AI tutoring can safely and effectively support students: An exploratory RCT in UK classrooms
Abstract: One-to-one tutoring is widely considered the gold standard for personalized education, yet it remains prohibitively expensive to scale. To evaluate whether generative AI might help expand access to this resource, we conducted an exploratory randomized controlled trial (RCT) with $N = 165$ students across five UK secondary schools. We integrated LearnLM -- a generative AI model fine-tuned for pedagogy -- into chat-based tutoring sessions on the Eedi mathematics platform. In the RCT, expert tutors directly supervised LearnLM, with the remit to revise each message it drafted until they would be satisfied sending it themselves. LearnLM proved to be a reliable source of pedagogical instruction, with supervising tutors approving 76.4% of its drafted messages making zero or minimal edits (i.e., changing only one or two characters). This translated into effective tutoring support: students guided by LearnLM performed at least as well as students chatting with human tutors on each learning outcome we measured. In fact, students who received support from LearnLM were 5.5 percentage points more likely to solve novel problems on subsequent topics (with a success rate of 66.2%) than those who received tutoring from human tutors alone (rate of 60.7%). In interviews, tutors highlighted LearnLM's strength at drafting Socratic questions that encouraged deeper reflection from students, with multiple tutors even reporting that they learned new pedagogical practices from the model. Overall, our results suggest that pedagogically fine-tuned AI tutoring systems may play a promising role in delivering effective, individualized learning support at scale.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
AI tutoring can safely and effectively support students: A simple explanation
What is this paper about?
The paper asks a big question: Can an AI tutor help students learn safely and well in real classrooms, not just in a lab? Tutoring one-on-one is great but expensive. The researchers tested a special AI (called LearnLM) that’s trained to teach, to see if it could help more students get good, personalized help in math classes.
What questions did the researchers ask?
The study focused on four simple questions:
- Is the AI’s teaching safe, accurate, and good quality?
- Is live, interactive tutoring better than static, pre-written hints?
- If you do get live tutoring, does AI (with a human supervising it) work as well as or better than a human tutor working alone?
- What did tutors and students think of the AI?
How did they test it?
The researchers ran a careful classroom experiment in five UK secondary schools with 165 students (ages 13–15) using the Eedi math platform.
Here’s the setup, in everyday terms:
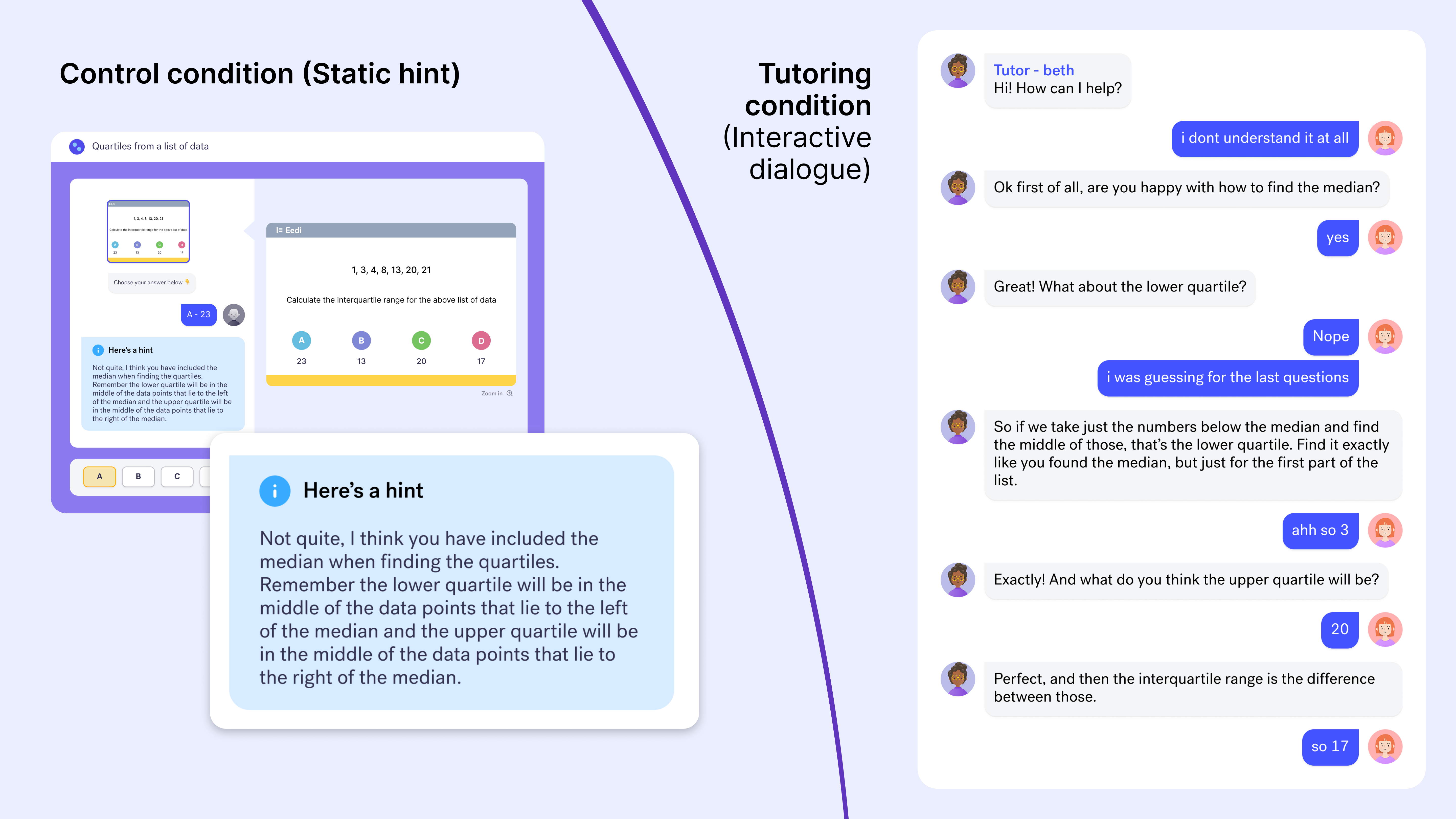
- Random assignment (like flipping a coin to keep things fair): Students who made a mistake were either given a static hint or invited into a live chat tutoring session.
- If a student got live tutoring, there was another random step: they either worked with a human tutor alone or with LearnLM, the AI tutor, whose messages were always reviewed by a human tutor before being sent.
- Human supervision: In the AI condition, a trained tutor checked every AI message, and could approve it, tweak it, or rewrite it. The goal was safety and quality.
- Teaching style: The AI was prompted to use a Socratic approach—asking guiding questions to help students figure things out—rather than just giving answers.
- What they measured:
- Immediate fix: Did the student get the same question right on the next try?
- Misconception solved: Did they get any follow-up question in that unit right?
- Transfer: Did they get the first question in the next, related topic right (a sign of learning that sticks)?
- How they analyzed results: They used a method that estimates how likely one kind of help is better than another, rather than just saying “different” or “not different.”
Quick glossary:
- Randomized controlled trial (RCT): A fair test where people are randomly put into different groups so comparisons are unbiased.
- Socratic questions: Instead of giving the answer, the tutor asks smart questions so you discover the solution yourself.
- Transfer: Using what you learned to solve a new, related problem later.
What did they find?
Here are the main results and why they matter:
- Safety and quality were strong:
- About three out of four AI-drafted messages were approved as-is by expert tutors; many others needed only tiny edits (often just removing an emoji).
- The audit found zero harmful content and only a handful of factual mistakes out of thousands of AI messages. That’s a strong safety signal.
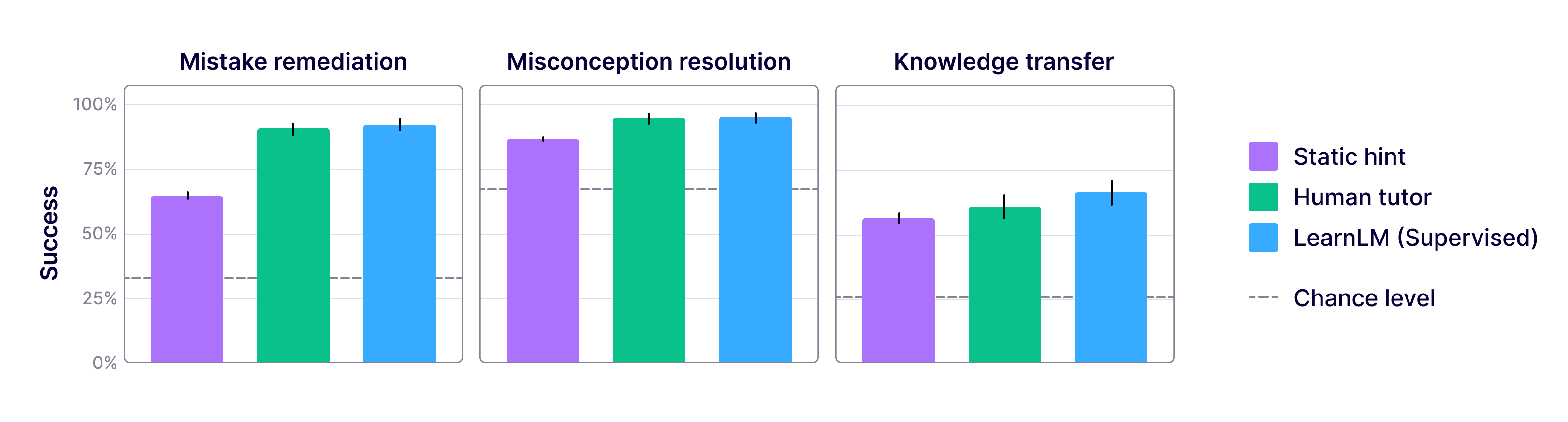
- Live tutoring beats static hints:
- Students did much better after interactive tutoring (whether human or AI+human) than after static hints when trying the problem again or solving follow-up questions. This confirms that real-time help matters.
- AI tutoring (with human supervision) matched or beat human-only tutoring:
- For fixing mistakes right away and resolving misconceptions, AI+human and human-only were similarly effective and both much better than static hints.
- For learning transfer to the next topic, AI+human did better: students supported by LearnLM were about 5.5 percentage points more likely to solve the first problem in the next unit than those helped by human tutors alone. This suggests the AI’s questioning may help students build understanding that carries over.
- Tutors’ experiences were positive (with useful cautions):
- Tutors praised the AI’s Socratic questions, saying they encouraged deeper thinking—and some tutors said they learned new teaching moves from the AI.
- The AI helped tutors handle more students at once, making their work feel smoother.
- Tutors still played a crucial role: they often adjusted pacing (so the AI didn’t “over-question” and frustrate students) and added social/emotional warmth and personalization (e.g., remembering a student, setting the right tone).
- Students liked tutoring:
- Students rated live tutoring as more helpful than static hints.
Why is this important?
- Access: One-on-one help is powerful but expensive. An AI that drafts strong tutoring messages—checked by a teacher—could give more students high-quality support.
- Safety: With human supervision, the AI’s help was safe and accurate in this trial.
- Learning that sticks: The AI+human approach didn’t just fix mistakes—it seemed to help students carry their understanding to new topics, which is what real learning is all about.
- Teacher support: The AI can save time and offer fresh ways to explain ideas, while teachers provide judgment, empathy, and classroom context.
What are the limits and what comes next?
- It was short-term and focused on math: We still need longer studies to see lasting effects and to test other subjects (like history or literature), which can be less clear-cut than math.
- Human oversight is key: Tutors made the AI’s guidance work for real students by moderating pace and tone. Today’s AI isn’t ready to handle the social/emotional side alone.
- Bigger studies: Future research should follow students for months, keep one type of support consistent, and include outside tests to confirm long-term gains.
Bottom line
In real UK classrooms, an AI tutor designed for teaching—and supervised by expert tutors—was safe, effective, and sometimes even better than human-only tutoring at helping students use what they learned on new problems. With teachers in the loop, AI tutoring could help bring personalized, high-quality support to many more students.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following gaps, limitations, and open questions remain unresolved and point to concrete directions for future research:
- Long-term learning and retention: Does AI-supported tutoring produce sustained gains over weeks or months, and does it improve performance on external, standardized assessments (e.g., GCSE), beyond immediate unit-level outcomes?
- Cumulative exposure effects: How does consistent assignment to AI vs human tutoring across an entire term affect learning trajectories, compared to session-by-session randomization that allows carryover between conditions?
- Autonomy vs supervision: What are the safety, efficacy, and failure modes of AI tutors operating with reduced or no human supervision, and what guardrails are necessary to preserve pedagogy and safety?
- Scalability and efficiency: Quantify throughput, time-on-task, latency, and cost-effectiveness (e.g., sessions per tutor per hour, cost per incremental learning gain) to determine whether supervised AI meaningfully expands capacity.
- Generalization beyond mathematics: Can AI tutoring handle subjects with ambiguous or interpretive tasks (e.g., history, literature) where misconceptions are less discrete and answers are non-binary?
- Cross-population validity: Test generalization across age groups (primary, post-16), diverse geographies and school systems, and language contexts (including higher English as an Additional Language rates), given the current cohort’s limited EAL representation and UK-only setting.
- Equity and subgroup analyses: Assess heterogeneous treatment effects by baseline ability, gender, socio-economic status, EAL status, and special educational needs to ensure AI tutoring does not widen achievement gaps.
- Tutor and school effects: Use hierarchical/multilevel models to estimate variability across tutors and schools, and to disentangle tutor-mediated effects from model effects; current analyses do not report random effects for these clusters.
- Item difficulty calibration: Incorporate item response theory (IRT) or equivalent to control for question difficulty and discrimination, particularly for the “knowledge transfer” metric based on the first question in the next unit.
- Far transfer and delayed testing: Evaluate transfer to non-adjacent topics and retention over delayed intervals (days/weeks), rather than only the immediate next unit within a sequence.
- Affective adaptivity: Measure and model student frustration, engagement, and patience in real time, and evaluate algorithms that dynamically adjust Socratic pacing versus direct instruction to prevent disengagement.
- Personalization via student history: Test whether adding past-session context and student-specific profiles (memory, rapport signals) to prompts improves engagement and outcomes while preserving privacy.
- Safety beyond constrained domains: Audit safety in open-ended tasks, longer dialogues, and adversarial scenarios; the current low-risk math setting with expert supervision may understate real-world risks.
- Pedagogical quality auditing: Go beyond edit-distance metrics and apply expert rubric-based semantic evaluations to detect subtle misguidance, incomplete explanations, or off-target questioning.
- Model and prompt ablations: Replicate with updated models (e.g., Gemini 2.5 Pro) and non-fine-tuned LLMs to isolate the contribution of pedagogy-specific fine-tuning and prompt design to observed effects.
- Reproducibility and transparency: Enable third-party replication with pre-registration, shared analysis plans, anonymized data/message corpora (where feasible), and independent auditing to mitigate potential conflicts of interest.
- Operational metrics: Rigorously measure tutor workload distribution, switching costs between supervision and direct tutoring, queue times, and session concurrency under classroom conditions.
- Tutor professional development: Quantify whether supervising AI produces durable improvements in tutors’ pedagogy, and estimate contamination effects when tutors apply AI-derived practices in human-only sessions.
- Student attitudes and agency: Systematically study students’ trust, perceived helpfulness, autonomy, and metacognitive outcomes when interacting with AI tutors, beyond small-sample post-trial surveys.
- Privacy and safety trade-offs: Investigate how storing session history and personalization data affects child safety, privacy, and regulatory compliance in school deployments.
- Topic-specific performance: Map AI vs human advantages across specific misconception categories and math topics to identify where AI guidance is most/least effective.
- Socratic pacing optimization: Develop and evaluate policies (e.g., reinforcement learning from human feedback) that trigger timely pivots from inquiry to instruction when affective signals indicate frustration.
- Tone and persona calibration: Test how stylistic choices (e.g., emoji use, formality, warmth) impact engagement and performance, and codify style guidelines for age-appropriate communication.
- Infrastructure constraints: Examine how latency, device availability, and connectivity affect tutoring effectiveness and student experience in varied school settings.
- Teacher adoption and role design: Study educators’ acceptance, training requirements, workload impacts, and the organizational changes needed to integrate AI tutoring sustainably.
- Platform dependence: Validate results on other platforms (including those using open-response items) to reduce dependence on multiple-choice, misconception-aligned workflows like Eedi’s.
- Selection effects: Analyze outcomes for students who do not trigger interventions (i.e., answer correctly on first attempt) and evaluate proactive AI support versus remedial-only triggering.
- Carryover and contamination quantification: Design studies that prevent or explicitly measure cross-condition learning among tutors and students to obtain cleaner causal estimates.
- Statistical power and stability: Conduct larger, pre-registered trials with planned power analyses to confirm the observed 5.5 percentage-point transfer advantage and assess effect stability across cohorts.
Practical Applications
Immediate Applications
The following applications can be deployed now by adapting the paper’s supervised AI-tutor workflow, safety practices, and evaluation methods to existing learning contexts.
- (Education) AI tutor co-pilot integrated into LMS and tutoring platforms
- What: Embed a “draft-and-supervise” chat assistant (e.g., Gemini 2.5 Pro, as LearnLM’s successor) that proposes Socratic, misconception-targeted messages for teacher/tutor approval, editing, or replacement.
- Tools/workflows: Tutor supervision console with Approve/Edit/Replace; prompt templates that include question text, student response, mapped misconception; edit-distance analytics to quantify supervision load; emoji/style controls.
- Assumptions/dependencies: Human-in-the-loop supervision; curated item banks with misconception labels; student consent and data protection compliance (GDPR/UK ICO guidance); reliable classroom connectivity.
- (Education) At-scale homework help and after-school support with human-supervised AI
- What: Expand 1:1 support capacity in homework helplines and after-school programs by letting one tutor supervise several concurrent AI-drafted chats.
- Tools/workflows: Multi-session dashboard; “frustration/pacing” flags to switch from Socratic probing to direct guidance; escalation button for full human takeover.
- Assumptions/dependencies: Staffing model for supervision; service-level policies for escalation; monitoring of throughput and quality.
- (Education) Socratic question generator for formative assessment
- What: Generate immediate, misconception-specific prompts when students miss a diagnostic item, then ask the same or an isomorphic item to check remediation.
- Tools/workflows: Item-level pipelines that pass error type + student response to the model; retry-and-check loop; transfer tracking to the next unit/topic.
- Assumptions/dependencies: Validated misconception taxonomy; guardrails to avoid revealing answers; alignment with curriculum standards.
- (Education, Teacher PD) In-class pedagogical coach for tutors and teachers
- What: Use AI drafts as live exemplars of Socratic questioning; surface alternative explanations teachers can adopt; support reflective practice.
- Tools/workflows: Side-panel that shows “Why this question?” rationale; snippet library of effective prompts; post-session review highlighting what teachers kept/edited.
- Assumptions/dependencies: Teacher buy-in; PD time; clarity that AI suggestions do not replace professional judgment.
- (Education) Exit-ticket remediation during lessons
- What: After a wrong answer, show an AI-drafted hint for teacher approval and push a follow-up item before students move to the next activity.
- Tools/workflows: One-click approve/edit on teacher tablet; class-wide or small-group application for common misconceptions.
- Assumptions/dependencies: Short latency; classroom device access; teacher oversight.
- (Education, Safety) Lightweight safety and quality auditing of AI tutoring
- What: Reproduce the paper’s corpus audit: track approvals, edit distances, and themes of edits to detect safety, factuality, pacing, and tone issues.
- Tools/workflows: Audit dashboard; sampling review of edited/replaced messages; red-team prompts; incident reporting loop.
- Assumptions/dependencies: Logging of both AI drafts and final messages; role-based access controls; child safety review.
- (Education Research) Embedded Bayesian RCTs for in-situ evaluation
- What: Run session-level randomization (AI-supervised vs human-only) and analyze learning outcomes with Bayesian models that yield decision-relevant probabilities.
- Tools/workflows: “RCT kit” for platforms (randomization service, posterior dashboards); pre-registered covariates (baseline performance).
- Assumptions/dependencies: Sufficient traffic; ethics approval; clear outcomes (remediation, resolution, transfer).
- (Policy, Governance) Procurement and deployment checklist for safe AI tutoring
- What: Require human-in-the-loop supervision, message logging and audits, child-safety review, consent flows, and clear escalation policies.
- Tools/workflows: Model card addendum for educational use; data-retention and transparency statements; local authority or MAT-level guidance.
- Assumptions/dependencies: Regulator-aligned templates (GDPR, age-appropriate design code); school board approval.
- (Industry/EdTech) Tutor workbench productization
- What: Package the supervision UI, prompt recipes, and analytics as a SaaS add-on to tutoring platforms and LMSs.
- Tools/workflows: API connectors (Canvas, Google Classroom, Schoology); SSO; usage-based metering; role-based dashboards for admins.
- Assumptions/dependencies: Vendor security review; scalable inference costs; uptime SLAs.
- (Daily life, Families) Parent-guided “Socratic mode” for homework
- What: A home app that drafts guided questions without revealing answers, with caregivers toggling strict Socratic vs “give-a-nudge” modes.
- Tools/workflows: Guardian dashboard; reading-level control; “no direct answers” switch; “show rationale” for parents.
- Assumptions/dependencies: Age-appropriate design; privacy controls; clear instructions to avoid over-reliance.
- (Customer Education, Software) Socratic troubleshooting for user onboarding
- What: Adapt Socratic prompts to guide users to self-diagnose errors (e.g., configuration issues) before surfacing solutions.
- Tools/workflows: Misconception taxonomies mapped to common support tickets; stepwise probing; escalation to agent when frustration signals appear.
- Assumptions/dependencies: Domain-specific knowledge base; user tolerance for guided questioning; careful pacing.
- (Analytics) Transfer tracking as a core success metric
- What: Add “next-topic first-question accuracy” to product analytics to capture durable learning beyond immediate correction.
- Tools/workflows: Sequence-aware data model; cohort dashboards; alerts when transfer drops despite high immediate remediation.
- Assumptions/dependencies: Curricular sequencing metadata; enough flow to next units to measure transfer.
Long-Term Applications
These applications require additional research, productization, or scaling beyond the current trial’s scope.
- (Education) Semi-autonomous AI tutors with adaptive pacing and socio-emotional calibration
- What: Move from fixed Socratic adherence to a calibrated tutor that modulates depth, tone, and length based on student engagement and affect.
- Tools/workflows: Signals from response latency, hesitation, sentiment; reinforcement learning from tutor edits; configurable “pacing governor.”
- Assumptions/dependencies: Robust affect detection; privacy-preserving telemetry; guardrails against manipulation; validated fairness across subgroups.
- (Education) Cross-subject expansion beyond mathematics
- What: Apply the supervised-tutor model to interpretive subjects (history, literature) and open-ended tasks (writing, argumentation).
- Tools/workflows: Rubric-aware guidance; citation and sourcing scaffolds; debate/argument maps; plagiarism-safe support modes.
- Assumptions/dependencies: Subject-specific pedagogy; measures for higher-order outcomes; new prompt templates; stronger content safety.
- (Education) Longitudinal, program-level efficacy and equity studies
- What: Year-long RCTs assigning students to stable support types, tracking standardized exams and subgroup effects (e.g., EAL, SEN).
- Tools/workflows: District-level research partnerships; data-sharing agreements; pre-registered analysis; equity dashboards.
- Assumptions/dependencies: Administrative buy-in; safeguarding; statistical power; mitigation plans for any detected harms.
- (Policy) Accreditation and compliance frameworks for AI tutors
- What: Establish certification tiers (e.g., “supervised-only,” “semi-autonomous”) tied to safety audits, learning outcomes, and transparency.
- Tools/workflows: Third-party audit protocols; incident disclosure norms; procurement standards; continuous monitoring requirements.
- Assumptions/dependencies: Regulator capacity; interoperability of evidence; international alignment.
- (Education, Workforce) Tutor role redesign and micro-credentialing
- What: Formalize “AI-supervising tutor” competencies (prompting, pacing overrides, discourse moves) with PD pathways and badges.
- Tools/workflows: Simulation labs with replay of real sessions; feedback on edit rationales; mentorship networks; competency-based micro-credentials.
- Assumptions/dependencies: Union/HR alignment; time for PD; recognition in hiring and pay.
- (EdTech, Research) Marketplace for misconception libraries and prompt packs
- What: Curate and exchange validated misconception graphs, Socratic prompt templates, and transfer-aligned item sequences.
- Tools/workflows: Versioned repositories; alignment to national curricula; quality ratings from outcomes.
- Assumptions/dependencies: IP/licensing models; standard schemas; governance to prevent leakage of direct answers.
- (Education, Accessibility) Personalized tutoring for EAL and SEN learners
- What: Tailor language level, multimodal supports (diagrams, read-aloud), and cultural references; memory across sessions for rapport.
- Tools/workflows: Per-learner profiles; controlled persona memory; teacher-approved biographical anchors (“Hi Sarah, welcome back!”).
- Assumptions/dependencies: Consent for personalization; safe memory policies; bias and fairness audits; multimodal model maturity.
- (Privacy, Infrastructure) On-device or edge-deployed tutoring for schools
- What: Reduce data exposure and latency via on-prem or edge models with school-managed governance.
- Tools/workflows: Federated fine-tuning with tutor edit signals; differential privacy; offline fallbacks.
- Assumptions/dependencies: Hardware budgets; MLOps capacity in districts; energy and maintenance costs.
- (Cross-sector Learning) Corporate training, healthcare CME, and coding bootcamps
- What: Use supervised Socratic tutoring for skills practice and error remediation in professional education.
- Tools/workflows: Domain-specific misconception taxonomies (e.g., clinical reasoning pitfalls, debugging heuristics); scenario-based dialogues; transfer metrics (task performance).
- Assumptions/dependencies: High-stakes safety reviews (especially in healthcare); alignment with certification bodies.
- (Methods) Continuous-improvement loops using posterior-based decisioning
- What: Normalize Bayesian posterior dashboards for product decisions (e.g., roll out when P(improvement > X) exceeds threshold).
- Tools/workflows: Experiment orchestration; sequential monitoring; guardrails against p-hacking.
- Assumptions/dependencies: Statistical literacy in teams; governance for stopping rules.
- (Safety) Proactive harm detection and red-teaming at scale
- What: Automated scans for hallucinations, harmful content, and subtle pedagogy risks; adversarial prompt test suites for education.
- Tools/workflows: Safety classifiers; synthetic student personas; post-hoc human adjudication.
- Assumptions/dependencies: High-quality labeled data; periodic re-certification.
- (Economics) Cost-effectiveness models for tutoring-at-scale
- What: Compare cost per additional correct transfer vs human-only tutoring; inform funding and procurement.
- Tools/workflows: Throughput measurement, staffing models, inference cost monitoring, ROI dashboards.
- Assumptions/dependencies: Transparent cost data; stable usage patterns; sensitivity to local wages and cloud pricing.
Cross-cutting assumptions and dependencies to consider
- Domain fit: Current evidence is from secondary mathematics with structured items and validated misconception labels; generalization to open-ended subjects is unproven.
- Supervision is central: Safety and efficacy hinge on expert human oversight, at least in the near term.
- Data governance: Student consent, minimal data retention, and age-appropriate design are essential.
- Equity: Trials should include diverse settings (EAL, SEN, varied socio-economic contexts) to avoid widening gaps.
- Measurement: Include transfer metrics, not just immediate remediation; use Bayesian analyses for actionable decisions.
- Model choice and updates: Use Gemini 2.5 Pro (as recommended) or equivalent pedagogically fine-tuned models; plan for model drift and re-validation.
Glossary
- Audit trail: A documented record of the analytic and coding steps that enables verification and transparency. "to create a complete audit trail."
- Bayesian framework: A statistical approach that incorporates prior beliefs and observed data to estimate treatment effects and their credibility. "we adopted a Bayesian framework and directly estimated the magnitude and credibility of our treatment effects."
- Bayesian regression: Regression analysis performed within a Bayesian inference framework to estimate effects and uncertainties. "We leveraged Bayesian regression to estimate treatment effects for these outcomes."
- Codebook: A structured set of definitions and labels used to consistently categorize qualitative data. "reviewed and refined the generated codes into a focused codebook."
- Credible interval: A Bayesian interval estimate that represents the range within which a parameter lies with a given posterior probability. "with a 95\% credible interval of [88.5\%, 93.6\%]"
- Crossover: A situation in experimental design where insights or effects transfer between conditions, potentially biasing comparisons. "that crossover might dampen the measured difference between the two tutoring conditions."
- Diagnostic multiple-choice questions: Assessment items designed to identify specific misconceptions by offering carefully crafted distractors. "consisting of diagnostic multiple-choice questions with four response options"
- Edit distance: A measure of how many character-level operations are required to transform one text into another. "As judged by edit distance~\citep{levenshtein1966binary, navarro2001guided}, many of the instances where tutors edited or rewrote a suggestion reflected minor or targeted adjustments"
- Edit ratio: The edit distance divided by the total character count of the original draft, indicating the proportion of text changed. "by computing the Levenshtein distance and the edit ratio (the Levenshtein distance divided by the total character count of the initial draft)."
- English as an Additional Language (EAL): A designation for students who speak a language other than English at home and are developing English proficiency. "English as an Additional Language (EAL), ranging from 2--11\%."
- Endline surveys: Post-intervention questionnaires administered at the end of a study to capture outcomes and experiences. "We administered short baseline and endline surveys to all supervising tutors."
- Frequentist approaches: Statistical methods that interpret probability as long-run frequencies and do not incorporate prior beliefs. "Unlike standard frequentist approaches, this method allows us to calculate the probability that one intervention outperforms another by a specific magnitude"
- Free School Meal eligibility: A UK education metric used as a proxy for socioeconomic status. "Free School Meal eligibility ranged from 12\% (representing affluent areas) to 26\%"
- Generative AI (genAI): AI systems that produce content (e.g., text, images) and can interactively tutor students. "generative AI (``genAI'')"
- Hybrid tutoring: A tutoring model that blends static supports (like hints) and interactive chat-based assistance. "chat-based tutoring (``hybrid tutoring''~\citep{chen2025vtutor})"
- Inductive process: A qualitative analysis method that derives themes and categories from the data rather than imposing predefined codes. "we audited the full corpus of drafted messages through an iterative, inductive process"
- Knowledge transfer: The ability for learners to apply understanding from one topic to correctly solve problems in a new, related topic. "students tutored by LearnLM exhibited measurably better knowledge transfer than those receiving support from human tutors alone."
- Levenshtein distance: A specific edit distance metric counting insertions, deletions, and substitutions needed to transform one string into another. "by computing the Levenshtein distance and the edit ratio"
- Longitudinal approach: A research design that follows the same participants over an extended period to assess lasting effects. "Such a longitudinal approach could help determine whether the immediate successes that we observed translate into persistent, substantive learning gains"
- Mistake remediation: An outcome measuring whether students correctly answer the same question on a second attempt after receiving support. "mistake remediation (success at attempting a question a second time, after an intervention)"
- Persona: The stylistic voice or identity projected by an AI or tutor in conversation, affecting tone and rapport. "adjusted the persona or tone conveyed by the drafted messages."
- Posterior distributions: The probability distributions of model parameters after updating with observed data and priors. "We then used the resulting posterior distributions to calculate the exact probability that outcomes in one group exceeded those in another"
- Posterior predictive margins: Predicted outcome rates derived from the posterior that account for covariates and uncertainty. "represent posterior predictive margins estimated from these regressions, adjusting for students' baseline performance."
- Posterior probability: The probability of a claim given the observed data and the prior, computed from the posterior distribution. "Tutors' self-reported comfort with using AI tools rose ... (posterior probability of increase: 90.0\%)."
- Productive struggle: A pedagogical principle where carefully managed difficulty helps deepen understanding without causing disengagement. "weighing the long-term benefits of productive struggle against the immediate risks of frustrating a student"
- Qualitative coding: The practice of labeling segments of text in qualitative data to identify patterns and themes. "emerging guidance on applying genAI tools to support qualitative coding"
- Randomized controlled trial (RCT): An experimental design where participants are randomly assigned to conditions, enabling causal inference. "an exploratory randomized controlled trial (RCT) with students across five UK secondary schools."
- Semi-structured interviews: Interviews guided by a protocol that allows flexibility to explore participants’ experiences in depth. "conducting in-depth, semi-structured interviews with a random subset of supervising tutors"
- Socratic dialogue: A tutoring technique that uses guided questioning to lead learners to self-correct and reflect. "LearnLM consistently generated high-quality, Socratic dialogue"
- Weakly informative priors: Priors that lightly regularize Bayesian models without strongly influencing the posterior. "we assigned identical, weakly informative priors to each intervention."
Collections
Sign up for free to add this paper to one or more collections.