- The paper introduces an information-theoretic framework to quantify and exploit layer redundancy in hypergraphs, achieving systematic data compression.
- The methodology employs exact and greedy algorithms to optimize representative hyperedge selection, balancing computational cost with accuracy.
- Empirical evaluations on synthetic and real-world datasets demonstrate that the reduced hypergraphs preserve global connectivity and key dynamical behaviors.
Introduction and Motivation
Higher-order network representations, particularly hypergraphs, provide a powerful means to encode complex relational data that go beyond simple, dyadic connections. While these models are instrumental in accurately modeling collective phenomena—ranging from contagion and synchronization to evolutionary dynamics—their inherent high dimensionality exacerbates interpretability challenges and computational cost. This paper introduces an information-theoretic framework to rigorously quantify and exploit redundancy within hypergraph representations, thereby enabling systematic reduction without sacrificing essential higher-order structure (2601.02603).
The approach formalizes a hypergraph G as a collection of layers, each G(ℓ) containing all hyperedges of size ℓ. Structural reducibility emerges from the observation that lower-order hyperedges may be nested within higher-order ones, and thus, information about some layers may be partially or fully redundant given others.
Given the minimal bit cost H0 for naїvely transmitting all layers and an optimal representative set R∗, the reducibility of G is defined as:
η=H0−HℓmaxH0−HG(R∗)
where HG(R) is the information content for transmitting G using R as representatives, and Hℓmax is the trivial lower bound (transmitting only the highest order layer). This normalization ensures η∈[0,1].
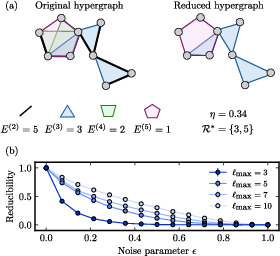
Figure 1: Schematic illustration of layer redundancy and the corresponding compression into optimal representative layers for a toy hypergraph.
Maximal compressibility (η=1) occurs for perfectly nested hypergraphs, whereas η≈0 for hypergraphs with negligible structural overlap across layers.
Algorithmic Framework and Computational Considerations
The method requires optimal identification of R∗, which can be solved exactly for most real datasets (L≲30 layers) via exhaustive search. For larger L, an efficient greedy approximation is shown to yield close-to-optimal results with dramatically reduced computational cost.
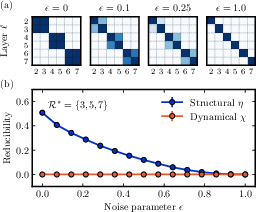
Figure 2: Comparison between structural and dynamical reducibility: the proposed structural measure uncovers planted redundancies and representative layers, in contrast to functional/dynamical approaches.
The stepwise calculation involves:
- Projecting higher-order hyperedges to lower orders to assess overlap and redundancy.
- Constructing and minimizing the total information cost matrix across all valid combinations of representatives.
- For very high-dimensional systems, greedily building up R while preserving compression guarantees.
Empirical results demonstrate that the greedy algorithm matches the exact method's output across both synthetic and real-world hypergraphs, while providing substantial runtime advantages, confirming scalability.
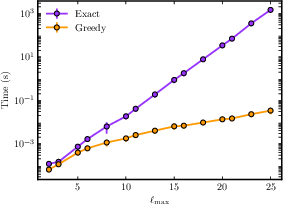
Figure 4: Runtime scaling with the number of layers for computing reducibility, demonstrating the exact vs. greedy optimization algorithms.
Evaluation on Synthetic and Empirical Systems
Synthetic benchmarks with tunable nestedness and controlled noise confirm the measure's rigorous interpolation between complete reducibility (η→1 for noise-free nested systems) and incompressibility (η→0 as stochastic rewiring increases). The method precisely recovers the planted optimal set of representatives in the generative process and quantifies the loss of redundancy as noise disrupts nestedness.

Figure 6: Structural reducibility η and pairwise layer similarities for synthetic hypergraphs under varying noise models and generative nestedness.
Empirical analyses span multiple domains—co-authorship, contact, recipe, email, and tagging hypergraphs. A variety of compressibility patterns emerge: some systems (e.g., contact/interaction datasets) exhibit strong redundancy, with optimal representations involving only a small subset of the total layers; others (e.g., scientific collaboration graphs) are more structurally unique at each scale.

Figure 5: Layer similarity matrices for empirical hypergraphs revealing nested architecture, which underlies observed reducibility.
The study also extends to a multiscale reducibility concept, wherein hypergraphs are coarse-grained according to node partitions (e.g., communities, metadata groupings) and compressibility is assessed at the mesoscale. Results confirm that reducibility is sensitive to the degree of alignment between network structure and partition metadata.
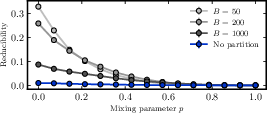
Figure 7: Multiscale reducibility as a function of community partition mixing; compressibility decreases as mesoscale structure weakens.
Preservation of Structural and Dynamical Properties
Reduced hypergraph representations, as constructed by this framework, preserve global connectivity, mesoscale features, and degree rank orderings except in degenerate cases with extremely low redundancy. Notably, voter model consensus times remain consistent between the original and reduced graphs, indicating preservation of essential dynamical behavior.
Theoretical Insights and Practical Implications
This research distinguishes structural from dynamical (functional) reducibility, demonstrating that the latter often fails to capture subtle topological compressibility, especially when collective behavior remains invariant under structural changes. The information-theoretic approach provides a principled method both for network compression and for dissecting the organizational principles governing higher-order interactions.
Practically, these results facilitate:
- Reduced memory/storage and computational costs for analysis or simulation of large-scale higher-order datasets.
- Interpretability: focusing attention on irreducible higher-order structures central to the system's function.
- Extensions to multiscale, temporal, directed, and weighted hypergraphs, increasing applicability in biological, social, and information systems.
Future Directions
Potential avenues include efficient algorithms for representative hyperedge selection beyond layer-wise reduction, direct characterizations of local redundancy, and integration with statistical inference tasks (e.g., community detection, dynamics prediction) in compressed spaces. Furthermore, applying this framework to temporal or multiplex hypergraphs may reveal new insights into the evolution and stability of redundancy in dynamic systems.
Conclusion
This work establishes a rigorous and efficient formalism for measuring and exploiting structural redundancy in hypergraph models. The provided framework supports substantial compression of higher-order data without sacrificing fidelity in essential structure or dynamics. By distinguishing informational redundancy from functional behavior, it opens directions for both theory and applications in the study and engineering of complex systems.

