- The paper introduces a paradigm shift by leveraging LLM-driven feature extraction from historical vulnerabilities to enhance fuzzing efficacy in JS engines.
- It combines static and dynamic features with SHAP-guided guidance to achieve precision over 85% and reduce false alarms to under 1% across tests.
- The approach shortens bug discovery times by up to 5–24 hours compared to traditional methods, ensuring resource-efficient vulnerability detection.
Data-Centric Feature-Guided Fuzzing for JavaScript Engines
Introduction and Motivation
This work proposes a paradigm shift in fuzz testing for JavaScript (JS) engines, moving from coverage-guided heuristics to a data-centric methodology leveraging historical vulnerability data. The infeasibility of exhaustive coverage-guided fuzzing in modern JS engines is highlighted: the vast state and execution path space means coverage-based approaches waste effort on low-risk or semantically irrelevant inputs, often missing vulnerability-triggering seeds that do not expand coverage. Instead, the authors introduce feature-guided fuzzing, underpinned by automated feature discovery and selection using LLMs, minimizing expert effort and capturing bug-indicative static (code) and dynamic (runtime) attributes.
Related Work Contextualization
Existing state-of-the-art fuzzers either rely on coverage (e.g., AFL, Fuzzilli) or incorporate manual semantic heuristics targeting specific bug classes (e.g., DIE, OptFuzz, JIT-picking). While grammar-aware and IR-based input generation improves code validity, it fails to consistently prioritize high-risk states. No prior work systematically integrates automated feature guidance from vulnerabilities with dynamic analysis across multiple trace sources. This paper fills the gap via LLM-driven discovery of both static and dynamic features directly from real-world JS engine vulnerabilities (2512.18102).
Methodology Overview
The approach consists of several phases:
- Dataset Construction: Historical collection of 190 V8 engine vulnerability-triggering PoCs and thousands of benign JS tests.
- LLM-Based Feature Extraction: Iterative feedback prompts identify and refine 115 static code features via regex classification, then cluster those features and recommend relevant V8 runtime trace flags. Analysis of trace print statements using contextual LLM prompts yields 49 dynamic features. Manual curation removes overfitting and non-general features.
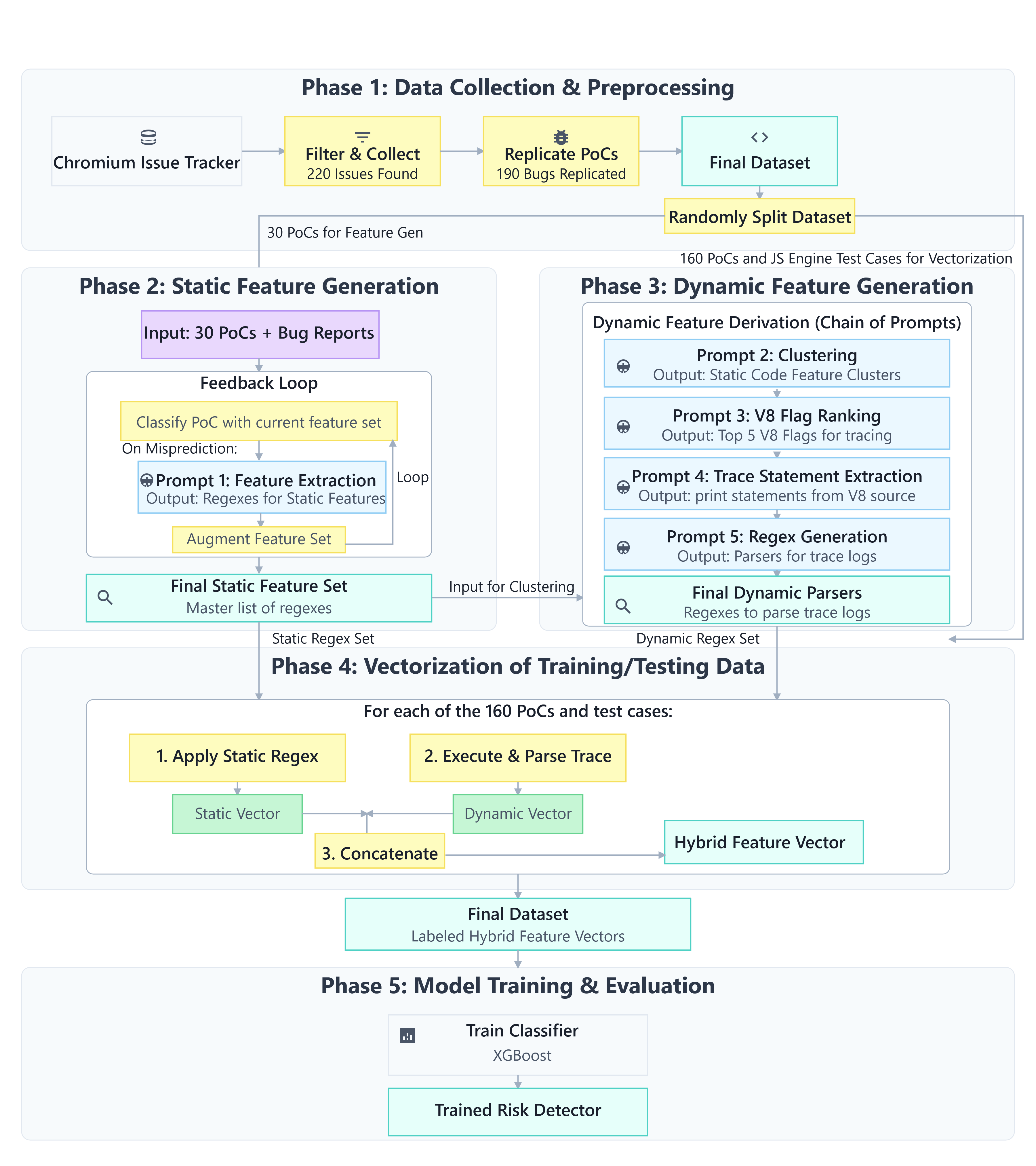
Figure 1: The proposed multi-phase pipeline for LLM-guided feature extraction, model training, and fuzzing implementation integrates historical PoCs and trace analysis.
- Feature Selection and Model Training: XGBoost is trained with combined static and dynamic features. Only 41 features (top 25%) are retained for optimal prediction—a result supported by feature importance ranking.
- Feature-Guided Fuzzer Implementation: Building atop Fuzzilli, the fuzzer exploits a hybrid loop: 90% exploitation based on predicted vulnerability scores and SHAP-guided feature preservation, 10% exploration using classic coverage criteria.
Experimental Results
Time-aware cross-validation demonstrates robust predictive reliability. The guidance model yields precision > 85% and false alarm rate < 1% across folds, vastly outperforming static-only, dynamic-only, and randomized baselines.
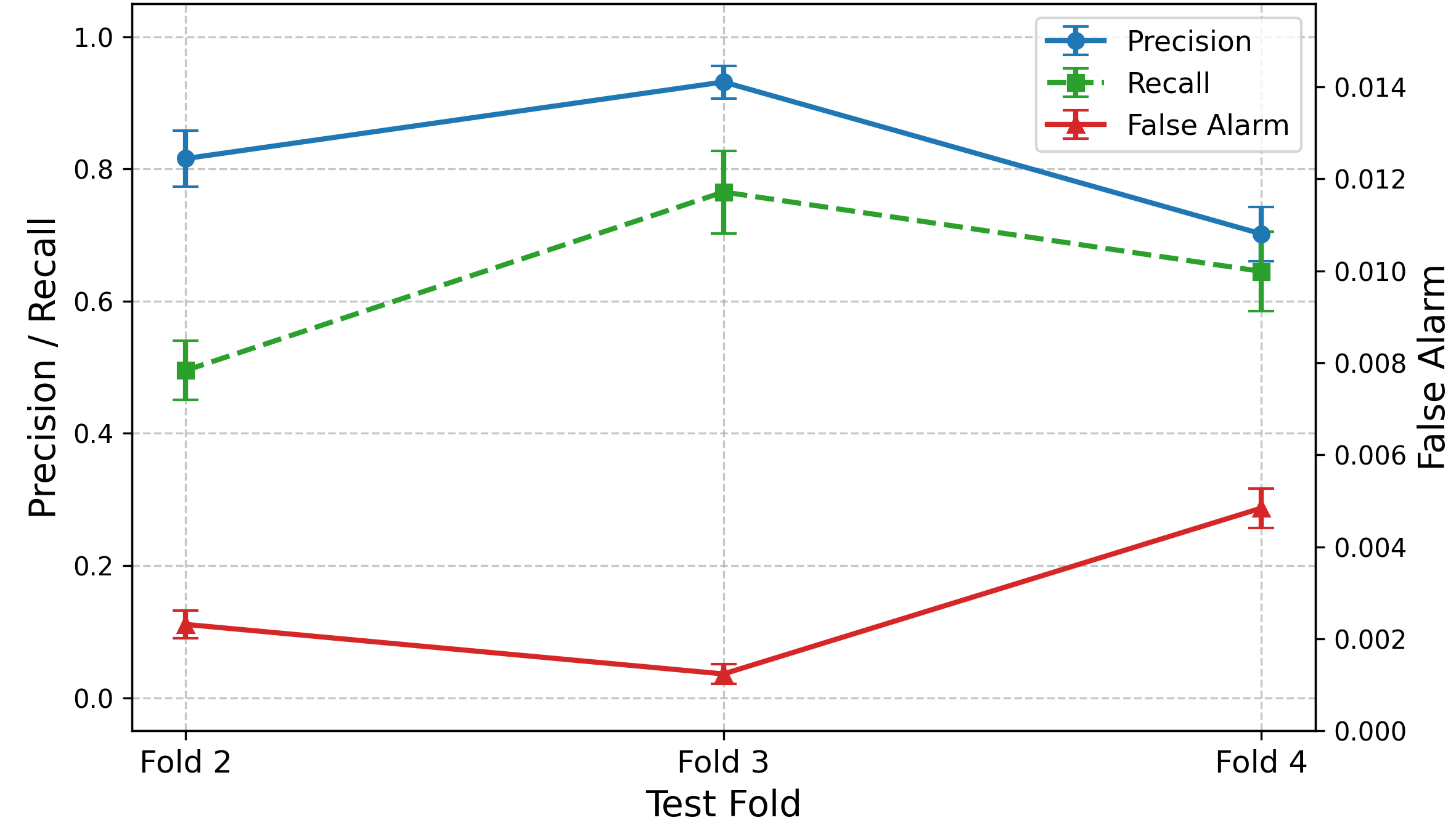
Figure 2: Strong overall performance across time-controlled folds: precision remains high (>0.85), recall varies moderately, and false alarm rates are minimal.
Ablation studies reveal that combining static and dynamic features produces a synergistic effect, with significant gains in both precision and recall over individual modalities. Notably, reducing the feature set to the top 25% retains comparable predictive performance, indicating diminishing returns from including most features.
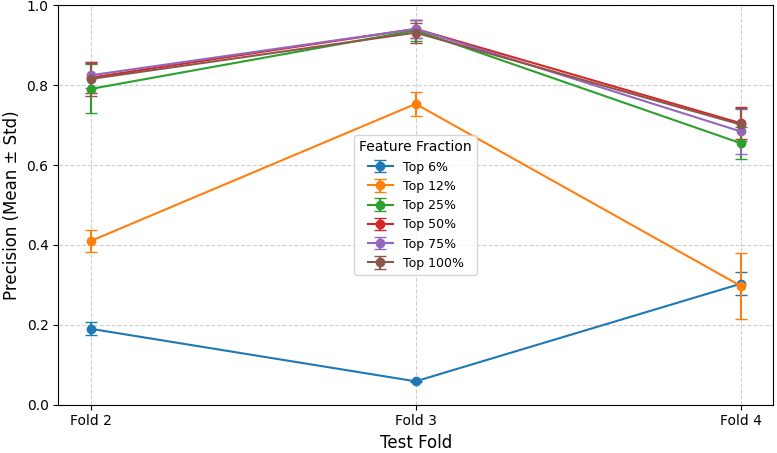
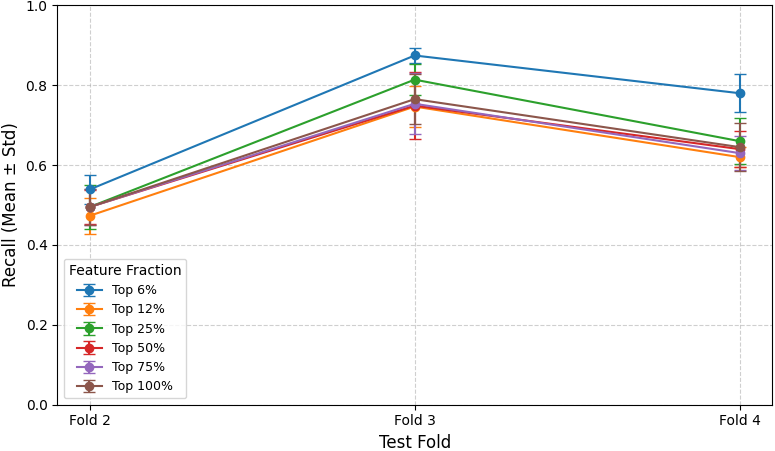
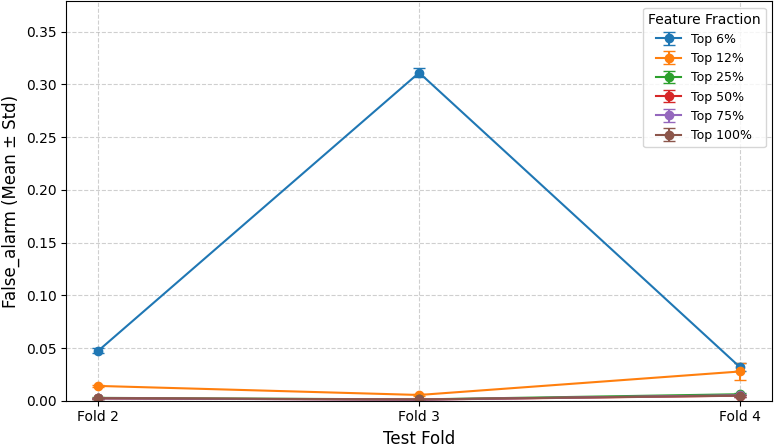
Figure 3: Precision remains stable across folds when varying the fraction of retained high-importance features.
Feature importance ranking further elucidates the contribution of dynamic features. Of 41 retained features, a proportionally higher fraction are dynamic versus static, supporting the argument for runtime trace signals in JS engine vulnerability detection.
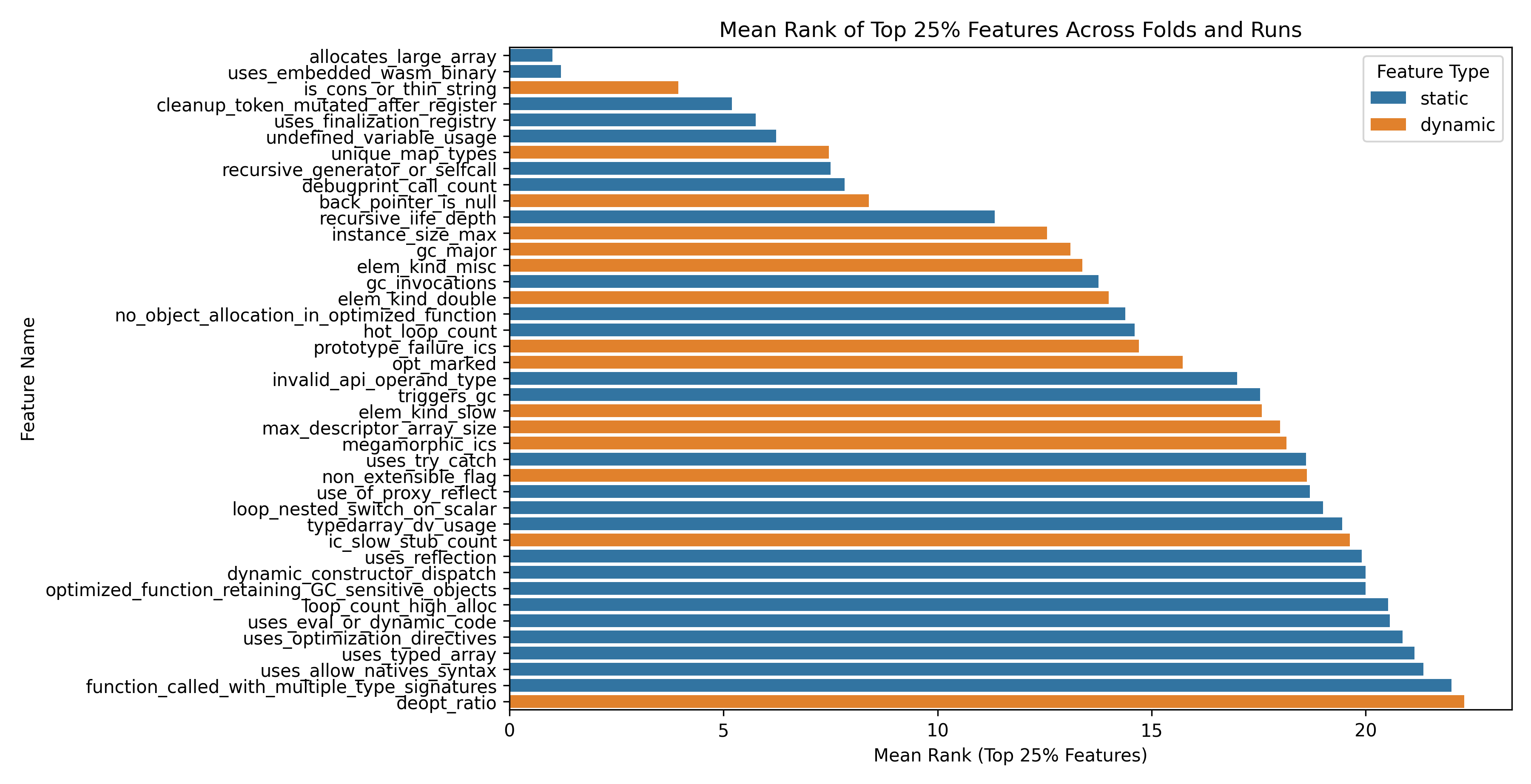
Figure 4: Top features, classified by static/dynamic origin, demonstrate that dynamic (trace-derived) features have higher mean importance.
Runtime overhead analysis shows that the optimized (top 25%) feature set maintains or exceeds baseline execution rates, whereas retaining all features incurs slowdowns. Prudence checks demonstrate practical value: the feature-guided fuzzer finds real crashes in both old and new V8 versions significantly faster (5–24 hours vs. 87–94 hours for state-of-the-art fuzzers).
Theoretical and Practical Implications
The results contradict the prevailing assumption that code coverage is an effective universal proxy for vulnerability discovery in complex software. Instead, cause-driven, data-centric feature guidance more efficiently exposes bug-prone states. This methodology demonstrates that periodic re-training with updated PoC data sustains model generalizability and recall, addressing concept drift as JS engines evolve. The approach requires minimal instrumentation, leveraging only five runtime trace flags, and is adaptable to new bug classes as indicated by historical data.
Practically, this enables reproducible, resource-efficient vulnerability hunting in mature JS engines, with direct applicability to other complex software (e.g., kernels, browsers, databases) contingent on domain-specific feature pipelines. The use of SHAP-based per-instance feature preservation sets the stage for interpretable fuzzing, allowing for further development in crash triaging and automated exploit causality analysis.
Future Directions
Further research should pursue online/incremental learning for continuous adaptation to emergent vulnerabilities, cross-engine generalization of feature sets, and deeper integration of interpretability frameworks. Extension to other dynamic analysis domains is promising, as the pipeline is not restricted to JS semantics.
Conclusion
This paper establishes a systematic, LLM-driven methodology for feature-guided fuzzing in JS engines, replacing path coverage with targeted data-driven inference. By distilling a compact and interpretable set of static and dynamic features from historical crash data, the approach achieves high predictive precision (>85%), minimal false alarms, and order-of-magnitude speedup in bug discovery. Data-centric fuzzers represent a fundamental shift toward adaptive vulnerability search, prioritizing high-risk states and facilitating the next generation of automated, reproducible security testing.

