A Network of Biologically Inspired Rectified Spectral Units (ReSUs) Learns Hierarchical Features Without Error Backpropagation
Abstract: We introduce a biologically inspired, multilayer neural architecture composed of Rectified Spectral Units (ReSUs). Each ReSU projects a recent window of its input history onto a canonical direction obtained via canonical correlation analysis (CCA) of previously observed past-future input pairs, and then rectifies either its positive or negative component. By encoding canonical directions in synaptic weights and temporal filters, ReSUs implement a local, self-supervised algorithm for progressively constructing increasingly complex features. To evaluate both computational power and biological fidelity, we trained a two-layer ReSU network in a self-supervised regime on translating natural scenes. First-layer units, each driven by a single pixel, developed temporal filters resembling those of Drosophila post-photoreceptor neurons (L1/L2 and L3), including their empirically observed adaptation to signal-to-noise ratio (SNR). Second-layer units, which pooled spatially over the first layer, became direction-selective -- analogous to T4 motion-detecting cells -- with learned synaptic weight patterns approximating those derived from connectomic reconstructions. Together, these results suggest that ReSUs offer (i) a principled framework for modeling sensory circuits and (ii) a biologically grounded, backpropagation-free paradigm for constructing deep self-supervised neural networks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new kind of artificial neuron called a Rectified Spectral Unit (ReSU). ReSUs are designed to behave more like real brain cells than the standard units used in most AI systems. They learn by watching how a signal changes over time—looking at a short “window” of the recent past to predict the near future—and then keeping only the part of the signal that matters (positive or negative). The authors show that a small network of these units can learn to detect motion in images in a way that closely matches how the fruit fly’s visual system works, all without using error backpropagation (the usual training method in deep learning).
What questions did the paper ask?
- Can we build neural networks that learn useful, layered (hierarchical) features from natural inputs without relying on backpropagation and labeled data?
- Can a biologically inspired unit that works with time-varying signals learn the kinds of filters and features seen in real sensory neurons?
- Do these units naturally learn motion detection (like the fly’s visual system), and do the learned connection patterns resemble what biologists see under the microscope?
How did they do it? Methods explained simply
Think of a signal like a song playing over time. A ReSU listens to the last few seconds (the “past window”) and tries to pick out the most informative pattern that helps it guess what’s coming next (the “future window”). Here’s how it works:
- Canonical Correlation Analysis (CCA): This is a statistical “match-up” game. It searches for directions (think: the best angle to look at the data) in the past that line up most strongly with directions in the future. These directions are like smart filters that focus on the most predictive parts of the signal.
- Projection: The ReSU projects the past window onto one of these learned directions. This is like pressing the signal through a shaped mold that highlights a particular pattern.
- Rectification: Real neurons often only send non-negative outputs (they don’t fire “negative spikes”). A ReSU copies this by keeping only the positive part (an ON response) or only the negative part (an OFF response). This makes the unit sensitive to increases versus decreases in the signal, similar to how biological ON and OFF pathways work.
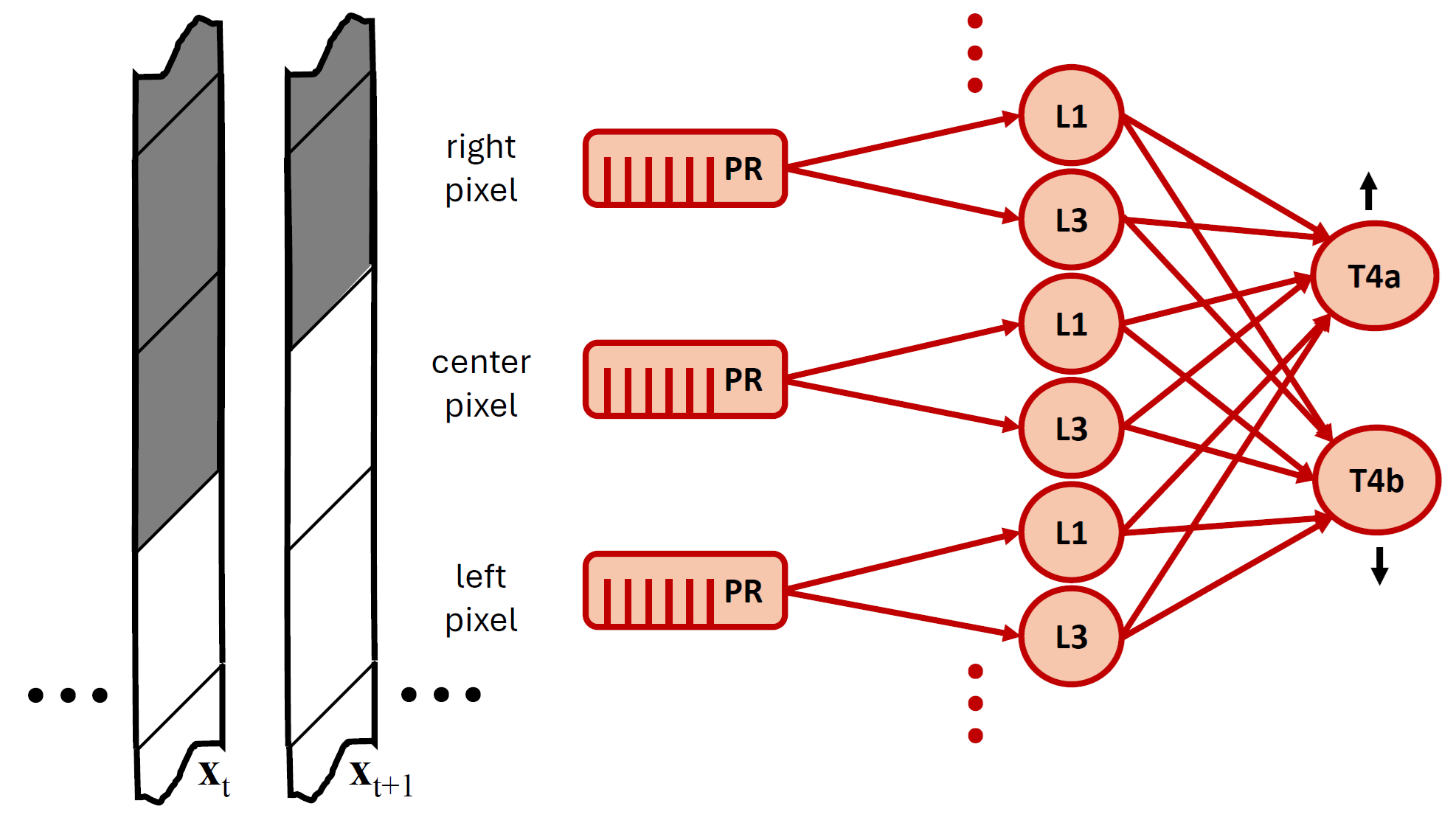
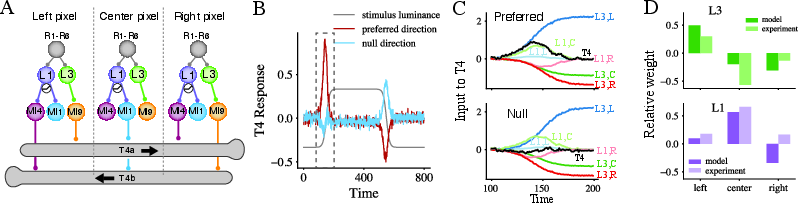
The authors trained a two-layer ReSU network on natural images that were shifted across the “retina,” simulating motion. The first layer acted on single pixels (like very small regions of the image), and the second layer pooled across neighboring pixels, much like the wiring seen in fruit flies.
They also analyzed the math behind their approach for different kinds of signals:
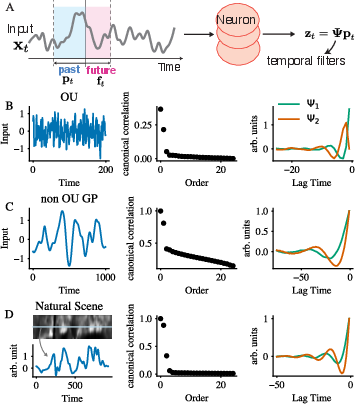
- Ornstein–Uhlenbeck (OU) and Gaussian processes: These are models of “smooth random wiggles” over time. The authors show that their CCA-based filters capture as much future-predicting information as possible for these signals. In everyday terms, their method finds the best way to summarize the past so you can guess the future.
What did they find, and why is it important?
Here are the main results and what they mean:
- First-layer filters look like real fly neurons:
- Units trained on single-pixel time series learned two kinds of temporal filters: one that smooths the signal (low-pass) and one that looks like a gentle derivative (responds to changes).
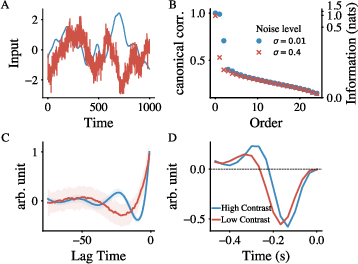
- These match the behavior of Drosophila neurons called L3 (low-pass) and L1/L2 (change-sensitive). Even more compelling, the filters automatically adapted when the signal got noisier, just like biological neurons adjust their sensitivity in low-contrast or noisy conditions.
- Second-layer units became direction-selective motion detectors:
- Pooling across three neighboring pixels, the network learned to respond strongly when a bright edge moved in a preferred direction and weakly in the opposite direction—just like T4 motion-detecting cells in flies.
- The synaptic weight patterns (which inputs are positive vs. negative and by how much) resembled what scientists have reconstructed from real fly brains (connectomics).
- No backpropagation needed:
- The network learned these layered features through local, self-supervised rules based on past–future relationships in the data. This is closer to how real brains might learn: from raw experience, without labeled examples or error signals being sent backward through many layers.
Why it matters:
- It shows a simple, biologically grounded pathway to building deep networks that learn temporal and hierarchical features on their own.
- It bridges AI and neuroscience by reproducing known properties of a well-studied visual circuit.
- It suggests we can build more efficient, robust, and interpretable AI systems by following biological principles.
Implications and potential impact
This research points toward a future where:
- AI systems use time-aware, self-supervised building blocks (like ReSUs) instead of static units trained with backpropagation. That could make learning more efficient, more data-friendly, and more brain-like.
- Neuroscientists gain principled models that explain why certain neural filters and wiring patterns appear in sensory systems—because they naturally maximize the ability to predict the future from the past.
- Engineers design multi-layer networks that learn complex features (like motion direction) from raw, unlabeled sensory streams, potentially extending to vision, audition, and other modalities.
- Deeper ReSU-based networks could support more advanced perception and planning while staying closer to biological reality.
In short, ReSUs show that paying attention to time—what just happened and what will likely happen next—can unlock powerful, layered learning without the usual heavy training tricks, making AI a little more like the brain.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Causality and continuity of temporal filters are not enforced; develop a ReSU learning formulation that guarantees causal, continuous filters consistent with biophysical constraints.
- Memory length and prediction horizon (, ) are chosen a priori; design an online procedure that infers and adapts these hyperparameters from input statistics and task demands.
- Past–future CCA is computed via global covariance whitening and SVD; derive and validate a synaptically local, online algorithm that implements past–future CCA (including whitening) with streaming data and only forward signals.
- Optimality guarantees are proved for OU processes and stationary integrable Gaussian processes; establish theoretical bounds and conditions for non-Gaussian, nonlinear, nonstationary natural stimuli (e.g., heavy-tailed, temporally structured, and nonstationary inputs).
- ReSU filters currently learned without explicit biophysical constraints (ion channel kinetics, synaptic dynamics, saturation); integrate these constraints and assess their impact on learned filters and performance.
- The model uses 1D motion and a three-pixel pooling window; extend to 2D motion with realistic optics (PSF), receptive field geometry, and larger pooling to capture speed tuning and direction selectivity across spatial frequencies.
- Intermediate lamina neurons are collapsed to effective weights; incorporate known interneurons and lateral interactions (e.g., contrast normalization, inhibition) and quantify how they alter learned filters and motion computations.
- Photoreceptor inputs are treated as scalar contrast with limited phototransduction details; include adaptation, dynamic range compression, and noise characteristics of photoreceptors to test robustness of learned filters.
- Second-layer training uses uncentered signals post-rectification; analyze the statistical consequences (bias, whitening quality) and propose centering or alternative normalization compatible with rectified outputs.
- The current two-layer network is trained with constant-velocity translations; evaluate generalization to accelerations, rotations, looming, motion parallax, and naturalistic ego-motion with depth cues.
- Null-direction responses in T4 analogs are suppressed via thresholding; determine biologically plausible mechanisms (inhibitory circuits, gain control) and test their necessity and sufficiency in vivo.
- The “dead leaves” explanation is qualitative; quantitatively test ReSU filters on synthetic dead-leaves movies and controlled edge stimuli to link filter shapes to scene statistics and optics.
- Synaptic weight comparisons to connectomics are qualitative and lack neuronal gain calibration; estimate effective gains and nonlinearity to enable quantitative, absolute comparisons of learned vs. anatomical weights.
- Adaptation to SNR is demonstrated, but the biological timescale, mechanism, and reversibility are not validated; measure ReSU adaptation kinetics against high-temporal-resolution neural recordings (e.g., voltage indicators).
- Hierarchical scaling beyond two layers remains largely untested; systematically stack ReSU layers, quantify emergent invariances and complexity, and benchmark on diverse tasks (e.g., motion segmentation, object tracking).
- Basis selection within the whitened canonical subspace is underdetermined (rotational freedom); specify biologically plausible criteria (sparsity, stability, metabolic efficiency) to resolve degeneracy in feature allocation across neurons.
- Self-supervised learning is claimed to be biologically plausible, yet sample complexity, convergence rates, and stability of online learning are not characterized; provide finite-sample analyses and robustness guarantees.
- Mapping ReSUs to spiking neurons is asserted but untested; implement spiking ReSUs (rate-to-spike conversions, refractory periods, spike noise) and evaluate fidelity and efficiency on neural hardware or neuromorphic platforms.
- The model does not incorporate top-down feedback; develop ReSU-compatible feedback mechanisms (e.g., controller neurons) and test their roles in attention, expectation, and task-guided representation shaping.
- Energy efficiency and data efficiency claims are qualitative; measure computational and energetic costs of ReSU training/inference vs. backprop-trained baselines on standardized benchmarks.
- Online estimation of covariance inverses (e.g., , ) is nontrivial; propose biologically plausible recurrent circuits (e.g., decorrelating interneurons) or plasticity rules to implement whitening.
- Sensitivity to hyperparameters (lag lengths, number of canonical components , regularization strength) is not analyzed; perform ablations and provide guidelines for robust settings across stimuli and tasks.
- Direction selectivity depends on suppressing the projection; verify experimentally whether inhibitory circuits perform such suppression and whether learned filters shift under manipulations of inhibition.
- The model assumes independence of per-pixel signals at the L1–L3 stage; include optical blur and lamina lateral interactions to examine the impact of spatial correlations on learned temporal filters.
- Generalization across image corpora and species is not demonstrated; evaluate ReSU learning on diverse natural scene datasets and test transfer to other sensory modalities (auditory, somatosensory) and organisms.
- Mutual information gains () are presented qualitatively; estimate from finite samples on natural movies and correlate MI with behavioral or neural performance metrics.
- The Koopman/soft-clustering interpretation is speculative; explicitly learn lifted ReSU feature spaces, identify approximate Koopman eigenfunctions, and test predictive control tasks grounded in this framework.
- Robustness under nonstationary environments (e.g., abrupt changes in contrast statistics) is shown qualitatively; formalize change-point detection and adaptive mechanisms within ReSUs, with guarantees on re-learning speed and stability.
- Integration with existing self-supervised objectives (e.g., JEPA, contrastive losses) is conceptually related but untested; compare ReSU-based predictive learning to backprop-trained JEPA/VAMPnets on matched tasks without labels.
Practical Applications
Immediate Applications
Below are concrete, near-term use cases that can be deployed with today’s tools (including the authors’ open-source code) and standard compute. Each item includes target sectors, potential tools/workflows, and key assumptions/dependencies.
- Bio-realistic modeling of early sensory circuits
- Sectors: neuroscience (academia), healthcare (vision science)
- What: Use ReSU to fit and interpret temporal filters and synaptic patterns directly from recorded time series (e.g., calcium/voltage imaging, extracellular recordings) to explain circuit function (e.g., L1/L3/T4-like computations, SNR adaptation).
- Tools/workflows: Apply past–future CCA on recorded sequences; use the provided GitHub code to reproduce 1D motion results and extend to lab data; compare learned weights to connectomic synapse counts (connectomics alignment).
- Assumptions/dependencies: Quasi-stationary stimulus statistics over the analysis window; sufficient data to estimate covariances; choice of memory/horizon (m, h); rate-code approximation for spiking signals.
- Direction-selective motion detection on resource-constrained devices
- Sectors: robotics, drones, embedded vision, AR/VR
- What: Deploy a two-layer ReSU pipeline as a low-compute module for direction-selective motion (T4-like), e.g., optic flow onset detection for collision avoidance or stabilization.
- Tools/workflows: Pretrain temporal and spatial filters on natural videos; deploy inference-only projections + rectification on MCU/FPGA; integrate with event cameras or rolling-shutter streams.
- Assumptions/dependencies: Training stimuli similar to deployment domain (naturalistic motion); 1D-to-2D extension is straightforward but needs engineering; online covariance updates optional but beneficial.
- Self-supervised time-series feature extraction for forecasting and anomaly detection
- Sectors: software, industrial IoT, energy, finance, manufacturing
- What: Use ReSU projections as predictive, whitened latent features for down-stream models (e.g., regressors, control policies), enabling label-efficient forecasting and anomaly detection.
- Tools/workflows: Stream past–future CCA with online covariance estimation; compute rectified ON/OFF channels to detect directional changes; plug ReSU features into existing ML stacks (scikit-learn/PyTorch).
- Assumptions/dependencies: Local second-order statistics informative of future; mild stationarity within windows; regularization for ill-conditioned covariances.
- Adaptive noise-aware filtering for biosignals and audio
- Sectors: healthcare (wearables/monitoring), audio signal processing
- What: Implement SNR-adaptive temporal filters that morph from multi-lobed to single-lobed as noise increases (mirroring physiology), improving robustness of ECG/EEG/sleep staging or voice activity detection.
- Tools/workflows: Estimate SNR on-device; update CCA-derived filters with sliding windows; run rectified channels as robust event detectors.
- Assumptions/dependencies: Reasonable SNR estimation; stable sampling; compliance for clinical applications requires validation.
- Privacy-preserving on-device self-supervision
- Sectors: mobile, smart home, edge computing
- What: Learn predictive features from unlabeled sensor streams (motion, accelerometer, microphone) locally without cloud labels or backprop.
- Tools/workflows: On-device covariance accumulation and SVD (or incremental SVD); inference via linear filters + rectification; discard raw data post-feature extraction.
- Assumptions/dependencies: Compute budget for incremental linear algebra; data retention policies; user opt-in.
- Curriculum and research prototyping platform
- Sectors: academia, education, software
- What: Teach and prototype biologically grounded self-supervised learning via CCA, balanced truncation, and predictive information, using the open-source ReSU implementation.
- Tools/workflows: Jupyter notebooks demonstrating OU/GP examples, SNR adaptation, and motion detection; assignments linking information theory and dynamical systems.
- Assumptions/dependencies: Availability of time-series datasets; basic linear algebra stack.
- Connectomics-informed hypothesis testing
- Sectors: neuroscience (academia)
- What: Use ReSU to generate testable predictions of synaptic sign patterns and functional roles; compare learned filters/weights with EM-derived connectivity.
- Tools/workflows: Fit ReSU to stimulus–response data; compute canonical directions; align with synapse counts after gain normalization.
- Assumptions/dependencies: Intermediate-cell simplifications (e.g., contrast normalization) acceptable; careful interpretation due to unknown gain factors.
- Preprocessing for robust ML pipelines
- Sectors: software, vision, speech
- What: Use ReSU front-ends for temporal whitening and predictive compression before task-specific models, improving robustness to domain shift/noise.
- Tools/workflows: Precompute CCA filters per domain; export as fixed preprocessor; monitor mutual information via canonical correlations as a health metric.
- Assumptions/dependencies: Domain-stationarity within calibration windows; compute for initial SVD fit.
Long-Term Applications
These opportunities require further research, scaling, validation, or development (e.g., deeper stacks, learned memory horizons, hardware co-design, regulatory approvals).
- Deep backprop-free self-supervised networks
- Sectors: software, vision, audio, NLP (sequence modeling), robotics
- What: Stack ReSU layers to build JEPA-like predictive hierarchies with analytical/local updates instead of end-to-end backprop; target data efficiency and reliability.
- Tools/products: ReSU-compatible training frameworks with layerwise CCA; auto-rotation/whitening management; hybrid JEPA/ReSU encoders.
- Dependencies: Generalization beyond 2–3 layers; stability with non-Gaussian, non-stationary data; automatic selection of memory/horizon (m, h).
- Neuromorphic and mixed-signal ReSU hardware
- Sectors: semiconductors, edge AI, defense, aerospace
- What: Implement temporal filtering, whitening, and rectification with analog/digital circuits; local updates approximating CCA via synaptic dynamics and time-constant diversity.
- Tools/products: ReSU SoCs; FPGA IP blocks; event-camera ASICs with direction-selective modules.
- Dependencies: Hardware-efficient online covariance/SVD approximations; precision–power trade-offs; manufacturability.
- Optic-flow and collision-avoidance stacks for micro-UAVs and AR
- Sectors: robotics, consumer electronics, mobility
- What: Multi-directional T4/T5-like arrays for fast optic flow and egomotion estimation under tight power budgets.
- Tools/products: ReSU-based front-end feeding SLAM/VO modules; low-latency control loops.
- Dependencies: 2D extension with wide-FOV sampling; robustness to lighting and texture paucity; integration with IMU.
- Wearables and clinical monitoring with adaptive predictive features
- Sectors: healthcare, medical devices
- What: Self-supervised ReSU front-ends for ECG/EEG/PNS signals that adapt to patient-specific noise and morphology, improving detection of arrhythmia, seizures, or sleep stages without large labeled datasets.
- Tools/products: On-device ReSU library; clinician-facing dashboards with canonical correlation “health” indicators.
- Dependencies: Clinical validation, FDA/CE approval; handling non-stationarity and artifacts; safety monitoring.
- Retinal and cortical prosthetics inspired by ReSU/T4 computations
- Sectors: medtech, neuroengineering
- What: Prosthetic preprocessing that mimics L1/L3/T4 computations (e.g., direction-selective enhancement), potentially improving motion perception.
- Tools/products: Signal-processing modules in implant firmware.
- Dependencies: Biocompatibility; individualized calibration; ethical and regulatory oversight.
- World-modeling for model-based RL via Koopman-aligned ReSU features
- Sectors: robotics, autonomous systems, industrial control
- What: Learn lifted linear predictive subspaces (Koopman-aligned) by ReSU to aid planning and control in partially observed environments.
- Tools/products: ReSU+Koopman pipelines; controllers using linear models in latent space.
- Dependencies: Robustness under actuator/sensor delays; partial observability and switching dynamics; safety constraints.
- Communication-efficient sensor networks
- Sectors: energy, environment, infrastructure
- What: Nodes transmit only innovations/prediction errors from ReSU predictors, reducing bandwidth and energy for long-lived deployments (e.g., pipelines, grids, habitats).
- Tools/products: ReSU firmware for in-sensor processing; network protocols prioritizing predictive surprise.
- Dependencies: Synchronization across nodes; drift handling; intermittent connectivity.
- Policy and standards for low-carbon, label-efficient AI
- Sectors: policy, public funding, sustainability
- What: Use ReSU-style frameworks to motivate programs and benchmarks prioritizing label-free learning and energy efficiency.
- Tools/products: Procurement criteria; standardized “energy-per-bit-of-predictive-information” metrics; public datasets for self-supervised evaluation.
- Dependencies: Cross-agency coordination; industry adoption; lifecycle analyses.
- Automated selection of memory and horizon (m, h) and architectural search
- Sectors: software tooling, AutoML
- What: Learn or adaptively tune lags/horizons per channel/task to maximize future mutual information; dynamic routing across units.
- Tools/products: Auto-ReSU configurators; Bayesian or information-theoretic controllers for lag selection.
- Dependencies: Stable online estimators; non-myopic criteria; computational caps on embedded platforms.
- Spiking ReSU and biologically local learning rules
- Sectors: neuromorphic computing, brain-inspired AI
- What: Map ReSU to spiking neurons with rectifying thresholds; approximate past–future CCA via local synaptic learning (Hebbian/anti-Hebbian) and dendritic time constants.
- Tools/products: Spiking ReSU libraries; Loihi/BrainScaleS deployments.
- Dependencies: Convergence guarantees; calibration of time constants; mapping of whitening to local circuitry.
- Scientific discovery in complex dynamical systems
- Sectors: climate, materials science, systems biology
- What: Use ReSU to extract maximally predictive latent variables from high-throughput time series (e.g., gene expression, turbulence, climate indices) for hypothesis generation.
- Tools/products: ReSU notebooks integrated with domain simulators; MI-based model selection dashboards.
- Dependencies: Handling non-Gaussian/nonlinear regimes; sparse/irregular sampling; scaling to high dimensions.
- Consumer cameras and smart-home motion intelligence
- Sectors: consumer electronics, security
- What: On-device direction-selective motion cues that are robust to noise/illumination for improved tracking and false-alarm reduction without cloud processing.
- Tools/products: ReSU motion modules in ISP pipelines; privacy-preserving analytics.
- Dependencies: Vendor SDK integration; 2D filter banks; long-tail scene robustness.
Cross-cutting assumptions and dependencies
- Statistical regime: Methods assume sufficient local stationarity to estimate past–future covariances; performance degrades with severe non-stationarity unless models adapt online.
- Model class: Optimality proofs hold for OU and broader Gaussian processes; empirical results suggest robustness, but strongly non-Gaussian/nonlinear domains may need deeper ReSU stacks and/or hybrid models.
- Hyperparameters: Memory length m and prediction horizon h must be set (or learned); too-short windows underfit dynamics; too-long windows increase compute and estimation error.
- Compute: Inference is light (linear projections + rectification). Training requires covariance estimation and SVD; streaming/approximate SVD or blockwise updates mitigate cost for edge devices.
- Biological locality: Fully local learning of past–future CCA is not yet standard; prior work on local CCA suggests feasibility but requires extensions to temporal settings.
- Generalization: Paper validates 1D motion detection; 2D and deeper hierarchies are promising but need additional engineering and validation.
Glossary
- Anti-Hebbian: A local learning rule where synaptic strength decreases when pre- and postsynaptic activities are correlated. "local (Hebbian and anti-Hebbian) rules"
- Balanced truncation: A model reduction technique that preserves the most controllable and observable dynamics of a system. "we apply balanced truncation~\cite{katayama2005subspace}"
- Canonical correlation analysis (CCA): A statistical method that finds pairs of directions maximizing correlation between two sets of variables. "canonical correlation analysis (CCA)"
- Canonical correlations: The correlation values between pairs of canonical variates obtained by CCA. "The first column displays the canonical correlations ()"
- Canonical direction: A projection vector learned by CCA that defines a maximally correlated feature between past and future signals. "onto a canonical direction obtained via canonical correlation analysis (CCA)"
- Canonical variates: The projected variables along canonical directions whose correlations are maximized by CCA. "the -th pair of canonical variates, and "
- Connectomic reconstructions: Detailed circuit maps derived from anatomical data (e.g., synapse counts) used to infer wiring patterns. "approximating those derived from connectomic reconstructions"
- Contrast normalization: A computation that rescales inputs to stabilize responses under varying contrast conditions. "the intermediate neurons are thought to primarily implement contrast normalization"
- Dead leaves model: A generative model of natural images composed of overlapping objects with piecewise-constant intensities. "the so-called âdead leaves modelâ of natural images"
- Direction selectivity: Neural tuning property where responses depend on the direction of motion. "develop direction-selectiveâanalogous to T4 motion-detecting cells"
- Equilibrium propagation: A learning framework for energy-based models that approximates gradient-based training through perturbations of network equilibria. "equilibrium propagation\cite{scellier2017equilibrium}"
- Gaussian process (GP): A nonparametric stochastic process defined by a mean function and covariance kernel, used to model distributions over functions. "Gaussian processes (GPs)âspecifically, discrete-time GPs with translation-invariant and integrable covariance kernels"
- Gramian (covariance Gramian): A matrix summarizing cross-covariances between signals, whose eigendecomposition reveals principal predictive directions. "eigendecomposition of the whitened pastâfuture covariance Gramian~\eqref{eq:CCA2}"
- Hebbian plasticity: A local learning rule where synapses strengthen when pre- and postsynaptic activities are correlated. "integrating self-supervised learning (such as contrastive learning), Hebbian plasticity, and predictive coding"
- Information bottleneck: A principle for learning compressed representations that preserve relevant information (e.g., about the future). "Gaussian information bottleneck"
- JEPA: Joint-Embedding Predictive Architecture; a self-supervised approach that learns representations predictive of future latent states. "Our approach is conceptually related to JEPA~\cite{LeCun2022PathAMI}"
- Koopman operator: A linear operator acting on nonlinear dynamical systems by lifting to a higher-dimensional feature space where evolution is linear. "within the Koopman operator framework for nonlinear dynamics"
- Mutual information: A measure of shared information between random variables, quantifying predictive power in this context. "maximizes the mutual information with the future"
- OrnsteinâUhlenbeck (OU) process: A continuous-time Gaussian Markov process modeling linear stochastic dynamics with mean reversion. "a partially observed multivariate OrnsteinâUhlenbeck (OU) process"
- Pastâfuture CCA: Applying CCA between lagged past and future observations to learn predictive temporal filters. "Pastâfuture CCA as a computational primitive applied to different data streams"
- Predictive coding: A computational paradigm where neurons encode prediction errors rather than raw features to infer latent causes. "built on the predictive coding principle"
- Random feedback alignment: A biologically motivated alternative to backpropagation where fixed random feedback weights guide learning. "random feedback alignment \cite{lillicrap2016random,nokland2016direct}"
- Rational quadratic kernel: A GP covariance function with power-law-like behavior that can model multi-scale correlations. "a Gaussian process with a rational quadratic kernel"
- Rectified linear unit (ReLU): A common neural activation function that outputs max(0, x), lacking temporal dynamics. "rectified linear units (ReLUs)"
- Rectified Spectral Unit (ReSU): A neuron model that projects past inputs onto CCA-derived directions and rectifies the output to produce nonnegative features. "Rectified Spectral Unit (ReSU)âa neuron model that projects past input onto a canonical direction and rectifies the projectionâs positive or negative component"
- Singular value decomposition (SVD): A matrix factorization used to compute canonical directions and correlations in CCA. "solved via singular value decomposition (SVD) of the whitened cross-covariance matrix"
- Slow feature analysis (SFA): An unsupervised method that extracts slowly varying features from time series for robust representation learning. "slow feature analysis (SFA)"
- Synaptic weights: Parameters representing the strength of connections between neurons, encoding learned filters or features. "By encoding canonical directions in synaptic weights and temporal filters"
- Temporal filter: A learned kernel that projects past inputs over time to extract predictive components. "developed temporal filters resembling those of Drosophila post-photoreceptor neurons"
- T4 cell: A direction-selective motion detector neuron subtype in the Drosophila visual system’s ON pathway. "T4 motion-detecting cells"
- VAMPnets: Deep learning architectures that learn slow collective variables by maximizing variational scores for dynamical systems. "VAMPnets~\cite{mardt2018vampnets}"
- Whitening: A transformation that decorrelates and scales variables to unit variance, simplifying subsequent learning. "whitened cross-covariance matrix"
Collections
Sign up for free to add this paper to one or more collections.