HumanDiffusion: A Vision-Based Diffusion Trajectory Planner with Human-Conditioned Goals for Search and Rescue UAV
Abstract: Reliable human--robot collaboration in emergency scenarios requires autonomous systems that can detect humans, infer navigation goals, and operate safely in dynamic environments. This paper presents HumanDiffusion, a lightweight image-conditioned diffusion planner that generates human-aware navigation trajectories directly from RGB imagery. The system combines YOLO-11--based human detection with diffusion-driven trajectory generation, enabling a quadrotor to approach a target person and deliver medical assistance without relying on prior maps or computationally intensive planning pipelines. Trajectories are predicted in pixel space, ensuring smooth motion and a consistent safety margin around humans. We evaluate HumanDiffusion in simulation and real-world indoor mock-disaster scenarios. On a 300-sample test set, the model achieves a mean squared error of 0.02 in pixel-space trajectory reconstruction. Real-world experiments demonstrate an overall mission success rate of 80% across accident-response and search-and-locate tasks with partial occlusions. These results indicate that human-conditioned diffusion planning offers a practical and robust solution for human-aware UAV navigation in time-critical assistance settings.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “HumanDiffusion: A Vision-Based Diffusion Trajectory Planner with Human-Conditioned Goals for Search and Rescue UAV”
Overview
This paper introduces a smart system called HumanDiffusion that helps small flying robots (drones) find and safely move toward people in emergencies using only what the drone sees through its camera. The system doesn’t need a map of the area. Instead, it looks at the camera image, spots a person, and draws a smooth, safe path for the drone to follow.
Key objectives and questions
Here’s what the researchers wanted to achieve:
- Make a drone quickly spot people and decide where it should go, even in messy or unknown places.
- Plan a safe, smooth route directly from the camera image without using heavy, slow planning methods or detailed maps.
- Work well in real-life situations like delivering medical supplies or finding someone who is partially hidden.
- Keep the system lightweight and fast enough for emergency use.
How the system works (methods and approach)
Think of the drone as having two main “skills”: seeing and planning.
- Seeing people (YOLO):
- The drone’s camera captures regular color images (called RGB).
- A vision tool named YOLO finds humans in the image and draws a box around them.
- The center of that box becomes the drone’s “goal,” like a pin on a map telling it where to go.
- Drawing a path with diffusion:
- The planner uses a type of AI called a diffusion model. Imagine starting with a noisy, messy picture and slowly “cleaning” it until a clear path appears—this step-by-step cleaning is what diffusion does.
- The model looks at the image, the drone’s starting point, and the person’s location, then “denoises” toward a clean path. It outputs the path as pixels on the image (a “pixel-space trajectory”).
- A UNet (a common neural-network shape used for editing images) helps the diffusion model focus on making a smooth route that starts at the drone and stops near the person, keeping a safe distance.
- Training the planner:
- The team created training examples in a simulator. They used a classic method called A* to produce good routes and taught the diffusion model to mimic those paths from camera images.
- They trained on 8,000 examples, checked performance on 1,500 during training, and tested on 300 newly held-out examples.
- From pixels to real flight:
- The path is first made in image pixels. To fly in the real 3D world, the drone uses a depth camera to measure distances and convert pixel points into actual waypoints in space.
- The drone then follows these waypoints. No big map is built—everything stays “vision-driven.”
- Safety and setup:
- The drone keeps about 1 meter away from people and flies slowly (around 0.3 m/s).
- It has propeller guards and a gripper for picking up and delivering items.
- The planning runs at roughly 0.2–0.3 seconds per frame, fast enough to be responsive.
Main findings and why they matter
- Accuracy in tests: On 300 simulated test images, the planner’s paths were very close to the “correct” paths, with a mean squared error of 0.02. In simple terms, the average difference between the planned and ideal routes was small.
- Real-world success:
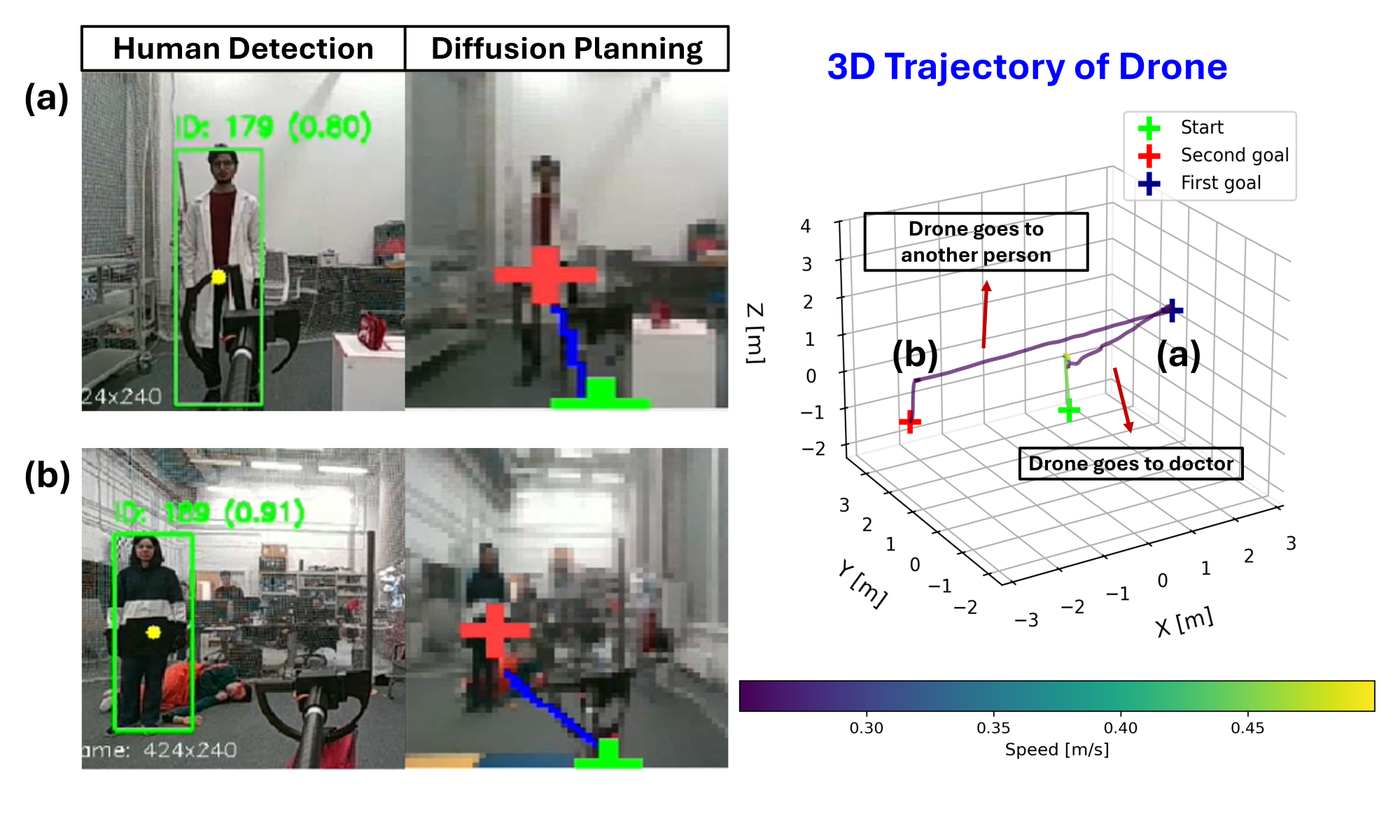
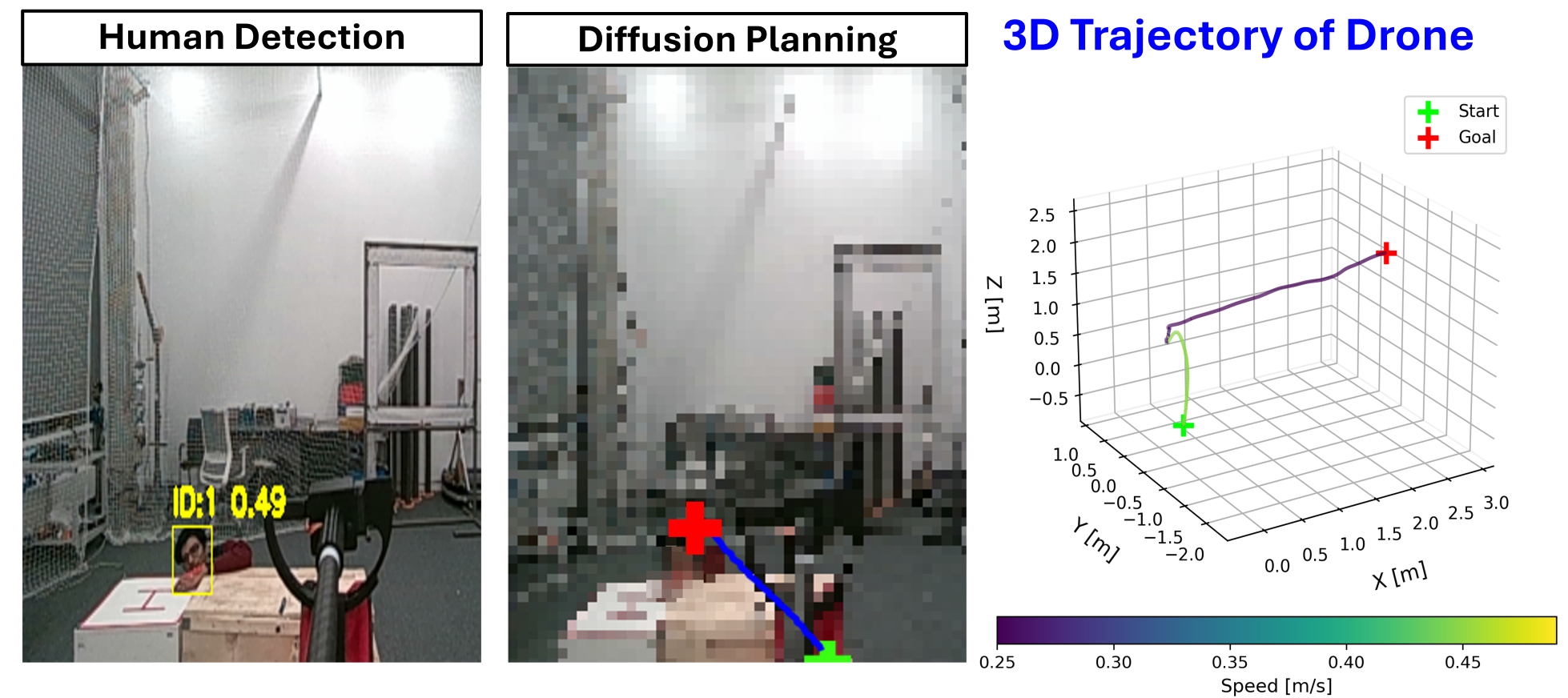
- Accident Response scenario (find a doctor, pick up a kit, deliver to an injured person): 9 out of 10 runs succeeded.
- Search-and-Locate with partial hiding (people behind small obstacles): 7 out of 10 runs succeeded.
- Overall success rate: 80%.
- The failures were understandable: losing sight of the person due to occlusion, minor control errors, and communication delays.
Why this is important:
- The system plans directly from camera images, without maps or heavy, slow algorithms. That makes it useful in fast-changing situations like rescue missions.
- It keeps a safe distance from people and produces smooth paths, which is important for trust and safety in human–robot interaction.
- It worked in both simulations and real indoor tests, showing good chances of working outside the lab as well.
What this could mean in the future (implications)
HumanDiffusion is a promising step toward drones that can help in real emergencies—finding people and delivering supplies quickly without needing perfect maps or pre-set routes. In the future, the team plans to:
- Let the drone react to gestures and pick the right person to help when many people are present.
- Switch targets and prioritize who needs help most.
- Improve collision awareness to better handle dynamic, crowded spaces.
If these improvements succeed, we could see more reliable rescue drones that collaborate safely with humans, respond faster, and operate in places where traditional planning tools struggle.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several aspects unresolved that future research could concretely address:
- Lack of baseline comparisons: No quantitative or qualitative comparison against classical planners (A*, RRT*, MPC), learning-based planners (RL), or contemporary diffusion planners (e.g., NoMaD, DTG, DiPPeR) to contextualize performance, robustness, and efficiency.
- Limited evaluation metrics: Real-world evaluation reports only overall success rate; missing metrics such as time-to-goal, path length, average/maximum deviation from safety margin, re-planning frequency, tracking accuracy for moving targets, and collision/near-miss statistics.
- Small-scale real-world trials: Only 20 indoor trials (10 per scenario) with three participants; no statistical significance analysis, confidence intervals, or diversity in environments, participants, clothing, poses, or behaviors typical of SAR.
- Indoor, controlled environments only: No outdoor tests or stressors common in SAR (low light, smoke, fog, dust, rain, thermal drift, wind gusts, uneven terrain) to assess robustness and generalizability.
- Detector robustness unquantified: YOLO-11 human detection is assumed reliable; no evaluation across occlusions, varied poses (e.g., prone, seated), PPE, blankets, low-visibility conditions, false positives/negatives, or detector confidence thresholds relevant to SAR.
- Goal inference simplification: Using only the bounding-box center as the goal ignores human pose, orientation, accessibility, and context (e.g., safe approach angle, victim condition), which may be critical for safe and effective assistance.
- Multi-human scenarios unsupported: No handling of multiple simultaneous detections, prioritization, target switching, re-identification after occlusion, or operator input for target selection; failure modes from identity switches are not analyzed.
- Mapless navigation without local avoidance: The system lacks explicit local obstacle avoidance; it does not leverage depth to construct transient occupancy maps or reactive control for dynamic obstacles, raising collision risk in cluttered or changing environments.
- Pixel-space planning resolution constraints: Trajectories are generated at 64×64 resolution with noted artifacts; the impact of resolution, aliasing, and upsampling methods on path fidelity and safety remains untested.
- 2D-to-3D projection uncertainties: No quantified analysis of calibration errors, depth noise (RealSense D455), occlusions, or rolling shutter effects on waypoint accuracy; failure impacts of misprojection are not measured.
- Dynamic feasibility unaddressed: The planner does not incorporate UAV dynamics (acceleration limits, yaw constraints) or flight-envelope safety; path feasibility and controller tracking performance are not evaluated under aggressive maneuvers or rapid goal changes.
- Safety margin selection and adaptation: The fixed 1 m stopping distance is heuristic; no adaptive margin based on speed, visibility, obstacle proximity, or human comfort is proposed or evaluated.
- Real-time, on-board performance not demonstrated: Inference runs off-board with 0.2–0.3 s per frame; total system latency (vision + networking + planning + control) is not measured, and on-board compute feasibility (CPU/GPU load, memory footprint) is untested.
- Communications dependency: The pipeline relies on remote server and ROS networking; resilience to packet loss, variable latency, bandwidth limits, and degraded links is not quantified or mitigated (e.g., fallback behaviors).
- Training exclusively on simulated data: The diffusion planner is trained only on simulated RGB and A*-generated trajectories; no domain randomization strategy, sim-to-real gap quantification, or real-world fine-tuning is provided.
- Ground-truth trajectory bias: Using A* as ground truth may bias the model toward planner-specific characteristics; the impact on generalization to non-A* routes or human-aware approach behaviors is not analyzed.
- Incomplete training specification and reproducibility: Loss equations in the paper contain typographical errors and missing brackets; loss weights (λ, w_t, w_s, w_g), noise schedule parameters, and conditioning/inpainting details are insufficiently specified for replication.
- Ablation studies missing: No ablations on start–goal conditioning, inpainting, loss components, diffusion steps, UNet architecture choices, or trajectory-channel weighting to understand which design elements drive performance.
- Uncertainty and confidence not modeled: The planner does not estimate trajectory or goal uncertainty; no mechanisms for risk-aware planning, confidence-based slowing/stopping, or human-in-the-loop overrides.
- Formal safety guarantees absent: There are no formal safety assurances (e.g., reachability analysis, barrier certificates) for maintaining minimum human distance or avoiding obstacles under sensor noise and disturbances.
- Failure mode depth limited: Failures are categorized (perception loss, controller drift, comm dropouts) but lack root-cause diagnostics, temporal traces, or mitigation strategies (e.g., detector fallback, controller retuning, redundant links).
- Handover task evaluation incomplete: The object handover with a gripper is asserted but not quantitatively evaluated (handover success rate, timing, alignment accuracy, human comfort, safety incidents).
- Human factors not assessed: No study of participant comfort, perceived safety, trust, or acceptability of flight behaviors and standoff distances; ethical considerations beyond consent and prop guards are not explored.
- Scalability and multi-agent coordination: The approach’s scalability to larger search areas, longer missions (energy budgets), or multiple UAVs (deconfliction, cooperative search) is unexamined.
- Security and adversarial robustness: No assessment of susceptibility to adversarial visual patterns, spoofing (images of humans), or sensor tampering, which can be critical in unstructured SAR settings.
- Integration with semantic reasoning: While VLM integration is cited in related work, the system does not leverage scene semantics (e.g., “doctor,” “injured person,” “pathways,” “unsafe regions”), leaving open how to fuse language-guided objectives with diffusion planning.
- Generalization across hardware: Portability to different UAV platforms, cameras (RGB vs thermal), and sensor suites is not studied; calibration and integration guidelines are missing.
Practical Applications
Immediate Applications
The following applications can be piloted in controlled environments or integrated into existing robotic workflows today, given the system’s demonstrated 80% mission success in indoor mock-disaster trials, 0.2–0.3 s/frame planning, and reliance on commodity sensors and ROS-based infrastructure.
- Indoor search-and-assist drills for first responders
- Sector(s): Public safety, Healthcare, Emergency response training
- Use case: Rapid approach to detected people in mock incidents, safe-distance medical kit handover, and reacquisition after occlusion in training arenas, hospitals, or campuses.
- Potential tools/products/workflows: ROS node for HumanDiffusion planning; “human-goal generator” plugin using YOLO-11; pixel-to-3D waypoint conversion with RealSense intrinsics; training scenario scripts for accident-response and search-and-locate drills.
- Assumptions/dependencies: Indoor flight permissions; RGB/Depth camera calibration; reliable YOLO-11 detection under indoor lighting; networked off-board compute or sufficiently powerful onboard computer; safety protocols (e.g., 1 m stopping margin, prop guards).
- Last-meter delivery to known personnel in facilities
- Sector(s): Healthcare (hospitals), Corporate campuses, Warehousing
- Use case: Map-free “approach-to-human” delivery for lab samples, documents, or small tools in hallways or labs where GPS and detailed maps are unavailable.
- Potential tools/products/workflows: Facility “delivery-to-person” mode in existing UAV fleets; operator tablet to select target person; safety margin and max-velocity parameterization; logs for human-approach events.
- Assumptions/dependencies: Clear indoor airspace and permissions; modest payloads; consistent visual line of sight; depth sensing for pixel-to-3D projection; integration with existing VIO/pose estimation.
- Human-aware telepresence/inspection assistance
- Sector(s): Facilities management, Industrial inspection, Education
- Use case: Telepresence drone that can autonomously move toward a human to begin interaction (e.g., a technician or student), reducing manual piloting effort in labs, classrooms, or warehouses.
- Potential tools/products/workflows: Operator-in-the-loop UI that toggles “go-to-person” plus safe hover; ROS bridge to teleop; automated “last 5 meters” approach using HumanDiffusion paths.
- Assumptions/dependencies: Controlled environment; strong Wi-Fi/mesh connectivity; privacy consent for person detection.
- Research and education testbed for map-free planning
- Sector(s): Academia, Robotics R&D, Software
- Use case: Drop-in global planner for mobile robotics courses and labs to study image-conditioned, human-anchored navigation without mapping.
- Potential tools/products/workflows: Open-source ROS package; dataset generation recipes (A* path synthesis and sim-only training); ablation studies on endpoint loss weights and diffusion steps; baseline comparisons against A*/RRT*.
- Assumptions/dependencies: Access to simulation environments (e.g., VLN-Go2-Matterport); reproducible training pipeline; lab safety compliance.
- Safety protocol prototyping for human-aware UAV approach
- Sector(s): Policy, Risk management, Institutional review boards (IRBs)
- Use case: Develop SOPs for “safe-distance approach,” occlusion handling, and emergency stop routines during HRI with aerial robots.
- Potential tools/products/workflows: Checklists for velocity caps (e.g., 0.3 m/s), fixed stopping margins, consent capture, and flight corridor markings; log auditing of approach trajectories.
- Assumptions/dependencies: Institutional acceptance; alignment with local regulations and privacy norms.
Long-Term Applications
These applications require further advances in robustness (outdoor generalization, collision awareness), multi-human reasoning, onboard compute integration, and regulatory maturation.
- Outdoor search-and-rescue deployment with autonomous goal inference
- Sector(s): Public safety, Disaster response
- Use case: Map-free UAV navigation toward detected survivors across rubble or vegetation, including handover of first-aid or comms devices, and re-targeting as humans move.
- Potential tools/products/workflows: Ruggedized onboard inference (edge GPU); thermal-RGB fusion; fallback strategies for occlusion and perception loss; integration with incident command systems.
- Assumptions/dependencies: Reliable outdoor detection under variable lighting/weather; collision-aware local planner fused with HumanDiffusion global plans; BVLOS regulatory approvals; robust state estimation without maps.
- Multi-human prioritization and gesture-guided assistance
- Sector(s): Healthcare triage, Event safety, Industrial EHS
- Use case: Prioritize whom to approach (e.g., injured vs. signaling personnel), switch targets based on gestures or urgency, and coordinate deliveries or escorts.
- Potential tools/products/workflows: Person re-identification and gesture classifiers; priority queues; target-switching policies; HRI interfaces for responders to “claim” a drone.
- Assumptions/dependencies: Increased perception stack complexity; annotated real-world data for gestures and re-ID; conflict resolution in crowded scenes.
- Integrated global–local planning stack with dynamic obstacle avoidance
- Sector(s): Robotics, Software
- Use case: Fuse image-conditioned global diffusion trajectories with proven local avoidance (e.g., ESDF-free or model-predictive controllers) for dense, dynamic environments.
- Potential tools/products/workflows: Middleware to hand off HumanDiffusion’s pixel-paths to local planners; unified cost/constraint interfaces; real-time safety monitors.
- Assumptions/dependencies: Real-time depth/SLAM; formal safety constraints; tuning across platforms and sensor configs.
- Cross-platform adoption (UGVs, legged robots, micro-UAVs)
- Sector(s): Logistics, Security, Inspection
- Use case: Human-conditioned approach for ground or legged robots (e.g., warehouse runners, campus escorts) and micro-drones in narrow spaces.
- Potential tools/products/workflows: Camera-pose adaptation layers; viewpoint-robust trajectory decoding; platform-specific control bridges.
- Assumptions/dependencies: Camera placement and FOV differences; dynamics limits; safety case for ground vs. aerial contact proximity.
- Swarm/teaming for area coverage and coordinated assistance
- Sector(s): Public safety, Large-event management, Industrial sites
- Use case: Multiple robots partition space, locate people, and hand off tasks (delivery, escort, triage support), maintaining safe inter-robot distances.
- Potential tools/products/workflows: Mission allocator with human-priority queues; inter-robot communication and deconfliction; shared human-detection map layers.
- Assumptions/dependencies: Scalable comms; decentralized planning; formal verification for collision/airspace safety.
- Consumer “come-to-me” assistant modes
- Sector(s): Consumer robotics, Daily life
- Use case: Context-aware UAVs that autonomously approach owners for handover (keys, medication) or to start a video call, especially for mobility-limited users.
- Potential tools/products/workflows: Mobile app pairing; privacy-preserving on-device detection; adaptive safety margins in homes.
- Assumptions/dependencies: Home safety certifications; noise and privacy considerations; strong indoor localization without markers.
- Standards and certification for human-aware autonomy
- Sector(s): Policy, Insurance, Compliance
- Use case: Certification criteria for “safe approach to humans,” occlusion recovery, and explainable trajectory logs for incident review.
- Potential tools/products/workflows: Conformance test suites (occlusion stress tests, communication dropouts, endpoint accuracy); data retention and consent frameworks.
- Assumptions/dependencies: Multi-stakeholder consensus; alignment with aviation and robotics standards bodies; privacy regulation harmonization.
- Data and benchmarking ecosystem for human-conditioned planning
- Sector(s): Academia, Robotics R&D
- Use case: Curated datasets and benchmarks for pixel-space trajectory prediction conditioned on human goals, including sim-to-real tracks and occlusion scenarios.
- Potential tools/products/workflows: Standardized annotation formats for start/goal/trajectory masks; leaderboards; challenge tasks integrating depth projection accuracy.
- Assumptions/dependencies: Broad community participation; reproducible training/inference pipelines; licensing for datasets and models.
- Integration with vision–language reasoning for mission understanding
- Sector(s): Public safety, Enterprise workflows, Education
- Use case: Language-guided “find-and-approach the doctor, then deliver kit,” or “approach the person waving,” combining semantic scene understanding with HumanDiffusion path generation.
- Potential tools/products/workflows: VLM front-end for intent parsing; goal selection policies feeding the diffusion planner; human-in-the-loop overrides.
- Assumptions/dependencies: Robust multimodal grounding; latency budgets for real time; fail-safe behaviors when language goals conflict with safety.
Notes on feasibility across all applications:
- The current system assumes reliable person detection (YOLO-11), consistent camera calibration, depth availability for 2D→3D projection, and either off-board compute with stable networking or sufficient onboard acceleration.
- Reported performance (80% success in indoor trials; MSE 0.02 on simulated masks) suggests readiness for pilots but not certification-grade deployment in complex, dynamic, or outdoor settings without added local obstacle avoidance and robustness measures.
- Regulatory, privacy, and safety constraints govern deployments that approach humans; standardized stopping margins, consent procedures, and logging should be integral to any operational rollout.
Glossary
- A: A graph search algorithm that finds shortest paths on discretized maps; widely used in robotic planning. Example: "such as A, RRT*, or Model Predictive Control (MPC)"
- Batch size: The number of samples processed together in one forward/backward pass during training. Example: "where is batch size"
- Bounding box: A rectangle that encloses a detected object in an image, used for localization. Example: "The center of the detected human bounding box is treated as an implicit goal"
- Camera intrinsics: The internal calibration parameters of a camera (e.g., focal length, principal point) used to map pixels to rays. Example: "using depth measurements and calibrated camera intrinsics."
- Cost fields: Spatial maps encoding traversal costs used to guide planning. Example: "conditioned on RGB observations, cost fields, or object-level goals"
- DDPM: Denoising Diffusion Probabilistic Model, a generative model that iteratively denoises samples using a learned reverse process. Example: "Denoising Diffusion Probabilistic Model (DDPM) posterior:"
- Diffusion models: Generative models that learn to reverse a gradual noising process to synthesize structured outputs such as trajectories. Example: "Diffusion models have recently gained significant attention for motion planning and trajectory synthesis."
- Filtering-based tracking: Estimating target states over time using filters (e.g., Kalman) to smooth detections and handle uncertainty. Example: "combine detection with filtering-based tracking to enable UAV-based human following"
- Forward diffusion process: The step that progressively adds noise to data to create a tractable distribution for training diffusion models. Example: "Forward Diffusion Process."
- Gaussian noise: Noise drawn from a normal distribution, commonly used in stochastic modeling and diffusion processes. Example: " is the Gaussian noise."
- Global trajectories: Long-horizon navigation paths planned at a high level, as opposed to local, reactive motions. Example: "generates global trajectories directly from RGB images"
- Goal inference: The process of deducing navigation targets from perception rather than relying on predefined waypoints. Example: "eliminating the need for maps and waypoints in goal inference."
- Gripper: A robotic end-effector used to grasp and manipulate objects. Example: "with a gripper for object handover."
- Human–robot collaboration: Coordinated interaction between humans and robots to accomplish tasks safely and effectively. Example: "Reliable human--robot collaboration in emergency scenarios"
- Inpainting: Filling in or preserving specified regions during generation to enforce constraints (e.g., fixed start/goal). Example: "the start and goal channels are inpainted to ensure that the generated trajectory remains aligned with the specified boundary conditions."
- Map-free navigation: Planning and control without building or relying on an explicit map of the environment. Example: "enabling map-free navigation."
- Mean squared error (MSE): A metric measuring average squared difference between predictions and ground truth. Example: "Performance was measured using the mean squared error (MSE) between predicted and ground-truth trajectory masks in pixel space."
- Model Predictive Control (MPC): An optimization-based control method that solves a finite-horizon problem at each step to compute control actions. Example: "such as A*, RRT*, or Model Predictive Control (MPC)"
- NMPC: Nonlinear Model Predictive Control, MPC applied to nonlinear system dynamics. Example: "UAV-VLRR combines VLM-based scene interpretation with NMPC for SAR tasks"
- Occupancy maps: Grid-based maps where cells indicate whether space is free or occupied, used for planning. Example: "Conventional UAV navigation pipelines rely on occupancy maps"
- Occlusion: When an object is partly or fully hidden from view by another object. Example: "with partial occlusions."
- Pixel space: The 2D image coordinate frame in which trajectories or masks are represented. Example: "Trajectories are predicted in pixel space, ensuring smooth motion and a consistent safety margin around humans."
- Posterior (DDPM): The distribution of the previous timestep given the current sample and predicted clean data in diffusion. Example: "Denoising Diffusion Probabilistic Model (DDPM) posterior:"
- Quadrotor: A four-rotor aerial robot capable of vertical takeoff, hovering, and agile flight. Example: "enabling a quadrotor to approach a target person and deliver medical assistance"
- Reinforcement Learning: A learning paradigm where agents learn policies by maximizing cumulative reward through interaction. Example: "including MPC or learning-based controllers such as Reinforcement Learning for trajectory execution"
- Reverse denoising process: The learned generative step in diffusion models that iteratively removes noise to recover structured outputs. Example: "Reverse Denoising Process."
- ROS: Robot Operating System, a middleware framework for robot software development and communication. Example: "and communicated with the onboard NUC via ROS."
- RRT: Rapidly-exploring Random Tree Star, a sampling-based path planning algorithm with optimality guarantees. Example: "such as A, RRT*, or Model Predictive Control (MPC)"
- Safety margin: A buffer distance maintained from obstacles or humans to ensure safe operation. Example: "ensuring smooth motion and a consistent safety margin around humans."
- Sim-to-real: Training or development in simulation followed by transfer to real-world deployment. Example: "Sim-to-real deployment: We train a diffusion planner solely on simulated RGB data and A*-generated trajectories and successfully deploy it in two real-world indoor assistance scenarios."
- Squared-cosine schedule: A noise variance schedule in diffusion that follows a squared cosine function over timesteps. Example: "Noise is gradually added to the clean mask using a squared-cosine schedule:"
- Start–goal pair: The specified initial position and intended target location used to constrain planning. Example: "conditioned solely on RGB images and the inferred start--goal pair"
- State-estimation drift: Accumulating error in a robot’s estimated pose over time due to sensor noise or bias. Example: "Controller tracking errors (1 trial), due to transient state-estimation drift;"
- Trajectory mask: A pixel-wise representation indicating the path to follow within an image. Example: "The model predicts a pixel-space trajectory mask by iteratively denoising a noisy sample."
- Trajectory reconstruction loss: The loss term penalizing differences between predicted and ground-truth trajectory masks. Example: "The trajectory reconstruction loss is:"
- UAV: Unmanned Aerial Vehicle, an aircraft piloted without a human onboard. Example: "Unmanned aerial vehicles (UAVs) are well suited to such settings"
- UNet: A convolutional neural network architecture with encoder–decoder and skip connections, used here as the diffusion backbone. Example: "a conditional UNet-based diffusion model"
- Vision–LLMs (VLMs): Models that jointly process visual and textual inputs for reasoning or control. Example: "Recent work integrates vision--LLMs (VLMs) with UAVs"
- Waypoints: Intermediate target positions used to guide a robot along a path. Example: "eliminating the need for maps and waypoints in goal inference."
- World-frame: A global 3D coordinate frame in which trajectories are executed. Example: "converted to a 3D world-frame path"
- YOLO-11: A real-time object detection model variant used to detect humans in images. Example: "YOLO-11--based human detection"
Collections
Sign up for free to add this paper to one or more collections.