- The paper introduces FLoPS, an L0-constrained framework that employs probabilistic gates to enforce sparsity in federated learning models.
- It formulates a constrained optimization linking L0 constraints with entropy maximization, ensuring precise density control even under non-IID data and client heterogeneity.
- The paper presents FLoPS-PA, a communication-efficient variant that compresses active parameter indices without compromising predictive performance.
Federated Learning With L0 Constraint Via Probabilistic Gates for Sparsity
Introduction and Problem Setting
This paper addresses fundamental limitations in conventional Federated Learning (FL) concerning model sparsity. Despite FL's success in privacy-preserving distributed learning, classical FL approaches typically produce excessively dense models. This over-parameterization leads to poor generalization in non-IID and heterogeneous client participation regimes, and excessive resource consumption on edge devices. The authors propose an L0-constrained FL framework—FLoPS—that enforces a hard constraint on the proportion of active model parameters by leveraging reparameterization via continuous probabilistic gates.
The paper outlines a constrained optimization problem over the global model's parameters, enforcing ∥θ∥0/∣θ∣≤ρ, where ρ is a pre-specified target density. Handling the L0 pseudo-norm in gradient-based frameworks is non-trivial due to its discontinuity. To circumvent this, the authors employ parameter reparameterization via a set of stochastic binary gates (following the Hard Concrete distribution), as proposed in the context of centralized L0 regularization [Louizos et al., 2017].
A key conceptual contribution is the connection between L0-constrained optimization and entropy maximization over gate state distributions, formalized using Lagrangian duality. This formulation reveals an intrinsic relationship between the sparsity constraint and a variational free energy objective from statistical physics, further connecting FL with mean-field variational inference.
Distributed Algorithms: FLoPS and FLoPS-PA
The core algorithm, FLoPS, utilizes server-coordinated, synchronous updates with reparameterized gradients propagated over both parameter and gate distributions. The updates to gates ϕ and model parameters θ~ are performed collaboratively—with the Lagrange dual λ governing adherence to the sparsity target. The method includes a restart mechanism for λ when the constraint is satisfied, ensuring stable enforcement of the density constraint.
Recognizing the communication bottleneck in FL, the paper introduces FLoPS-PA, a "parameter averaging" variant that dramatically reduces the communication cost by transmitting only indices corresponding to the top-m active parameters (per the learned sparsity), and compressing the associated gate values. This design achieves practical communication efficiency without sacrificing statistical performance.
Experimental Evaluation
Extensive experiments are reported over both synthetic and real-world high-dimensional datasets (RCV1, MNIST, EMNIST), systematically varying data heterogeneity and client participation rates. The evaluation leverages metrics such as True Discovery Rate (TDR), R2, accuracy, and cross-entropy to quantify both sparsity recovery and predictive performance.
The results demonstrate that:
- FLoPS achieves precise control over model density, gradually matching the desired parameter sparsity during training, even for extreme ρ as low as $0.005$.
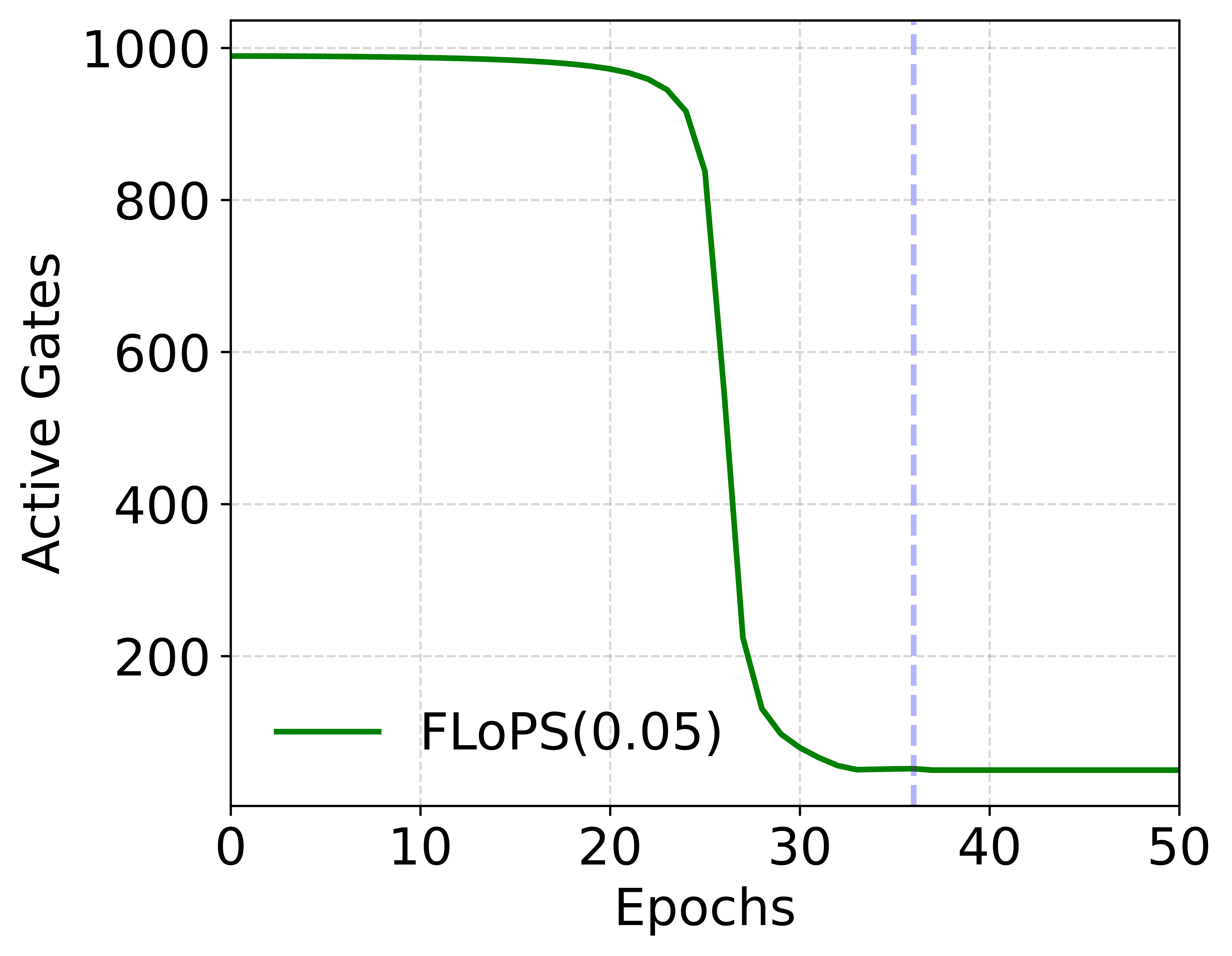
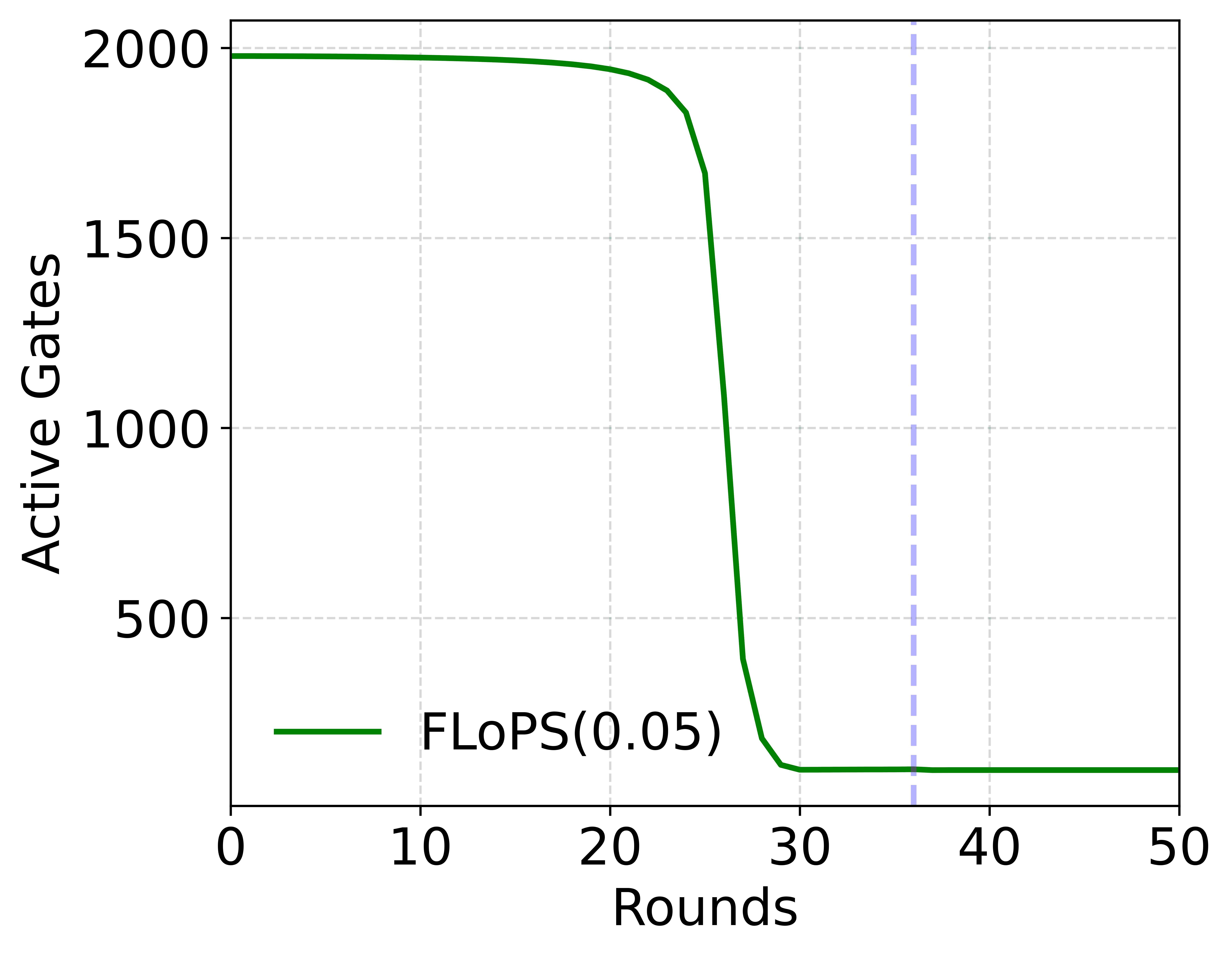
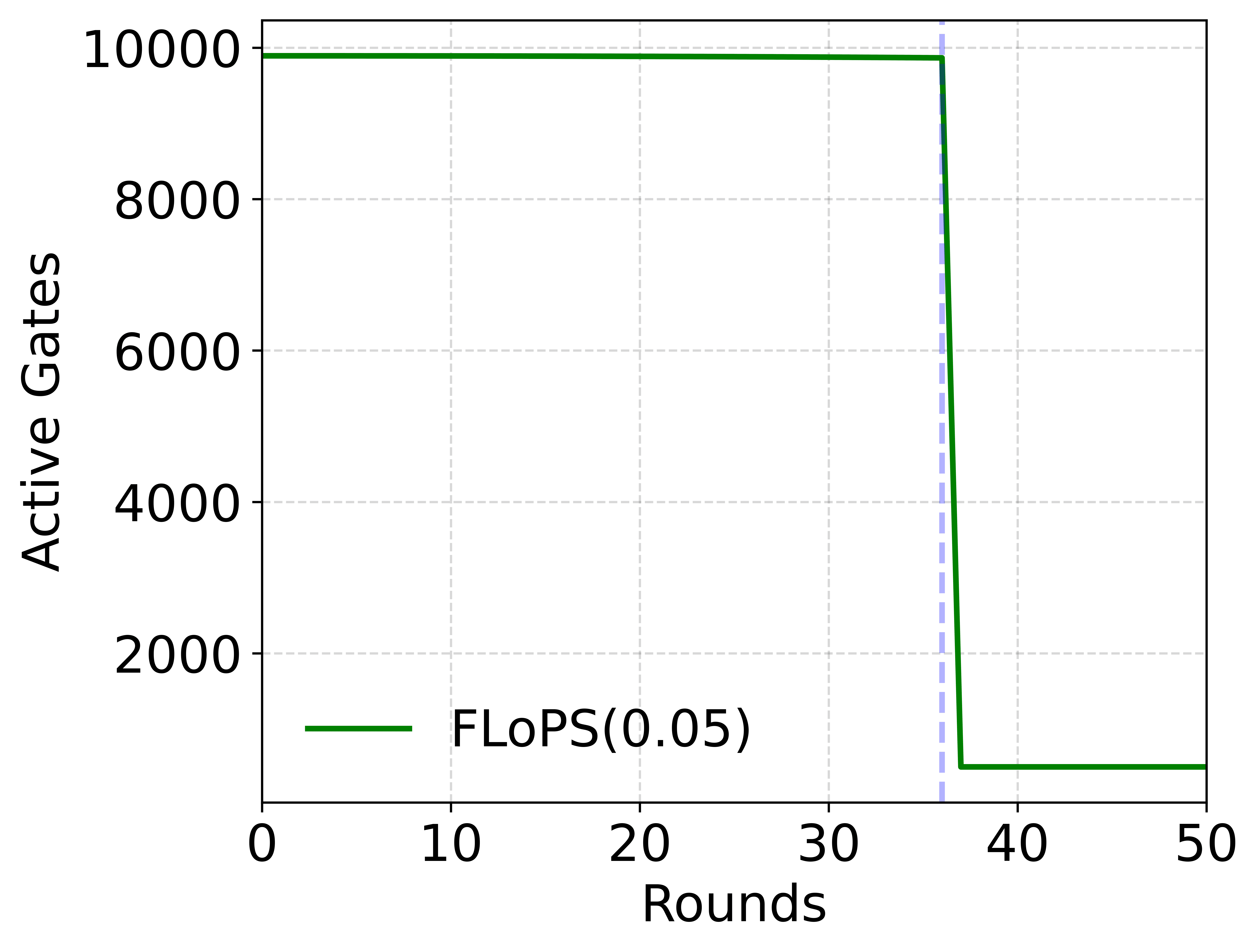
Figure 1: Evolution of the expected number of active gates during training in linear regression, highlighting convergence to the prescribed target density.
- Sparsity recovery (TDR) and statistical performance are consistently superior to magnitude-based iterative thresholding (FedIter-HT), particularly under high data heterogeneity, low client participation, and high correlations in features.
- Communication savings with FLoPS-PA are substantial, especially for large models and very low ρ. This variant achieves efficient training with only a minor tradeoff in performance, outperforming dense FedAvg approaches when magnitude pruning is deferred to post-training.
- Dynamic patterns of sparsity emerge during training, as visualized by the soft Jaccard/IOU heatmaps of the active gates. FLoPS first explores the parameter space, then rapidly settles into a stable, high-performing configuration, in contrast to more erratic patterns seen with FedIter-HT.
Theoretical and Practical Implications
This work provides a formal bridge between energy-based modeling, variational inference, and sparsity-constrained distributed optimization. By embedding the L0 constraint into the probabilistic gate mechanism, it enables precise, differentiable control over sparsity and offers a principled alternative to heuristic or magnitude-based pruning. The experimental findings suggest that enforcing explicit density constraints during FL training is substantially more robust than post hoc sparsification—especially important for resource-constrained clients and communication-efficient FL settings.
On a practical level, the methods are directly applicable to high-dimensional tasks (e.g., NLP, vision), and the compression mechanism can benefit deployment across severely bandwidth/compute-limited networks. The capacity of FLoPS/FLoPS-PA to maintain generalization under severe non-IID data and low active density thresholds indicates immediate relevance for on-device intelligence (e.g., smartphones, IoT).
Future Directions
Potential avenues for extension include:
- Decentralized FL architectures: FLoPS currently assumes centralized orchestration; generalization to decentralized protocols promises broader applicability.
- Richer model classes: Extension to structured sparsity, group sparsity, or convolutional architectures.
- Adaptive/learned sparsity schedules: Dynamically adjusting ρ during training for improved generalization or resource adaptation.
- Theoretical analysis: Formal convergence and generalization bounds under probabilistic gating and nonconvex landscapes.
Conclusion
The paper introduces a theoretically principled, communication- and computation-efficient FL method enforcing hard sparsity constraints via probabilistic reparameterization. The FLoPS framework achieves significant improvements in statistical performance, precise sparsity, and communication efficiency over magnitude-based alternatives, particularly under heterogeneous and lossy participation. The theoretical unification with entropy maximization, variational inference, and the detailed empirical analysis together present a comprehensive advance for practical, scalable federated learning in resource-constrained environments.

