Towards Better Search with Domain-Aware Text Embeddings for C2C Marketplaces
Abstract: Consumer-to-consumer (C2C) marketplaces pose distinct retrieval challenges: short, ambiguous queries; noisy, user-generated listings; and strict production constraints. This paper reports our experiment to build a domain-aware Japanese text-embedding approach to improve the quality of search at Mercari, Japan's largest C2C marketplace. We experimented with fine-tuning on purchase-driven query-title pairs, using role-specific prefixes to model query-item asymmetry. To meet production constraints, we apply Matryoshka Representation Learning to obtain compact, truncation-robust embeddings. Offline evaluation on historical search logs shows consistent gains over a strong generic encoder, with particularly large improvements when replacing PCA compression with Matryoshka truncation. A manual assessment further highlights better handling of proper nouns, marketplace-specific semantics, and term-importance alignment. Additionally, an initial online A/B test demonstrates statistically significant improvements in revenue per user and search-flow efficiency, with transaction frequency maintained. Results show that domain-aware embeddings improve relevance and efficiency at scale and form a practical foundation for richer LLM-era search experiences.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Brief overview
This paper is about making search better on Mercari, a big app in Japan where people sell items to each other. The authors trained a smarter language tool (called a text-embedding model) that understands marketplace words and product names more like a human would. Their goal was to find the most relevant items faster, even when people type short or unclear queries like “switch” or “coach,” and to do it efficiently so the app stays fast.
Key objectives and questions
The paper focuses on simple but important questions:
- How can we make search results match what users really mean when their queries are short or confusing?
- Can the model learn marketplace-specific meanings (for example, “Coach” the fashion brand instead of “sports coach”)?
- Can we compress the model so it runs quickly, without losing too much accuracy?
- Does this improved model actually help users and the business in real life?
Methods used
What is a “text embedding”?
A text embedding is a way to turn words and sentences into a list of numbers (a “vector”) so a computer can compare them. If two texts have similar meanings, their vectors are close together. This helps the system find items that “mean” the same thing as your query, even if they don’t use exactly the same words.
How they taught the model
They started with a strong Japanese LLM and fine-tuned it using real Mercari data:
- They collected pairs of “query” and “item title” where the user actually bought the item. This teaches the model what kinds of results lead to purchases.
- They added a small label at the start of each input—like “Query:” for searches and “Passage:” for item titles—so the model knows whether it’s reading a user’s search or a product listing. This helps it treat queries and items differently.
- They used a training method called Multiple Negatives Ranking. Imagine a matching game: for each query, there’s one correct item title, and all the other titles in the batch are treated as “wrong” matches. This pushes the model to separate correct matches from similar-but-wrong ones.
Making embeddings small and still smart (Matryoshka)
Big vectors (like 768 numbers) are accurate but slow in production. Mercari needs small vectors (like 32 numbers) to search quickly for millions of items. To keep accuracy while making vectors small, they used Matryoshka Representation Learning.
Think of Russian nesting dolls (“Matryoshka dolls”): the biggest doll includes everything, but the smaller dolls still carry the most important parts. The training encourages the first few numbers in the vector to hold the most useful information, so even if you “cut off” the rest to make it shorter, the model still works well.
How they tested it
They checked the model in three ways:
- Manual review: side-by-side comparisons of search results, focusing on brand names, marketplace meanings, and which words in a query matter most.
- Offline logs: replaying past searches to see if the model ranks better items toward the top. They used standard scores like precision, recall, and nDCG (which measures how high the good items appear in the results list).
- Public benchmark: testing general Japanese sentence similarity (called STS) to make sure the model didn’t “forget” general language skills during fine-tuning.
They also ran online A/B tests on the real app to see if users bought more, clicked better results earlier, and needed fewer scrolls to find what they wanted. Finally, they tried “hybrid retrieval,” which mixes classic keyword matching with the new meaning-based matching.
Main results and why they matter
- Better ranking with full-size vectors: The fine-tuned model consistently improved ranking metrics over a strong baseline. In simple terms, it put the right items higher up.
- Big gains with small vectors: The new training plus Matryoshka truncation made 32-number vectors much better than the old 32-number approach that used PCA (a simple compression method). In fact, the ranking score almost doubled compared to the old compressed setup. This is important because small vectors keep the system fast at large scale.
- Smarter marketplace understanding:
- Proper names: For “Switch,” it favored Nintendo Switch items, not light switches.
- Brand meanings: For “coach,” it preferred COACH-brand bags instead of sports coaching.
- Word importance: For “ultra rare CHANEL belt,” it focused on “belt” first, then “CHANEL,” and didn’t get distracted by “rare.”
- Challenge areas: Both models still struggled with tricky requests like “not too flashy.”
- General language skills still strong: On the public Japanese STS test, the fine-tuned model stayed close to the baseline, showing it didn’t forget general language understanding.
- Real-world impact (A/B tests):
- Users reached relevant items sooner: They clicked good results earlier and needed fewer item views before engaging.
- Business metrics improved: Average revenue per user and average order value went up by just under 1%, which is meaningful at Mercari’s scale.
- Hybrid retrieval helped even more: Mixing keyword and meaning-based results improved conversion and recovered a lot of pages that would otherwise have had zero or very few results.
Overall, the new model made search more accurate and efficient, and it delivered measurable gains both for users and the marketplace.
Implications and impact
For a big app like Mercari, even small percentage improvements mean better experiences for millions of users. This research shows that:
- Teaching the model marketplace-specific meaning (brands, item types, and what matters in a query) makes search feel smarter and more helpful.
- Compressing embeddings the right way (Matryoshka) keeps the app fast without giving up quality.
- The approach creates a strong base for future features, like:
- More powerful chat assistants that understand shopping needs,
- Personalized search that adapts to each user,
- Natural-language exploration (“Show me wedding accessories that are elegant but not flashy”),
- Multimodal search that uses text and images together.
There’s still room to grow—especially for complex requests, negation (“not X”), and soft style preferences—but this work is a practical step toward modern, meaning-aware search that helps people find the right items quickly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide future research and engineering work:
- Data positives: Using only purchase-driven query–title pairs may bias representations toward high-priced or highly convertible items; does incorporating non-purchase relevance (e.g., add-to-cart, dwell, repeat views) improve balance without diluting signal?
- Label noise: How often do purchases within a query session reflect accessory or serendipitous buys rather than the query’s intended item, and can filtering or reweighting reduce this noise?
- Negatives: In-batch negatives likely contain false negatives for popular or co-bought items; what is the impact of curated/hard negatives (e.g., near-duplicates, compatible-but-not-core accessories) or debiased negative sampling?
- Objective design: Would multi-task training (e.g., attribute/constraint prediction, taxonomy classification) or pairwise ranking with calibrated margins outperform MNR alone?
- Prefix strategy: Role-specific prefixes helped; would separate encoders or asymmetry-aware projection heads bring further gains, and what are the latency/quality trade-offs?
- Matryoshka configuration: The paper does not detail schedules or weights ; what design yields the best quality-per-byte, and how low (e.g., 16d) can truncation go before material quality loss?
- Compression baselines: PCA is a strawman for 32d; how do product-quantization (IVF-PQ), scalar quantization, or distillation to small encoders compare to MRL at equal memory/latency?
- ANN retrieval tuning: No analysis of vector index settings (e.g., HNSW ef/search, M) vs. recall/latency; what configurations optimize end-to-end throughput under traffic spikes?
- Hybrid retrieval policy: The 0.90 similarity threshold is presented without sensitivity analysis; how do dynamic thresholds, per-intent thresholds, or score calibration affect zero/low-hit recovery and precision?
- End-to-end retrieval impact: Offline evaluation reuses baseline candidate sets; what is the true recall/precision when the fine-tuned embeddings are used as the primary retriever rather than as features?
- Segment-level effects: Which query and user segments (tail vs. head, cold-start users, device, language variants) benefit or regress, and how should models be specialized?
- Category-specific behavior: Are gains uniform across categories (fashion, electronics, collectibles), and do category-aware adapters or MoE routing further improve proper-noun/brand handling?
- Complex intents: Both models struggled with negation and soft style constraints; can instruction-style contrastive tuning, counterfactual negatives, or LLM-generated constraint pairs reduce these failures?
- Term-importance calibration: Improvements are qualitative; can explicit token/attribute weighting losses or attribution-guided training stabilize importance across queries?
- Personalization: The model is non-personalized; how much lift arises from user-conditioned embeddings or session-aware encoders under strict latency budgets?
- Temporal drift: No analysis of re-training cadence; how quickly do embeddings decay with fast-moving inventory, trends, and new releases (e.g., Switch 2) and what is the optimal refresh schedule?
- Robustness: How resilient are embeddings to listing spam, keyword stuffing, adversarial misspellings, or obfuscations common in C2C titles?
- Code-switching and variants: Japanese queries often include romaji, English brand names, emojis, and colloquialisms; what is performance on code-switched or non-standard inputs?
- Multimodality: Manual review used images but the model is text-only; what is the incremental value of adding image embeddings or OCR signals for noisy titles?
- Constraint-aware retrieval: Can the system incorporate structured constraints (price range, condition, compatibility) at embedding time to reduce post-filter mismatch?
- Fairness and seller impact: Do embeddings systematically favor established brands or high-priced items, affecting seller exposure fairness and platform diversity?
- Economic outcomes: ARPU and AoV increased while ATPU did not; is the model shifting demand toward higher-priced items, and what are long-term effects on liquidity and repeat purchase?
- A/B test duration and external factors: The initial 7-day test may be sensitive to seasonality or promotions; do effects persist over longer horizons and across traffic regimes?
- Metric coverage: Offline metrics emphasize nDCG/precision/recall; what about diversity, subtopic coverage, category consistency, and exploration vs. exploitation trade-offs?
- Generalization: STS drops were small, but task breadth is narrow; how do embeddings transfer to other Japanese IR tasks (QA, FAQ, intent classification) or to other locales/languages?
- Interpretability: Term-importance gains are anecdotal; can we quantify explanation faithfulness (e.g., gradient-based attribution alignment) and expose interpretable signals for debugging?
- Training details and reproducibility: Key hyperparameters, augmentations, and ablations (batch size, temperature, learning rate schedule, tokenizer behavior) are not reported; what settings are necessary to reproduce results?
- Data governance: The work relies on purchase logs; what privacy safeguards, consent mechanisms, and data retention policies are in place, and how do they constrain future training?
- Model release and benchmarking: Without public data/models, external validation is impossible; can a sanitized benchmark of Japanese C2C queries/titles be released to foster comparability?
- System-level efficiency: The paper lacks concrete latency, throughput, and cost measurements for 768d vs. 32d and for hybrid retrieval; what are the production SLO trade-offs at peak?
- Failure taxonomy: Beyond a few examples, there is no systematic error analysis; which failure classes (brand confusion, accessory over-ranking, cross-category drift) dominate and how should sampling focus on them?
- Index freshness: New or edited items are encoded synchronously; what is the staleness window, and does embedding lag degrade freshness-sensitive queries?
- Blending and deduplication: How are lexical and semantic candidates merged and de-duplicated across SERP modules, and do blending errors cause regressions (e.g., near-duplicate floods)?
- Alternatives to MNR: Would distillation from a cross-encoder teacher, synthetic pair generation via LLMs, or curriculum learning on increasingly hard negatives yield larger gains?
- Low-resource efficiency: Can further dimensionality or quantization reductions (e.g., 8–16d, 4–8 bit) preserve most gains for edge deployments or cost-sensitive tiers?
Practical Applications
Immediate Applications
The following applications can be deployed now based on the paper’s results, with sector links, potential tools/workflows, and feasibility notes.
- Domain-aware query–item embeddings in C2C search (e-commerce)
- Use case: Replace generic embeddings in marketplace search with the fine-tuned, prefix-conditioned encoder to lift relevance and revenue.
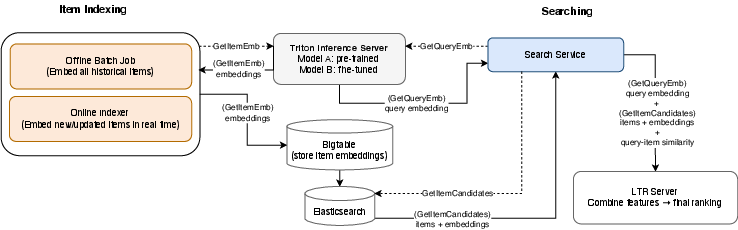
- Tools/workflows: MNR fine-tuning on purchase-driven pairs; role-specific prefixes (“Query:” and “Passage:” in Japanese); Triton model serving; integration as continuous features to LTR (cosine similarity + raw vectors).
- Evidence: ARPU +0.92% (p<0.05), AoV +0.91% (p<0.05); better nDCG/precision/recall offline; improved Item Tap Rank and reduced impressions per engagement.
- Assumptions/dependencies: Access to purchase-labeled query–title pairs; Japanese tokenization and prefix conventions; existing LTR pipeline.
- Replace PCA compression with Matryoshka truncation at 32-D (software infrastructure, e-commerce)
- Use case: Cut latency and storage while maintaining retrieval quality by using MRL-trained nested embeddings instead of PCA-compressed vectors.
- Tools/workflows: MRL training with nested objectives; truncate to 32-D servings; Bigtable feature store and ES indexing; ANN search.
- Evidence: ~2× nDCG@100 vs PCA baseline; large lifts in precision/recall under 32-D constraints.
- Assumptions/dependencies: Ability to retrain encoders with MRL; acceptance of small general-language STS drops; vector infra capable of handling reindexing.
- Hybrid retrieval (dense + sparse) to recover low/zero-hit SERPs (e-commerce search operations)
- Use case: Blend BM25 candidates with semantic candidates above a calibrated similarity threshold (e.g., >0.90) to improve coverage and conversion.
- Tools/workflows: Dual-stage retrieval; thresholding logic in “best-match” module; monitoring of zero/low-hit recovery rates.
- Evidence: Zero-hit recovery 60.2%, low-hit recovery 66.1%; BCR +0.88%, ATPU +0.96% on BM module; UIV +12% on low-hit SERPs.
- Assumptions/dependencies: Robust ANN index; threshold calibration; safeguards for semantic drift; logging/analytics for long-tail queries.
- Proper-noun and brand disambiguation in search and browse (e-commerce merchandising)
- Use case: Improve retrieval for brand- and character-heavy categories (e.g., COACH vs “coach”) to align with marketplace semantics.
- Tools/workflows: Domain-aware encoder; targeted QA on brand-rich taxons; synonym suppression via semantic similarity checks.
- Evidence: Manual assessments show stronger proper-noun handling and marketplace-specific semantics.
- Assumptions/dependencies: Continual monitoring for domain drift; curation of evaluation sets with proper nouns.
- Query understanding and term-importance alignment (e-commerce, UX)
- Use case: Calibrate retrieval to prioritize core descriptors over generic modifiers (e.g., belt > brand > rare) to surface the intended items earlier.
- Tools/workflows: Prefix-conditioned encoder; LTR reweighting using embedding-derived features; offline log replay for alignment checks.
- Evidence: Qualitative review shows better term weighting for marketplace-relevant signals.
- Assumptions/dependencies: Mixed-intent sessions require careful metric design; guardrails against overfitting rare modifiers.
- Search-flow efficiency improvements (product analytics, e-commerce)
- Use case: Reduce effort-to-engagement (fewer impressions, earlier taps) by swapping embeddings in existing ranking stacks.
- Tools/workflows: A/B testing; Item Tap Rank and impression-per-engagement instrumentation; rollout via Triton routing.
- Evidence: Item Tap Rank −0.65% and impressions −0.64% (p<0.05).
- Assumptions/dependencies: Stable traffic allocation; consistent SERP surfaces across buckets; seasonality controls.
- Seller listing assistance: title optimization from purchase-driven signals (e-commerce tools)
- Use case: Suggest high-converting title phrases to sellers derived from query–title pairs that led to purchases.
- Tools/workflows: Embedding similarity between seller draft titles and high-performance exemplars; auto-suggest in listing UI.
- Assumptions/dependencies: Privacy-safe aggregation of purchase logs; safeguards against keyword stuffing; feedback loops to prevent marketplace spam.
- Near-duplicate and spam moderation using semantic similarity (platform trust and safety)
- Use case: Identify duplicates or misleading listings by measuring embedding similarity between titles across inventory.
- Tools/workflows: Batch inference; similarity thresholds for moderation queues; human-in-the-loop review.
- Assumptions/dependencies: Clear policy definitions of duplication/misrepresentation; escalation tooling; multilingual support if needed.
- Internal evaluation framework for domain-aware embeddings (academia/industry R&D)
- Use case: Adopt the paper’s multi-pronged evaluation (offline graded logs, manual assessment, public STS) to avoid catastrophic forgetting while optimizing in-domain metrics.
- Tools/workflows: Temporal hold-outs; graded feedback signals (purchase > like > comment > click > view); stakeholder workshops.
- Assumptions/dependencies: Access to historical logs; domain experts for qualitative reviews; reproducible splits.
- Cost-aware deployment pattern for semantic search (software/platform engineering)
- Use case: Serve compact embeddings via Triton, index in Bigtable/ES, and route model variants by bucket for safe rollouts.
- Tools/workflows: Triton multi-model hosting and traffic routing; batch preindexing; synchronous embedding generation on write.
- Assumptions/dependencies: MLOps maturity; infra observability; rollback plans.
- General text-similarity utilities across marketplace workflows (operations)
- Use case: Use embeddings beyond search for content deduplication, catalog linkage, and customer support triage.
- Tools/workflows: Cosine-similarity services; lightweight APIs to compare titles/descriptions; threshold tuning per task.
- Assumptions/dependencies: Acceptable STS performance at truncated dims; domain calibration for each workflow.
Long-Term Applications
These applications require further research, scaling, or development and can build on the paper’s methods and findings.
- Agentic conversational shopping assistants (e-commerce, LLMs)
- Use case: Power natural-language exploratory search, Q&A, and guided buying with LLMs using domain-aware embeddings as retrieval/backbone.
- Tools/workflows: RAG stacks with domain-tuned retrievers; session memory; tool-use policies (e.g., price filters, compatibility).
- Dependencies: Robust handling of nuanced constraints (negation, soft styles); safety/guardrails; multimodal grounding (text + image).
- Real-time personalization in search and discovery (recommendation systems)
- Use case: Session-level re-ranking and intent blending using embedding signals (exact lookup vs accessories vs substitutes vs deals).
- Tools/workflows: Streaming feature pipelines; per-session encoder conditioning; bandit or RL-based ranking.
- Dependencies: Low-latency inference; privacy-preserving user modeling; online learning infrastructure.
- Multimodal marketplace embeddings (e-commerce, computer vision)
- Use case: Joint text–image embeddings to resolve ambiguous queries and improve visual matching of items and accessories.
- Tools/workflows: CLIP-like training with MNR/MRL extensions; multimodal hybrid retrieval; image-aware LTR features.
- Dependencies: Image data quality; GPU training at scale; robust evaluation for cross-modal alignment.
- Domain-adapted embeddings for other verticals (healthcare, legal, education, finance)
- Use case: Apply role-specific prefixes and MNR/MRL to specialized corpora (e.g., query: symptom→passage: clinical note; query: statute→passage: case law).
- Tools/workflows: Vertical-specific positive pairs (e.g., validated diagnoses, citations, learning outcomes); compact vectors for low-latency search.
- Dependencies: High-quality labeled pairs; compliance and privacy (HIPAA/GDPR); domain expert evaluation.
- Improved handling of nuanced intents (negation, soft constraints, style) (IR research, e-commerce)
- Use case: Incorporate instruction-tuned encoders or cross-encoders on top of dense retrieval to honor constraints (e.g., “not too flashy”).
- Tools/workflows: Weak supervision from LLMs; pairwise re-ranking layers; counterfactual data augmentation.
- Dependencies: Careful objective design to avoid overfitting; computational budget for cross-encoders; evaluation sets capturing nuance.
- Federated or on-device compact retrieval (privacy-preserving AI)
- Use case: Utilize 32-D truncation-robust embeddings for on-device query encoding and federated training to protect user data.
- Tools/workflows: Edge inference libraries; federated averaging with differential privacy; compressed vector indices.
- Dependencies: Device capabilities; privacy constraints; synchronization with server-side indices.
- Marketplace analytics and policy audits for ranking fairness and transparency (policy, governance)
- Use case: Establish audits that track accessory-overranking biases, brand disambiguation quality, and zero-hit recovery as consumer-protection metrics.
- Tools/workflows: Metric dashboards; routine A/B testing protocols; transparency reports for regulators and users.
- Dependencies: Agreement on fairness definitions; data retention and anonymization policies; cross-functional governance.
- Compatibility and bundling discovery (e-commerce merchandising)
- Use case: Use semantic proximity to discover compatible accessories and bundle recommendations (e.g., console + matching case).
- Tools/workflows: Graph construction from embedding neighborhoods; bundle scoring; UI experiments on bundle placement.
- Dependencies: Accurate product-relationship signals; validation to avoid irrelevant bundling; seasonality awareness.
- Cross-lingual marketplace search (global expansion)
- Use case: Extend approach to multilingual settings via synthetic supervision and language adapters to serve cross-border buyers/sellers.
- Tools/workflows: Multilingual encoders; language-specific prefixes; translation-aware retrieval flows.
- Dependencies: Training data across languages; quality translation resources; localized evaluation and UX.
- Standardized methodology and open tooling for domain-aware embedding training (academia/OSS)
- Use case: Package MNR+prefix+MRL recipes with evaluation harnesses (offline logs + STS + qualitative review) for reproducible domain adaptation.
- Tools/workflows: Open-source training scripts; benchmark suites; tutorial datasets (where permissible).
- Dependencies: Licensing and data-sharing constraints; community maintenance; alignment with emerging embedding standards.
- Marketplace seller education and listing quality policies (policy/daily life)
- Use case: Provide guidance and automated prompts that align seller titles with buyer search behavior to improve matching and reduce friction.
- Tools/workflows: Embedded tips in listing forms; periodic best-practice updates; automated checks against low-quality patterns.
- Dependencies: Clear marketplace rules; monitoring to prevent gaming; feedback channels for sellers.
- Demand-supply insights for pricing and inventory (analytics/finance)
- Use case: Use aggregated embedding neighborhoods to detect emerging demand clusters and inform dynamic pricing or sourcing.
- Tools/workflows: Cluster analysis on compact vectors; time-series monitoring; integration with pricing tools.
- Dependencies: Robust anomaly detection; guardrails against overreacting to short-term spikes; ethical pricing policies.
In all cases, feasibility hinges on data quality (purchase-driven positives and robust negatives), scalable vector infrastructure (indexing, serving, monitoring), privacy and compliance for log usage, and careful metric design to balance in-domain gains with general-language retention.
Glossary
- A/B test: An experimental method that splits traffic into control and treatment to compare performance of system variants. "We conducted a seven-day online A/B test to evaluate the impact of fine-tuned, domain-aware text embeddings on real user search behavior."
- agentic assistants: LLM-driven systems that can autonomously plan and act on behalf of users in search/e-commerce contexts. "enabling LLM-era experiences such as agentic assistants, real-time personalization, and natural-language exploratory search."
- BM25: A classic sparse retrieval algorithm using term frequency and inverse document frequency to rank documents. "for each BM25-retrieved candidate pair, both cosine similarity and raw vectors served as continuous LTR features."
- catastrophic forgetting: A phenomenon where fine-tuning on a new task degrades a model’s performance on previously learned tasks. "to assess general-language retention in Japanese and detect catastrophic forgetting"
- cosine similarity: A measure of similarity between vectors based on the cosine of the angle between them, used in embedding retrieval. "both cosine similarity and raw vectors served as continuous LTR features."
- C2C marketplace: A consumer-to-consumer online platform where users buy and sell directly to each other. "Consumer-to-consumer (C2C) marketplaces pose distinct retrieval challenges: short, ambiguous queries; noisy, user-generated listings; and strict production constraints."
- dense, embedding-based matching: Retrieval approach that uses learned dense vectors to match queries and items semantically. "Dense, embedding-based matching has become a standard remedy for vocabulary mismatch and semantic variability in e-commerce search"
- Elasticsearch (ES): A distributed search and analytics engine commonly used for indexing and retrieving documents. "propagated to Elasticsearch (ES) prior to the experiment."
- feature store: A production system for storing and serving computed features/embeddings for online inference. "written to the Bigtable feature store and propagated to Elasticsearch (ES)"
- graded relevance: An evaluation scheme that assigns different relevance levels to user interactions rather than binary labels. "with graded relevance: purchase > like > comment > click > view."
- hybrid retrieval: Combining sparse lexical matching with dense semantic retrieval to improve coverage and relevance. "Additionally, we then evaluated hybrid retrieval—blending lexical matching with semantic candidates retrieved by vector similarity—"
- in-batch negatives: A contrastive training technique where other samples in the minibatch act as negatives. "MNR treats all non-matching titles in the batch as in-batch negatives for each query"
- JGLUE STS: A Japanese Semantic Textual Similarity benchmark in the JGLUE suite for evaluating sentence similarity. "We evaluate general-language similarity on JGLUE STS, reporting Pearson's and Spearman's ."
- learning-to-rank (LTR): A machine learning framework that optimizes ordering of items for search results. "Mercari's learning-to-rank (LTR) model used a task-specific embedding layer jointly trained with the ranking objective"
- lexical matching: Retrieval based on exact or near-exact term matches between query and document. "—blending lexical matching with semantic candidates retrieved by vector similarity—"
- Matryoshka Representation Learning (MRL): A training method that enforces nested, informative subspaces so truncated embeddings remain effective. "we adopt Matryoshka Representation Learning (MRL) \cite{kusupati2024matryoshka}, wrapping the base contrastive loss with nested objectives over the leading dimensions"
- Matryoshka truncation: Using only the leading dimensions of Matryoshka-trained embeddings to meet efficiency constraints. "Matryoshka truncation plus domain fine-tuning yields substantial gains"
- Multiple Negatives Ranking (MNR): A contrastive loss that treats non-matching pairs in the batch as negatives to separate representations. "We fine-tune a text encoder with using Multiple Negatives Ranking (MNR) \cite{henderson2017efficientnaturallanguageresponse}."
- nDCG@k: Normalized Discounted Cumulative Gain at cutoff k, an IR metric that weights higher-ranked relevant results more. "We report metrics at a cutoff of : , (long), , and ."
- PCA: Principal Component Analysis, a linear dimensionality reduction technique. "we compressed 768-dimensional embeddings to 32 dimensions via PCA"
- Precision@k: The fraction of retrieved items in the top k that are relevant. "We report metrics at a cutoff of : , (long), , and ."
- Recall@k: The fraction of all relevant items that appear in the top k retrieved candidates. "We report metrics at a cutoff of : , (long), , and ."
- role-specific prefixes: Special tokens prepended to inputs to condition the encoder on roles (e.g., query vs. item). "using role-specific prefixes to model query–item asymmetry."
- semantic search results: Items retrieved based on semantic similarity of embeddings rather than exact term overlap. "The treatment group, which integrates semantic search results when similarity score , produced consistent gains."
- SERP: Search Engine Results Page, the UI surface displaying ranked search items. "search engine results page (SERP)"
- temporal hold-out split: An evaluation protocol that separates training and test data by time to avoid leakage. "we construct a temporal hold-out split disjoint from training months."
- Triton inference server: A serving system for deploying and scaling ML models for low-latency inference. "produce vector representations via a shared Triton inference server."
- truncation-robust embeddings: Representations trained to retain performance when reduced to fewer dimensions. "apply Matryoshka Representation Learning to obtain compact, truncation-robust embeddings."
- vector similarity: A retrieval signal based on similarity between query and item embeddings. "semantic candidates retrieved by vector similarity"
- zero-hit SERPs: Search result pages that would otherwise return no results due to lack of lexical matches. "hybrid retrieval recovered of would-be zero-hit SERPs"
Collections
Sign up for free to add this paper to one or more collections.

