- The paper introduces Guided Attentive Interpolation (GAI) as an attention-based upsampling operator that boosts semantic segmentation accuracy with improvements up to +1.8 mIoU.
- It employs a lightweight encoder-decoder network using backbones like ResNet-18 or DF-2, balancing real-time speed with accuracy on benchmarks such as Cityscapes and CamVid.
- Experiments demonstrate that GAI overcomes limitations of bilinear upsampling by better aligning spatial features and reducing inter-class confusion, leading to sharper segmentation boundaries.
Cross-Layer Attentive Feature Upsampling for Low-latency Semantic Segmentation
Introduction and Motivation
This work introduces Guided Attentive Interpolation (GAI), a novel attention-based cross-layer feature upsampling operator for efficient and accurate semantic segmentation (2601.01167). The method addresses limitations of coordinate-based interpolation (e.g., bilinear), which typically result in coarse high-resolution (HR) features lacking semantic context and suffering from spatial misalignment due to repeated subsampling operations in convolutional networks. GAI incorporates pixel-level semantic and spatial relations to adaptively interpolate high-resolution semantic features. This approach is deployed within a lightweight segmentation network, GAIN, achieving a favorable speed-accuracy trade-off suitable for real-time applications.
Guided Attentive Interpolation (GAI)
Mechanism
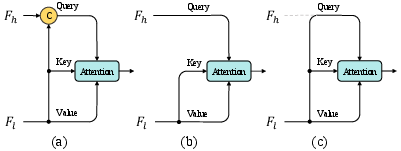
Conventional upsampling strategies (bilinear, deconvolution) rely on geometric proximity, disregarding latent semantic correlations among pixels; this leads to misaligned features and compromised segmentation accuracy. GAI addresses this by leveraging the attention mechanism to build a full pairwise affinity between query positions in (potentially less semantic-rich) HR features and key positions in low-resolution (LR), semantically enhanced features. The core design utilizes the HR features as query, and the LR features as key and value. Through a dot-product-based affinity calculation, the HR features are augmented by adaptive semantic contexts from the LR features.
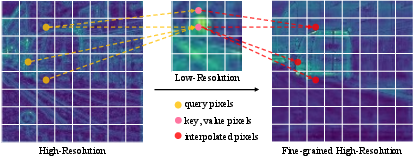
Figure 1: Guided Attentive Interpolation builds pixel-level pairwise relations between query points and key points from high- and low-resolution features, leveraging them for semantic interpolation.
The module first brings the lower-resolution features to match the HR spatial scale, concatenates them with HR features for context-aware querying, and then computes attention maps—optionally employing Criss-Cross Attention (CCA) for tractable complexity.
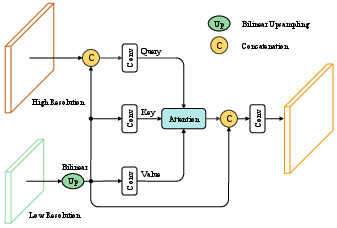
Figure 2: The GAI module upsamples LR features to HR size, concatenates with HR features for querying, and uses dimension-reduction convolutions for efficiency.
The output is an HR feature map where each pixel adaptively aggregates information from semantically similar LR positions, significantly enhancing contextual consistency and spatial alignment.
Network Architecture: GAIN
GAIN (GAI-based Network) is a streamlined encoder-decoder design using lightweight backbones (e.g., ResNet-18 or DF-2). It extracts multi-scale features and utilizes two GAI modules to upsample and fuse features from intermediate (C4) and deepest (C5) stages to an $1/8$ scale resolution. This limits computational burden while producing semantically rich, spatially precise HR features suitable for dense prediction.
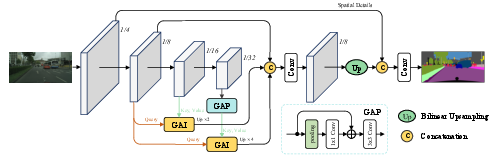
Figure 3: GAIN architecture uses two GAI modules to interpolate deep features from C4 and C5 to $1/8$ scale, which are fused with HR spatial features for the final prediction.
A global average pooling (GAP) operation after C5 enhances long-range context before attentive upsampling. The concatenated outputs pass through convolutional heads and auxiliary supervision is used to assist intermediate GAI module outputs for improved optimization.
Experimental Results
Speed-Accuracy Trade-off
GAIN decisively improves over existing real-time segmentation methods in terms of mean Intersection-over-Union (mIoU) and inference frames per second (FPS). On Cityscapes, GAIN using ResNet-18 attains 78.8 mIoU at 22.3 FPS (1024x2048 resolution), and with DF-2 achieves 78.3 mIoU at 43.8 FPS—substantially surpassing prior real-time designs at comparable speed, and approaching/ surpassing recent transformer accelerations but at much lower complexity.
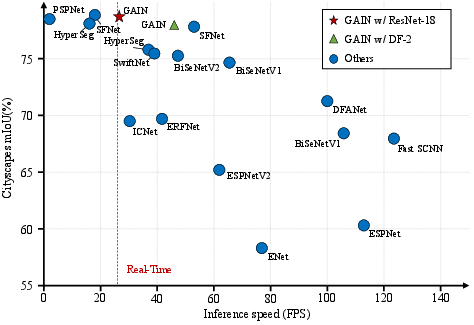
Figure 4: GAIN yields a superior speed-accuracy trade-off, outperforming prior methods (blue circles) for different backbones.
On CamVid, GAIN (ResNet-18 pre-trained) yields 80.6 mIoU at 64.5 FPS; on ADE20K, GAIN (ResNet-18) achieves 39.1 mIoU at 81.8 FPS, establishing new benchmarks for real-time segmentation.
Ablation and Diagnostic Visualizations
GAI produces HR feature maps with richer semantics and more precise spatial detail compared to both LR and non-attentive fusions. Figure 5 shows the enhanced detail and context after GAI modules; Figure 6 highlights the spatial patterns in attention weights, confirming adaptive, semantically driven feature alignment.
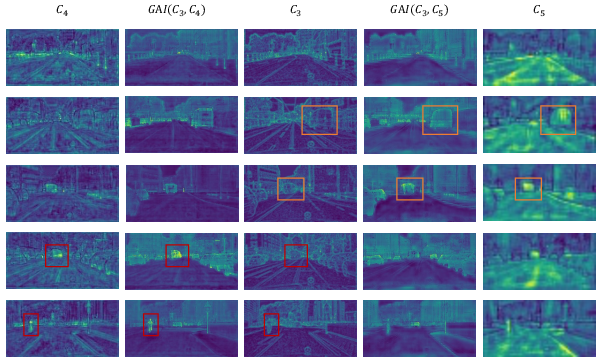
Figure 5: Feature maps before/after GAI show coarse semantics in LR features, spatial detail in HR features, and semantically enriched fine-grained activity after GAI.
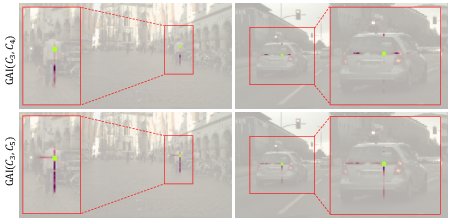
Figure 6: Attention maps for selected pixels (green) demonstrate cross-shaped, semantically guided response patterns owing to Criss-Cross Attention.
Qualitative segmentation outputs confirm consistent reduction of inter-class confusion and sharper object boundaries using GAI compared to bilinear, CARAFE, or feature alignment modules.

Figure 7: Qualitative results show higher-quality segmentation and error reduction with GAI.
Module and Design Analysis
Through systematic ablations, the following conclusions emerge:
Implications and Future Developments
GAI generalizes the paradigm of feature upsampling in dense prediction tasks, replacing coordinate-based interpolation with adaptive, contextual aggregation via attention. The design is backbone-agnostic, efficient, and modular, implying potential integration in multi-task frameworks, mobile settings, and other structured prediction tasks. The approach leverages state-of-the-art efficient attention (e.g., Criss-Cross) and supports future compatibility with dynamic attention, vision transformers, or hardware-specific optimizations.
Architecturally, GAIN achieves a compelling balance: matched or improved segmentation accuracy at real-time speed, but requiring significantly less model and memory complexity compared to heavy context modules or global transformers. The plug-and-play nature of GAI makes it widely deployable, including in embedded/edge applications for autonomous systems and robotics.
Conclusion
Guided Attentive Interpolation is an effective and theoretically sound advancement for feature upsampling in semantic segmentation networks. By explicitly leveraging pixel-level semantic-spatial affinities across layers, GAI enables the aggregation of fine-grained, context-rich high-resolution features, overcoming the limitations of coordinate-centric interpolation schemes. Embedded in a compact segmentation network, GAI yields state-of-the-art accuracy-speed trade-offs across multiple benchmarks. As a generic operation, GAI is positioned as a standard module for efficient, accurate dense prediction in future vision architectures.