- Mesh: A 3D surface made of small flat triangles connected at corners (vertices).
- Topology: How parts of the surface connect—think holes, separate pieces, or handles.
- Remeshing: Reweaving the triangle network to improve shape and distribution of triangles.
- Volumetric rendering: Simulating how light travels through semi-transparent material, blending front-to-back.
- Receptive field: How much surrounding 3D area the model can learn from at once.
Final takeaway
By turning a solid mesh into a stack of semi-transparent layers during training, the model can “see” more 3D context and learn detailed shapes directly from images. After training, you keep a clean, high-quality mesh with controlled complexity. It’s a practical, fast, and accurate way to reconstruct surfaces for real-world 3D use—and a strong step toward better, end-to-end 3D modeling pipelines.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research.
- Gradient theory and convergence: No formal analysis of how the stop-gradient trick and the mapping affect gradient bias, stability, and convergence of geometry updates; conditions for guaranteed improvement of the base mesh are unclear.
- Learnable density concentration (): It is unspecified whether is global, per-layer, or per-vertex; risks of collapse (e.g., trivial sharp/flat densities), suitable regularization, initialization, and scheduling are not analyzed.
- Layer sampling strategy: The offsets are “randomly sampled” with a fixed band (±10 cm) and N=5 layers; there is no study on optimal number of layers, spacing, distribution, resampling schedule, or adaptive/hierarchical bandwidths tied to uncertainty or reconstruction error.
- Offset direction via vertex normals: Offsetting along vertex normals can cause self-intersections and instability in high-curvature or non-manifold regions; robust alternatives (e.g., geodesic offsets, signed-distance-based offsets, collision constraints) are not explored.
- Failure when base mesh is far from the true surface: The method can fail when the thin softened band does not overlap the target; no mechanism is provided to detect this and adaptively expand/relocate the layers or switch to a coarser global search.
- Topology control after DMTet freeze: Once DMTet is disabled, topology changes rely on Continuous Remeshing (primarily quality/size control), not true genus changes; strategies for late-stage topology edits or recovery from early topology mistakes are missing.
- Non-differentiable remeshing impact: Continuous Remeshing is run during training but is non-differentiable; its effect on optimization stability, convergence guarantees, and possible bias is not quantified.
- Scaling to large scenes: The approach is memory-bound by DMTet resolution and splatting; there is no demonstrated end-to-end pipeline for room- or city-scale scenes, nor an out-of-core, tiled, or multi-GPU strategy.
- Renderer efficiency and scalability: Mesh Splatting is still slower/more memory-hungry than Gaussian splatting; concrete algorithmic optimizations (culling, LOD, adaptive tessellation, per-tile sorting complexity, anti-aliasing) and asymptotic complexity analyses are absent.
- Visibility, ordering, and numerical robustness: Depth sorting per pixel for semi-transparent layers can be fragile near grazing angles and at thin, self-occluding structures; failure modes (z-fighting, ordering ambiguities) and their mitigations are not studied.
- Appearance modeling limitations: The MLP color head with view direction lacks an explicit BRDF; robustness to strong specularities, translucency, interreflections, and spatially varying illumination is untested; disentangling geometry from view-dependent appearance remains open.
- Reliance on auxiliary priors: Although the method emphasizes image-based volumetric supervision, training also uses shading and monocular normal priors; there is no ablation of truly photometric-only training nor a quantification of how much each prior contributes.
- Texture–geometry ambiguity: Using a powerful color MLP with hashed positional features risks “painting over” geometry errors; no regularization or diagnostics assess whether appearance compensates for geometric inaccuracies.
- Metrics beyond Chamfer: Evaluations do not report normal/angular error, edge sharpness, watertightness, manifoldness, or self-intersection rates; these are critical for practical mesh use and for validating the claimed mesh-quality advantages.
- Fair comparison protocols: Vertex counts and training times differ substantially across methods; standardized budgets (fixed vertex counts/time) and controlled hardware comparisons are not provided.
- Thin-structure reconstruction: The paper notes isotropic remeshing struggles with cables/hair; there is no implemented solution (e.g., curvature-aware anisotropic/adaptive remeshing, edge-length targets aligned with principal curvatures) or quantitative thin-structure benchmarks.
- Layer–base coupling design: Only one mapping from signed distance to alpha (VolSDF-like) is tested; the effect of alternative transfer functions, per-layer learned widths, or regularizers that encourage layers to collapse toward the base surface is unexplored.
- Initialization sensitivity: The method starts from a sphere (object-centric) or a coarse external mesh (scene-level); robustness to poor initializations, automated initialization from sparse SfM points, or joint coarse-to-fine strategies is not evaluated.
- Camera and photometric robustness: Sensitivity to calibration errors, exposure/white-balance differences, rolling-shutter effects, and tone-mapping is unreported; invariances or preprocessing needed for robust photometric supervision are not specified.
- Handling of backgrounds and open scenes: Representing distant backgrounds or unbounded regions remains ad hoc (requires external initialization); integrated representations for foreground meshes plus background radiance/environment maps are not developed.
- Memory/time scaling laws: Beyond a single table, there is no systematic study of how training cost scales with image resolution, triangle count, layer count, and view count, nor guidelines to choose hyperparameters under resource constraints.
- Offset sampling learnability: Offsets are not learned; exploring learnable or gradient-informed sampling (e.g., along rays with high reprojection error) or importance sampling of layers is an open avenue.
- Post-training asset readiness: The pipeline outputs a base mesh, but procedures for texture baking, material parameter estimation, and ensuring watertight/manifold meshes for downstream engines (physics/rendering) are not specified.
- Dynamic/non-rigid scenes: Extending soft mesh splatting to time-varying geometry (e.g., with motion priors or deformation fields) is not addressed.
- Integration with semantics/priors: How semantic cues (e.g., part/category priors) or physical constraints (e.g., smoothness in developable regions) could improve topology and detail recovery remains unexplored.
Practical Applications
Practical Applications Derived from “Mesh Splatting for End-to-end Multiview Surface Reconstruction”
The paper introduces a differentiable “soft mesh” representation (semi-transparent layers around a base mesh), a splatting-based volumetric renderer for meshes, and a hybrid topology-control strategy (DMTet early, Continuous Remeshing later). Together, these yield accurate meshes with fewer vertices, short optimization times (~20 minutes per object on a single GPU), and reduced error accumulation compared to volumetric pipelines that require meshing. Below are actionable applications, categorized by deployability and linked to relevant sectors, tools, and workflows. Each item notes assumptions and dependencies affecting feasibility.
Immediate Applications
These applications can be deployed now (with standard engineering effort), leveraging the described method as a standalone reconstruction stage or a refinement step in existing pipelines.
- Game and VFX asset optimization (software, media/entertainment)
- Use case: Replace or augment the meshing stage of photogrammetry/NeRF/3DGS pipelines to produce production-ready meshes that meet strict vertex budgets and topology standards.
- Tools/products/workflows: Integrate as a “Mesh Splatting Refinement” stage following RealityCapture/Metashape/AliceVision (Meshroom), or as a Blender/Unreal/Unity plugin; export to FBX/GLTF/USD with continuous remeshing during optimization.
- Assumptions/dependencies: Multi-view calibrated images (SfM available); access to an NVIDIA-class GPU; object-centric scenes preferred (scene-level requires coarse mesh init).
- E-commerce product digitization with lower bandwidth and faster load (retail, web)
- Use case: Generate lightweight, clean meshes for 3D product viewers (WebGL/three.js/Model-Viewer) to reduce transfer size and improve interaction performance while preserving detail.
- Tools/products/workflows: Cloud microservice (“Asset Optimizer API”) that ingests product photos or coarse meshes, outputs topology-controlled assets and LODs.
- Assumptions/dependencies: Sufficient multi-view coverage; smartphone capture rigs; basic camera calibration; cloud GPU capacity.
- AR/VR content creation with mobile-friendly assets (XR)
- Use case: Produce meshes with fewer vertices for mobile AR/VR while avoiding meshing artifacts common in volumetric methods; improve thin structure fidelity compared to Gaussian-only assets.
- Tools/products/workflows: Pipeline step in USDZ/glTF authoring; integrate with RealityKit/ARCore/ARKit and Unity/Unreal importers; automatic LOD generation via continuous remeshing.
- Assumptions/dependencies: Good photo coverage; isotropic remeshing may need tuning for extremely thin features (cables/hair).
- Cultural heritage and museum artifact digitization (public sector, cultural heritage)
- Use case: High-quality, watertight meshes from multi-view images that avoid downstream meshing errors, suitable for archiving, visualization, and 3D printing.
- Tools/products/workflows: Add-on to existing photogrammetry workflows; batch refinement of scanned artifacts; export with per-asset vertex budgets and QA reports (Chamfer/vertex count).
- Assumptions/dependencies: Permissions for photography, consistent lighting; GPU availability; object-centric capture.
- Improved meshes for 3D printing and fabrication (manufacturing, maker communities)
- Use case: Deliver cleaner, better-conditioned manifold meshes that slice reliably and require fewer manual repairs.
- Tools/products/workflows: “Slicer-ready mesh” mode; integrate into MeshLab/Blender toolchains; automated watertightness checks; optional decimation guided by remeshing metrics.
- Assumptions/dependencies: Target watertightness constraints; geometry capture quality; potentially tune minimum edge length for print fidelity.
- Simulation pre-processing: better element quality for FEA/CFD (engineering)
- Use case: Use topology-controlled triangle meshes as bases for generating high-quality volumetric meshes, reducing artifacts and improving convergence in physics simulations.
- Tools/products/workflows: Export pre-conditioned surfaces to mesh generators (TetGen/Gmsh/SimScale pipelines); apply continuous remeshing for near-isotropic triangles before tet meshing.
- Assumptions/dependencies: Conversion to volumetric (tet) meshes still required; coverage and surface fidelity depend on input views.
- Robotics and SLAM: post-processing of scene meshes for planning/collision (robotics)
- Use case: Refine coarse scene meshes (e.g., output of GaussianSurfel/3DGS) into topology-controlled surfaces for collision checking and path planning in simulation.
- Tools/products/workflows: Offline refinement step in mapping pipelines; export to ROS-friendly formats; integrate with Gazebo/Isaac Sim for testing.
- Assumptions/dependencies: Availability of coarse mesh initialization; static scenes preferred; compute resources for scene-level refinement.
- Academic use: baseline and teaching tool for photogrammetry courses (academia)
- Use case: Demonstrate how volumetric supervision can update meshes end-to-end; compare representation choices and remeshing impacts in lab assignments.
- Tools/products/workflows: Open-source release; Jupyter notebooks with DTU/BlendedMVS examples; reproducible 20-minute training recipes.
- Assumptions/dependencies: GPU access; datasets with camera poses; licensing of code and datasets.
- Turnkey “Mesh Splatting Refinement Service” (software/SaaS)
- Use case: A cloud API that takes multi-view imagery or a coarse mesh (from NeRF/3DGS) and returns an optimized, topology-controlled mesh with quality metrics.
- Tools/products/workflows: REST API with queued GPU jobs; outputs include mesh, LODs, vertex count targets, QA report (Chamfer distance, normals).
- Assumptions/dependencies: Robust camera calibration; customer uploads meet coverage requirements; GPU autoscaling.
Long-Term Applications
These applications require further research, scaling, or engineering (e.g., handling very large scenes, on-device performance, domain adaptations, and standardized workflows).
- Real-time or on-device end-to-end reconstruction (mobile/XR)
- Use case: On-device capture-to-mesh for AR authoring or live asset creation.
- Tools/products/workflows: Hardware-accelerated mesh splatting and adaptive softening; incremental optimization; LOD-aware remeshing.
- Assumptions/dependencies: Efficient GPU kernels, triangle culling, adaptive density; battery and thermal constraints; codegen for mobile GPUs.
- City-scale digital twins and AEC workflows (AEC, energy, smart cities)
- Use case: Hierarchical softening and remeshing for very large scenes (buildings/infrastructure), producing standardized, simulation-ready meshes for BIM/digital twins.
- Tools/products/workflows: Cluster/distributed training; tiled scene partitioning; integration with BIM tools (IFC/Revit); streaming LODs for viewers.
- Assumptions/dependencies: Memory-efficient reparameterizations beyond DMTet; hierarchical softening bands; robust camera registration of large capture sets.
- Medical applications from multi-view video (healthcare)
- Use case: Reconstruct surfaces from endoscopic or laparoscopy videos for surgical planning and training simulators, with topology-controlled meshes.
- Tools/products/workflows: Domain-specific capture rigs; photometric models robust to specular, fluid-covered surfaces; QA for clinical safety.
- Assumptions/dependencies: Strict imaging constraints, privacy/IRB compliance; specialized reflectance handling; validation against ground-truth anatomy.
- Online robotics mapping and replanning (robotics)
- Use case: Incremental mesh updates during navigation, producing collision-safe, topology-controlled surfaces in near real-time.
- Tools/products/workflows: Streaming optimization, adaptive softening bandwidths; fusion with LiDAR depth; integration with SLAM back-ends.
- Assumptions/dependencies: Dynamic scene handling; robust initialization when base meshes are far from true surfaces; mixed sensor fusion.
- Drone photogrammetry and geospatial terrain modeling (geospatial)
- Use case: Lightweight, artifact-free terrain meshes for visualization, simulation (e.g., flood modeling), and data delivery.
- Tools/products/workflows: Tiled processing of aerial datasets; export LOD pyramids; standard formats (Cesium/3D Tiles).
- Assumptions/dependencies: Very large image sets; need hierarchical softening and memory-efficient rendering; accurate georegistration.
- Standardization and policy for public 3D assets (public sector)
- Use case: Guidelines that mandate topology-controlled, vertex-budgeted meshes for archiving and distribution (reduces storage/bandwidth, improves usability).
- Tools/products/workflows: Procurement specs and QA protocols (mesh density, smoothness, watertightness); audit tooling built on the paper’s metrics.
- Assumptions/dependencies: Inter-agency adoption; open standards alignment; training and capacity for cultural heritage and public agencies.
- Physics-driven digital twin simulation fidelity (engineering/energy)
- Use case: Use better-conditioned meshes to reduce numerical artifacts in large simulation campaigns (contact, structural analysis, fluid flow).
- Tools/products/workflows: Automated pre-simulation mesh conditioning pipelines; coupling with mesh generators; sensitivity analyses to mesh quality.
- Assumptions/dependencies: Robust control of mesh anisotropy; domain-specific validation; scalable to millions of elements.
- Content delivery networks for 3D assets (software/web)
- Use case: Mesh-aware CDN optimization (vertex budgets and LODs) to reduce bandwidth without quality loss, powered by topology-controlled reconstruction.
- Tools/products/workflows: Build-time mesh optimization; per-device LOD selection; integration with web viewers.
- Assumptions/dependencies: Stable reconstruction at scale; device profiling; standardized QA thresholds.
- Cross-representation research platforms (academia)
- Use case: A testbed that unifies volumetric supervision and surface optimization to study differentiable remeshing, adaptive softening, and renderer efficiency.
- Tools/products/workflows: Benchmarks for large scenes; ablations across softening layers, β concentration parameters, and renderer implementations.
- Assumptions/dependencies: Open datasets with consistent camera calibration; multi-GPU scaling; reproducibility frameworks.
Key assumptions and dependencies common across applications
- Multi-view, calibrated image inputs (intrinsics/extrinsics) and sufficient coverage are required for accurate reconstruction.
- GPU resources: current implementation was benchmarked on an NVIDIA V100 (32 GB); full-resolution scenes and large datasets need memory-aware engineering (triangle culling, adaptive density).
- Object-centric optimization is most mature; scene-level use benefits from coarse mesh initialization (e.g., from GaussianSurfel) and may require hierarchical softening or alternative reparameterizations.
- Isotropic remeshing may under-represent extremely thin structures; adaptive remeshing policies are advisable where cables/wires/hair are important.
- When the base mesh is far from the true surface, softening bands may not overlap sufficiently; strategies like adaptive layer bandwidths or hierarchical sampling improve robustness.
Glossary
- 3D receptive field: The spatial extent in three dimensions over which input observations influence a rendered pixel or learned geometry. "endowing it with a controllable 3D receptive field."
- Adaptive Remeshing: A mesh processing technique that modifies triangle sizes and shapes during optimization to better capture fine or thin structures. "adaptive remeshing could be explored to generate slender triangular faces"
- alpha weights: Per-sample transparency values used to accumulate color along a ray in volumetric compositing. "We convert signed distances to alpha weights using a variant of the VolSDF mapping"
- barycentric coordinates: Weights that express a point inside a triangle as a convex combination of its vertices, used for interpolation. "compute its barycentric coordinates"
- barycentric interpolation: Interpolating per-vertex attributes (e.g., color, normals) at a point inside a triangle using barycentric coordinates. "by barycentric interpolation of the vertex-attached parameters."
- Chamfer Distance: A metric measuring the average nearest-neighbor distance between two point sets (often used to compare surfaces). "“Verts” and “CD” denote the number of vertices and the Chamfer distance, respectively."
- Continuous Remeshing: An optimization-compatible remeshing approach that continuously adjusts mesh topology and element quality during training. "employ Continuous Remeshing for further topology control after convergence"
- Deep Marching Tetrahedra (DMTet): A differentiable meshing framework that extracts surfaces from signed distance values defined on a tetrahedral grid. "Deep Marching Tetrahedra (DMTet)"
- depth peeling: A rendering technique that iteratively extracts layers of geometry sorted by depth to handle transparency and multiple intersections. "using depth peeling in Nvdiffrast"
- Differentiable Mesh Splatting: A rendering pipeline that treats mesh faces as splats and supports gradient-based optimization through volumetric compositing. "Differentiable Mesh Splatting based on tile-based rasterization"
- differentiable rasterizers: Rendering tools that compute images from meshes while allowing gradients to flow back to geometry and material parameters. "Meshes are typically rendered with differentiable rasterizers"
- Gaussian Splatting: An explicit volumetric representation that models scenes with many transparent 3D Gaussian primitives and renders them by splatting. "3D Gaussian Splatting (3DGS)"
- Gaussian Surfel: A Gaussian-based surfel (surface element) representation and pipeline for reconstruction with downstream meshing. "Gaussian Surfel"
- hash-encoded coordinate features: Multi-resolution hashed feature grids used to efficiently encode spatial signals for neural fields or rendering MLPs. "hash-encoded coordinate features"
- isotropic remeshing: Remeshing that enforces near-uniform triangle sizes and shapes to improve element quality and stability. "e.g., isotropic remeshing"
- Marching Cubes: A classic isosurface extraction algorithm that converts sampled scalar fields into triangle meshes using cube-wise cases. "apply Marching Cubes"
- Marching Tetrahedra: An isosurface extraction algorithm operating on tetrahedral cells, often used with signed distance fields. "Marching Tetrahedra"
- mesh smoothness loss: A regularization term that penalizes sharp or irregular variations in mesh geometry to promote smooth surfaces. "mesh smoothness loss from PyTorch3D"
- monocular normal supervision: Training supervision that uses surface normals predicted from single-view images to guide reconstruction. "monocular normal supervision"
- NeRF: Neural Radiance Fields; an implicit volumetric model that maps 3D coordinates and view directions to density and radiance for novel view synthesis. "NeRF"
- Nvdiffrast: A GPU-based differentiable rasterization library used for gradient-based mesh rendering. "Nvdiffrast"
- photometric loss: A reconstruction objective that measures differences between rendered colors and ground-truth image pixels. "via a photometric loss"
- Poisson Reconstruction: A meshing technique that reconstructs surfaces from oriented point clouds by solving a Poisson equation. "Poisson Reconstruction"
- signed distance field (SDF): A scalar field where each point stores its signed distance to a surface; negative inside, positive outside. "signed distance field"
- soft mesh: A mesh representation transformed into multiple semi-transparent layers to act as a pseudo-volumetric structure for rendering and optimization. "soft mesh"
- splatting-based renderer: A renderer that projects primitives (e.g., triangles or Gaussians) as footprint “splats” onto the image plane and composites them. "a splatting-based renderer"
- stop-gradient operator: An operation that prevents gradients from flowing through certain variables during backpropagation. "Let \operatorname{stop}(\cdot) denote the stop-gradient operator."
- Structure-from-Motion (SfM): A technique that estimates camera poses and sparse 3D points from multiple images by solving geometric constraints. "Structure-from-Motion (SfM)"
- tetrahedral grid: A spatial discretization of volume into tetrahedra used to store fields (e.g., signed distances) and extract meshes. "a tetrahedral grid"
- tile-based rasterization: A rendering approach that divides the image into tiles to efficiently determine primitive coverage and perform per-pixel computations. "Using tile-based rasterization"
- topology control: Strategies to adjust mesh connectivity during optimization to maintain watertightness, prevent artifacts, and improve element quality. "topology control via remeshing techniques."
- TSDF-based methods: Approaches using truncated signed distance fields to represent surfaces for reconstruction and meshing. "TSDF-based methods"
- VolSDF mapping: A mapping from signed distances to densities/alpha used in volumetric rendering to concentrate opacity near surfaces. "a variant of the VolSDF mapping"
- volumetric proxies: Auxiliary volumetric structures (e.g., grids, spheres) attached to meshes to stabilize optimization or guide rendering. "volumetric proxies"
- volumetric rendering: Rendering that integrates color and transparency along rays through a volumetric representation to form images. "volumetric rendering"
Collections
Sign up for free to add this paper to one or more collections.