InfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields
Abstract: Existing depth estimation methods are fundamentally limited to predicting depth on discrete image grids. Such representations restrict their scalability to arbitrary output resolutions and hinder the geometric detail recovery. This paper introduces InfiniDepth, which represents depth as neural implicit fields. Through a simple yet effective local implicit decoder, we can query depth at continuous 2D coordinates, enabling arbitrary-resolution and fine-grained depth estimation. To better assess our method's capabilities, we curate a high-quality 4K synthetic benchmark from five different games, spanning diverse scenes with rich geometric and appearance details. Extensive experiments demonstrate that InfiniDepth achieves state-of-the-art performance on both synthetic and real-world benchmarks across relative and metric depth estimation tasks, particularly excelling in fine-detail regions. It also benefits the task of novel view synthesis under large viewpoint shifts, producing high-quality results with fewer holes and artifacts.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a computer to tell how far away things are in a picture taken with a single camera. That “how far” information is called depth. The new method, called InfiniDepth, can predict depth at any spot in an image, at any resolution you want (from small to super high-res), while keeping tiny details sharp.
What questions did the researchers ask?
They focused on three simple questions:
- Can we predict depth as a smooth, continuous signal (not just on a fixed grid of pixels), so we can get sharp details at any resolution?
- Can this help recover tricky, fine structures in a scene (like thin edges, railings, or leaves) that often get blurred by other methods?
- Can better depth also improve “novel view synthesis” (making new images as if the camera moved), especially when the viewpoint changes a lot?
How did they do it?
From fixed grids to continuous depth
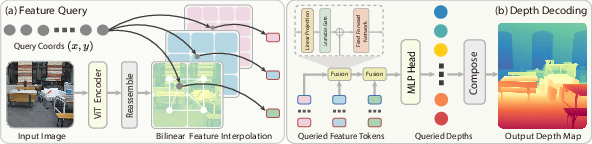
Most systems predict depth on a fixed pixel grid, like painting numbers on a checkerboard. That makes it hard to zoom in or get finer details without blurring. InfiniDepth does something different: it learns a function that you can “ask” for the depth at any 2D point in the image—not just at pixel centers. Think of it like a calculator that, given a location on the picture, tells you the distance there. This is called a neural implicit field.
Getting clues from the image at different scales
The method first reads the image using a vision transformer (a powerful type of neural network) to create feature maps—summaries of what’s in the image—at different scales:
- High-resolution features capture fine details (edges, thin lines).
- Lower-resolution features capture the overall structure (big shapes and layout).
For any point you ask about, InfiniDepth grabs a small neighborhood of features around that point at each scale (using smooth interpolation) so it knows the local details and the global context.
Predicting depth at any spot
After collecting those multi-scale clues, a small network (an MLP, think “mini calculator”) fuses them and outputs the depth value for that exact point. Because the point can be anywhere, the model naturally supports any output resolution—just ask for more points more densely when you want a 4K or even higher-res depth map.
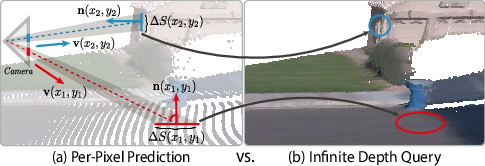
Making better 3D points for new views
To make new views (as if the camera moved), you turn each pixel’s depth into a 3D point cloud. A problem with regular per-pixel depth is that these 3D points end up bunched in some places and too sparse in others, causing holes and artifacts. InfiniDepth fixes this by:
- Estimating how much real surface area each pixel covers (which depends on how far it is and how the surface is tilted).
- Asking for several sub-pixel depth samples where needed, so the resulting 3D points are spread more evenly across surfaces. This makes the 3D reconstruction more complete and stable when the viewpoint changes a lot.
What did they find?
The researchers built a new 4K benchmark called Synth4K from five different video games, which includes very detailed depth maps and special masks to focus on fine-detail regions (like sharp edges). They also tested on popular real-world datasets.
Here are the highlights:
- InfiniDepth reached state-of-the-art accuracy on both synthetic (4K) and real-world tests, with especially strong performance on tiny, high-frequency details.
- Because it can predict depth at any resolution directly (no upscaling needed), it keeps edges and thin structures sharper than grid-based methods.
- When used for novel view synthesis, its more uniform 3D points led to noticeably fewer holes and artifacts under big camera moves.
- With a small amount of extra information (sparse depth “prompts”), it also achieved very strong metric depth (real scale) performance.
Why does this matter?
- Sharper, scalable depth: Apps like 3D scanning, AR filters, and robotics need precise depth at high resolutions. A continuous method lets you zoom in and still get clean geometry.
- Better 3D from a single image: More accurate depth turns 2D photos into richer 3D scenes with fewer glitches, improving virtual tours, editing, and visual effects.
- Strong foundation for future systems: Representing depth as a continuous function opens doors to smoother, more consistent 3D perception across many tasks.
In short, InfiniDepth shows that treating depth as a continuous function you can query anywhere—not just a fixed grid—brings sharper details, flexible resolutions, and better 3D reconstructions, which can power a wide range of visual technologies.
Knowledge Gaps
Below is a single, consolidated list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each point highlights a concrete direction for future research.
- Temporal consistency: The model is trained on single images and does not enforce temporal coherence; how to extend the implicit depth field to multi-view/video with explicit constraints (e.g., optical-flow-consistent depth, bundle-level consistency) remains open.
- Synthetic-only training: The method is trained exclusively on synthetic RGB-D; the extent of domain gap under diverse real-world conditions (sensor noise, motion blur, rolling shutter, lighting extremes, weather) is not quantified nor addressed via adaptation strategies.
- Efficiency at arbitrary resolutions: Querying continuous coordinates at 4K (or higher) may be computationally heavy; runtime, memory footprint, and throughput versus grid-based decoders at different output resolutions are not fully characterized, nor are optimizations (e.g., caching, vectorized querying, tiling).
- Scaling behavior: It is unclear how performance and runtime scale with resolution (e.g., 4K→8K) and with the number of query points per pixel for NVS; systematic scaling laws and bottlenecks are not provided.
- Sparse-depth utilization without prompts: Metric depth is improved via a third-party prompt module; a native mechanism to integrate camera intrinsics and sparse depth directly into the implicit decoder, and its sensitivity to sparsity patterns and noise, is not explored.
- Uncertainty and confidence: The implicit field produces point estimates without uncertainty; how to estimate, calibrate, and exploit per-query confidence for downstream tasks (e.g., NVS, SLAM) is missing.
- Normal estimation stability: Surface normals are derived via autograd from the depth field; numerical stability, bias at discontinuities, sensitivity to ε, and robustness under high-frequency regions are not analyzed.
- Query budget formulation: The sub-pixel budget w(x,y) ∝ d²⋅|n·v| is motivated but lacks a formal derivation; sensitivity to camera intrinsics, field-of-view, and non-pinhole models, and the optimal budget allocation per pixel are not studied.
- Occlusions and hidden surfaces in NVS: The uniform point sampling targets visible surfaces only; handling occluded/back surfaces, disocclusions, and scene completion for large viewpoint shifts is left open.
- Quantitative NVS evaluation: NVS improvements are shown qualitatively; standardized metrics (e.g., PSNR, SSIM, LPIPS) and comparisons against strong baselines (NeRF/GS variants with depth priors or multi-view cues) are missing.
- Edge-aware consistency: Behavior at depth discontinuities (boundary precision, bleeding, cross-edge mixing due to bilinear feature interpolation) is not quantitatively measured (e.g., boundary F-scores).
- Feature query design space: The main decoder uses 2×2 bilinear interpolation over multi-scale features; broader alternatives (learned offsets, deformable sampling, cross-attention, positional encodings/Fourier features) and their trade-offs for high-frequency recovery are not systematically compared.
- Training supervision: The model is trained with L1 loss on randomly sampled points; the impact of sample count N, sampling distributions (bias toward high-frequency regions), and auxiliary losses (e.g., gradient/normal/edge/photometric consistency) is unexamined.
- Encoder dependence: Results rely on DINOv3 ViT-L; robustness to smaller backbones, different pretraining regimes, and efficiency–accuracy trade-offs are not thoroughly explored.
- Implicit versus explicit baselines: The paper does not compare against strong implicit 2D baselines (e.g., LIIF-style continuous decoders for depth) at high resolution, leaving the relative gains of the proposed local implicit decoder under-tested.
- Camera intrinsics and calibration: For relative depth, intrinsics are not leveraged; investigating a unified formulation that conditions the implicit field on intrinsics (and distortion models) could reduce scale ambiguity—this is not attempted.
- Frequency-resolved evaluation: While HF masks provide a proxy for detail regions, sensitivity to mask construction (thresholds, scales), cross-dataset consistency, and correlation with perceptual geometry quality are not analyzed.
- Robustness to materials and effects: Performance on reflective, transparent, refractive, or texture-less surfaces (common failure modes for monocular depth) is not reported; synthetic datasets may underrepresent these effects.
- Interactive/streaming use: The latency of on-demand continuous querying for interactive applications (AR, robotics) and strategies for amortization or caching are not discussed.
- Global consistency and integrability: Constraints ensuring integrable surface geometry (e.g., consistency of normals/curvature across queries) and enforcing physically plausible shape priors within the implicit field are not explored.
- Failure case analysis: Detailed error breakdowns (near/far depth ranges, thin structures, repetitive patterns, extreme perspective) and diagnostic tools to guide improvements are absent.
- Data diversity and coverage: Synth4K’s coverage of scene categories, camera motions, and depth ranges is not quantified; benchmarking protocols for generalization beyond the five games are not established.
- Memory–accuracy trade-offs: Storing multi-scale pyramids and querying hierarchically may be memory-intensive; ablations quantifying parameter count, cache sizes, and their effect on detail recovery are not presented.
- Multi-task integration: How the implicit depth field could be co-trained with semantics, surface normals, or planar primitives to further improve fine geometry is left as future work.
Practical Applications
Overview
This paper introduces InfiniDepth—a neural implicit representation of depth that enables querying depth at arbitrary continuous 2D coordinates and preserves fine-grained geometry. It also proposes an “infinite depth query” strategy to generate approximately uniform 3D points on surfaces, which improves single-view novel view synthesis (NVS), and provides Synth4K, a 4K benchmark that targets high-resolution and high-frequency geometric details. Below are practical applications organized by deployment readiness.
Immediate Applications
The following applications can be piloted or deployed with current tooling, leveraging the project page, codebase, and demonstrated results.
- Industry (VFX, Games, 3D Content Creation) — Single-view NVS quality booster
- Product/workflow: Integrate InfiniDepth’s infinite depth query with Gaussian Splatting pipelines (e.g., ADGaussian) to reduce holes/artifacts during large viewpoint shifts; ship as a plugin for Blender/Unreal/Unity/DCC tools.
- Tools: “InfiniDepth GS Query” plugin; “Uniform Surface Point Generator.”
- Dependencies/assumptions: Known camera intrinsics; integration with existing GS renderer; compute budget for 4K queries; domain shift from synthetic to real may require light tuning.
- Industry (Imaging/Photo Apps) — High-resolution bokeh, relighting, and background replacement from a single image
- Product/workflow: Use InfiniDepth’s relative depth for finer edge preservation in portrait mode, matting, and relighting; build Photoshop/Lightroom/Figma plugins and mobile SDKs.
- Tools: “InfiniDepth Depth Map API”; “Fine-Detail Mask Utility.”
- Dependencies/assumptions: Relative depth is sufficient for bokeh/relighting; high-frequency detail recovery validated on Synth4K; accuracy may vary across camera domains.
- Industry (Mobile AR) — Better occlusion and scene understanding from monocular inputs
- Product/workflow: Continuous sub-pixel depth queries for improved occlusion boundaries and per-surface uniformity in AR scenes; bundle into ARKit/ARCore modules.
- Tools: “InfiniDepth AR Occlusion Module.”
- Dependencies/assumptions: Camera intrinsics available; latency/thermal constraints on-device; video temporal consistency not yet enforced (possible flicker).
- Industry (Robotics/Autonomous Driving) — Depth super-resolution with sparse sensors
- Product/workflow: Use Ours-Metric (with sparse depth prompts) to densify and refine LiDAR/ToF depth maps and capture fine geometry (edges, thin structures) in perception stacks.
- Tools: “Depth Completion/SR SDK for LiDAR/ToF.”
- Dependencies/assumptions: Reliable calibration between RGB and sparse depth; real-time constraints; safety validation under domain shift.
- Academia — Benchmarking and research on high-resolution, fine-grained depth
- Product/workflow: Adopt Synth4K and its high-frequency masks to evaluate detail-sensitive regions; use the local implicit decoder as a baseline for continuous depth research.
- Tools: “Synth4K Benchmark Suite”; “Local Implicit Decoder Reference Implementation.”
- Dependencies/assumptions: Synthetic-only training provides clean supervision; require clear licensing and reproducible protocols.
- Academia/Industry — Arbitrary-resolution depth querying for multi-scale analysis
- Product/workflow: Use continuous depth queries to probe fine structures at arbitrary scales (e.g., failure mode analysis, inspection of depth boundaries).
- Tools: “Depth Query Explorer”; “Feature Pyramid Inspector.”
- Dependencies/assumptions: ViT backbone (DINOv3) used in paper; compute cost at very high resolutions.
- Industry (E-commerce/Product Visualization) — Single-image 3D effects and pseudo-3D turntables
- Product/workflow: Use InfiniDepth to generate plausible depth for product shots to enable parallax/tilt effects and micro camera moves with fewer artifacts.
- Tools: “Parallax/NVS Micro-Effect Pipeline.”
- Dependencies/assumptions: Relative depth suffices; controlled studio lighting/camera metadata improves robustness.
- Policy/Standards — Evaluation criteria for monocular depth in tenders and audits
- Product/workflow: Use Synth4K and detail masks to standardize procurement tests for monocular depth systems emphasizing high-frequency recovery and 4K scalability.
- Tools: “Depth Evaluation Protocol (4K + HF mask).”
- Dependencies/assumptions: Synthetic-to-real representativeness must be stated; include real-world validation alongside Synth4K.
Long-Term Applications
These applications are promising but require further research, scaling, and development—e.g., temporal consistency, domain adaptation, on-device efficiency, multi-view training.
- Industry (Autonomous Driving) — Monocular fallback and edge-case geometric understanding
- Product/workflow: Deploy InfiniDepth-based monocular modules to refine thin objects (poles, wires), road edges, and occlusion cues, especially when LiDAR/vision degrades.
- Dependencies/assumptions: Extensive real-world training; safety certification; temporal stability in video; robust across weather/night.
- Industry (Robotics Manipulation) — Precision grasping and contact-rich tasks with fine geometry
- Product/workflow: High-detail monocular depth to aid grasp planning on small/deformable objects; integrate with tactile sensing and multi-view cameras.
- Dependencies/assumptions: Multi-view/temporal extensions; task-specific datasets; latency constraints.
- Industry (AEC/Digital Twins) — As-built capture and remodeling from commodity cameras
- Product/workflow: Use continuous depth queries to uplift single-/few-view imagery into higher-detail meshes for rapid site assessment and change tracking.
- Dependencies/assumptions: Multi-view consistency; scale-aware metric depth; integration with SfM/SLAM pipelines.
- Industry (AR Cloud/Spatial Computing) — Dynamic occlusion and scene reconstruction at scale
- Product/workflow: Continuous depth fields for uniform surface sampling in AR cloud maps; improved surface completeness for large viewpoint shifts.
- Dependencies/assumptions: Temporal consistency; large-scale map management; privacy and calibration policies.
- Industry (Photogrammetry/SfM) — Monocular-guided sampling to reduce holes in reconstructions
- Product/workflow: Seed multi-view pipelines with uniform monocular point distributions to improve mesh completeness and thin structure recovery.
- Dependencies/assumptions: Tight coupling with SfM/MLP-based INRs; validation on diverse terrains/materials.
- Healthcare (Endoscopy/Minimally Invasive Imaging) — Monocular depth for scene understanding
- Product/workflow: Apply continuous depth fields to endoscopic imaging to improve navigation and lesion mapping.
- Dependencies/assumptions: Domain-specific training; safety; instrument calibration and optics modeling; real-time constraints.
- Remote Sensing (Aerial/Satellite) — Monocular depth for topography estimation
- Product/workflow: Extend implicit depth fields to orthorectified imagery with camera models for coarse topography and structure-from-motion initialization.
- Dependencies/assumptions: Accurate camera models; atmospheric effects; large-domain generalization.
- Disaster Response/Public Safety — Rapid 3D situational awareness from limited imagery
- Product/workflow: Use single-/few-image depth to generate actionable 3D views of damage sites where full sensor stacks are unavailable.
- Dependencies/assumptions: Robustness to severe domain shift; uncertainty quantification; operator-in-the-loop validation.
- Policy/Standards — Dataset governance and evaluation for high-resolution depth
- Product/workflow: Establish standards around reporting high-frequency detail metrics, scale-aware accuracy (δ thresholds), and domain shift performance (synthetic vs. real).
- Dependencies/assumptions: Multi-stakeholder consensus; benchmark curation and maintenance; clear privacy/data-use guidelines.
- Consumer (Mobile 3D Scanning) — Single-view 3D capture with sensor fusion
- Product/workflow: Fuse phone LiDAR/ToF with InfiniDepth metric prompts to produce high-detail 3D scans for DIY, home design, and collectibles.
- Dependencies/assumptions: Device hardware availability; efficient on-device inference; user guidance for capture.
Key Assumptions and Dependencies Across Applications
- Training data and domain shift: The model is trained exclusively on synthetic datasets; real-world robustness is good but may benefit from domain adaptation or fine-tuning on target domains.
- Camera intrinsics and calibration: Metric depth and NVS quality rely on accurate intrinsics and RGB–depth alignment when sparse depth is used.
- Temporal consistency: Current model is single-view; video applications may exhibit flicker without multi-view/temporal training.
- Computational cost: Arbitrary-resolution (e.g., 4K) queries are computationally intensive; mobile/edge deployment requires optimization and possibly model distillation.
- Pipeline integration: The infinite depth query strategy assumes differentiability (for normals) and integration with GS/NVS systems; careful engineering is needed for production.
- Safety and certification: Robotics/AD use cases demand rigorous validation, uncertainty estimation, and compliance with safety standards.
Glossary
- AdamW optimizer: A variant of Adam that decouples weight decay from the gradient update to improve generalization. "We train our model using the AdamW optimizer with a learning rate of ."
- Affine-invariant point maps: Geometry representations unchanged under affine transformations, helping robust supervision. "MoGe~\cite{wang2025moge} enhances geometric accuracy with affine-invariant point maps and optimal training supervision."
- Arbitrary-resolution: Capability to produce outputs at any desired resolution beyond training size. "we can query depth at continuous 2D coordinates, enabling arbitrary-resolution and fine-grained depth estimation."
- Back-projecting: Converting image-plane depth values into 3D coordinates using camera intrinsics. "Querying at these continuous coordinates and back-projecting to 3D yields a point cloud with approximately uniform surface coverage (Fig.~\ref{fig:sampling} (b))."
- Bilinear interpolation: A local interpolation method on grids using weighted averages of neighboring pixels. "query local features for the coordinate at each scale through bilinear interpolation."
- Conditional random fields (CRFs): Probabilistic graphical models that encode contextual dependencies for structured prediction. "represent the depth map as a graph-structured output with conditional random fields (CRFs)"
- Continuous 2D coordinates: Real-valued image-plane positions enabling resolution-agnostic querying. "we can query depth at continuous 2D coordinates, enabling arbitrary-resolution and fine-grained depth estimation."
- Convolutional upsampling: Increasing spatial resolution via convolutional layers, often causing smoothing. "predicting depth on entire grids requires either convolutional upsampling or linear projection from latents to depth patches."
- Depth completion approaches: Methods that infer full dense depth from partial or sparse measurements. "For metric depth estimation, we compare with depth completion approaches, including Marigold-DC~\cite{viola2025marigold}, Omni-DC~\cite{zuo2025omni}, PriorDA~\cite{wang2025depth}, and PromptDA~\cite{lin2025prompting}."
- Depth prompt module: A conditioning mechanism that integrates sparse depth cues into a model. "we incorporate sparse depth inputs using the depth prompt module proposed in~\cite{lin2025prompting}, referred to as Ours-Metric for clarity."
- Depth query strategy: A procedure for allocating continuous sampling points to achieve uniform surface coverage. "we design a depth query strategy that allocates sub-pixel query budgets proportionally to each pixel's corresponding 3D surface element"
- Differential surface area: Infinitesimal surface patch size used to weight sampling density. "derive an adaptive weight that estimates the differential surface area at each pixel location:"
- Differentiable nature: Property that outputs vary smoothly with inputs, enabling gradient-based geometric computations. "leveraging the differentiable nature of our implicit depth field (Fig.~\ref{fig:normal})"
- DINOv3 ViT-Large: A self-supervised Vision Transformer variant used as the image encoder. "We adopt the DINOv3~\cite{simeoni2025dinov3} ViT-Large model as our image encoder."
- Diffusion-based methods: Generative modeling approaches that learn data distributions via iterative denoising. "Diffusion-based methods~\cite{ke2024repurposing, xu2025pixel, he2024lotus, gui2025depthfm} model the distribution of depth maps"
- DPT decoder: A dense prediction transformer-based decoder for grid-based depth output. "predicts depth on discrete grids using a DPT decoder~\cite{ranftl2021vision}."
- Feed-forward NVS methods: Single-pass pipelines for rendering new viewpoints without iterative optimization. "recent feed-forward NVS methods~\cite{xu2025depthsplat, song2025adgaussian} predict pixel-aligned depth and Gaussian parameters."
- Feature pyramid: Multi-scale representation combining shallow and deep features for detail and semantics. "we construct a feature pyramid "
- Feature tokens: Patch-level embeddings produced by transformers for downstream decoding. "The input image is firstly encoded by a Vision Transformer to obtain a set of feature tokens."
- Gaussian Splatting (GS): A rendering technique that represents surfaces with anisotropic Gaussians for view synthesis. "we extend our depth model with a lightweight Gaussian Splatting (GS) head."
- Gaussian Splatting (GS) head: A prediction head that outputs Gaussian parameters for rendering. "we extend our depth model with a lightweight Gaussian Splatting (GS) head."
- High-frequency (HF) mask: A binary mask highlighting fine-detail regions based on local frequency content. "construct a binary high-frequency (HF) mask."
- Jacobian: Matrix of partial derivatives used to compute surface normals from coordinate changes. "computed from the Jacobian of with respect to continuous image coordinates"
- Laplacian energy map: A measure of local second-order variations used to locate high-frequency detail regions. "compute a multi-scale Laplacian energy map for each depth image"
- Metric depth estimation: Predicting depth with absolute scale consistent with real-world units. "To demonstrate that InfiniDepth is also effective for metric depth estimation, we incorporate sparse depth inputs"
- Multi-layer perceptron (MLP): A fully connected neural network used for function approximation. "where is typically implemented as a multi-layer perceptron (MLP)."
- Multi-scale local implicit decoder: A decoder that queries and fuses local features across scales to predict continuous depth. "We instantiate in Eq.~\ref{eq:depth-nif} as a multi-scale local implicit decoder"
- Neural implicit fields: Functions parameterized by neural networks that map continuous coordinates to signals. "represents depth as neural implicit fields."
- Novel view synthesis (NVS): Generating images from new camera viewpoints given limited observations. "Another benefit of InfiniDepth is its ability to enhance novel view synthesis (NVS) quality under large viewpoint shifts."
- Perspective projection: The mapping from 3D to 2D where apparent size scales inversely with depth. "produces a surface point cloud with strong density imbalance due to perspective projection and surface orientation"
- Pixel-aligned depth: Depth predictions aligned with image pixels rather than continuous coordinates. "recent feed-forward NVS methods~\cite{xu2025depthsplat, song2025adgaussian} predict pixel-aligned depth and Gaussian parameters."
- Point cloud: A set of 3D points representing surfaces reconstructed from depth. "Unprojecting a discrete per-pixel depth map produces a surface point cloud with strong density imbalance"
- Reassemble block: A transformer-based module that aggregates multi-layer tokens into multi-scale features. "we design a reassemble block which extracts feature tokens from multiple ViT layers and projects them to different hidden dimensions."
- Relative depth estimation: Predicting depth up to a scale factor without absolute units. "Relative depth estimation aims to infer a normalized depth map without absolute scale."
- Residual gated fusion block: A feature fusion module using residual connections and learnable gates. "using a residual gated fusion block:"
- Sparse depth inputs: Limited depth samples used to guide or complete dense depth prediction. "while others~\cite{liu2024depthlab, wang2025depth, zuo2025omni, viola2025marigold, lin2025prompting} leverage sparse depth as additional inputs to improve accuracy."
- Sub-pixel query: Sampling multiple continuous points within a pixel to improve spatial uniformity. "Infinite Depth Query applies sub-pixel query with adaptive weights to generate uniformly distributed point clouds."
- Surface normal: A unit vector perpendicular to a local surface used for orientation and shading. " is the surface normal,"
- Surface orientation effect: Variation in apparent area due to the angle between the surface and view direction. "surface orientation effect—when the surface normal deviates from the viewing direction, its projection onto the image is compressed"
- Synth4K: A curated 4K synthetic RGB-D benchmark for high-resolution depth evaluation. "we curate Synth4K, a high-quality benchmark for evaluating depth estimation methods at high resolution and fine geometric details."
- Torch autograd: PyTorch’s automatic differentiation engine used to compute gradients and geometric quantities. "Normal map from implicit fields through torch autograd, indicating high-quality internal geometry of our model."
- Unprojecting: Converting per-pixel depth back to 3D points using camera geometry. "Unprojecting a discrete per-pixel depth map produces a surface point cloud with strong density imbalance"
- Upsampling: Increasing the spatial resolution of feature maps or predictions. "The feature maps from layers 4 and 11 are then upsampled by factors of 4 and 2, respectively."
- Vision Transformer (ViT): A transformer-based architecture for image representation using patch tokens. "Relative depth estimation aims to infer a normalized depth map without absolute scale. Recent works~\cite{ranftl2021vision, yang2024depth,yang2024depth2, wang2025moge} adopt Vision Transformer (ViT) backbones~\cite{dosovitskiy2020image} with convolutional decoders to regress 2D discretized depth maps."
- Viewing direction: A unit vector from the camera toward the 3D point, used in orientation calculations. " represents the unit viewing direction,"
Collections
Sign up for free to add this paper to one or more collections.