LoGoPlanner: Localization Grounded Navigation Policy with Metric-aware Visual Geometry
Abstract: Trajectory planning in unstructured environments is a fundamental and challenging capability for mobile robots. Traditional modular pipelines suffer from latency and cascading errors across perception, localization, mapping, and planning modules. Recent end-to-end learning methods map raw visual observations directly to control signals or trajectories, promising greater performance and efficiency in open-world settings. However, most prior end-to-end approaches still rely on separate localization modules that depend on accurate sensor extrinsic calibration for self-state estimation, thereby limiting generalization across embodiments and environments. We introduce LoGoPlanner, a localization-grounded, end-to-end navigation framework that addresses these limitations by: (1) finetuning a long-horizon visual-geometry backbone to ground predictions with absolute metric scale, thereby providing implicit state estimation for accurate localization; (2) reconstructing surrounding scene geometry from historical observations to supply dense, fine-grained environmental awareness for reliable obstacle avoidance; and (3) conditioning the policy on implicit geometry bootstrapped by the aforementioned auxiliary tasks, thereby reducing error propagation. We evaluate LoGoPlanner in both simulation and real-world settings, where its fully end-to-end design reduces cumulative error while metric-aware geometry memory enhances planning consistency and obstacle avoidance, leading to more than a 27.3\% improvement over oracle-localization baselines and strong generalization across embodiments and environments. The code and models have been made publicly available on the https://steinate.github.io/logoplanner.github.io.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
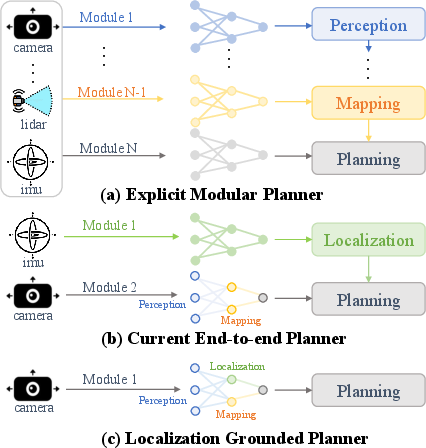
This paper introduces LoGoPlanner, a new way for robots to find their way to a goal while avoiding obstacles, using only what they see through a camera and depth sensor. Unlike many older methods that split the job into many parts (like “see,” “map,” “locate,” “plan”), LoGoPlanner learns to do everything end-to-end. It focuses on two big ideas:
- Help the robot understand the real size of things it sees (metric scale), so it knows how far and how big objects are.
- Let the robot figure out where it is (localization) directly from video, without needing a separate, fragile localization system.
The result is a robot that plans safer, more consistent paths, even in messy, real-world places.
What questions does the paper try to answer?
The paper aims to answer:
- Can a robot plan its path better if it learns to “know where it is” directly from what it sees, instead of relying on a separate localization system?
- Can the robot build a memory of the 3D world around it from past video frames, so it avoids obstacles more reliably?
- Can combining these skills into one end-to-end system reduce errors and work across different robots and environments?
How did they do it?
The researchers combined smart vision models with a planning method that improves paths step by step. Here’s how it works, using simple ideas and analogies:
Seeing in 3D with real sizes (metric-aware visual geometry)
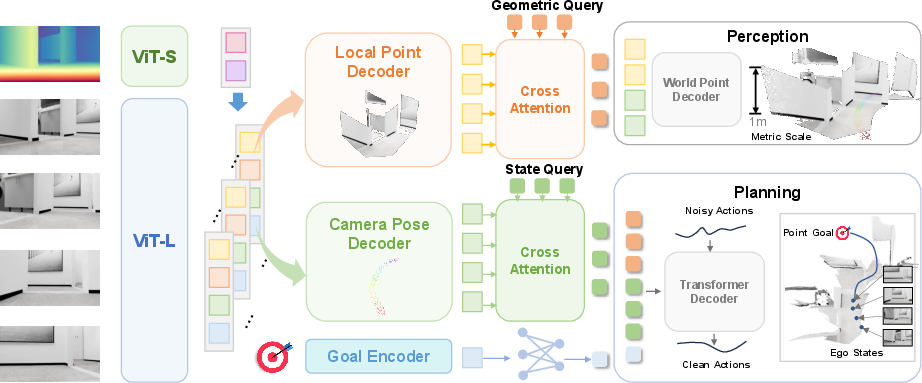
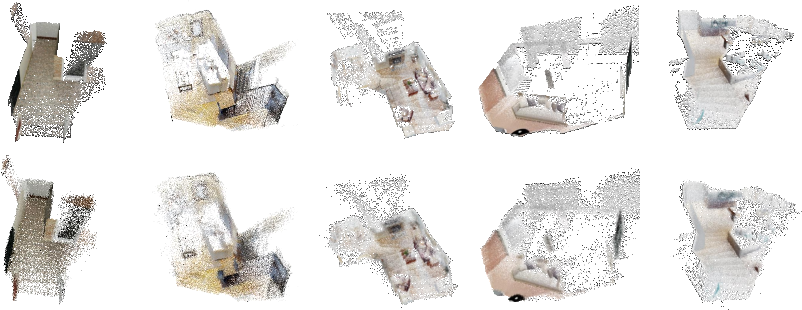
Imagine looking at the world through a camera and also having a rough sense of how far things are (depth). Many vision models can build a 3D picture, but they don’t know the “true scale” (is that box 20 cm away or 2 meters?). LoGoPlanner fine-tunes a video-geometry model so it learns real-world sizes using the depth sensor as a guide. This turns the camera’s view into a “point cloud” — like a swarm of dots floating in space — at the correct scale.
Remembering what it saw (geometry memory)
Robots don’t just look at one frame; they watch a video sequence. LoGoPlanner gathers information from many frames to reconstruct the surroundings, including parts that might be blocked in one view but visible in others. This gives the robot a dense, detailed sense of nearby obstacles — like remembering the layout of a room as you walk through it.
Knowing where it is (implicit localization)
Localization means “figuring out your own position.” Instead of using a separate, delicate module (like SLAM) that can break if the camera shakes or is mounted differently, LoGoPlanner learns to estimate its position directly from the video. Think of it as a person who remembers where they’ve walked by piecing together their visual history, without needing a map pinned to exact coordinates.
There’s also a practical trick: cameras are mounted on different robots at different heights and angles. LoGoPlanner separates the “camera viewpoint” from the “robot body” (chassis), so it doesn’t get confused by camera placement. This makes it work across different robot types.
Planning smooth paths (diffusion-based trajectory generation)
To plan a route, LoGoPlanner uses a “diffusion” policy: start with a rough, noisy path and polish it over several steps into a clean, collision-free trajectory. You can think of it like sketching a route quickly and then refining it until it makes sense and avoids obstacles.
Inside the model, “queries” act like focused questions:
- State queries ask: “Where am I now and where is my goal?”
- Geometry queries ask: “What obstacles are around me?” These are answered using the robot’s internal features (not raw predicted poses or point clouds), which helps avoid error stacking.
What did they find?
In both simulated worlds and real-life tests, LoGoPlanner:
- Outperformed strong baselines, including ones that had perfect (oracle) localization from the simulator. It achieved more than a 27.3% improvement in success rate in challenging home environments, showing that its built-in localization works very well.
- Planned more consistent paths and avoided obstacles better, thanks to its 3D geometry memory and metric-aware understanding.
- Worked across different robots and places:
- TurtleBot in offices
- Unitree Go2 in homes
- Unitree G1 in industrial scenes
- Even with camera shake (like on a walking robot), it stayed stable and accurate.
Why is this important?
- Fewer moving parts: By learning everything end-to-end, the robot avoids “cascading errors” that happen when many separate modules pass mistakes down the pipeline.
- Easier to deploy: No need for exact camera-to-body calibration or a separate localization system. This means you can put the camera in different spots and still get good performance.
- Safer navigation: Understanding 3D geometry with real sizes helps avoid collisions and plan consistent paths.
- Better generalization: It works across different robots and environments, which is critical for real-world use.
Looking ahead
The authors note that real-world 3D reconstruction can still be improved, especially because large, diverse, metric-scale datasets are limited. They are training on more real-world data to make the system even stronger in practical deployment.
Overall, LoGoPlanner points toward a future where robots can navigate reliably in messy, unpredictable spaces using just what they see, without needing a complicated stack of separate systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, framed to guide future research.
- Reliance on RGB-D input at inference: quantify performance when depth is unavailable, noisy, or partially missing; develop RGB-only variants and cross-modal fallback strategies.
- Depth-based scale injection: assess generalization when metric-scale depth priors are not available (e.g., monocular cameras), and explore self-supervised or learned metric-scale recovery without depth supervision.
- Pose estimation evaluation: report standard localization metrics (ATE/RPE, drift per meter/time) across motion profiles (e.g., walking-induced jitter, rapid rotations) to validate implicit state accuracy.
- Zero-yaw extrinsic assumption: relax the assumption that camera yaw relative to chassis is zero; learn full 6-DoF camera–chassis extrinsics online and handle time-varying mounts or slippage.
- Fixed extrinsic transformation: design and evaluate online calibration modules that adapt extrinsics over time, including multi-camera configurations and variable camera placements.
- 2D ground-plane pose restriction: extend to full 3D navigation (roll/pitch-aware planning), uneven terrain, stairs, slopes, and step-height constraints, especially for legged robots.
- Dynamic environments: evaluate robustness and planning in the presence of moving obstacles, dynamic crowds, and non-static scenes; integrate motion forecasting and reactive avoidance.
- Safety guarantees: incorporate and evaluate formal safety constraints (e.g., hard collision constraints, reachable sets, control barrier functions) for provably safe trajectories from the diffusion head.
- Interpretability of implicit geometry: provide mechanisms to export or visualize the internal geometric memory (e.g., occupancy/TSDF) and quantify coverage (front, rear, occluded regions) and uncertainty.
- Memory horizon sensitivity: analyze how history length, memory update rate, and aggregation affect localization drift, obstacle recall, and planning stability over long episodes.
- Persistent mapping and loop closure: investigate building and maintaining a global, persistent map across episodes, with loop closure and place recognition to reduce drift and enable long-range navigation.
- Compute and latency profile: measure end-to-end inference latency, throughput, and energy on embedded platforms; optimize for on-board deployment (edge GPUs/CPUs) without cloud reliance.
- Network connectivity dependence: assess failure modes and design graceful degradation when cloud inference or network bandwidth is constrained; enable local fallback policies.
- Dataset coverage and domain shift: expand beyond synthetic indoor scenes to outdoor, industrial, and adverse conditions (extreme lighting, weather, reflective/glass surfaces) and quantify domain transfer.
- Real-world evaluation scale: increase trials, report SPL/time-to-goal/collision counts, and perform statistical significance testing to validate robustness and generalization claims.
- Baseline breadth and fairness: compare against strong SLAM/VO+planner baselines (e.g., VINS-Mono, modern local/global planners), and recent end-to-end models (e.g., GNM, NOMAD) under matched settings.
- Data and sample efficiency: study how performance scales with training data size, synthetic-to-real ratios, and weak/unsupervised labels; develop finetuning and few-shot adaptation strategies.
- Sensor noise and failure robustness: stress-test under motion blur, rolling shutter, desynchronization, dropped frames, and depth artifacts; integrate sensor fault detection and recovery.
- Uncertainty-aware planning: calibrate uncertainty of state/geometry estimates and diffusion outputs; propagate uncertainty into risk-aware action selection and emergency behaviors.
- Low-level control integration: evaluate trajectory tracking under platform-specific dynamics and constraints (e.g., legged gait planners, slip, contact planning) to bridge policy outputs to safe execution.
- Metric point cloud parameterization: compare the proposed sign–exp mapping with alternative coordinate parameterizations (e.g., log-depth, bounded activations) for stability and accuracy.
- Coordinate frame specification: clarify and standardize frame definitions (camera/world/chassis, last-frame alignment) and quantify how frame choices impact drift and planning consistency.
- Multi-modal fusion: explore integrating IMU, wheel odometry, or LiDAR to improve robustness and reduce reliance on depth; study learned sensor weighting under varying conditions.
- Multi-camera and panoramic setups: extend to heterogeneous camera arrays and omnidirectional views, learning extrinsics jointly and leveraging broader coverage for occlusion handling.
- Failure mode analysis: systematically characterize and publish common failure cases (e.g., textureless walls, specular reflections, repetitive patterns) with targeted mitigation strategies.
Glossary
- A* algorithm: A graph-search algorithm that finds shortest paths using heuristics. "Initial paths between randomly sampled start and goal points are generated using the A* algorithm."
- Alternating-attention mechanism: A transformer strategy that alternates intra-frame and inter-frame attention to improve spatial and temporal consistency. "The alternating-attention mechanism alternates between intra-frame and inter-frame attention, improving both local fidelity and long-horizon consistency."
- Auxiliary tasks: Additional supervised objectives used during training to guide intermediate representations (e.g., odometry, goal projection, point cloud). "To endow the model with self-state estimation and metric-aware perception, we introduce three auxiliary tasks in the first stage."
- Camera extrinsics: The external parameters that define a camera’s position and orientation relative to a reference frame. "supervision is provided by metric-scale scene point clouds and camera extrinsics."
- Chassis frame: The coordinate frame attached to the robot’s base used for planning and alignment. "where the world coordinate system is defined with respect to the chassis frame of the last time step"
- Chassis pose: The robot base’s position and orientation (often on the ground plane) used for control. "The model also predicts the chassis pose and latest goal position from pose estimation task-specific feature "
- Coded apertures: Patterned masks in imaging systems that help recover additional scene information, improving VO scale estimates. "CodedVO~\cite{shah2024codedvo} improves scale estimation via coded apertures"
- Cross-attention: An attention mechanism that lets query tokens attend to context tokens across modules. "Interactions across modules are realized via query cross attention."
- Cubic spline interpolation: A smoothing technique that fits piecewise cubic polynomials to trajectories. "subsequently smoothed via cubic spline interpolation to ensure collision-free navigation."
- Differential-drive: A locomotion scheme where two wheels are independently driven to control motion and rotation. "a cylindrical rigid body with a differential-drive two-wheel configuration"
- Diffusion policy head: A generative policy head that denoises action sequences iteratively to produce feasible trajectories. "we attach a diffusion policy head to generate action chunks "
- Ego-motion: The motion of the camera/agent through the environment estimated from visual input. "Odometry supervises ego-motion estimation"
- Epipolar constraints: Geometric relations between corresponding points in different views used for pose and structure estimation. "rely on handcrafted features and epipolar constraints"
- Extrinsic calibration: The process of determining the rigid transform between sensors (e.g., camera to chassis). "still rely on separate localization modules that depend on accurate sensor extrinsic calibration"
- Extrinsic transformation: A fixed rigid transformation mapping camera coordinates to the chassis/base frame. "denotes the fixed extrinsic transformation capturing the camera’s height and pitch angle relative to the chassis."
- Gaussian noise: Random noise drawn from a normal distribution used in diffusion processes. "Starting from sampled from Gaussian noise"
- Geometric priors: Prior knowledge or constraints about 3D structure used to guide perception or planning. "thereby providing fine-grained geometric priors for planning."
- Greedy search: A heuristic optimization that makes locally optimal choices to refine paths. "These paths are refined through greedy search"
- Implicit state estimation: Inferring the agent’s state from features without an explicit localization module. "we design an implicit state estimation module that operates on long visual sequences."
- Metric-scale: Absolute scaling in physical units (e.g., meters) required for consistent planning and localization. "enabling the prediction of dense, metric-scale point clouds relative to the robot’s current position."
- Monocular visual odometry (VO): Estimating camera motion from a single camera stream, typically suffering scale ambiguity. "Monocular visual odometry (VO) and SLAM methods inherently suffer from scale ambiguity."
- Noise prediction network: The network in diffusion models that predicts noise at each denoising step. " is the noise prediction network conditioned on planning context query "
- Oracle localization: Ground-truth poses provided by a simulator used to benchmark planners. "a 27.3\% relative improvement over baselines that rely on oracle localization"
- Photometric consistency: The assumption that pixel intensities remain consistent across views, used in direct VO/SLAM. "Direct methods such as DSO... optimize photometric consistency"
- Pinhole model: A standard camera projection model mapping depth and pixel coordinates to 3D points. "which is supervised by local points in the camera coordinate system using the pinhole model for each pixel "
- Point cloud: A set of 3D points representing scene geometry used for perception and planning. "the reconstructed metric-scale scene point cloud expressed in the last frame"
- Query-based design: An architecture where task-specific queries extract and fuse features via attention. "we adopt a query-based design in which different modules are aggregated through task-specific queries."
- RGB-D: Combined color (RGB) and depth sensing used as the primary observation modality. "We study the problem of point-goal navigation using only RGB-D observations."
- Rotary Position Embedding (RoPE): A positional encoding that applies rotations to embeddings to encode spatial coordinates. "Rotary Position Embedding(RoPE)"
- Scale ambiguity: The inability to recover absolute scale from monocular observations without additional priors. "Monocular visual odometry (VO) and SLAM methods inherently suffer from scale ambiguity."
- Sim-to-real gap: The performance difference between simulation-trained models and real-world deployment. "the model further reduces the sim-to-real gap"
- SLAM: Simultaneous Localization and Mapping; building a map while localizing within it. "explicit localization modules such as SLAM or visual odometry"
- SPL (Success weighted by Path Length): A metric that balances success with trajectory efficiency. "Planning performance is measured using Success Rate (SR) and Success weighted by Path Length (SPL)."
- SR (Success Rate): The fraction of successful navigations to the goal. "Planning performance is measured using Success Rate (SR) and Success weighted by Path Length (SPL)."
- Vision Transformer (ViT): A transformer architecture for image patches used as a backbone encoder. "image patches that are encoded by ViT~\cite{oquab2023dinov2}"
- Video geometry model: A model that reconstructs 3D geometry and camera poses from video sequences. "we fine-tune the decoder of the video geometry model and the task-specific head"
- World coordinate system: A global reference frame used to express poses and scene geometry. "where the world coordinate system is defined with respect to the chassis frame of the last time step"
- Yaw: Rotation around the vertical axis, often the heading angle in navigation. "we assume the robot-mounted camera has no yaw rotation relative to the chassis."
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, each noting sectors, potential tools/products/workflows, and key assumptions or dependencies.
- Sector(s): Robotics, Logistics, Healthcare, Facilities
Use case: Drop-in end-to-end indoor navigation for mobile bases (AGVs/AMRs, service robots) in warehouses, hospitals, and offices—replacing SLAM/VO modules to cut calibration overhead and reduce cascading errors.
Potential tools/products/workflows: LoGoPlanner ROS2 node that subscribes to RGB-D and publishes local trajectories; containerized inference (
Docker) or edge deployment on Jetson Orin; integration with existing controllers (Pure Pursuit/DWA). Assumptions/dependencies: RGB-D available; planar ground; camera yaw roughly aligned with chassis (or quick calibration); GPU/CPU budget for diffusion head; acceptable latency (on-device or low-latency network). - Sector(s): Robotics (Legged), Industrial, Consumer Use case: Robust obstacle-aware navigation for legged robots in cluttered homes and industrial sites (e.g., Unitree Go2/G1), mitigating camera jitter and extrinsic sensitivity. Potential tools/products/workflows: LoGoPlanner policy paired with a locomotion/footstep controller; “trajectory shield” that enforces clearance; runtime health monitor for pose-confidence thresholds. Assumptions/dependencies: Chassis-level control interface; relatively flat terrain or locomotion module handling elevation; stable RGB-D stream.
- Sector(s): Manufacturing, Service Robotics Use case: Retrofitting legacy robots with inconsistent camera mounts—deploy navigation without precise extrinsic calibration; cross-embodiment fleet unification. Potential tools/products/workflows: “Calibration-lite wizard” (set yaw, height, pitch ranges); “Geometry Memory Visualizer” for debugging perceived point-cloud context; ROS integration guide. Assumptions/dependencies: Ability to consume trajectories in existing stack; basic mechanical alignment to avoid large yaw offsets; time to validate safety envelope.
- Sector(s): Software/Cloud Robotics, IT Use case: Cloud inference for navigation—stream RGB-D to an RTX-class GPU and return trajectories in real time to resource-constrained robots. Potential tools/products/workflows: gRPC/WebSocket microservice; video compression (H.264/H.265); SLA for latency and uptime; TLS for data security. Assumptions/dependencies: Reliable network; privacy and compliance policies; bandwidth sufficient for RGB-D streaming; fallback on local safe-stop.
- Sector(s): Security, Inspection, Utilities Use case: Teleoperation assistance (“goal autopilot”)—operators set point goals; LoGoPlanner supplies obstacle-aware local paths, reducing operator workload and accident risk. Potential tools/products/workflows: Operator UI overlay with goal projection and predicted trajectory; haptic/visual alerts for collision reports; manual override integration. Assumptions/dependencies: Continuous camera feed; organizational safety SOPs; trained operators for takeover.
- Sector(s): Software/Robotics Use case: Mapping-lite safety layer—convert LoGoPlanner’s implicit point-cloud memory into a local cost map to upgrade existing planners’ obstacle handling. Potential tools/products/workflows: ROS2 costmap plugin; BEV conversion of implicit geometry; fusion with existing lidar/stereo when present. Assumptions/dependencies: Point-cloud fidelity under lighting/textures; sensor synchronization; computational budget.
- Sector(s): Academia, Education Use case: Teaching and benchmarking—use LoGoPlanner as an open-source baseline for end-to-end navigation, ablations, and video-geometry research in robotics courses and labs. Potential tools/products/workflows: Course notebooks; reproducible training scripts; evaluation harness with SR/SPL and error metrics; dataset loaders (InternScenes/Habitat-like). Assumptions/dependencies: GPU access; students’ familiarity with ROS2/CV/ML.
- Sector(s): Retail, Events Use case: Rapid deployment of service robots in pop-up venues (expos, malls) without site-specific calibration or mapping. Potential tools/products/workflows: Turnkey robot package (RGB-D sensor, preloaded LoGoPlanner); minimal configuration workflow; staff training kit. Assumptions/dependencies: Indoor layout with manageable crowd dynamics; clear safety zones and signage; compliance with venue rules.
- Sector(s): Construction, Facilities Management Use case: Autonomous indoor inspection rounds—navigate to predefined checkpoints to capture photo/video, with reliable obstacle avoidance in clutter. Potential tools/products/workflows: Waypoint scheduler; automatic logging and report generation; integration with CMMS/BIM. Assumptions/dependencies: Stable lighting; limited dynamic obstacles; on-site safety review.
- Sector(s): Academia, Robotics Use case: Real-world data collection for metric-scale video geometry—use LoGoPlanner to gather diverse trajectories and RGB-D sequences to expand training corpora and reduce sim-to-real gaps. Potential tools/products/workflows: Data-collection pipeline; metadata capture (sensor poses, environment tags); annotation and curation tools. Assumptions/dependencies: Privacy consent; storage/compute; standardized labeling schemas.
Long-Term Applications
Below are forward-looking applications that likely require further research, scaling, or ecosystem development before widespread deployment.
- Sector(s): Robotics (Field), Agriculture Use case: Outdoor navigation with vision-only scale recovery—operate without dedicated depth hardware using learned scale priors. Potential tools/products/workflows: Multi-sensor fusion (IMU/barometer/LiDAR altimetry) for robust scale; domain adaptation to weather/lighting; self-supervised real-world fine-tuning. Assumptions/dependencies: Larger real-world datasets; advances in generalization to outdoor textures and lighting; resilient hardware.
- Sector(s): Aerospace, Infrastructure Inspection Use case: 6-DoF aerial navigation—extend LoGoPlanner to drones with full 3D trajectory generation and dynamic obstacle handling. Potential tools/products/workflows: 3D diffusion policy; tight IMU/vision fusion; hardware acceleration (Edge TPU/Orin NX); safety corridors. Assumptions/dependencies: Regulatory approval; collision-avoidance certification; robust scale estimation in aerial contexts.
- Sector(s): Healthcare Use case: Fleet-scale hospital delivery—minimal calibration across wards, elevators, and complex layouts; robust human-aware navigation. Potential tools/products/workflows: Fleet management console; multi-robot coordination; clinical-grade safety validation (SPL/SR targets); incident auditing. Assumptions/dependencies: Human–robot interaction design; integration with building infrastructure (elevators/doors); liability and compliance frameworks.
- Sector(s): Consumer Electronics Use case: Self-installed home robots (vacuum/mop/assist) with map-free navigation, persistent geometry memory, and cross-room generalization. Potential tools/products/workflows: On-device inference with quantization/pruning; memory persistence across sessions; user-friendly setup app. Assumptions/dependencies: Cost/power constraints; multi-floor handling; privacy-preserving local processing.
- Sector(s): Policy/Standards Use case: Certification and benchmarking of end-to-end navigation—define acceptance tests (SR, SPL, navigation error) and safety protocols for ML policies. Potential tools/products/workflows: Standardized test suites; runtime shielding requirements; audit trails; procurement checklists (calibration-lite criteria). Assumptions/dependencies: Multi-stakeholder consensus; regulatory body engagement; reproducible evaluation procedures.
- Sector(s): Software/Robotics Use case: Navigation foundation model—pretrain across massive diverse environments and embodiments, with parameter-efficient finetuning for new robots/tasks. Potential tools/products/workflows: Dataset aggregation at scale; continual learning and distillation; adapters/LoRA for specific platforms. Assumptions/dependencies: Large compute budgets; broad, high-quality datasets; model governance.
- Sector(s): Smart Buildings, Digital Twins Use case: Digital twin–aware navigation—align implicit geometry memory with facility BIM/twins for semantic-aware routing and dynamic occupancy updates. Potential tools/products/workflows: Twin-to-robot map alignment; semantic memory modules; building management integration (HVAC, access). Assumptions/dependencies: Standardized BIM/twin APIs; privacy and cybersecurity; maintenance workflows.
- Sector(s): Policy/Regulatory, Safety Use case: Formal verification and runtime assurance for diffusion-based navigation policies—certifiable safety envelopes with dynamic shielding. Potential tools/products/workflows: Verification toolchains; risk assessment and hazard analysis; real-time monitors and fail-safes. Assumptions/dependencies: Advances in verifiable ML; acceptance by safety regulators; demonstrable robustness metrics.
- Sector(s): Software Productization, OEM Partnerships Use case: Commercial SDK for plug-and-play navigation—ROS2 plugins, microservices, OEM integration kits, telemetry and support. Potential tools/products/workflows: CI/CD pipelines; device provisioning; field diagnostics; OEM reference implementations. Assumptions/dependencies: Long-term maintenance; customer support; licensing and IP.
- Sector(s): Energy, Heavy Industry Use case: Autonomous inspection in plants and refineries—navigate GPS-denied, cluttered environments with metric-aware geometry memory. Potential tools/products/workflows: Multi-sensor fusion with thermal/gas sensors; hazardous-environment compliance; mission planning with waypoints and safe zones. Assumptions/dependencies: Ruggedized hardware; strict safety certification; domain-specific training and adaptation.
Collections
Sign up for free to add this paper to one or more collections.