- The paper introduces CAOS, a leave-one-out conformal method that aggregates one-shot predictors to achieve exact marginal coverage.
- It employs a k-minimum sum operator and adaptive aggregation to fully utilize limited labeled data for efficient uncertainty quantification.
- Empirical results in facial landmarking and text classification demonstrate CAOS’s superiority in reducing prediction set size while maintaining reliable coverage.
Motivation and Problem Setting
Robust uncertainty quantification in low-data regimes is crucial for the safe deployment of pretrained foundation models in few-shot learning tasks across vision and language domains. The one-shot paradigm, where each labeled example serves as an instance-specific predictor, yields a collection of conditional models with varying relevance for query inputs. Conformal prediction, particularly the split conformal method, guarantees marginal coverage for prediction sets but suffers from substantial inefficiency when calibration data are scarce; further, it is not designed to leverage the heterogeneity and adaptive aggregation inherent to one-shot collections. The challenge addressed by "CAOS: Conformal Aggregation of One-Shot Predictors" (2601.05219) centers on constructing small, reliable prediction sets for one-shot ensembles while maximizing data efficiency and retaining strict conformal validity.
The CAOS Methodology
CAOS introduces a leave-one-out conformal prediction procedure specifically tailored for the aggregation of multiple one-shot predictors. Rather than splitting the limited labeled data into reference and calibration sets as in split conformal methods, CAOS utilizes all available labeled examples for both purposes via a leave-one-out scheme. For each test input, the method aggregates nonconformity scores across all reference examples, focusing adaptively on the most informative sources using a k-minimum sum operator. Calibration is performed by excluding each labeled example in turn from the reference set and using the remaining pool to compute scores, thus fully exploiting data efficiency.
To formalize, given n labeled examples, each inducing a one-shot predictor and corresponding nonconformity score, CAOS defines a prediction set for new inputs by aggregating the k lowest nonconformity scores (typically k=3), calibrates thresholds using empirical quantiles of leave-one-out scores, and uses these thresholds for set construction. The aggregated score is symmetric and monotonic in the reference set—a property leveraged in the theoretical analysis.
Theoretical Guarantee and Coverage Analysis
A critical feature of CAOS is its ability to break classical exchangeability assumptions at the score level yet recover exact marginal coverage guarantees. The method’s validity is anchored by a monotonicity-based reduction to full conformal prediction: the leave-one-out aggregation ensures that an increase in calibration data can only improve (decrease) nonconformity scores for any input-output pair. The theoretical argument establishes that under a natural “self-score optimality” assumption—where each label is maximally informative about itself—the CAOS prediction set contains the full conformal set, hence inherits its sharp coverage guarantee.
The paper rigorously proves finite-sample marginal coverage at the target level 1−α, independent of the adaptive aggregation procedure, as long as the nonconformity scoring is symmetric and monotonic. This result contradicts conventional understanding that data-adaptive or ensemble methods require additional slack or rely on disjoint calibration structures, and thus represents a strong claim regarding the interplay of adaptivity, efficiency, and validity in conformal prediction frameworks.
Empirical Evaluation: Facial Landmarking and Text Classification
CAOS’s empirical advantages are demonstrated on two benchmarks: exemplar-based facial landmarking via patch similarity in computer vision, and one-shot text classification using LLMs on the RAFT benchmark. Prediction set size and empirical coverage are key metrics.
In facial landmarking, CAOS yields substantially tighter prediction sets across 478 landmarking tasks with reliable coverage at various α thresholds. Specifically, at α=0.05, CAOS achieves a mean coverage of $0.953$ with an average prediction set size of $15.96$ (SEM $0.58$), significantly outperforming SCOS Avg. ($36.07$) and SCOS Best ($20.49$) while closely approaching the unattainable Oracle ($16.66$).
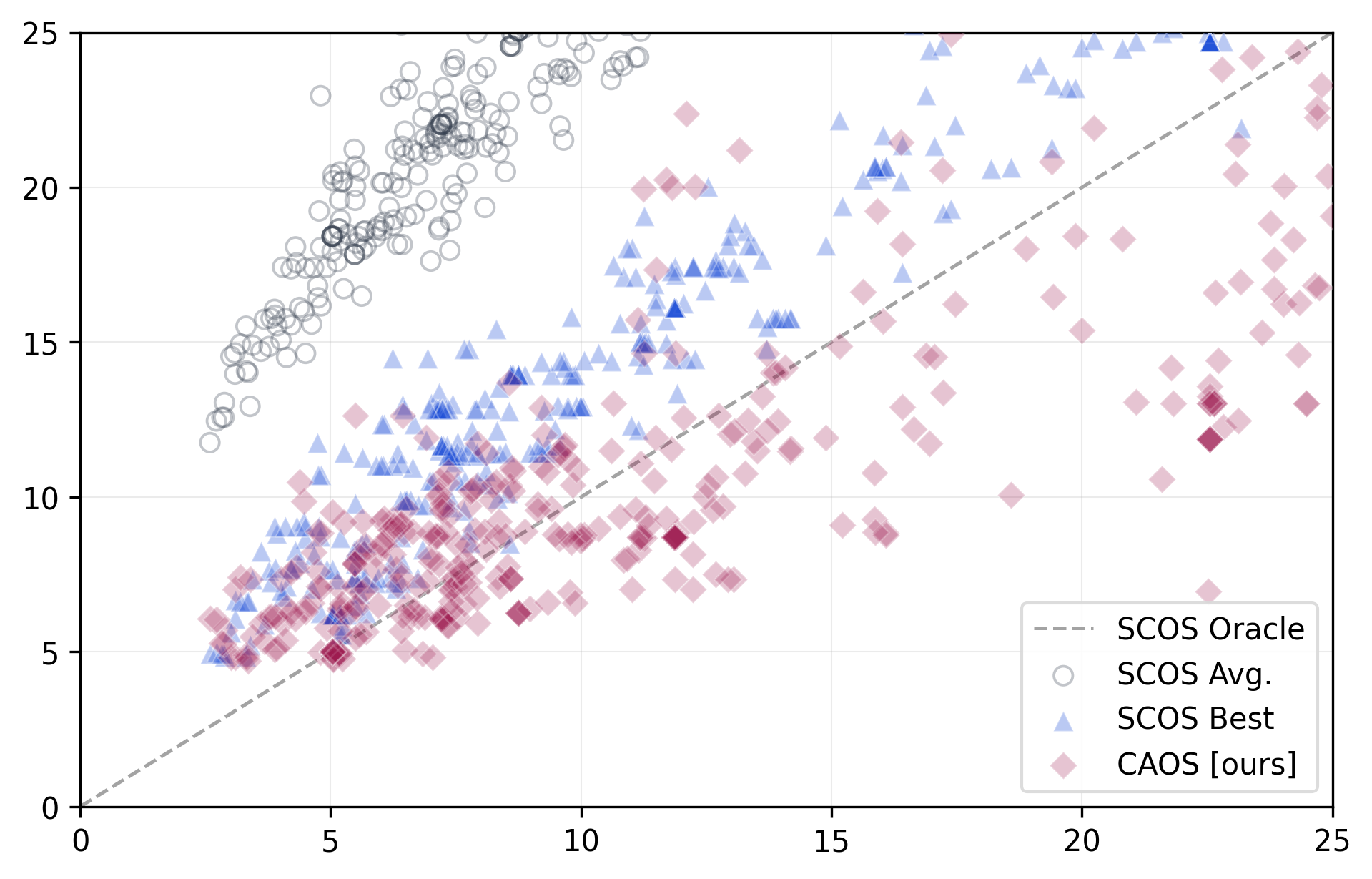
Figure 1: CAOS produces smaller prediction sets per landmark, approaching the efficiency of the SCOS Oracle.

Figure 2: Visualization of prediction set sizes for CAOS versus SCOS on three test images illustrating qualitative reduction in uncertainty.
On RAFT one-shot text classification tasks with Llama2-7B, CAOS consistently produces smaller prediction sets at the target α=0.1 with empirical coverage meeting or exceeding the nominal level in more tasks than SCOS. For 8 of 9 tasks, CAOS delivers lower predictive uncertainty, and in challenging settings retains validity where SCOS fails, underscoring the efficiency gain from adaptive aggregation.
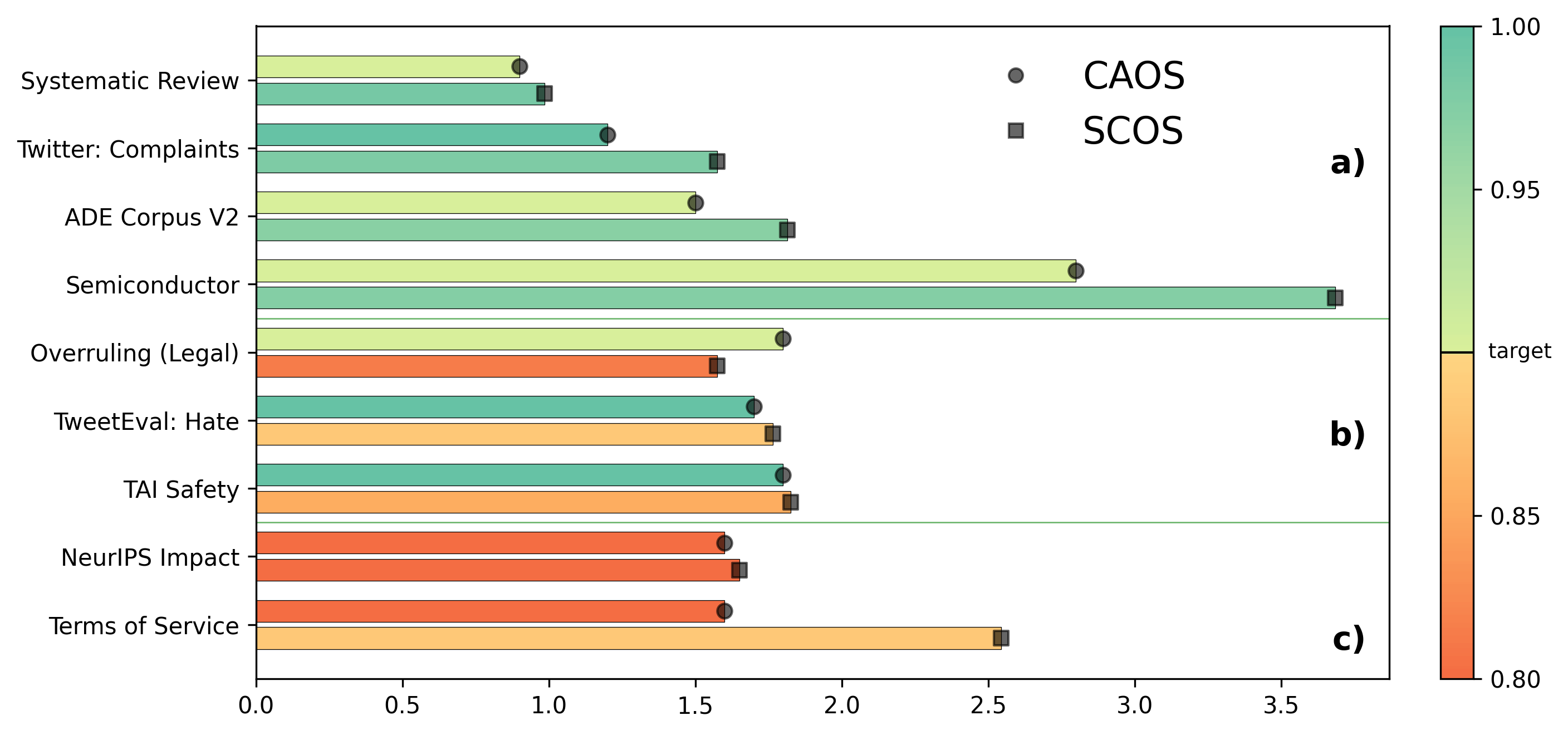
Figure 3: CAOS outperforms SCOS in average conformal set size and empirical coverage across RAFT tasks.
Practical and Theoretical Implications
CAOS advances the state of conformal prediction by demonstrating that adaptive aggregation with full calibration participation is compatible with exact marginal coverage under structured score monotonicity. This paves the way for more efficient conformal methods in low-sample settings, where standard approaches suffer from data splitting overheads that inflate predictive uncertainty. The framework's relevance extends to ensemble model selection, instance-adaptive uncertainty quantification, and practical machine learning deployments that prioritize sharp error control and small set sizes.
Theoretically, CAOS highlights that score-level exchangeability is not universally required for conformal validity provided the aggregation mechanism is monotonic and symmetric, suggesting new directions in the design and analysis of robust predictive inference methods. The monotonicity-based coverage argument may be applicable to broader classes of adaptive conformal algorithms, including those for online prediction and non-stationary data.
Perspectives and Future Directions
The aggregation principle underlying CAOS can be generalized to combinations of predictors with varying confidence, hierarchical label spaces, and structured prediction tasks. Future research may explore automated selection of aggregation hyperparameters (k), extensions to multiclass or regression settings, and integration with full in-context learning protocols for multimodal foundation models. Further, establishing tight control for coverage under more aggressive selection and adaptive post-processing, and characterizing limitations under distribution shift or non-exchangeable data, remain compelling next steps.
Conclusion
CAOS provides a theoretically sound, data-efficient framework for uncertainty quantification in one-shot prediction, demonstrably improving over split conformal baselines in both facial landmarking and text classification. The method’s reliance on monotonic score aggregation rather than rigid exchangeability facilitates sharp coverage guarantees without sacrificing adaptivity or efficiency. These contributions open new methodological avenues for reliable predictive inference in resource-constrained settings and suggest promising directions for future research in adaptive conformal methodologies.