- The paper introduces TTC-aware training that leverages intermediate checkpoints to achieve test-time compute awareness and reduce training FLOPs by up to 92%.
- It employs a curve-fitted projection with an exponential saturation model to predict final validation accuracy and determine optimal inference samples.
- Experimental results show that models like TinyLlama and Pythia using intermediate checkpoints match or exceed fully trained baselines, enabling faster, cost-effective deployments.
FLOP-Efficient Training: Early Stopping Based on Test-Time Compute Awareness
Introduction
The paper "FLOP-Efficient Training: Early Stopping Based on Test-Time Compute Awareness" (2601.01332) addresses the resource-intensive nature of training LLMs and proposes a novel approach to mitigate these challenges. The primary contribution is the introduction of Test-Time Compute (TTC) awareness during training, which allows intermediate checkpoints in conjunction with TTC configurations to match or exceed the accuracy of fully trained models. The method promises up to 92% reductions in training FLOPs while maintaining or improving accuracy.
Scaling laws, specifically those established by Kaplan et al. [kaplan2020scaling] and challenged by Hoffmann et al. [hoffmann2022training], have traditionally guided LLM development by focusing on the optimal balance between model size, training tokens, and compute. However, this paper expands the paradigm by incorporating inference-time costs into training strategies, highlighting the potential of TTC-aware training to reduce the financial and environmental burdens associated with LLM development.
The paper systematically develops an efficient TTC evaluation method that circumvents exhaustive search and proposes a break-even bound to determine when increased inference compute compensates for reduced training compute. This approach facilitates faster deployment cycles and frequent model refreshes, making it particularly valuable for academic and open-source labs with limited computational resources.
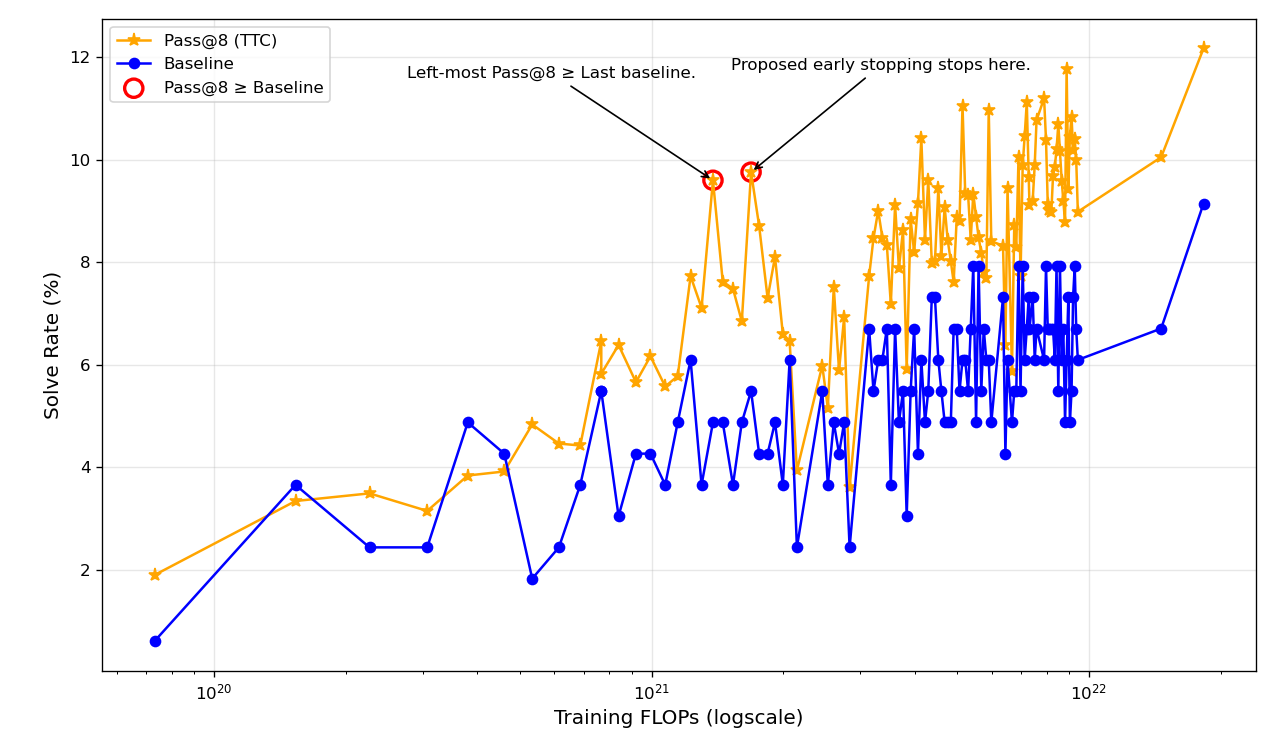
Figure 1: Solve rate (\%) versus training FLOPs for TinyLlama on HumanEval, illustrating the efficiency of TTC in reducing FLOPs while maintaining accuracy.
Proposed Method: TTC-Aware Training Procedure
The core methodology of the paper revolves around TTC-aware training, a procedure designed to optimize the balance between training and inference compute. The process begins with setting training hyperparameters and a budget for FLOPs. Validation accuracy is monitored across selected intermediate checkpoints, allowing the construction of a curve-fitted projection to estimate final validation accuracy at a given budget.
This dynamic projection leverages empirical observations that learning curves typically exhibit a saturation pattern, characterized by an initial rapid increase followed by diminishing returns. The model employs an exponential saturation function for fitting:
$\hat{\mathcal{A}(B) = a \left(1 - e^{-b B} \right) + c$
where a, b, and c are parameters representing accuracy gain scale, convergence rate, and base accuracy, respectively. The fitting process filters out non-monotonically increasing points to mitigate the impact of validation fluctuations, thus reducing variance beyond the inherent training run.
The algorithm also includes a mechanism to estimate the optimal number of inference samples per query (K∗), grounded in a sigmoid function that models accuracy gains with increasing K. This estimation method is designed to predict K∗ efficiently, ensuring that the chosen checkpoint satisfies both accuracy and compute constraints.
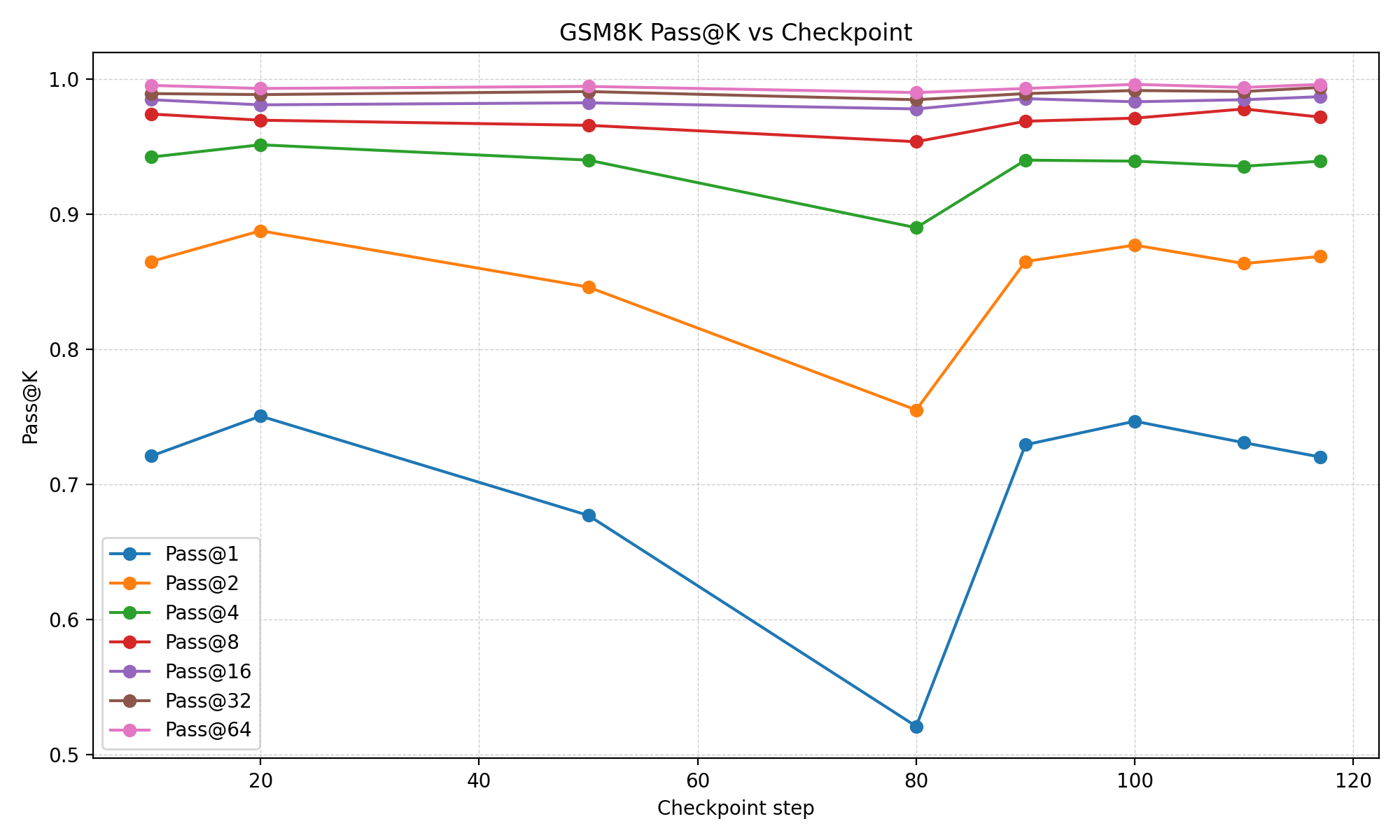
Figure 2: Qwen3-30B-A3B-Instruct on GSM8K demonstrates how intermediate checkpoints with TTC can outperform the final checkpoint.
Experimental Analysis and Results
The experimental analysis validates the effectiveness of the TTC-aware training approach across several datasets and LLM scales, including TinyLlama, Pythia, and FineMath models. The experiments demonstrate consistent trends where intermediate checkpoints using TTC match or surpass the performance of fully trained baselines while requiring significantly fewer FLOPs.
For example, on HumanEval, the TinyLlama model achieves comparable accuracy to that of the fully trained baseline with up to 92.44% savings in training FLOPs. Further experiments on GSM8K with Pythia models showcase similar insights, where intermediate checkpoints outperform larger model baselines.
Additionally, the paper investigates diverse TTC techniques beyond Pass@K, such as majority voting and Diverse Tree Search (DVTS). The results from these methods reinforce the generality of TTC's impact, emphasizing its applicability across verifier-based and aggregation metrics.
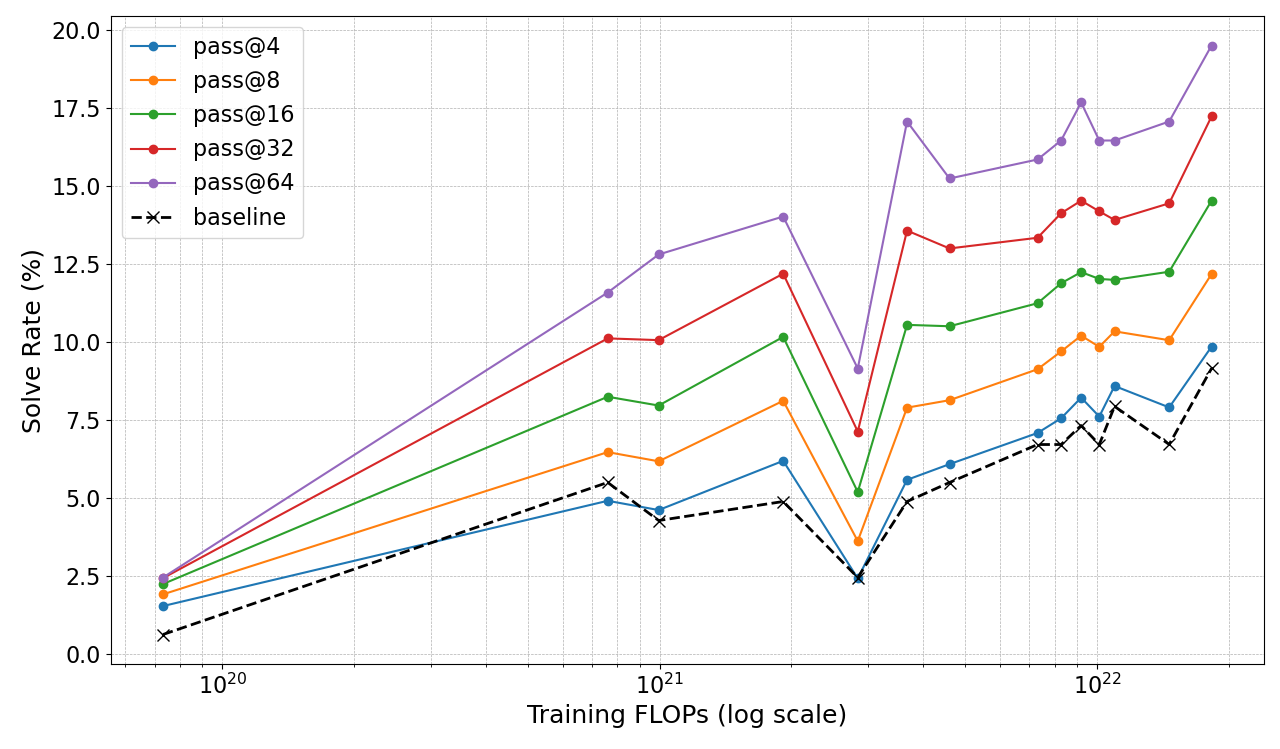
Figure 3: TinyLlama on HumanEval across Pass@K demonstrates FLOP-efficient performance by intermediate checkpoints.
Conclusion
This research introduces a significant shift in the training paradigm for LLMs, advocating for the integration of TTC awareness to reduce training compute without compromising model accuracy. The TTC-aware early stopping algorithm provides a practical method for identifying optimal deployment points, leading to cost-effective training and inference strategies. Through comprehensive validation, the approach is shown to deliver substantial compute savings, enabling more agile model development and deployment.
The findings suggest that the proposed method can substantially decrease the economic and environmental costs associated with training LLMs, particularly important in the current context of escalating demands for model efficiency and sustainability. By demonstrating practical improvements across multiple popular benchmarks and model architectures, the paper provides a compelling case for reconceptualizing training compute strategies in AI research.
Future work may explore scaling TTC-aware training principles to larger models and investigate more efficient inference techniques to further enhance test-time compute optimization.