- The paper introduces a structural-simulation hybrid approach that combines DSGE-simulated synthetic data with transformer sequence learning for robust macroeconomic forecasts.
- The methodology leverages separate-then-concatenate embeddings and modularized output forecasting to efficiently model small-sample, multivariate time series.
- Experimental results show stable out-of-sample predictions that capture ordinal macroeconomic dynamics, even during turbulent periods.
Introduction
This paper presents a new framework for macroeconomic forecasting that addresses the fundamental data limitations inherent in macroeconomic time series by integrating theory-consistent synthetic data generation and transformer-based sequence modeling. Classical deep learning models, notably transformers, have achieved remarkable performance in large-sample domains, but macroeconometrics is defined by small-sample, multivariate sequences. The methodology leverages dynamic stochastic general equilibrium (DSGE) models as high-fidelity simulators, enabling the generation of millions of synthetic macroeconomic trajectories. Mixing these theory-driven simulations with historical data, the approach trains a specialized, compact transformer model to forecast multiple aggregate variables. This structured hybrid procedure unites Bayesian structural modeling with deep learning, producing models that are theoretically grounded and empirically flexible.
Methodology
Data Partitioning and DSGE Model Specification
The approach initiates by partitioning the quarterly U.S. macroeconomic dataset (1947:Q3–2025:Q2) into three subperiods: a segment for DSGE parameter estimation (pre-1960), one for transformer training (1960–2017), and a strictly out-of-sample test period (2017:Q4–2025:Q2). This orthogonalization ensures that simulation and empirical forecasting are independently informed.
A medium-scale DSGE model in the Smets-Wouters (SW07) tradition is augmented with stochastic volatility and Student-t innovations, capturing observed macroeconomic nonlinearities, regime shifts, and shock heteroscedasticity that are critical for realistic scenario modeling. Bayesian estimation delivers posterior draws from the parameter space, embracing model uncertainty in synthetic data generation. Rather than relying on a point estimate, the model generates 104 synthetic trajectories, each 1,000 quarters long, by drawing parameters from the estimated posterior and simulating forward. These synthetic panels manifest a multidimensional uncertainty surface, embedding both standard macroeconomic propagation channels and rare, high-impact events.
The architecture adapts standard transformer mechanisms for multivariate time series. Two primary modifications are highlighted:
- Separate-then-concatenate embeddings: Each macroeconomic variable is discretized via percentile-based binning and embedded independently; resulting embeddings are concatenated to form the multivariate state input. This design controls parameter growth and enables efficient cross-variable attention without an infeasible combinatorial explosion in vocabulary size.
- Output modularization: Forecasting is delegated to a set of seven variable-specific transformers rather than a single high-dimensional output layer. Each module receives complete multivariate histories and predicts the next period's value for a single variable, reducing dimensionality and improving stability.
Training is conducted with mixed batches: 10% real observations, 90% synthetic. This departs from conventional pretraining/fine-tuning regimes—critical given extreme data imbalance; empirical signals from historical data are enforced via mixing from the outset, tightly coupling the learning of empirical and theoretical patterns. The mixing ratio effectively parallels a prior-likelihood weighting in Bayesian updating, and its hyperparameterization can be tuned to balance theoretical discipline with empirical flexibility.
Tokenization and Regularization
Percentile-based tokenization regularizes learning and reflects practical decision granularity relevant for policy analysis. Each input series is partitioned into 10 bins; this robust discretization yields balanced token frequencies and encodes ordinal relationships that are critical in macroeconomic judgment (e.g., distinguishing 'low' vs. 'high' inflation) while suppressing noise from measurement imprecision.
Numerical Results
The empirical evaluation targets out-of-sample forecasts for seven U.S. macroeconomic aggregates, including both persistent level variables (hours worked, inflation, interest rate) and more volatile growth rates (output, consumption, investment, wage).
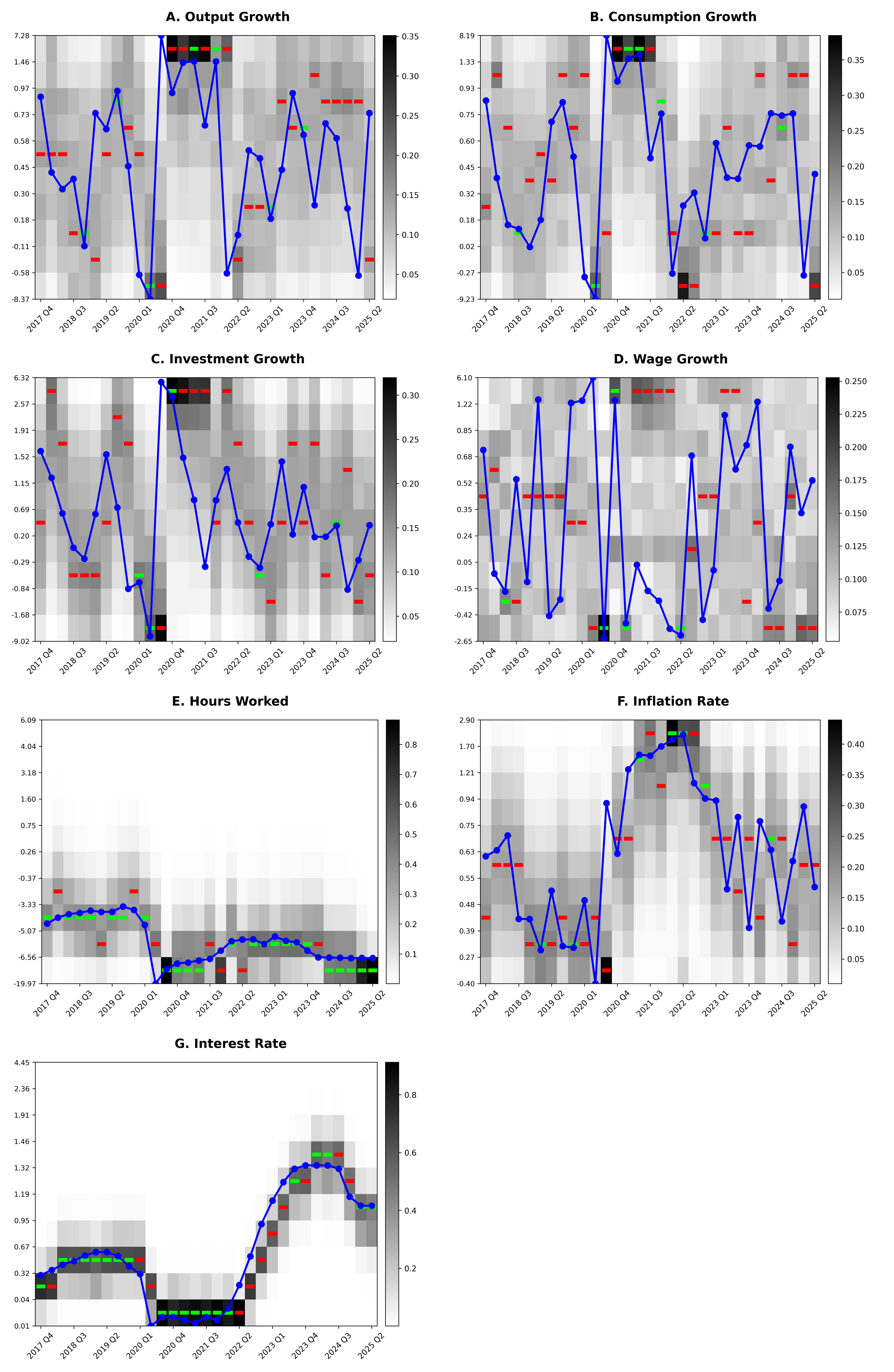
Figure 1: Out-of-sample predictions for seven macroeconomic variables, 2017:Q4–2025:Q2.
The predicted token distributions, mapped onto percentile bins, are visualized as probabilistic heatmaps. The model exhibits sharp predictive confidence in stable periods, with broader predictive spreads during turbulent episodes (e.g., the COVID-19 pandemic, inflation surges). Notably, most prediction errors are adjacent-token misclassifications rather than large outliers, indicating that the model has captured the underlying ordinal macroeconomic structure.
Performance is systematically stronger for variables with high persistence and mean-reverting dynamics—specifically hours, inflation, and the policy rate—corroborating both the intrinsic signal-to-noise differentiation among macro aggregates and the architecture's ability to exploit this regularity. Growth rate variables, which are by construction more idiosyncratic and less autocorrelated, present greater predictive difficulty but still yield plausible probabilistic outputs.
The modularized architecture, compact at approximately 50,000 parameters, achieves rapid convergence with minimal computational requirements, signifying that with theory-consistent augmentation, macroeconomic forecasting does not necessitate the scale of typical LLMs.
Theoretical and Practical Implications
This structural-simulation hybrid brings multiple implications:
- Theoretically, the model interprets the transformer as a hierarchical posterior updater, with the DSGE-based synthetic data constituting a structured prior and mixed training corresponding to empirical Bayesian updating. The transformer learns beyond linearized equilibrium restrictions by discovering nonlinear, cross-variable state transitions not specified a priori in classical macro models.
- Methodologically, the work offers a pathway for integrating simulation-based priors into deep learning, generalizable to other domains where real-world observations are severely limited but agent-based or physics-based simulators exist.
- Practically, the model's probabilistic outputs are aligned with risk-aware policy analysis, supporting robust decision-making under model and parameter uncertainty. The flexibility to modulate the theory-data trade-off is valuable for sensitivity analysis and stress testing under alternative scenarios.
The approach also hints at avenues for further development: transformer variants could target multi-horizon or probabilistic scenario forecasts; DSGE-simulation ensembles could address model structure misspecification; and amortized likelihood surrogates could facilitate joint structural estimation and forecasting.
Conclusion
This paper demonstrates that transformer sequence models, correctly regularized and hybridized with theory-driven synthetic data, can learn a "macroeconomic language" that affords strong and stable out-of-sample forecasting of key aggregates. The framework balances theoretical discipline and data-driven flexibility, offering a reproducible path to robust forecasting in small-sample domains. The paradigm has implications for the broader design of AI systems in social sciences: domain-specific simulators can be harnessed to produce structured priors for deep sequence models, mitigating limits inherent to pure data scaling. As diminishing returns from large-scale LLMs emerge, the integration of economic/scientific structure through simulation-based regularization may represent a key direction for advancing both the theoretical and practical frontiers of AI forecasting.