In-Context Reinforcement Learning through Bayesian Fusion of Context and Value Prior
Published 6 Jan 2026 in cs.LG and cs.AI | (2601.03015v1)
Abstract: In-context reinforcement learning (ICRL) promises fast adaptation to unseen environments without parameter updates, but current methods either cannot improve beyond the training distribution or require near-optimal data, limiting practical adoption. We introduce SPICE, a Bayesian ICRL method that learns a prior over Q-values via deep ensemble and updates this prior at test-time using in-context information through Bayesian updates. To recover from poor priors resulting from training on sub-optimal data, our online inference follows an Upper-Confidence Bound rule that favours exploration and adaptation. We prove that SPICE achieves regret-optimal behaviour in both stochastic bandits and finite-horizon MDPs, even when pretrained only on suboptimal trajectories. We validate these findings empirically across bandit and control benchmarks. SPICE achieves near-optimal decisions on unseen tasks, substantially reduces regret compared to prior ICRL and meta-RL approaches while rapidly adapting to unseen tasks and remaining robust under distribution shift.
The paper introduces SPICE, a Bayesian ICRL method that fuses calibrated value priors with context evidence for efficient policy adaptation.
It employs a value ensemble with diverse priors and a posterior-UCB rule, achieving logarithmic regret in bandits and minimax-optimal regret in MDPs.
Empirical evaluations in both bandit tasks and gridworld MDPs demonstrate robust performance even when starting from suboptimal pretraining data.
In-Context Reinforcement Learning via Bayesian Fusion of Context and Value Priors: Analysis of SPICE
Introduction and Motivation
This work investigates the problem of in-context reinforcement learning (ICRL), where policies must adapt to new environments purely via context, without parameter or gradient updates. ICRL is appealing in domains where online training is risky or impractical, as it leverages diverse historical trajectories for fast adaptation in sequence models, especially transformers.
The authors address critical shortcomings prevalent in prior ICRL algorithms: (1) behavior-policy bias, which arises from supervised training on suboptimal data, causing poor out-of-distribution generalization and inability to surpass the data-generating policy; (2) lack of actionable, calibrated uncertainty, hindering principled exploration; and (3) strong dependence on optimal labels or learning traces, which is unrealistic for most practical deployments.
The core contribution is the SPICE (Shaping Policies In-Context with Ensemble prior) algorithm, which introduces a strictly Bayesian approach to ICRL that (i) learns a value prior with calibrated epistemic uncertainty from suboptimal data, (ii) performs test-time Bayesian fusion of the value prior with context-driven evidence, and (iii) deploys a posterior-UCB action selection rule, enabling efficient in-context adaptation and provable regret guarantees—even with weak pretraining data.
Methodology
SPICE integrates three principal technical innovations for ICRL:
Value Ensemble Prior: The architecture supplements a transformer sequence encoder (GPT-2 variant) with an ensemble of K value heads, each initialized with a randomized prior and anchored for diversity. The ensemble mean and variance at the query state constitute a calibrated Gaussian value prior for each action.
Representation Shaping: During pretraining, SPICE employs a policy head used solely as a shaping mechanism. Supervision is weighted by a combination of importance correction (to mitigate behavior-policy mismatch), advantage weighting (to upweight high-advantage transitions), and epistemic weighting (to emphasize uncertain regions as measured by value head disagreement). The weighted objective facilitates de-biasing the learned representation, producing features suitable for accurate value estimation from suboptimal datasets.
Test-Time Bayesian Fusion: At evaluation, SPICE performs closed-form Bayesian updates at the query state. Context transitions are aggregated using a kernel function applied to the latent representations (not raw states), producing state-weighted sufficient statistics. These are fused with the value prior via Normal-Normal conjugacy to yield a per-action posterior (mean and variance). For online adaptation, SPICE applies a posterior-UCB rule with an exploration parameter, ensuring directed exploration driven by residual epistemic uncertainty. Greedy selection is used for offline decision-making.
Theoretical Analysis
A central theoretical result is that SPICE achieves logarithmic regret in stochastic bandits and O(HSAK) minimax-optimal regret in finite-horizon MDPs, regardless of the quality of the pretraining data. Regret decomposition demonstrates that any bias or miscalibration in the value prior contributes solely to a constant warm-start term in the total regret, which does not impact the asymptotic rate. Thus, even pretraining on highly suboptimal or random data allows SPICE to rapidly converge to optimal policies, as its posterior uncovers and corrects prior inaccuracies via accumulated context evidence.
Empirical Evaluation
Bandit Setting
SPICE is evaluated against recent ICRL (DPT, ICEE, DIT), classical meta-RL, and bandit baselines on standard stochastic bandit tasks with weak and mixed-optimal pretraining. Trajectories for training are intentionally generated by random or poor policies to stress-test the adaptation capabilities of each method.
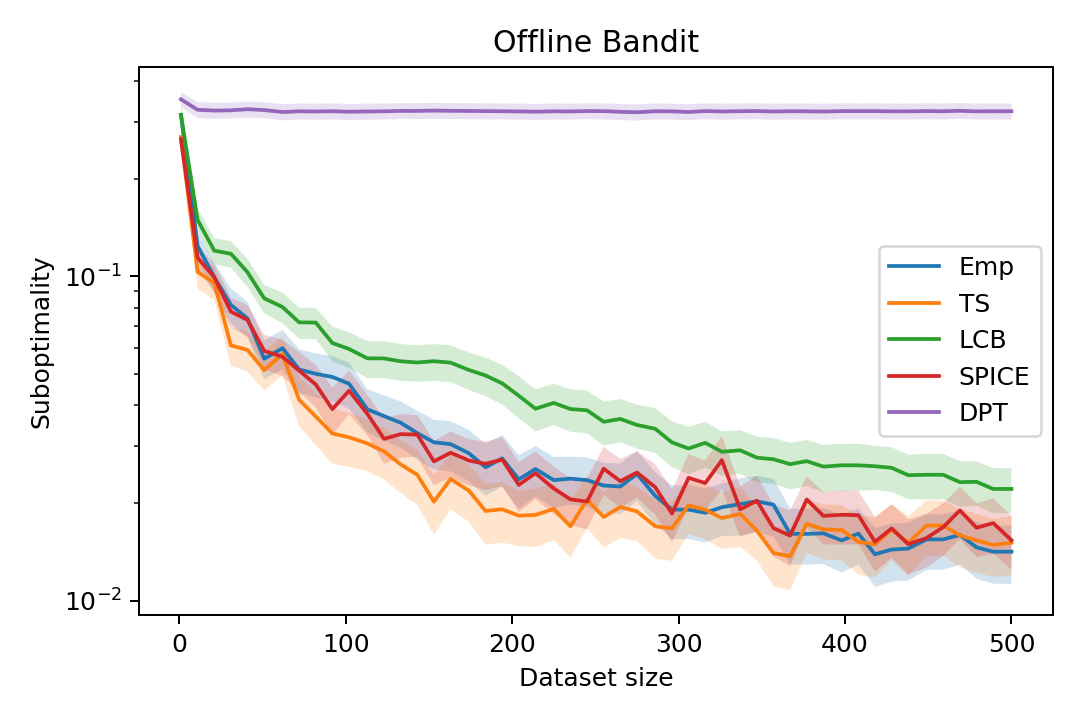
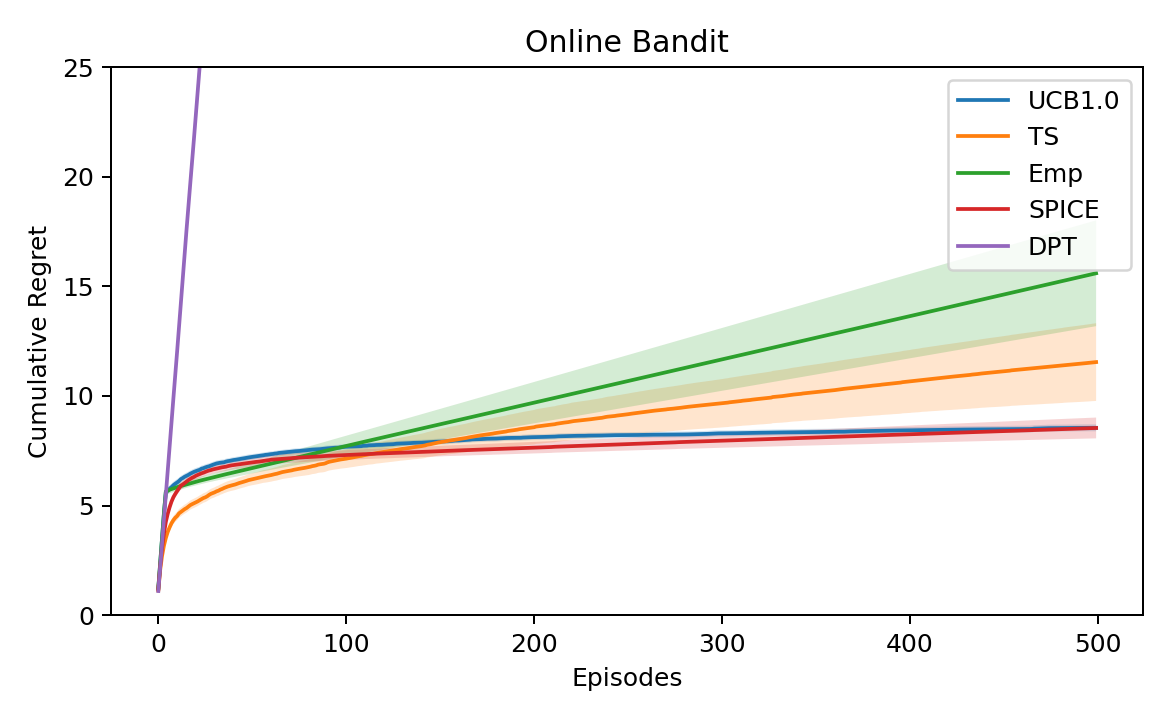
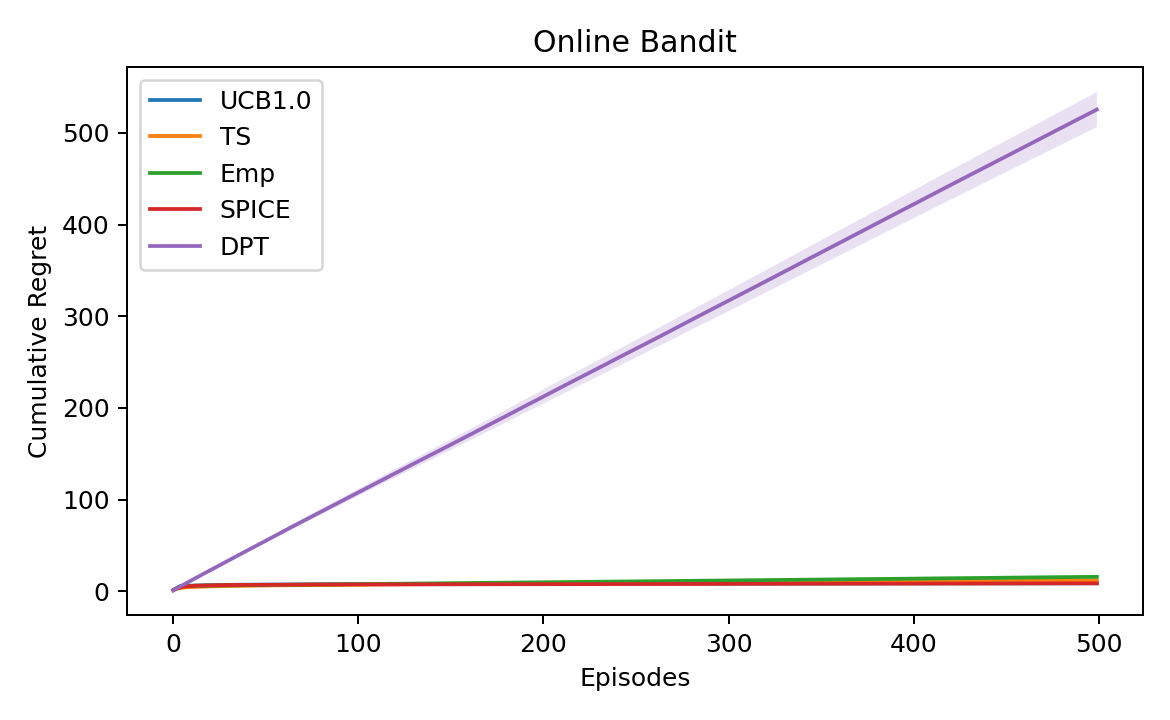
Across all context lengths, SPICE achieves near-optimal offline selection and closely tracks UCB and Thompson Sampling in online regret, whereas behavior cloning-based methods exhibit high, often linear regret and cannot adapt beyond the support of their pretraining distribution.
Figure 1: Offline suboptimality as a function of context window; lower suboptimality for SPICE across all context sizes demonstrates robust exploitation of limited context information.
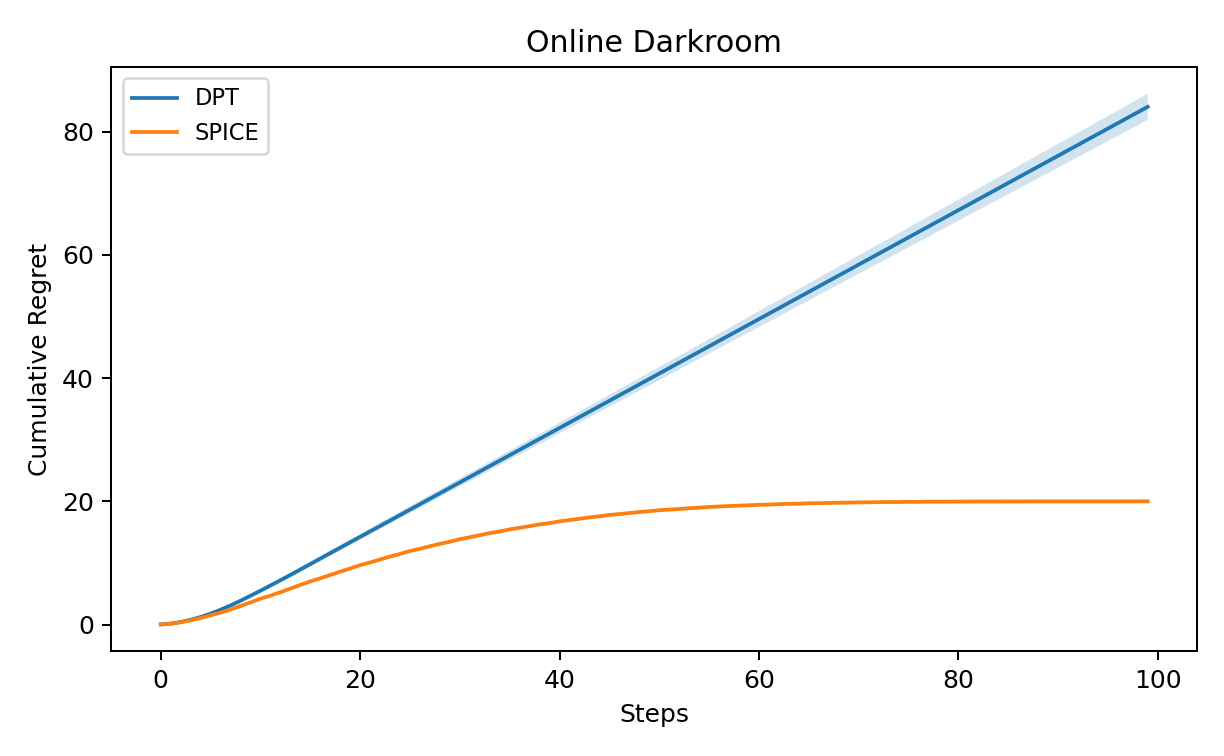
Figure 2: Online cumulative regret over H—SPICE rapidly attains the lowest regret among learned baselines and tracks UCB, underscoring efficient in-context exploration and learning from poor priors.
Robustness experiments with increasing reward noise indicate that SPICE, UCB, and TS degrade gracefully, while supervised sequence models fail to adapt, demonstrating the necessity of Bayesian evidence fusion for high-noise, offline, or misspecified domains.
MDP Setting
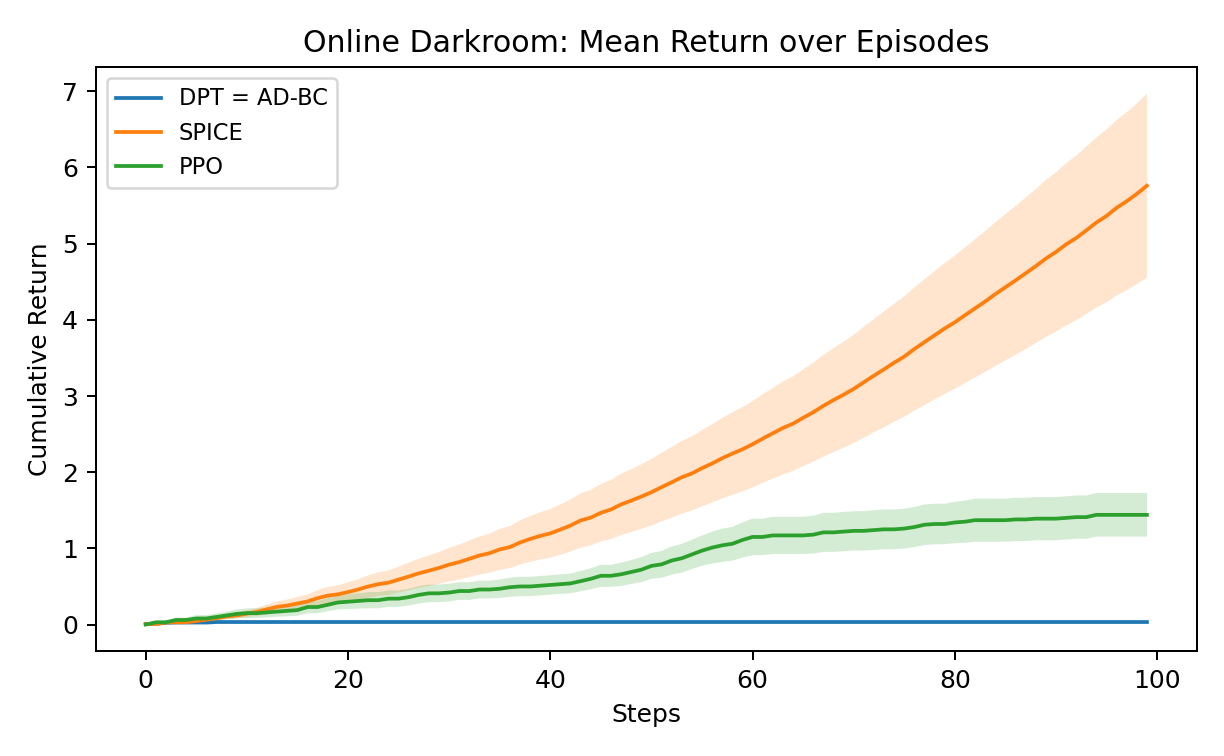
The Darkroom environment (10x10 gridworld, sparse reward, suboptimal supervision) tests ICRL adaptability under severe distribution shift. SPICE is the only method to achieve substantial online gain after only a few episodes; sequence-only models fail due to entrenchment in behavior cloning-induced policy bias.
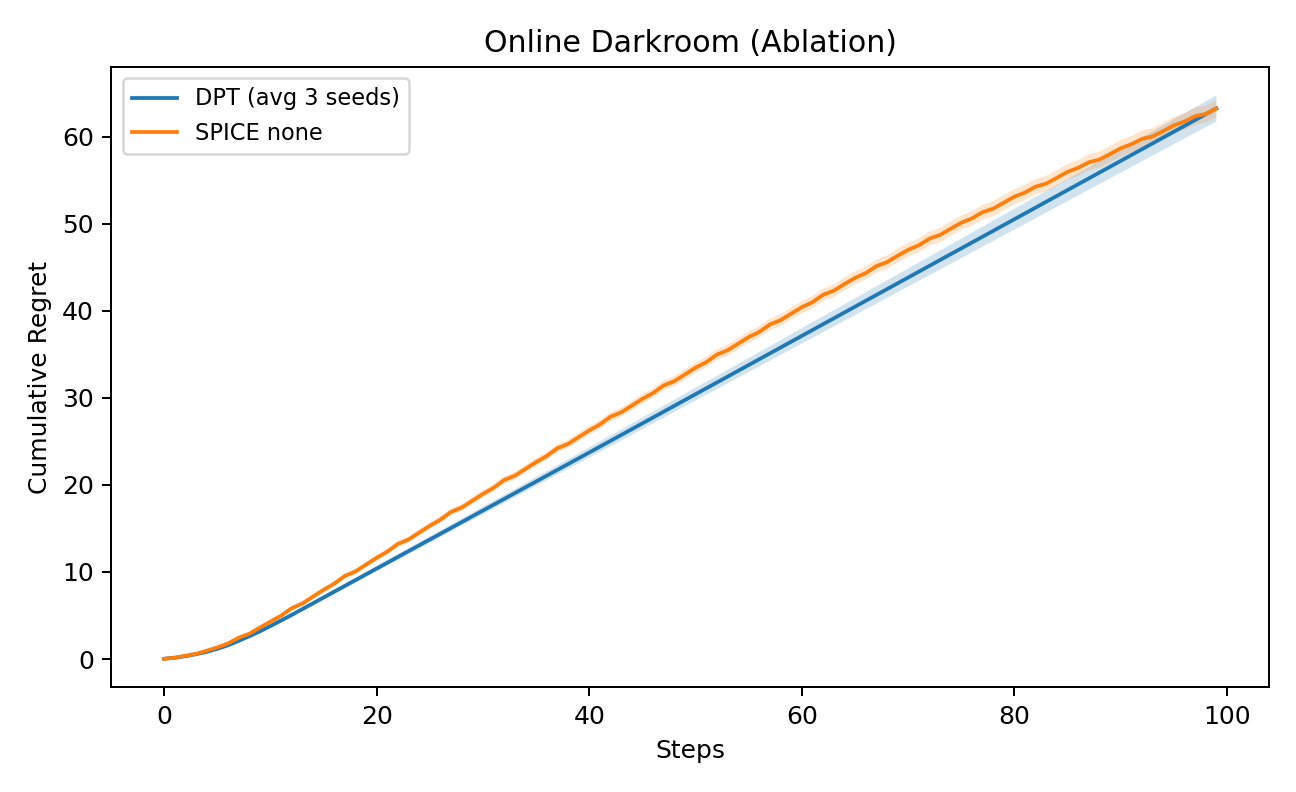
Figure 3: Ablation on the contribution of SPICE's weighting terms during training—omitting these terms significantly increases regret, particularly disadvantageous under weak supervision.
These results illuminate the criticality of explicitly calibrated value uncertainty and inference-driven adaptation in ICRL. SPICE's value ensemble and Bayesian controller provide a strong structural prior which is quickly overridden as task-specific evidence is accrued, enabling adaptation even far from pre-training support.
Practical and Theoretical Implications
SPICE advances ICRL toward realistic deployments where optimal demonstrations or extensive online fine-tuning are impractical, e.g., robotics, autonomous systems, and resource management. By avoiding reliance on strong supervision, it supports knowledge transfer from weak or heterogeneous logs, and gracefully shifts from prior-driven to evidence-driven behavior.
Theoretically, SPICE provides a template for incorporating Bayesian uncertainty quantification and efficient exploration directly at test-time, decoupling the representation and inference roles during pretraining. The use of per-action posteriors paves the way for combining powerful sequence models with sample-efficient bandit-style controllers in multi-task and continual RL.
Future Directions
While SPICE shows strong empirical and theoretical properties, future research could address its extension to high-dimensional continuous control (via kernelized or parametric context fusion in action space), real-world deployment with non-i.i.d. logs, and more sophisticated priors incorporating domain knowledge or hierarchical structure. Additionally, automated kernel/bandwidth selection for context-based evidence aggregation and improved calibration under heavy-tailed or multimodal uncertainty remain open technical challenges.
Conclusion
SPICE introduces a principled Bayesian inference approach to in-context RL, enabling adaptation from arbitrary pretraining data by fusing value priors with context evidence and leveraging uncertainty for efficient exploration. This method achieves optimal or near-optimal regret rates in both stochastic bandits and MDPs, rendering behavior-policy bias and lack of uncertainty quantification—long-standing obstacles in ICRL—effectively obsolete. The framework provides a solid foundation for further advances in scalable, reliable, and deployable RL systems.