- The paper introduces a configurable, automated pipeline that harmonizes heterogeneous EO, climate, soil, and terrain data, enabling reproducible and scalable crop yield prediction.
- Key methodology includes dynamic feature mapping, multi-source automated retrieval, and robust cross-family imputation validated on a real-world rice yield dataset achieving R² > 0.65.
- Implications highlight that data-centric engineering can match advanced ML architectures, fostering rapid prototyping, transfer learning, and operational scalability in agricultural analytics.
UniCrop: A Universal Pipeline for Scalable, Multi-Source Crop Yield Prediction
Motivation and Problem Statement
Despite advances in Earth observation (EO), climate reanalysis, and agricultural ML, crop yield prediction workflows remain impeded by dataset heterogeneity, inconsistent harmonisation practices, and ad hoc pipeline engineering. Most operational and research pipelines are narrowly scoped to specific crops, regions, or satellite products, impeding generalisability and reproducibility. UniCrop addresses the core bottleneck in operational and research deployment—rapid and robust engineering of high-quality multi-modal predictors from heterogeneous EO, climate, soil, and terrain datasets—by abstracting data specification into a configuration interface and delivering an automated, extensible, and transparent pipeline.
UniCrop Pipeline Design
The UniCrop architecture embodies a modular, data-centric paradigm composed of five primary stages: feature specification, data acquisition, harmonisation, engineered variable construction, and model-ready feature reduction. The configurable mapping file decouples human data requirements from technical implementation, enabling portability and reproducibility across crops, regions, and timeframes. Automated fetch plans execute multi-source queries (Sentinel-1/2, MODIS, ERA5-Land, NASA POWER, SoilGrids, SRTM) for any spatial-temporal window, yielding unified tables primed for downstream ML.
Key technical steps include:
- Dynamic feature mapping via CSV configuration, tracking APIs, sources, and derivation logic.
- Automated, context-aware retrieval leveraging Google Earth Engine (GEE) and public APIs.
- Harmonisation with strict ISO timestamping, provenance manifesting, and type/casting/collinearity checks.
- Cross-family imputation and robust scaling within each CV fold.
- Crop-agnostic engineered variables: GDD, NDVI/EVI dynamics, SAR statistics, topographic/soil–climate interactions.
- Minimum Redundancy Maximum Relevance (mRMR) filter with family-preservation for compact, diverse predictors.
This approach eliminates the need for substantial domain-specific scripting and supports transparent benchmarking and transfer learning tasks.
Case Study: Rice Yield Prediction
Study Design and Data Context
Validation of UniCrop was executed using a 557-field rice yield dataset with geolocated parcels from climatically varied districts. The dataset exhibited both significant spatial heterogeneity and substantial intra-seasonal missingness in specific feature families due to monsoon-driven cloud cover.
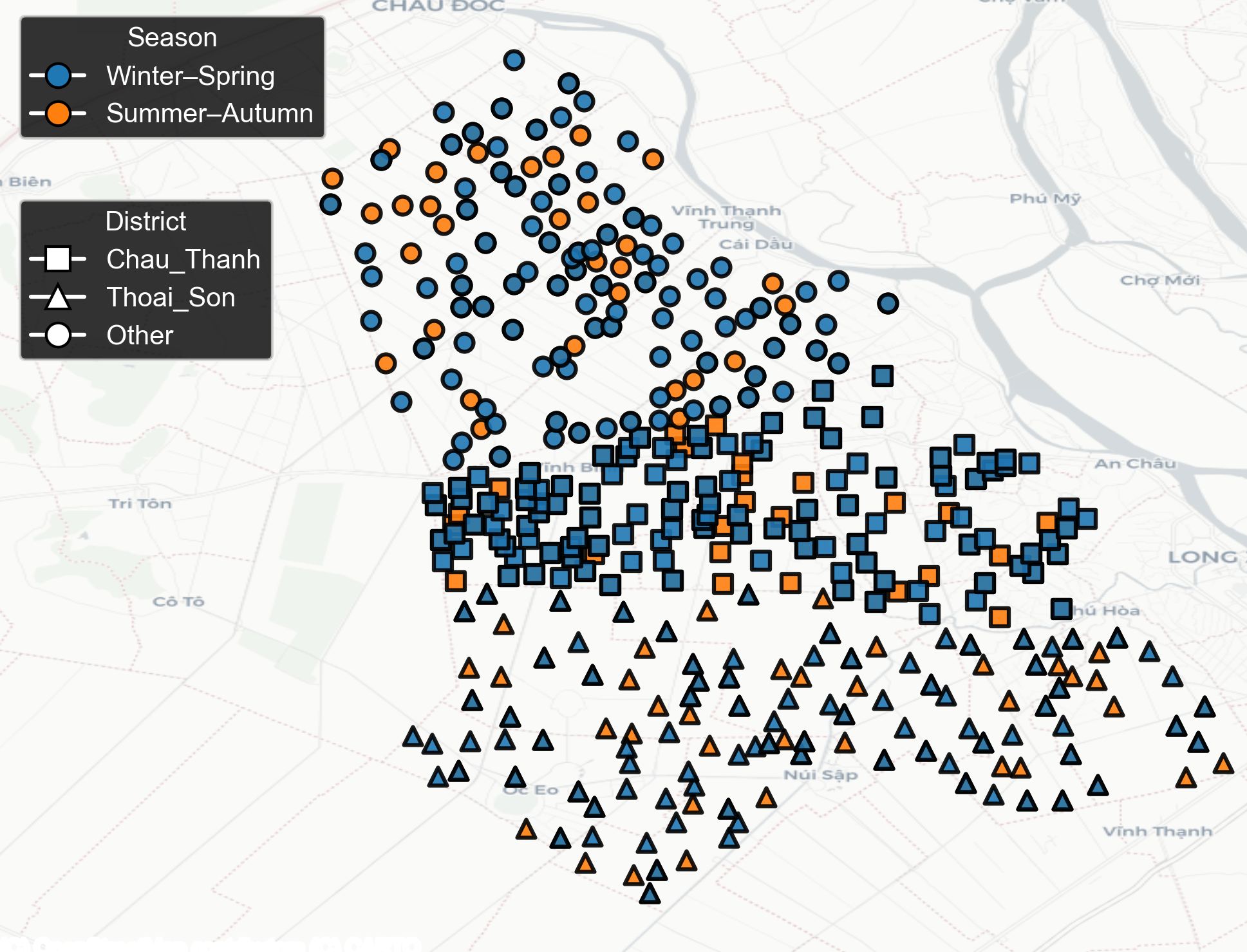
Figure 2: Spatial distribution of field parcels included in the case study, colour-coded by growing season.
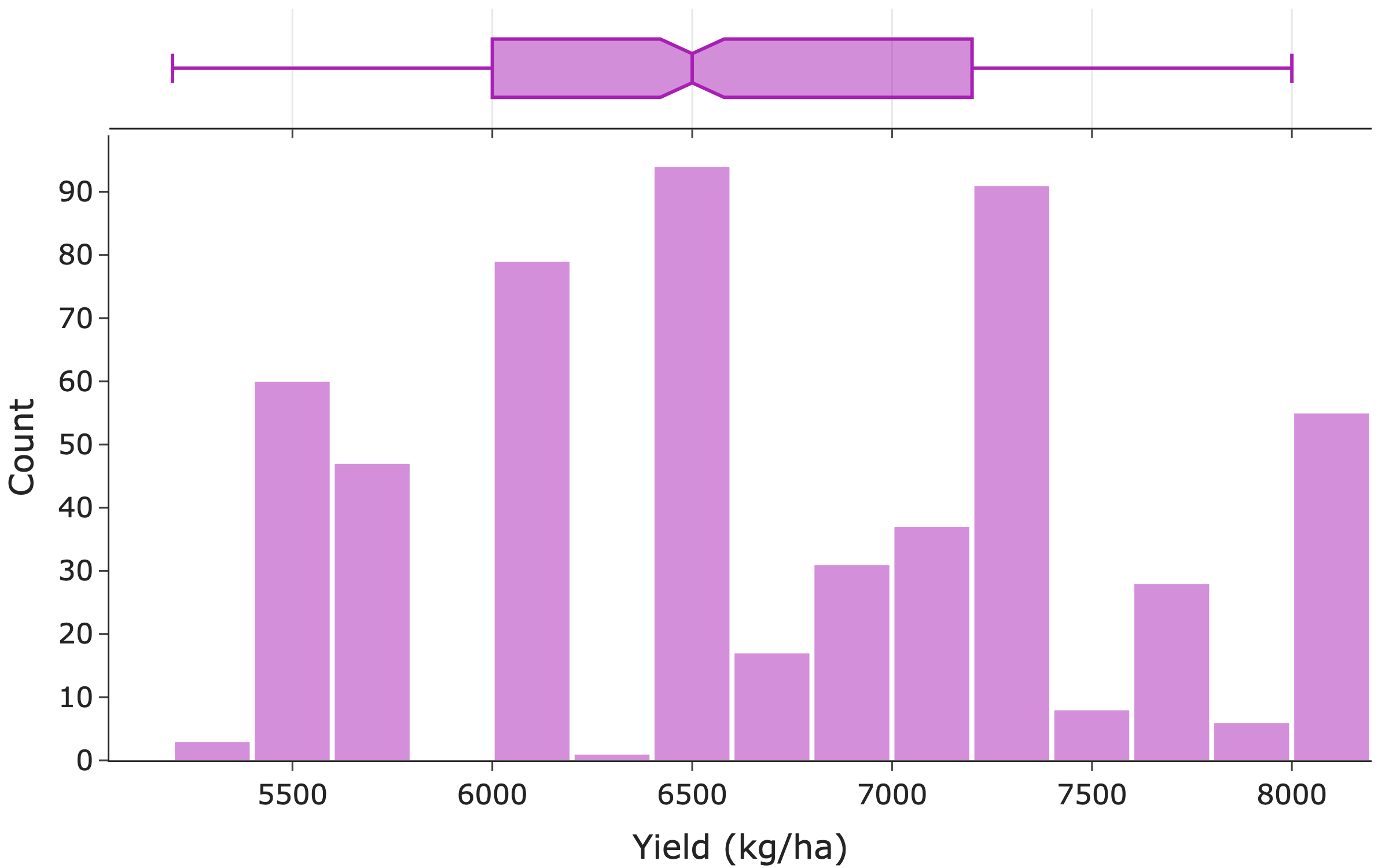
Figure 4: Distribution of rice yield (kg/ha).
Multi-Source Feature Integration and Reduction
The automated pipeline generated ~160 master features per instance, spanning meteorology, multispectral, radar, vegetation index, soil, and terrain domains. Family-specific imputation and cross-validation protocol preserved data integrity and avoided leakage. High missingness in vegetation indices for the summer-autumn season, correlated with cloud contamination, was adequately addressed by the contextual preprocessing strategy.
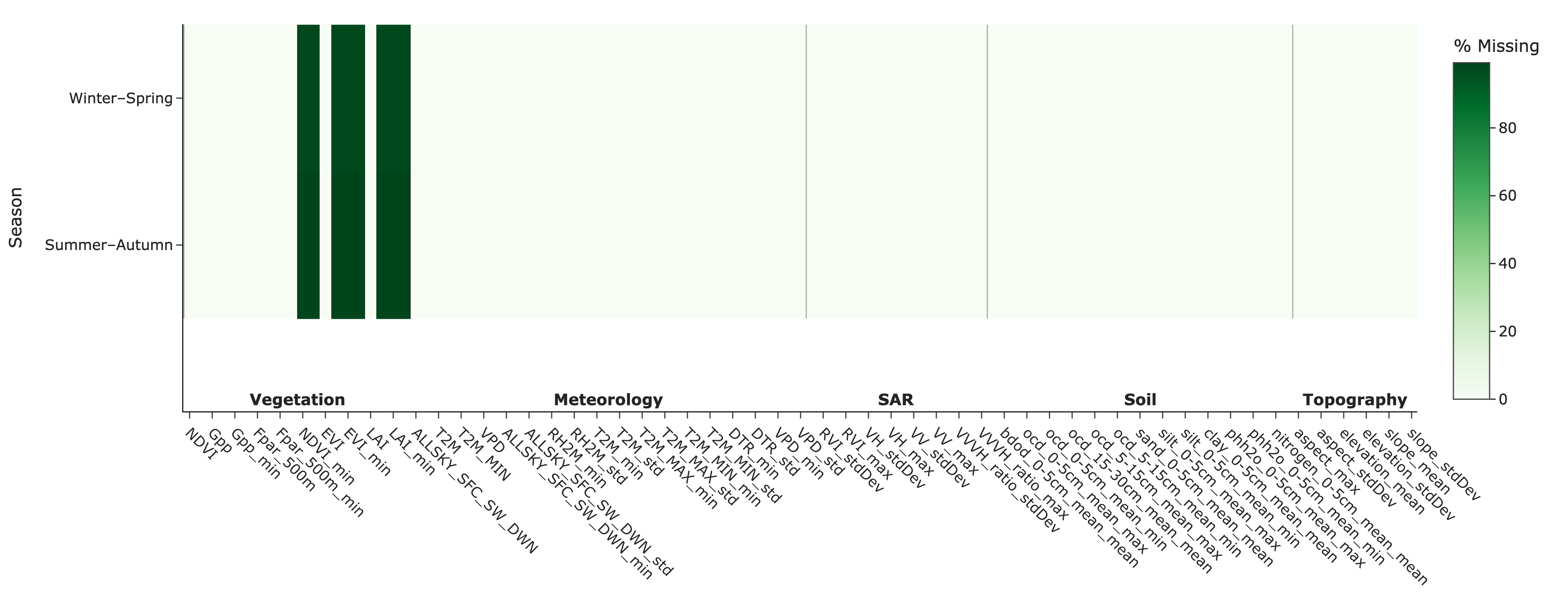
Figure 1: Seasonal missingness patterns for vegetation indices.
Feature reduction applied sequential variance filtering, redundancy pruning (r≥0.98), and mutual information ranking per fold, followed by mRMR with a family-preservation constraint. The resulting 15-feature subset preserved representation across all environmental families, with the top predictors spanning meteorological, spectral, radar, soil, and topographic modalities.
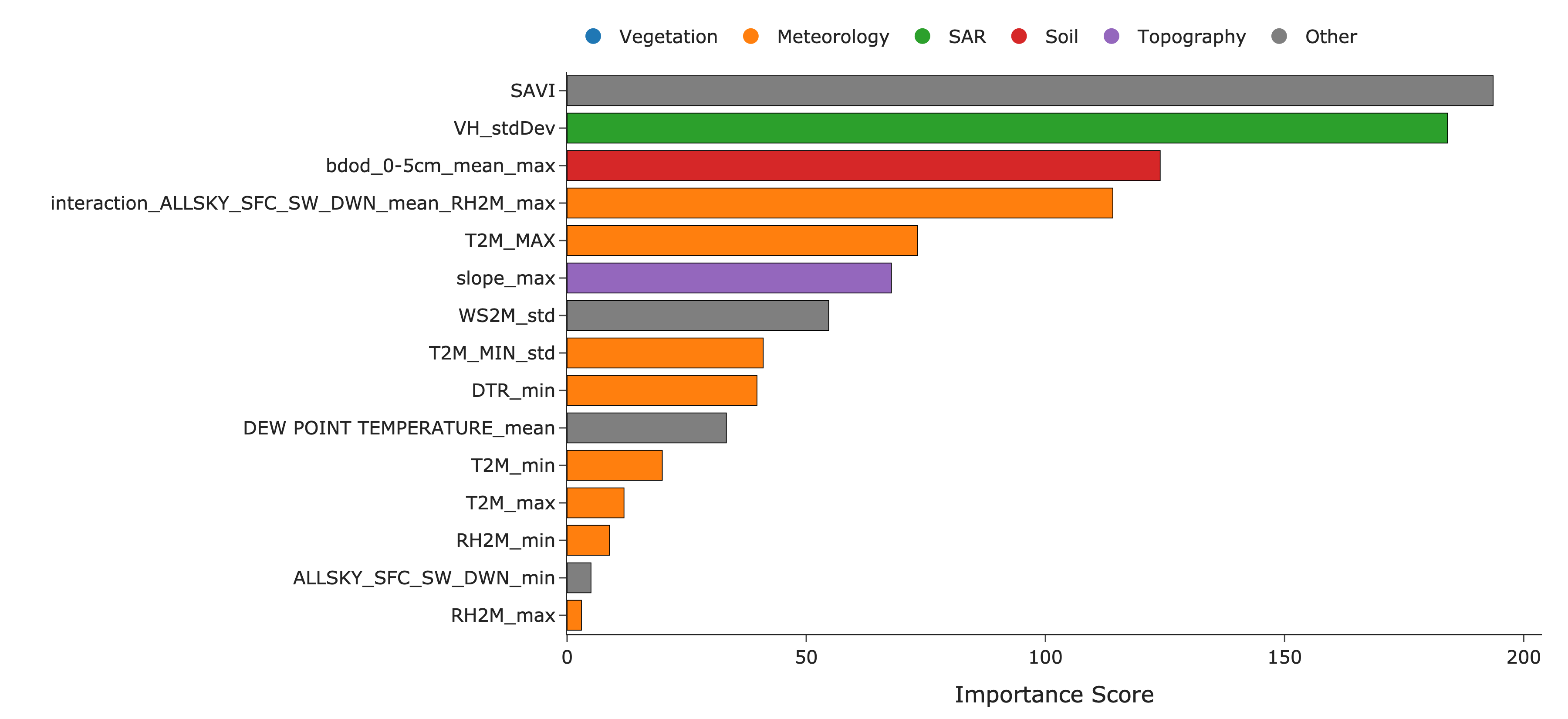
Figure 3: Top 15 predictors selected by the mRMR process. Bars are colour-coded by variable family (meteorology, vegetation, SAR, soil, topography).
Model Training, Results, and Diagnostics
LightGBM, Random Forest, SVR, and ElasticNet models were trained independently in 5-fold CV, with all preprocessing and feature selection performed within training folds to preclude leakage. Ensemble predictions were computed by a constrained non-negative least squares solution over base model OOF predictions.
Notable quantitative results:
- Best single-model (LightGBM) RMSE: 465.1 kg/ha; R2=0.6576
- Constrained ensemble: RMSE = 463.2 kg/ha; R2=0.6604
- Minimal performance difference between LightGBM and ElasticNet baselines, substantiating the pipeline's ability to generate linearly informative predictors from multi-modal data.
Prediction vs observation plots exhibit near-linear alignment, and residuals are well-centred with no evident heteroskedasticity, supporting model well-specification.
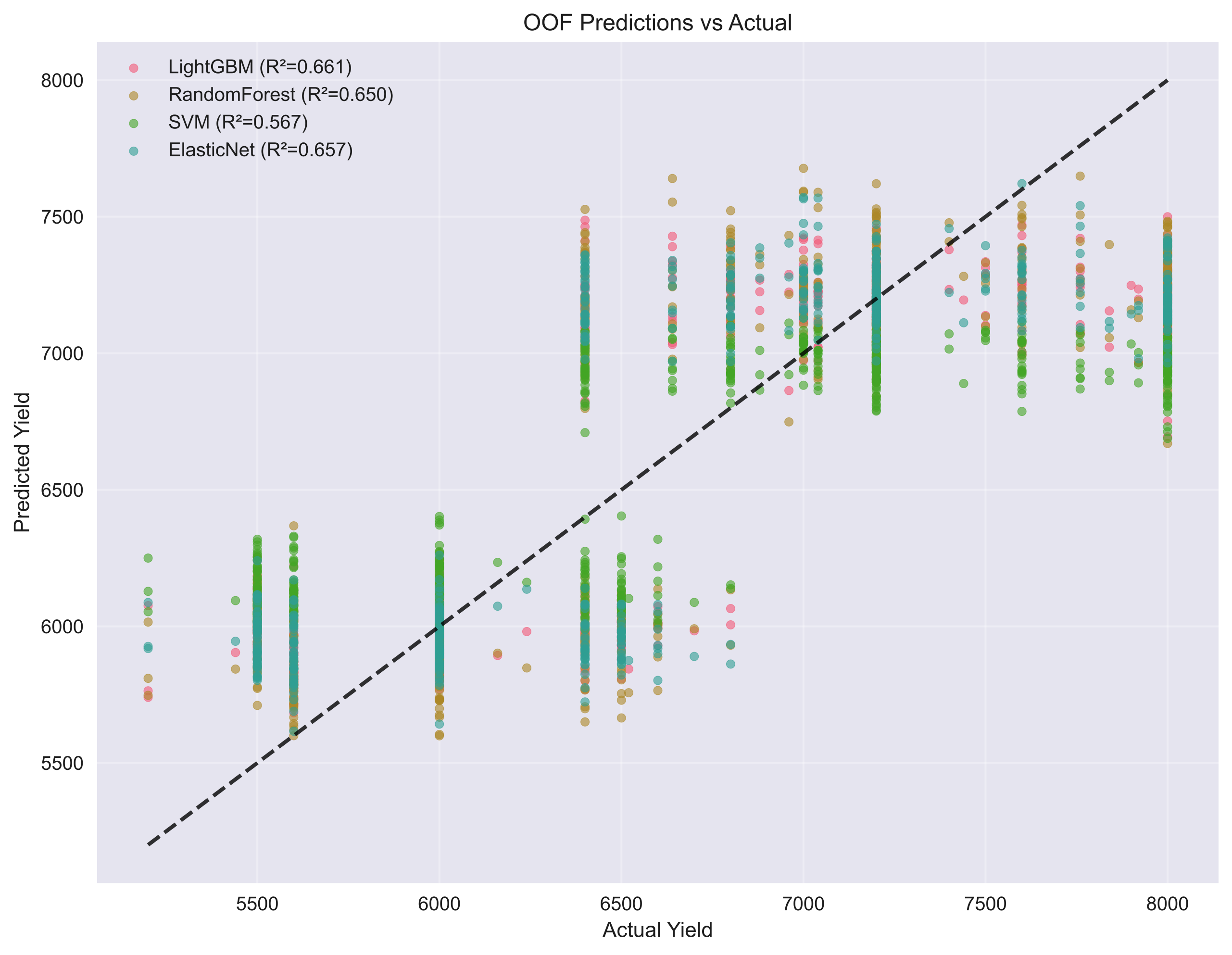
Figure 5: Out-of-fold predictions vs. observed yields.
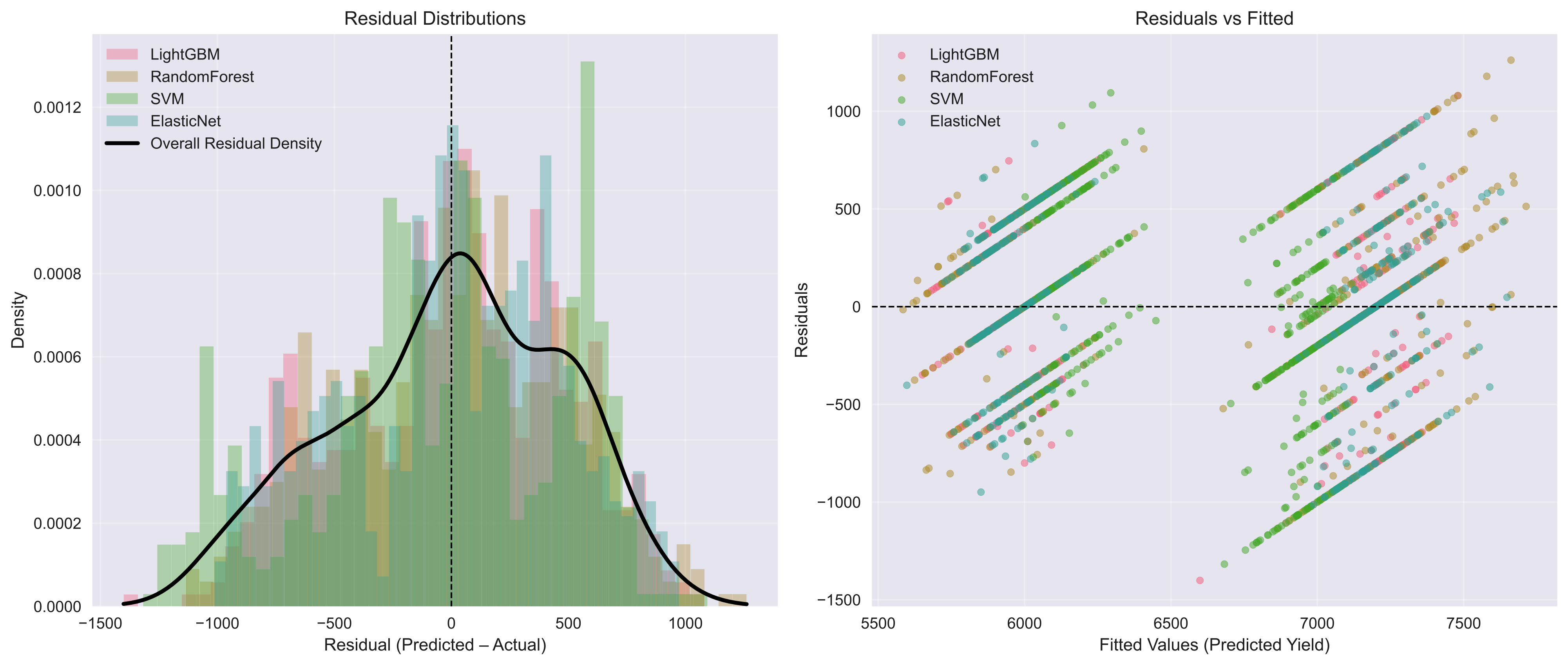
Figure 6: Residual distributions and residuals vs. fitted values for the LightGBM model.
Interpretability and Agronomic Plausibility
SHAP importances computed for LightGBM reveal that the most influential predictors are meteorological (e.g., maximum RH2M), SAR-derived canopy texture, seasonally stable temperature metrics, vegetation indices, and soil context. These patterns align with established mechanistic drivers of rice yield, substantiating that the pipeline-driven predictors encapsulate agriculturally meaningful signals.
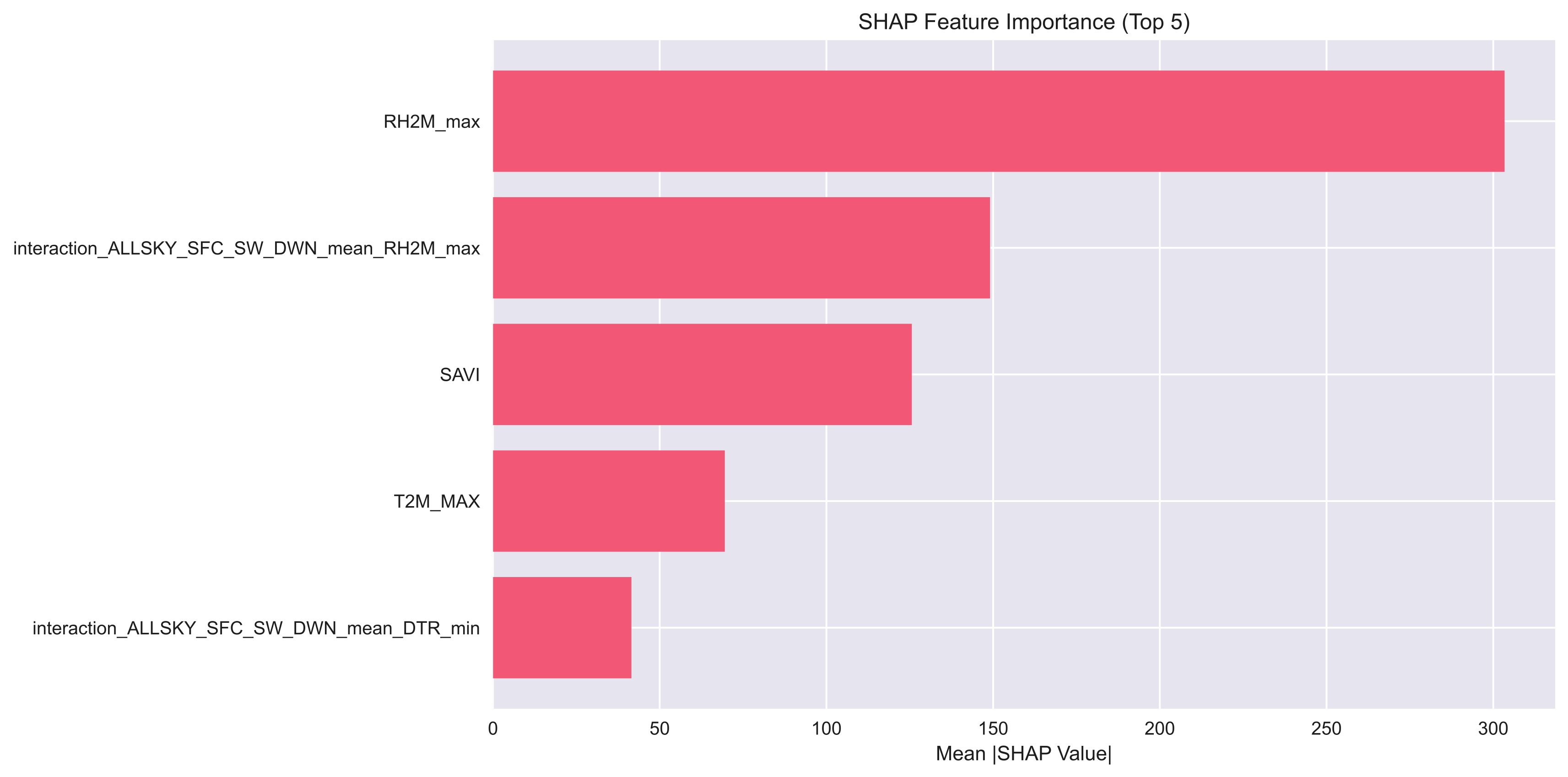
Figure 7: Global SHAP Importance plot for the Top 5 features.
Implications for Scalable and Universal Agricultural Modelling
UniCrop's configuration-driven abstraction and pipeline automation decisively mitigate the most significant challenges in operational agricultural ML: scaling to multiple crops, geographies, and temporal windows, and ensuring reproducibility. The proven effectiveness of the compact mRMR-reduced feature set demonstrates that agnostic, harmonised pipelining enables competitive predictive accuracy even with classical ML, and that more complex architectures (deep ensembles, LSTMs, transformers) would likely yield further gains on the same backbone. This division of concerns—optimise data harmonisation first, model architecture second—may be generalisable to a wide spectrum of environmental ML workflows.
Practically, UniCrop is well-positioned for rapid prototyping, regional benchmarking, and as a unified foundation atop which new spatiotemporal or sequence-based deep models can be constructed. Transparent separation of data logic and model code further underpins robust, collaborative, and shareable analytics in the agri-food sector.
Limitations and Future Directions
Key limitations include:
- Only single-crop (rice) validation is presented; empirical generalisation to other phenological types (temperate cereals, root crops) is outstanding.
- The pipeline currently excludes agronomic management (irrigation schedules, fertiliser) and cultivar/genotype effects, which constrains fine-scale or causal inference potential.
- All variables are static per field–season pair; no explicit temporal modelling is performed, and exploitation by sequence models is not yet supported.
- Quality of outputs is inherently limited by public EO and climate data continuity and latency; in persistent cloud regions, missing data remains an issue despite SAR fusion.
- High-resolution, real-time or farmer-digital twin applications may require local data ingest extensions.
Strategic future developments include spatial-temporal data extraction, explicit management and genotype variable modules, expansion to additional crop systems, containerised or serverless deployment for operational scalability, and interfaces for real-time heterogenous (EO + in situ + IoT) data fusion.
Conclusion
UniCrop presents a universal, configuration-driven, multi-source data preparation pipeline that abstracts and automates the most laborious stages of crop yield ML: multi-modal feature construction and harmonisation. Validation on a diverse, missingness-affected real-world rice dataset demonstrates that pure data-centric engineering can match or surpass advances from novel ML architectures, as seen by the high explained variance (R2>0.65) achieved with both advanced and linear models on the compact mRMR feature subset.
UniCrop's modular foundation, interpretability, and the demonstrated agronomic soundness of the resulting predictors position it as a key enabling framework for scalable, reproducible agricultural analytics, with significant implications for both the research and deployment ecosystem. The open release of code and modular configuration files further supports rapid adoption and extension. As next-generation EO, farm management, and sensor datasets mature, pipelines of UniCrop's design will be central to data-driven agronomic innovation, sustainable intensification, and climate adaptation research.
Reference: "UniCrop: A Universal, Multi-Source Data Engineering Pipeline for Scalable Crop Yield Prediction" (2601.01655)

