RL-BioAug: Label-Efficient Reinforcement Learning for Self-Supervised EEG Representation Learning
Abstract: The quality of data augmentation serves as a critical determinant for the performance of contrastive learning in EEG tasks. Although this paradigm is promising for utilizing unlabeled data, static or random augmentation strategies often fail to preserve intrinsic information due to the non-stationarity of EEG signals where statistical properties change over time. To address this, we propose RL-BioAug, a framework that leverages a label-efficient reinforcement learning (RL) agent to autonomously determine optimal augmentation policies. While utilizing only a minimal fraction (10%) of labeled data to guide the agent's policy, our method enables the encoder to learn robust representations in a strictly self-supervised manner. Experimental results demonstrate that RL-BioAug significantly outperforms the random selection strategy, achieving substantial improvements of 9.69% and 8.80% in Macro-F1 score on the Sleep-EDFX and CHB-MIT datasets, respectively. Notably, this agent mainly chose optimal strategies for each task--for example, Time Masking with a 62% probability for sleep stage classification and Crop & Resize with a 77% probability for seizure detection. Our framework suggests its potential to replace conventional heuristic-based augmentations and establish a new autonomous paradigm for data augmentation. The source code is available at https://github.com/dlcjfgmlnasa/RL-BioAug.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers to understand brainwave recordings (called EEG) without needing lots of human-labeled examples. The authors show a new way to automatically choose the best “edits” (data augmentations) for each EEG signal so a model can learn good features by itself. Their method is called RL-BioAug.
What questions did the researchers ask?
- Can a computer automatically pick the right kind of data augmentation for each EEG sample, instead of using the same edits for everything?
- If it does, will the model learn better features and perform better on real tasks like sleep stage classification and seizure detection?
- Can this be done using only a small amount of labeled data to guide the process, while the main learning stays label-free?
How did they do it?
Think of training as teaching with “two views” of the same signal:
- A weakly edited version (almost the same as the original).
- A strongly edited version (changed more).
The model is trained to recognize that both views come from the same signal, so it learns what truly matters.
The key idea: contrastive learning (learning from two views)
In contrastive learning, the model pulls together the weak view and the strong view of the same EEG, and pushes apart views from different EEGs. Over time, it learns a strong internal “sense” of patterns in the signals without labels.
The “coach” that picks the edits: a reinforcement learning agent
Data augmentation (the edits) is crucial, but EEG is tricky and changes a lot over time. Random edits can break important details. So the authors add a “coach” (an RL agent) that chooses which strong edit to apply to each signal. It learns from experience which edits help the model learn better.
The coach chooses among five strong edits:
- Time Masking: hide short parts of the signal.
- Time Permutation: cut the signal into chunks and shuffle them.
- Crop & Resize: zoom in on a part and stretch it back to full length.
- Time Flip: reverse the signal in time.
- Time Warp: speed up or slow down parts of the signal.
There are also gentle “weak edits” (tiny noise and small scaling) that keep the signal meaning.
How the coach gets feedback (without many labels)
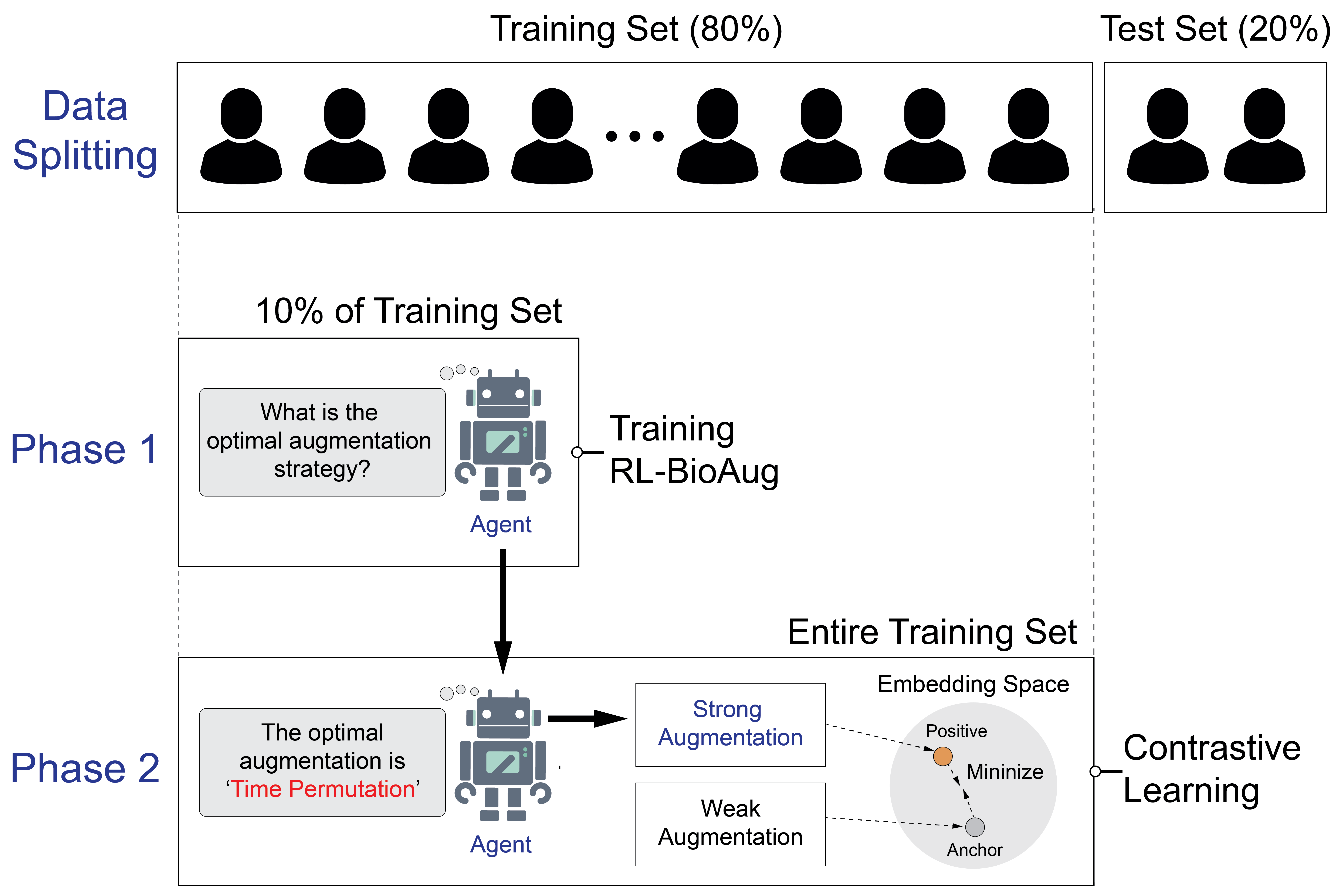
After the coach picks an edit and the model trains on that edited signal, the system checks how well the model’s features group similar examples together. It uses a small, labeled “reference” set (only 10% of the labels) to see if samples that should be the same class end up close together in the model’s feature space. This closeness score becomes the coach’s “reward.” Higher reward = that edit helped.
To keep learning both strong and stable, the coach:
- Looks at recent choices and rewards to improve.
- Doesn’t always pick the same single best edit; it samples from the top few good options to keep helpful variety.
Two-phase training (label-efficient)
- Phase 1 (with 10% labels): Train the coach to pick helpful edits using the reward signal.
- Phase 2 (no labels): Freeze the coach. Train the main model on all the data in a self-supervised way using the coach’s chosen edits.
What did they find?
On two EEG tasks, the automatic coach beat random or fixed augmentation strategies by a clear margin:
- Sleep-EDFX (sleep stage classification): Macro-F1 improved by about 9.7 percentage points over random selection. Final scores were about 72.7% Balanced Accuracy and 69.6% Macro-F1.
- CHB-MIT (seizure detection): Macro-F1 improved by about 8.8 percentage points over random selection. Final scores were about 76.2% Balanced Accuracy and 71.5% Macro-F1.
The coach also learned task-specific preferences:
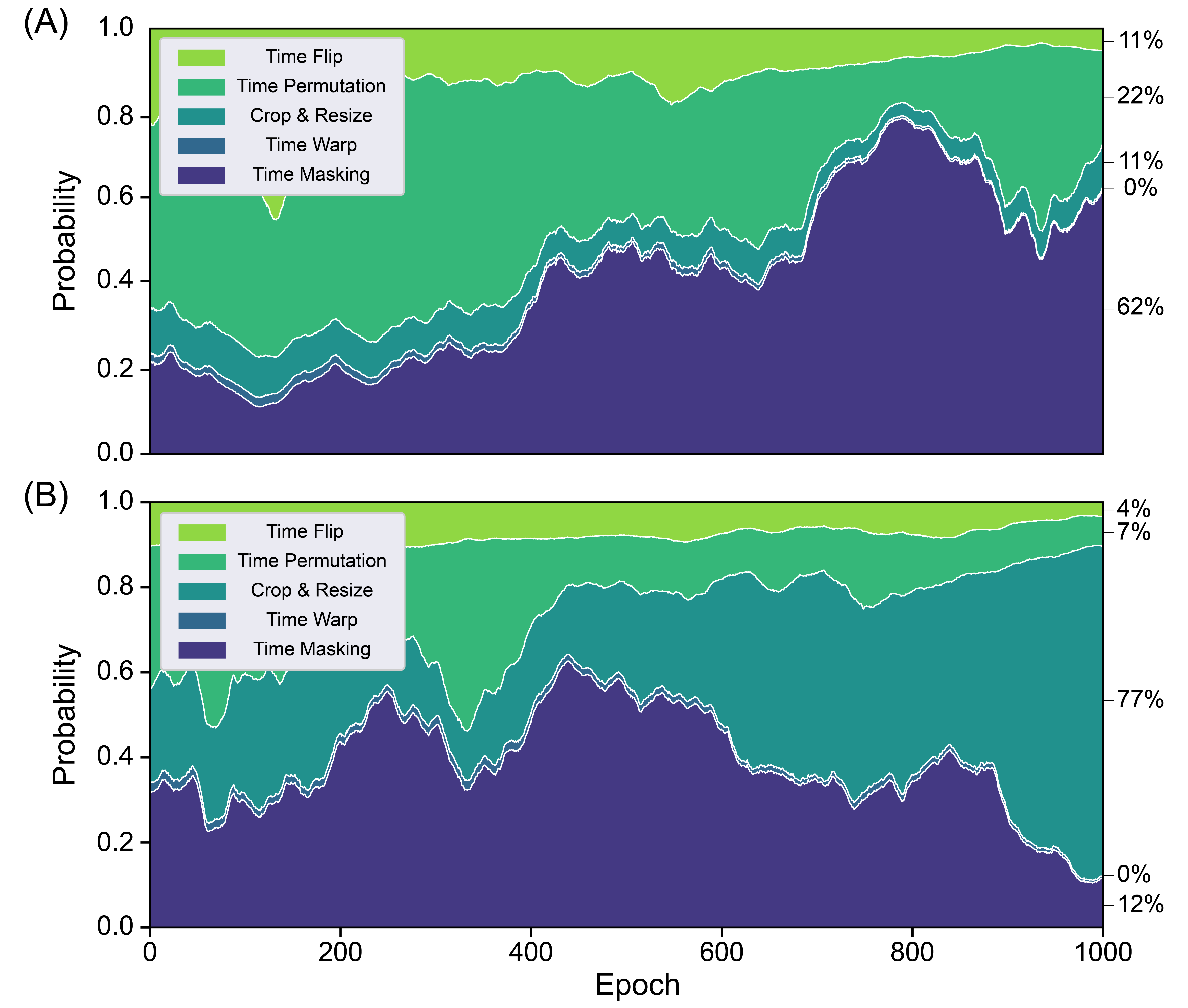
- For sleep stages, it mostly chose Time Masking (about 62%). That makes sense because sleep stages depend on broader context, and masking teaches the model to use surrounding information.
- For seizure detection, it mostly chose Crop & Resize (about 77%). That fits because seizures often show sharp, local patterns; zooming in helps the model notice those details.
They also tested different ways of picking actions and giving rewards. Letting the coach choose from the top 3 options and using the “closeness” reward worked best.
Why does this matter?
- Better learning with fewer labels: Medical labels are expensive and slow to get. This method uses only a small fraction of labels to train the coach, while the main model learns without labels.
- Smarter, safer edits: Instead of guessing which edits to use, the system adapts to each signal’s needs, helping the model learn robust, meaningful features.
- Replaces trial-and-error: It reduces reliance on hand-crafted, one-size-fits-all augmentation rules.
Big picture impact
This approach could make EEG analysis more reliable and practical in clinics, and it could extend to other biosignals like ECG (heart) or EMG (muscles). While it currently picks from a fixed set of edits and adds some computing cost, it points to a future where models automatically design the best training transformations for each piece of data.
Knowledge Gaps
Below is a concise list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research:
- Limited dataset scope: results are shown on only two EEG datasets (Sleep-EDFX, CHB-MIT), both single-channel settings, with no external/site-shift validation or cross-dataset transfer to test policy generalization under domain shift (montage changes, sampling rates, devices, institutions).
- Single-channel constraint: the approach is not evaluated on multi-channel EEG where spatial dependencies, montage variability, and channel dropouts are common; no spatial augmentation actions (e.g., channel mixing, spatial masking) are considered.
- Narrow action space: the agent chooses from five discrete, time-domain transforms only; there is no coverage of frequency-domain, time–frequency, artifact-specific, or physiology-guided augmentations that may be more appropriate for EEG.
- No augmentation parameter search: augmentation intensities and hyperparameters (e.g., mask length, crop ratio, warp factor, permutation segment count) are fixed and not learned; the agent cannot tune strengths or ranges.
- Single strong transform per sample: the policy selects exactly one strong augmentation; the framework does not explore composing multiple transforms, ordering effects, or mixup-style strategies that could increase view diversity.
- Weak augmentations are fixed: the “weak” view (jittering and scaling with fixed magnitudes) is not optimized or validated for robustness; sensitivity to weak-view choice is unreported.
- Reward supervision dependence: the Soft-KNN reward requires labels for a reference set; the approach is not label-free and its performance under very low label fractions (<10%) or varying label fractions is not studied.
- Label noise robustness: Soft-KNN reward uses ground-truth labels but EEG labels can be noisy; there is no analysis of how label noise in the reference set affects policy learning or ways to mitigate it (e.g., robust KNN, confidence-weighted labels).
- Reference set design: the effect of reference-set size, class balance, subject diversity, and maintenance (static vs refreshed during training) on reward stability and policy quality is not examined.
- Reward hyperparameters: sensitivity to Soft-KNN design choices (K, temperature τ, similarity metric, normalization) is not ablated; their impact on stability, bias toward majority classes, and convergence is unknown.
- Computational overhead and scalability: the RL loop and Soft-KNN reward introduce extra computation; there is no profiling of training/inference time, memory, or energy costs, nor strategies to reduce them for deployment.
- Cold start and non-stationary coupling: early in training, encoder embeddings are weak, yet reward depends on them; there is no study of warm-up strategies, target networks, or stabilization mechanisms to handle this bootstrapping problem.
- Ambiguity in state encoder “frozen vs updated”: the state is extracted from a “frozen encoder,” yet the encoder is “instantaneously updated” in the SSL step; it is unclear whether a separate frozen copy is used, and how representation drift between state extraction and reward impacts training.
- RL vs contextual bandit mismatch: the environment is described as non-causal (i.i.d. samples), yet actions change encoder parameters, which affect future rewards; there is no comparison to contextual bandits or supervised policy search that may be more appropriate and sample-efficient.
- Baseline coverage: comparisons omit strong automated augmentation baselines for time series (e.g., AutoAugment/RandAugment-style adaptations, PBA, TrivialAugment) and domain-informed heuristics; fairness of the comparison is therefore unclear.
- Contrastive framework generality: only SimCLR is used; it is unknown whether gains transfer to other SSL frameworks (e.g., MoCo, BYOL/SimSiam, VICReg, TS-TCC) and to different negative-sampling or batch-size regimes.
- Downstream evaluation protocol clarity: details about how the encoder is evaluated downstream (linear probe vs fine-tuning, training splits, regularization) are missing; sensitivity to classifier type and training regime is not reported.
- Limited ablations on policy learning: the impact of entropy regularization, advantage baseline choices, β schedule, learning rates, and Transformer architecture (vs simpler MLP/bandit models) is not explored.
- Exploration strategy breadth: Top-K sampling is tuned, but alternatives (e.g., Thompson sampling, UCB, softmax temperature schedules, ε-greedy with decay) are not evaluated.
- Per-class/condition policy behavior: the claim that the agent adapts to signal state is shown at a dataset level; there is no analysis of action distributions conditioned on sleep stages, seizure/non-seizure, or artifact presence to confirm fine-grained adaptivity.
- Safety and physiological plausibility: some augmentations (e.g., time flip, heavy warping) may create non-physiological signals; there is no assessment of augmentation validity against clinical criteria or constraints to prevent clinically misleading transformations.
- Robustness to artifacts and OOD data: no evaluation under common EEG artifacts (EMG bursts, electrode pops, eye blinks) or out-of-distribution recordings; resilience of the learned policy under such conditions is unknown.
- Subject and session adaptation: the policy is trained once and frozen; online adaptation or personalization to new subjects/sessions without labels (e.g., via pseudo-labels or unsupervised clustering) remains unexplored.
- Statistical reliability: results lack confidence intervals, multiple-seed runs, and significance tests; robustness to random initialization and training noise is not quantified.
- Multi-task extensibility: it is unclear whether a single policy can generalize across multiple EEG tasks or whether task-specific policies are required; strategies for multi-task or meta-learned augmentation policies are not investigated.
- Practical deployment: real-time constraints, latency of policy inference, and on-device feasibility are not characterized; mechanisms to cache/approximate policies for low-resource settings are absent.
- Reproducibility details: precise augmentation parameter ranges, batch sizes, temperatures, optimizer settings, and compute budgets are not fully specified; this hampers exact reproduction and sensitivity analysis.
Practical Applications
Below is a structured synthesis of practical, real-world applications that emerge from the paper’s findings, methods, and innovations. Each item specifies sector alignment, concrete use cases, potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be piloted or deployed with current tooling and the provided open-source implementation, assuming access to modest compute and a small labeled subset.
- Healthcare — Sleep lab model pretraining for sleep stage classification
- Tools/Products/Workflows: Integrate
RL-BioAuginto a two-phase pipeline (Phase 1: train the RL agent with ~10% labeled data and a reference set using Soft-KNN reward; Phase 2: self-supervised SimCLR pretraining on unlabeled data with the frozen agent). Use the learned policy (e.g., higher probability of Time Masking) to produce robust encoders for downstream classifiers in sleep staging. - Assumptions/Dependencies: Availability of a small, reasonably clean labeled subset; single- or multi-channel EEG compatibility; GPU access; alignment to subject-independent evaluation for generalization.
- Tools/Products/Workflows: Integrate
- Healthcare — Seizure detection model improvement for EEG monitoring devices
- Tools/Products/Workflows: Apply
RL-BioAugto pretrain encoders for seizure detection; leverage the agent’s task-adapted augmentation (e.g., Crop-Resize dominance) to improve Balanced Accuracy/Macro-F1 before supervised fine-tuning. - Assumptions/Dependencies: Small labeled subset for agent training; label quality for seizure events; compatible data segmentation and preprocessing (e.g., 4-second windows, band-pass filtering).
- Tools/Products/Workflows: Apply
- Medtech/Wearables — Consumer sleep trackers with label-efficient pretraining
- Tools/Products/Workflows: Pretrain on large unlabeled device EEG logs using
RL-BioAugwith minimal labeled calibration; deploy encoders in firmware/app for improved stage classification without extensive annotation. - Assumptions/Dependencies: Edge/cloud training pipeline; device data access and consent; sufficient on-device or cloud compute for pretraining.
- Tools/Products/Workflows: Pretrain on large unlabeled device EEG logs using
- Neurotechnology/BCI — Robust EEG encoders for limited-label BCI tasks
- Tools/Products/Workflows: Use
RL-BioAug-trained encoders to stabilize representations across non-stationary EEG states, improving downstream BCI classifiers/regressors (e.g., motor imagery). - Assumptions/Dependencies: Task-specific augmentation pool sufficiency; small labeled calibration set per user; transferability across subjects/sessions.
- Tools/Products/Workflows: Use
- Software/MLOps — AutoAugmentation SDK/API for biosignals
- Tools/Products/Workflows: Package the transformer-based policy network and Top-K sampling into an SDK that outputs per-sample augmentation probabilities; integrate with PyTorch/TensorFlow training loops for EEG SSL.
- Assumptions/Dependencies: Teams adopt SimCLR or similar contrastive frameworks; access to labeled reference set for reward computation; operational monitoring to avoid policy collapse (entropy regularization tuned).
- Academia — Task-specific augmentation benchmarking and reproducible policy reporting
- Tools/Products/Workflows: Use
RL-BioAugto derive and publish augmentation policy distributions (e.g., 62% Time Masking for sleep, 77% Crop-Resize for seizures), enabling replicable comparisons against static/random baselines and informing design of new SSL methods for time series. - Assumptions/Dependencies: Comparable datasets and splits; consistent preprocessing; shared code and config for reproducibility.
- Tools/Products/Workflows: Use
- Data services — Label cost reduction in EEG curation projects
- Tools/Products/Workflows: Employ the RL-guided augmentation policy to pretrain encoders with ~10% labels; rely on SSL for representation learning, decreasing the volume of expert annotations needed before supervised fine-tuning.
- Assumptions/Dependencies: Minimal yet representative labeled subset; governance around label noise; curated reference set for Soft-KNN reward.
- Education/Training — Practical teaching modules for non-causal RL and SSL in time series
- Tools/Products/Workflows: Course labs using the open-source repo to illustrate the non-causal RL setting, Soft-KNN reward shaping, and augmentation impacts on InfoNCE objectives.
- Assumptions/Dependencies: Basic GPU access in educational settings; students’ familiarity with contrastive learning.
- Policy/Governance — Procurement guidance for clinical AI with label-efficient pretraining
- Tools/Products/Workflows: Immediate inclusion of adaptive augmentation and label-efficient SSL requirements in RFPs for EEG analytics tools to lower annotation costs and improve performance under non-stationarity.
- Assumptions/Dependencies: Stakeholder buy-in; basic methodological literacy among evaluators; pilot evidence within the health system’s data.
- Daily life/Open-source — Community-driven sleep/seizure projects
- Tools/Products/Workflows: Hobbyists and startups adopt the GitHub implementation to pretrain models on available datasets, then fine-tune for personal or community health projects.
- Assumptions/Dependencies: Data access and responsible use; modest compute; adherence to privacy/ethics norms.
Long-Term Applications
These require further research, scaling, optimization, or regulatory maturation before broad deployment.
- Healthcare — On-device continual learning with adaptive augmentation
- Tools/Products/Workflows: Edge RL agents that adjust augmentation policies during continual learning to personalize models across time and subjects in home monitoring or ICU settings.
- Assumptions/Dependencies: Efficient, low-latency policy networks; power/memory constraints; robust safeguards against catastrophic forgetting and spurious adaptations.
- Cross-modality biosignals — Dynamic augmentation for ECG/EMG and beyond
- Tools/Products/Workflows: Extend
RL-BioAugto modality-specific augmentation pools (e.g., beat-level warp for ECG; segment jitter for EMG) with analogous Soft-KNN rewards built from small labeled reference sets. - Assumptions/Dependencies: Carefully designed, clinically valid augmentation primitives per modality; validation across datasets and devices; domain-specific reward calibration.
- Tools/Products/Workflows: Extend
- Generative augmentation synthesis — Continuous action spaces and learned transforms
- Tools/Products/Workflows: Replace discrete pools with generative components (e.g., diffusion/GAN-based transform generators) controlled by a policy over continuous parameters to tailor augmentations to signal states.
- Assumptions/Dependencies: Safety constraints to preserve clinical semantics; stable training of generative models in noisy biosignal regimes; reliable reward signals.
- Reward robustness — Label-noise-aware and label-free reward mechanisms
- Tools/Products/Workflows: Develop rewards that reduce dependence on potentially noisy ground truth (e.g., confidence-weighted Soft-KNN, consistency-based pseudo-labels, mutual information approximations).
- Assumptions/Dependencies: Strong theoretical and empirical validation; safeguards against reward hacking; improved convergence stability.
- Regulatory/Standards — Guidance on adaptive augmentation and SSL in medical AI
- Tools/Products/Workflows: Standards bodies (e.g., FDA/EMA/ISO) define evaluation protocols and documentation requirements for label-efficient SSL pipelines and augmentation policies, including stress-testing across non-stationary regimes.
- Assumptions/Dependencies: Multi-center clinical evidence; reproducible testbeds; alignment with safety and transparency frameworks.
- Hospital-scale AI ops — Autonomous pretraining pipelines integrated with data lakes
- Tools/Products/Workflows: Enterprise platforms that automatically pretrain EEG encoders using
RL-BioAugon incoming unlabeled streams, exposing embeddings for diverse clinical tasks (sleep, seizure, encephalopathy). - Assumptions/Dependencies: Secure data infrastructure; privacy-preserving training; MLOps for monitoring reward dynamics, policy entropy, and performance drift.
- Tools/Products/Workflows: Enterprise platforms that automatically pretrain EEG encoders using
- Energy/Sustainability — Efficient training of RL-guided SSL for biosignals
- Tools/Products/Workflows: Hardware-aware agent designs, mixed-precision training, and pruning/distillation to reduce compute footprints and environmental impact.
- Assumptions/Dependencies: Collaboration with hardware vendors; algorithmic advances in efficient RL/SSL; clear energy metrics.
- Finance/Insurance — EEG-derived risk models and reimbursement analytics
- Tools/Products/Workflows: Deploy robust, generalizable EEG features to support risk stratification (e.g., sleep disorders, epilepsy management), informing coverage and reimbursement decisions.
- Assumptions/Dependencies: Regulatory acceptance; population-level validation; interoperable data standards.
- Robotics/HRI — Improved intent decoding from EEG for assistive systems
- Tools/Products/Workflows: Use
RL-BioAug-pretrained encoders to stabilize intent signals for exoskeletons, prosthetics, or teleoperation systems. - Assumptions/Dependencies: Cross-task transfer validity; low-latency inference; human factors studies for safety/usability.
- Tools/Products/Workflows: Use
- Tooling/MLOps — Augmentation policy observability and governance dashboards
- Tools/Products/Workflows: Build UI dashboards to visualize action probabilities, reward trajectories, Top-K diversity, and downstream metrics; integrate alerts for policy collapse or reward sparsity.
- Assumptions/Dependencies: Standardized logging schemas; human-in-the-loop review; alignment with audit and compliance needs.
- Cloud platforms — “BioAug-as-a-Service” for pretrained biosignal encoders
- Tools/Products/Workflows: Managed services that pretrain and serve encoders and augmentation policies, enabling developers to fine-tune on their data with minimal labels.
- Assumptions/Dependencies: Data privacy and federated learning support; service-level agreements; robust cross-domain generalization.
- Education — Curricular integration of non-causal RL and adaptive augmentation
- Tools/Products/Workflows: MOOCs and textbooks formalizing non-causal RL environments, Soft-KNN reward design, and adaptive augmentation for biosignals, shaping future practitioners’ skillsets.
- Assumptions/Dependencies: Community consensus on best practices; accessible teaching datasets; sustained support from academic institutions.
In summary, the paper’s core contribution—an RL-guided, label-efficient augmentation policy for self-supervised EEG representation learning—immediately enables better-performing, lower-annotation-cost pipelines in healthcare and research, while opening longer-term pathways toward adaptive, generative augmentation ecosystems, cross-modality biosignal applications, and standardized governance of label-efficient medical AI.
Glossary
- Advantage function: A variance-reducing baseline-adjusted reward signal used in policy gradient methods to stabilize learning. "To suppress the variance of the policy gradient, we utilize the advantage function ."
- Balanced Accuracy (B-ACC): Metric that averages per-class recall to handle class imbalance. "Balanced Accuracy (B-ACC) is defined as the arithmetic mean of recall for each class."
- Band-pass suppose: A filter that retains frequencies within a specified range and attenuates frequencies outside it. "we applied a 0.5--40 Hz band-pass filter"
- CHB-MIT: A scalp EEG dataset used for epileptic seizure detection research. "We utilized the CHB-MIT Scalp EEG dataset for epileptic seizure detection."
- Contrastive learning: A self-supervised paradigm that pulls positive pairs together and pushes negatives apart in representation space. "The core principle of contrastive learning is to maximize the similarity between positive pairs generated by data augmentation"
- Cosine similarity: A similarity measure between vectors based on the cosine of the angle between them. "Based on the cosine similarity "
- Crop {paper_content} Resize: A strong time-series augmentation that crops a segment and resizes it back to original length. "Crop {paper_content} Resize crops a local temporal region and resizes it to the original length."
- Electromyogram (EMG) artifacts: Muscle activity-induced disturbances contaminating EEG signals. "Wake state with frequent EMG artifacts"
- Entropy regularization: A technique that adds policy entropy to the objective to encourage exploration and avoid premature convergence. "we incorporate an entropy regularization term."
- Exploration–exploitation trade-off: The balance between trying new actions and leveraging known good actions in RL. "controls the trade-off between exploration and exploitation."
- Indicator function: A function that returns 1 when a condition is met and 0 otherwise, used to select label-matching neighbors. "is an indicator function that returns 1 if the condition is met and 0 otherwise."
- Jittering: Weak augmentation that adds small random noise to signals to simulate sensor noise. "Jittering injects gaussian noise with a standard deviation of 0.01 into the original signal."
- Label-efficient reinforcement learning: RL that uses a small fraction of labeled data to guide policy learning. "leverages a label-efficient reinforcement learning (RL) agent"
- Macro F1-Score (MF1): The unweighted mean of per-class F1-scores, emphasizing performance across all classes. "Macro F1-Score (MF1) is defined as the unweighted mean of per-class F1-scores."
- Non-causal environment: An RL setting where actions do not affect future state distributions, removing long-term planning considerations. "Given this non-causal nature, we designed the agent to focus solely on analyzing the immediate context rather than formulating long-term future plans."
- Non-stationarity: When signal statistics change over time, complicating fixed augmentation strategies. "non-stationarity of EEG signals where statistical properties change over time."
- Policy entropy: The entropy of a policy’s action distribution, used to measure and encourage exploration. "here, the policy entropy term , which encourages exploration over the action space "
- Policy gradient: A class of RL algorithms that optimize policies by ascending the gradient of expected returns. "RL Step: agent update via policy gradient."
- Positional embeddings: Encodings added to sequences to inject order information into Transformer models. "Positional embeddings are added to the integrated sequence before it is fed into the Transformer."
- Reference set: A labeled subset of data used to compute reward signals or consistency measures. "from a distinct reference set in the embedding space."
- REINFORCE++ algorithm: A reinforced policy gradient variant adopted for stable convergence in noisy environments. "we adopt the REINFORCE++ algorithm~\cite{hu2025reinforce++}."
- ResNet18-1d: A 1D convolutional residual network used as the encoder for time-series signals. "We employed ResNet18-1d~\cite{wang2017time} as the encoder."
- Self-attention mechanism: A Transformer component that relates different positions in a sequence to capture dependencies. "The self-attention mechanism captures the historical context of policy-reward dynamics to infer the current representation state."
- Self-supervised learning (SSL): Learning representations from unlabeled data by constructing supervisory signals from the data itself. "We utilized the entire training dataset for SSL, completely excluding labels."
- SimCLR: A contrastive learning framework sensitive to augmentation quality, used here for EEG representation learning. "We selected SimCLR \cite{chen2020simple} as our contrastive learning framework"
- Sleep-EDFX: A sleep EEG benchmark dataset used for stage classification tasks. "We employed the Sleep-Cassette subset of the Sleep-EDFX dataset for sleep stage classification"
- Soft-KNN consistency score: A reward signal computed via soft, similarity-weighted KNN classification in embedding space. "using the Soft-KNN consistency score on a reference set to reward the agent."
- Subject-independent split: A data partitioning strategy where training and testing subjects are disjoint to assess generalization. "we adopted a subject-independent split strategy"
- Temperature (τ): A scaling factor in softmax that controls the sharpness of similarity distributions. "scaled by temperature ."
- Time Flip: A strong augmentation that reverses the temporal order of the signal. "Time Flip reverses the time axis."
- Time Masking: A strong augmentation that zeroes out random temporal segments to enforce contextual inference. "Time Masking masks arbitrary time intervals with zeros."
- Time Permutation: A strong augmentation that shuffles segments to challenge reliance on global order. "Time Permutation segments the signal into multiple intervals and randomly shuffles their order."
- Time Warp: A strong augmentation that stretches or compresses the temporal axis to simulate speed changes. "Time Warp arbitrarily accelerates or decelerates the speed of signal."
- Top-K nearest neighbors: The K most similar samples used to compute similarity-weighted label probabilities. "the labels of the top- nearest neighbors:"
- Top-K Sampling: Selecting an action from the K most probable choices to balance exploration and stability. "Finally, the action is selected via Top-K Sampling, which effectively balances exploration and stability."
- z-normalization: Standardizing signals by subtracting mean and dividing by standard deviation. "and performed z-normalization."
Collections
Sign up for free to add this paper to one or more collections.