Bio-inspired Agentic Self-healing Framework for Resilient Distributed Computing Continuum Systems
Abstract: Human biological systems sustain life through extraordinary resilience, continually detecting damage, orchestrating targeted responses, and restoring function through self-healing. Inspired by these capabilities, this paper introduces ReCiSt, a bio-inspired agentic self-healing framework designed to achieve resilience in Distributed Computing Continuum Systems (DCCS). Modern DCCS integrate heterogeneous computing resources, ranging from resource-constrained IoT devices to high-performance cloud infrastructures, and their inherent complexity, mobility, and dynamic operating conditions expose them to frequent faults that disrupt service continuity. These challenges underscore the need for scalable, adaptive, and self-regulated resilience strategies. ReCiSt reconstructs the biological phases of Hemostasis, Inflammation, Proliferation, and Remodeling into the computational layers Containment, Diagnosis, Meta-Cognitive, and Knowledge for DCCS. These four layers perform autonomous fault isolation, causal diagnosis, adaptive recovery, and long-term knowledge consolidation through LLM (LM)-powered agents. These agents interpret heterogeneous logs, infer root causes, refine reasoning pathways, and reconfigure resources with minimal human intervention. The proposed ReCiSt framework is evaluated on public fault datasets using multiple LMs, and no baseline comparison is included due to the scarcity of similar approaches. Nevertheless, our results, evaluated under different LMs, confirm ReCiSt's self-healing capabilities within tens of seconds with minimum of 10% of agent CPU usage. Our results also demonstrated depth of analysis to over come uncertainties and amount of micro-agents invoked to achieve resilience.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
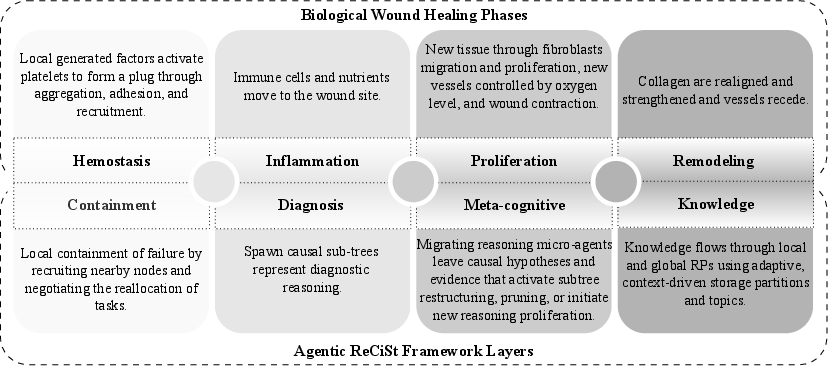
This paper is about teaching computer systems to “heal” themselves the way the human body heals a cut. When something goes wrong in a big, spread-out computer system (like phones, sensors, edge devices, and cloud servers all working together), it shouldn’t have to wait for a person to fix it. Instead, it should quickly spot the problem, contain it, figure out what caused it, repair itself, and remember what it learned so it does even better next time. The authors call their approach ReCiSt, a bio-inspired, agent-based self-healing framework for Distributed Computing Continuum Systems (DCCS).
Goals and Questions
The paper aims to answer simple but important questions:
- How can a large, complex computer system notice when something goes wrong right away?
- How can it stop the problem from spreading and keep services running?
- How can it find the root cause of the problem, fix it automatically, and do this fast?
- How can it learn from each incident so future fixes are even quicker and smarter?
- Can this work with different types of devices and networks, and use only a small amount of computing power?
How It Works (Method, in everyday terms)
Think of a DCCS like a living city of devices: tiny sensors, home routers, street cameras, company servers, and big cloud computers. They share jobs so that the whole city runs smoothly. But because there are so many pieces, things can break often—connections drop, machines slow down, or software crashes.
ReCiSt uses small software “helpers” called agents, powered by LLMs (the same kind of AI that reads and reasons with text). These agents read system logs (like diaries of what happened on each device), send quick “are you okay?” pings, and coordinate responses. The system copies the human body’s wound-healing steps:
- Containment (like blood clotting): Quickly isolate the problem and reroute work to healthy neighbors so services keep running.
- Diagnosis (like inflammation bringing help): Collect clues from logs and messages to figure out what went wrong and where.
- Meta-cognitive recovery (like new tissue growth): Spin up “micro-agents” that try different reasoning paths and reconfigure resources (e.g., update routing tables) to repair the system.
- Knowledge (like scar remodeling): Save what worked into shared memory hubs so the system gets better at healing over time.
A few simple ideas behind the scenes:
- Agents send short “heartbeats” to check if devices respond in time. If not, they flag a fault and contain it.
- Language-model agents read different kinds of messy logs and still make sense of them (like a good detective).
- Micro-agents are small, temporary helpers that can move to where they’re needed and try different fix strategies.
- Knowledge is stored both locally and globally (in “Rendezvous Points”) so the system remembers good solutions and can reuse them later.
To test ReCiSt, the authors used several public datasets of real system problems (labeled as Zoo, Hadoop, SSH, and BGL, which are common benchmarks with failure logs). They ran ReCiSt with different LLMs to see if the framework is flexible and reliable, and they measured:
- How long it takes to heal (latency)
- How much CPU it uses
- How many helper micro-agents it needs
- How “deep” the reasoning goes (number of steps)
- Whether the agents’ actions were helpful, rejected, or harmful
Main Findings
Here is what the experiments showed, in simple terms:
- Fast recovery: ReCiSt can heal many problems within tens of seconds. That’s quick for large, spread-out systems.
- Low overhead: Agents usually used a small share of CPU (the paper highlights that minimum agent CPU usage can be around 10%), which is important for devices with limited power.
- Deep, careful reasoning: The system can take multiple steps to handle confusing or uncertain problems without rushing into harmful actions.
- Works across different settings: Whether it’s cloud logs, server logs, or system messages from different environments (Zoo, Hadoop, SSH, BGL), the approach still works.
- Flexible AI engines: The same framework ran on different LLMs and still delivered self-healing, which means the design isn’t tied to one specific AI.
Why this matters: Quick containment stops small failures from becoming big outages. Accurate diagnosis means less guessing. Learning from each fix makes future healing even faster. All of this means less downtime and fewer emergency human interventions.
What It Means (Impact)
If computer systems can heal themselves like this, we could have:
- More reliable smart cities (traffic lights, cameras, and sensors keep working)
- Safer hospitals and factories (less downtime for critical equipment)
- Smoother networks for phones and the internet (helpful for future 6G ideas)
- Lower costs and faster response times (fewer on-call fixes at 2 a.m.)
ReCiSt shows a practical way to bring nature’s resilience into computing systems. While the paper didn’t compare against many similar systems (because there aren’t many yet), it gives strong evidence that bio-inspired, agent-based self-healing can work quickly and efficiently. In the future, this approach could be improved with stronger safety checks, shared knowledge across organizations, and standard methods so many systems can learn from each other.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research:
- Lack of baselines: The evaluation explicitly omits comparisons against standard fault-tolerance/self-healing baselines (e.g., rule-based failover, gossip-based detection, RCA via AIOps pipelines, causal graphical models, classical anomaly detection), making it impossible to contextualize ReCiSt’s benefits and trade-offs.
- Missing algorithmic details: The “Heal” operation, agent decision policies, containment rerouting strategy, and micro-agent orchestration logic are not specified, preventing reproducibility and rigorous analysis of the control pipeline.
- Incomplete optimization solution: The multi-objective problem in Eq. (1)–(6) is formulated but no solution method (e.g., Pareto optimization, scalarization, constrained RL, online scheduling heuristic) is provided; convergence, optimality, and runtime guarantees remain unknown.
- Notation and formulation issues: The resource utilization equation (Eq. (2)) is syntactically inconsistent (missing closing brackets/denominators), and several variables (e.g., how “cpu_load” and “mem_load” are computed) are undefined, hindering implementability.
- Threshold sensitivity: Key parameters (e.g., heartbeat interval Δt, bandwidth threshold δ, neighborhood radius k, vulnerability levels, state codes) lack sensitivity analyses; effects on false positives/negatives, detection latency, and stability are unknown.
- False positive vs. slowdown discrimination: The framework acknowledges the challenge but provides no quantitative study of distinguishing transient slowdowns from genuine failures across diverse workloads and network conditions.
- Ground-truth for diagnosis: There is no description of how root causes were labeled, validated, or audited; without gold standards or expert adjudication, the accuracy of LM-based causal inference remains unclear.
- Layer ablation: No experiments isolate the contribution of each layer (Containment, Diagnosis, Meta-Cognitive, Knowledge); the marginal utility and necessity of each bio-inspired mapping is unquantified.
- LM selection, prompting, and tool use: Prompt templates, tool-calling protocols, and model-specific configurations (e.g., temperature, context windows, function-calling schemas) are not detailed; their impact on outcomes and reproducibility is unknown.
- Hallucination and safety controls: There is no systematic characterization of LM hallucinations, unsafe actions, or propagation of erroneous reasoning across agents; observed “HarmfulResponsesRate” lacks mitigation strategies and safety guarantees.
- Resource overhead characterization: Micro-agent proliferation and call rates are reported, but their relationship to end-to-end recovery latency, CPU/memory/energy overhead, and network traffic is not modeled or bounded.
- On-device feasibility: The framework does not address feasibility on resource-constrained nodes (edge/IoT), including model compression, distillation, caching, or fallback decision mechanisms when LMs are unavailable.
- Knowledge layer mechanics: Rendezvous Points (local/global) are not formally defined (routing, storage, versioning, TTLs, consistency model, conflict resolution, staleness control, privacy); the knowledge consolidation protocol is underspecified.
- Resilience metrics and definitions: Metrics like “BestResponseRate,” “AcceptedResponsesRate,” “ReasoningDepthRate,” and “CallRate” are reported but not defined or justified; mapping from agent outcomes to system-level resilience (Eq. (7)) is unclear.
- Dataset representativeness: Evaluations rely on legacy datasets (e.g., BGL, Hadoop, SSH, Zoo) that may not reflect modern DCCS characteristics (mobility, intermittent connectivity, multi-tenancy, heterogeneous sensors); coverage of failure types is unclear.
- Generalization across domains: No cross-domain validation shows ReCiSt’s robustness to new logs, unseen failure modes, multi-cloud fabrics, wireless backhauls, or dynamic topology changes in real edge environments.
- Recovery semantics: The actual reconfiguration actions (service migration, routing updates, admission control) and their constraints (e.g., stateful services, session continuity, data locality) are not described; SLA impacts are unmeasured.
- Network overhead: Heartbeat/probing traffic and diagnostic data collection cost on constrained links are not quantified; scalability of monitoring under large N and high churn is unknown.
- Cascading failures and stability: The framework does not analyze behavior under correlated or cascading failures, including oscillations, thrashing, or overload during aggressive containment/rerouting.
- Privacy, security, and compliance: Handling of sensitive logs, PII, adversarial faults, poisoning attacks, and compliance with privacy policies during knowledge sharing is unaddressed.
- Formal guarantees: There are no theoretical guarantees (e.g., bounded recovery time, robustness margins, competitive ratios, stability under stochastic arrivals) to support deployment in mission-critical systems.
- Energy efficiency: CPU usage is reported, but total energy consumption, battery impact, and energy-aware decision-making for IoT/fog nodes are not modeled or optimized.
- Multi-objective trade-offs: No explicit exploration of latency–resilience–utilization trade-offs, Pareto front characterization, or policy tuning across different operational priorities.
- Parameter auto-tuning: Strategies to automatically adapt Δt, δ, k, and vulnerability thresholds based on observed context drift, workload patterns, and network states are absent.
- Knowledge drift and forgetting: The framework does not specify mechanisms to handle outdated or contradictory knowledge, catastrophic forgetting, or adaptive memory consolidation.
- Heterogeneous logging: While heterogeneity is noted, there is no standardization pipeline (parsers, schema alignment, ontology) to normalize logs, nor evaluation of LM robustness to noisy/incomplete logs.
- Real-world deployment: No end-to-end deployment case study (e.g., in a 5G/6G edge-cloud continuum) demonstrates operational viability, integration with orchestration platforms (K8s, serverless), or DevOps practices.
- Reproducibility: Code, prompts, data preprocessing, and experiment scripts are not provided; reported tables lack sufficient context to replicate results across models and datasets.
- Cost model: Model inference costs (compute/$), bandwidth costs, and operational expenses of sustained agentic self-healing are not analyzed; economic feasibility remains unknown.
- Ethical and governance considerations: Decision autonomy, accountability, auditability of LM-driven actions, and human-in-the-loop requirements are not specified.
Practical Applications
Immediate Applications
The following applications can be deployed now by adapting the paper’s bio-inspired, LM-powered ReCiSt framework to real operational contexts. Each item lists sector fits, potential tools/products/workflows, and key assumptions or dependencies.
- Edge–cloud AIOps incident triage and self-healing
- Sectors: software, cloud, edge computing, telecom
- Tools/products/workflows: a “ReCiSt Operator” for Kubernetes/OpenShift that implements Containment (reflexive isolation/reroute), Diagnosis (LM root-cause inference from heterogeneous logs), Meta-cognitive recovery (adaptive reconfiguration), and Knowledge (runbook consolidation via local/global rendezvous points). Integrates with Prometheus, OpenTelemetry, and service meshes (Istio/Linkerd).
- Assumptions/dependencies: consistent heartbeat/health-check telemetry; LM inference available on-prem/cloud; acceptance rates and low harmful response rates (as evidenced across datasets) hold in the target stack; CPU overhead stays near observed 10–20% per agent layer.
- Industrial IoT gateway resilience for smart manufacturing lines
- Sectors: robotics, manufacturing, industrial IoT
- Tools/products/workflows: deploy micro-agents on plant gateways to interpret device logs, isolate failing PLCs/robots, and reroute tasks to adjacent cells. Meta-cognitive agents adapt routing tables and knowledge RPs maintain evolving process-specific remediation steps.
- Assumptions/dependencies: small LMs or distilled models fit gateway resource budgets; device log normalization; safety interlocks coordinate with autonomous containment to avoid unintended actuation.
- Big data/HPC cluster self-healing
- Sectors: software (data engineering), HPC
- Tools/products/workflows: ReCiSt plugins for Hadoop/YARN/Spark and HPC schedulers (SLURM/PBS) that contain failing nodes and resubmit/relocate jobs. Use LM agents trained on BGL/Hadoop logs to diagnose faults and rebuild routing/placement policies.
- Assumptions/dependencies: access to detailed job/daemon logs; scheduler APIs for automated failover; latency within “tens of seconds” and CPU utilization under ~20% as observed in BGL/Hadoop evaluations.
- MEC/Fog site resilience for 5G/6G edge services
- Sectors: telecom
- Tools/products/workflows: integrate with NFV/SDN controllers to perform rapid containment (traffic steering/multipath reroute), LM-based diagnosis of RAN/core anomalies, and adaptive recovery at MEC nodes. Knowledge layer propagates remediation playbooks across sites.
- Assumptions/dependencies: intent APIs from orchestrators; alignment with early 6G resilience targets; low harmful response rates and controlled micro-agent proliferation under network constraints.
- SSH/SIEM augmentation for secure service continuity
- Sectors: cybersecurity, enterprise IT
- Tools/products/workflows: augment SIEM/SOAR with ReCiSt Diagnosis agents that parse SSH/auth logs to classify anomalies, contain compromised hosts (quarantine, credential rotation), and update RPs with forensic playbooks.
- Assumptions/dependencies: guardrails against over-containment; incident response policies and approvals; verifiable low false-positive rates.
- Multi-cloud workload continuity and failover orchestration
- Sectors: software, finance, media
- Tools/products/workflows: ReCiSt policy engine that reads heterogeneous cloud logs/events, identifies impending failures, and triggers cross-cloud failovers. The Knowledge layer accumulates provider-specific procedures for faster future responses.
- Assumptions/dependencies: cross-cloud APIs and IAM integration; data compliance during migration; latency targets met with agent CPU budgets near observed minima.
- Smart grid edge controller self-healing
- Sectors: energy
- Tools/products/workflows: deploy micro-agents on feeder/DER controllers to detect device or comms faults, isolate failing edges, and reroute control tasks to backups. Knowledge RPs maintain localized grid repair playbooks.
- Assumptions/dependencies: certified control paths; strict safety constraints; deterministic response requirements.
- SMB/home network self-healing
- Sectors: consumer networking
- Tools/products/workflows: router/mesh firmware add-on that uses ReCiSt Containment for link/node isolation, Diagnosis from device/syslogs, and adaptive channel/route reconfiguration; Knowledge stores action histories for recurring issues.
- Assumptions/dependencies: on-device tiny LMs or cloud inference; privacy-preserving telemetry; UX for user approvals.
- Automated SRE runbook generation and maintenance
- Sectors: software, DevOps
- Tools/products/workflows: leverage the Knowledge layer’s local/global RPs to convert Diagnosis and Meta-cognitive reasoning traces into evolving, versioned runbooks/playbooks; integrate with GitOps.
- Assumptions/dependencies: high-quality log context; alignment with change management; observable improvement in accepted response rates over time.
- Enterprise resilience dashboards and KPIs
- Sectors: policy/compliance, enterprise IT
- Tools/products/workflows: report resilience metric R(A), latency L(A), and resource utilization U(A) directly from agent pipelines to risk and compliance teams; benchmark improvements across LMs and datasets.
- Assumptions/dependencies: standardized KPIs; governance of model selection; transparency into agent decisions to satisfy audit requirements.
Long-Term Applications
These applications require further research, scaling, formalization, or ecosystem development before broad deployment.
- Autonomic, intent-driven 6G networks with embedded self-healing
- Sectors: telecom
- Tools/products/workflows: standardize an agentic resilience stack mapping biological phases to network functions; embed meta-cognitive regulation across RAN, transport, and core; propagate knowledge via distributed RPs.
- Assumptions/dependencies: standards bodies adoption; tinyLMs for on-device reasoning; formal safety guarantees to meet carrier-grade SLAs.
- City-scale “digital immune systems” for urban IoT
- Sectors: smart cities, public infrastructure
- Tools/products/workflows: distributed micro-agents across traffic, environmental, and utility sensors that isolate failing subsystems, reconfigure data paths, and share remediation knowledge.
- Assumptions/dependencies: data privacy frameworks; cross-vendor telemetry normalization; secure RP synchronization across jurisdictions.
- Self-healing robotic swarms and autonomous logistics
- Sectors: robotics, logistics, defense
- Tools/products/workflows: on-board meta-cognitive agents that detect actuator/sensor degradation, contain failure roles, reassign tasks, and maintain swarm formation/function.
- Assumptions/dependencies: real-time guarantees; certification for safety-critical control; robust on-device inference and energy budgets.
- Healthcare edge ecosystems for patient monitoring and telemedicine
- Sectors: healthcare
- Tools/products/workflows: wearable/edge gateways that isolate faulty devices, maintain service continuity (e.g., vital streaming), and share remediation protocols across providers via RPs.
- Assumptions/dependencies: HIPAA/GDPR compliance; clinical safety validation; defense against misdiagnosis via ensemble agents and clinician-in-the-loop workflows.
- Resilient energy grids with autonomous containment and reconfiguration
- Sectors: energy
- Tools/products/workflows: distribution operators deploy self-healing micro-agents to re-route power flows, isolate faults, and coordinate DER operations under contingencies.
- Assumptions/dependencies: regulatory approval; formal verification of control actions; integration with SCADA/EMS.
- High-assurance finance and trading infrastructure self-healing
- Sectors: finance
- Tools/products/workflows: ultra-low-latency agent pipelines that diagnose exchange/API faults and trigger deterministic failovers without violating compliance or market integrity.
- Assumptions/dependencies: formal methods for determinism; strict latency envelopes; auditable decision records.
- Autonomous SOCs with bio-inspired containment and adaptive knowledge
- Sectors: cybersecurity
- Tools/products/workflows: multi-agent systems that blend LM reasoning with signal processing to contain threats, reconfigure defenses, and evolve knowledge RPs across enterprises.
- Assumptions/dependencies: strong guardrails to prevent harmful actions; red-team validation; robust acceptance rates under adversarial conditions.
- Formal verification and assurance of agentic self-healing
- Sectors: academia, safety-critical industries
- Tools/products/workflows: develop proofs and runtime monitors for Containment/Diagnosis/Recovery/Knowledge phases; certify RMAs (resilience management agents) for regulated domains.
- Assumptions/dependencies: new verification frameworks for LM-in-the-loop systems; traceability of agent reasoning.
- Hardware-level bio-inspired self-repair
- Sectors: semiconductors, embedded systems
- Tools/products/workflows: map wound-healing phases onto chip fabrics for isolation, redundancy activation, and remodeling (e.g., partial reconfiguration in FPGAs).
- Assumptions/dependencies: architectural support; reliability modeling; co-design with firmware-level agents.
- Cross-industry resilience standards and RP interoperability
- Sectors: policy, standards
- Tools/products/workflows: define schemas and protocols for rendezvous-point knowledge exchange; resilience KPIs; safe agent behavior policies.
- Assumptions/dependencies: multi-stakeholder alignment; privacy/security guarantees; vendor-neutral telemetry formats.
- Ubiquitous on-device tiny LMs for resource-constrained self-healing
- Sectors: IoT, mobile, edge
- Tools/products/workflows: model compression/distillation pipelines to fit LM agents to gateways and devices while preserving diagnostic quality; standardized prompts and tools.
- Assumptions/dependencies: advances in efficient inference; robust performance across heterogeneous logs; adaptive guardrails to maintain near-zero harmful responses.
Notes on Feasibility and Evidence from the Paper
- Performance: Evaluations across multiple fault datasets (e.g., BGL, Hadoop, SSH, Zoo) show self-healing within tens of seconds and agent CPU usage often near the 10–20% range per layer, supporting near-term deployment in operations contexts.
- Safety/quality: Harmful response rates are low across models and datasets, and accepted/best response rates are generally high, but vary by LM and workload—adoption should include model selection, guardrails, and continuous monitoring.
- Overheads: Micro-agent calls and tree depths indicate variable reasoning complexity; integrating rate limits and meta-cognitive controls can keep overhead acceptable in resource-constrained environments.
- Generality: The framework operates over heterogeneous logs and contexts without heavy pretraining baselines; however, real deployments should invest in log normalization, domain-tuned prompts, and integration testing with existing orchestration tooling.
Glossary
- Active inference: A neuroscience-inspired framework where agents minimize prediction errors to adaptively regulate behavior; applied here as a resilience strategy. "Active inference has been proposed as a resilience strategy for DCCS"
- Agentic: Characterized by autonomous, self-directed decision-making and action by software agents. "a bio-inspired agentic self-healing framework"
- Angiogenesis: Biological process of forming new blood vessels; used as an analogy for creating new system pathways. "A key event in this stage is angiogenesis, the formation of new capillaries"
- Bandwidth threshold: A minimum required link capacity below which a communication link is considered insufficient. "where is bandwidth threshold."
- Causal discovery: The process of inferring cause-effect relationships from data to explain failures. "perform causal discovery"
- Collagen (fibrillar collagen): Structural protein forming fibrous networks; cited in biological mapping of healing. "exposed fibrillar collagen"
- Distributed Computing Continuum Systems (DCCS): Integrated frameworks spanning IoT, edge, fog, and cloud resources into a unified computational fabric. "Distributed Computing Continuum Systems (DCCS)"
- End-to-end latency: Total time from task initiation to completion, including network and computation. "The end-to-end latency of task "
- Epithelialization: Restoration of the epithelial barrier during healing; used as a metaphor for system recovery. "epithelialization restores the epidermal barrier"
- Federated ML: Machine learning where models are trained collaboratively across devices without centralizing data. "employ federated ML failure prediction"
- Fibrin: Protein forming a mesh that stabilizes blood clots; part of the biological analogy. "converted to fibrin, forming a stabilizing polymeric network."
- Fibrinogen: Soluble blood protein that is converted to fibrin during clotting. "releasing mediators such as fibrinogen"
- Fibronectin: Extracellular matrix protein involved in tissue repair and cell adhesion. "composed of collagen fibers, proteoglycans, and fibronectin"
- Gossip-based communication: Decentralized, peer-to-peer information dissemination protocol for robust detection. "proposes gossip-based communication with migrating agents"
- Heartbeat vector: A compact status signal summarizing a node’s operational load for liveness monitoring. "a minimal heartbeat vector"
- Hemostasis: Immediate biological response to injury to stop bleeding; mapped to fault containment. "Hemostasis is the initial phase of wound healing"
- Hypoxia: Reduced oxygen condition that triggers biological signaling pathways. "hypoxia increases Hypoxia-Inducible Factor (HIF)"
- Hypoxia-Inducible Factor (HIF): Transcription factor activated under low oxygen, regulating angiogenesis-related genes. "Hypoxia-Inducible Factor (HIF)"
- Intent-aware reasoning: Decision-making that incorporates high-level intents or goals into resource allocation. "agentic mechanisms employ intent-aware reasoning"
- k-neighborhood: The set of nodes within k hops of a given node in a graph. "its -neighborhood $\mathcal{N}_\imath^{(k)}$"
- Meta-cognitive: Self-regulatory mechanisms that monitor and adjust an agent’s own reasoning processes. "Meta-Cognitive Layer"
- Micro-agents: Lightweight, specialized agents that can migrate or proliferate to perform focused tasks. "amount of micro-agents invoked to achieve resilience."
- Multi-objective optimization problem: An optimization formulation with multiple, often competing objectives. "The resulting multi-objective optimization problem is formulated as"
- Multipath communication: Networking technique that uses multiple simultaneous paths for resilience and performance. "a resilient architecture for multipath communication"
- Myofibroblasts: Contractile cells that shrink wound size during tissue repair. "myofibroblasts contract the wound"
- Orchestration mechanisms: Coordinated control systems that manage task placement and resources across heterogeneous nodes. "which demands orchestration mechanisms capable of adapting"
- Platelet plug: Initial aggregation of platelets that forms a temporary barrier at a wound site. "aggregate to form an initial platelet plug"
- Probe window: A defined time interval during which acknowledgments are expected for health checks. "during the probe window"
- Proliferation (phase): Healing stage focused on rebuilding tissue and forming new vasculature. "Proliferation phase focuses on healing and reconstruction"
- Proteoglycans: Large extracellular matrix molecules that contribute to tissue structure and repair. "composed of collagen fibers, proteoglycans, and fibronectin"
- Rendezvous Points (RP): Designated coordination nodes or locations for knowledge sharing and synchronization. "Rendezvous Points (RP)"
- Remodeling/maturation: Final healing phase where tissue is strengthened and reorganized for long-term function. "Remodeling/maturation"
- Resilience: The system’s ability to maintain or quickly restore functionality under faults. "achieve resilience in Distributed Computing Continuum Systems (DCCS)"
- Root-cause analysis: Systematic identification of the primary cause of a fault or failure. "improve root-cause analysis and failure localization"
- Serverless runtime: Execution environment where the cloud provider dynamically manages resources, abstracting servers from developers. "through serverless runtime designs."
- Vascular Endothelial Growth Factor (VEGF): Signaling protein that stimulates blood vessel formation. "induces Vascular Endothelial Growth Factor (VEGF)"
- Vasoconstriction: Narrowing of blood vessels to reduce blood flow, part of early hemostasis. "undergo vasoconstriction"
- Vasodilation: Widening of blood vessels to increase blood flow, supporting immune response. "Vasodilation occurs"
- Virtual machine (VM) migration: Moving a running VM between hosts to maintain availability or performance. "optimized virtual machine (VM) migration"
Collections
Sign up for free to add this paper to one or more collections.

