- The paper introduces DRIP, a framework combining TaSIL and L controller to decouple and bound policy-induced and uncertainty-induced imitation gaps.
- The layered approach leverages contraction theory and Wasserstein ambiguity sets to certify stability and robustness amid distribution shifts.
- Empirical results demonstrate that the composite TaSIL+L method maintains a bounded imitation gap under model drift and diffusion uncertainties.
Distributionally Robust Imitation Learning: Layered Control Architecture for Certifiable Autonomy
Introduction and Motivation
This paper presents a unified control-theoretic and learning-based framework for achieving certifiable autonomy in dynamical systems subjected to distribution shifts. Conventional Imitation Learning (IL) methods effectively leverage expert demonstrations but remain critically sensitive to distribution shifts—arising not only from policy mismatch but also from epistemic model errors, aleatoric disturbances, and initialization ambiguity. Existing approaches frequently rely on unverifiable or impractical assumptions, limiting their application in safety-critical domains. The authors introduce the Distributionally Robust Imitation Policy (DRIP), a Layered Control Architecture (LCA) that compositionally integrates Taylor Series Imitation Learning (TaSIL) with L1-Distributionally Robust Adaptive Control (L), yielding strong distributional robustness guarantees across multiple axes of uncertainty.
Layered Control Architecture
The proposed LCA composes TaSIL and L in a modular structure, where TaSIL operates as a mid-level planner producing reference trajectories, and L implements distributionally robust feedback at the lower level. TaSIL leverages contraction-theoretic stability certification for policy-induced distribution shift, while L employs adaptive control principles to mitigate robustness degradation arising from statistical and structural uncertainties in the system model. The separation enables independent certification of robustness for policy errors and uncertainties, with system-wide compositional guarantees via appropriate interface contracts.
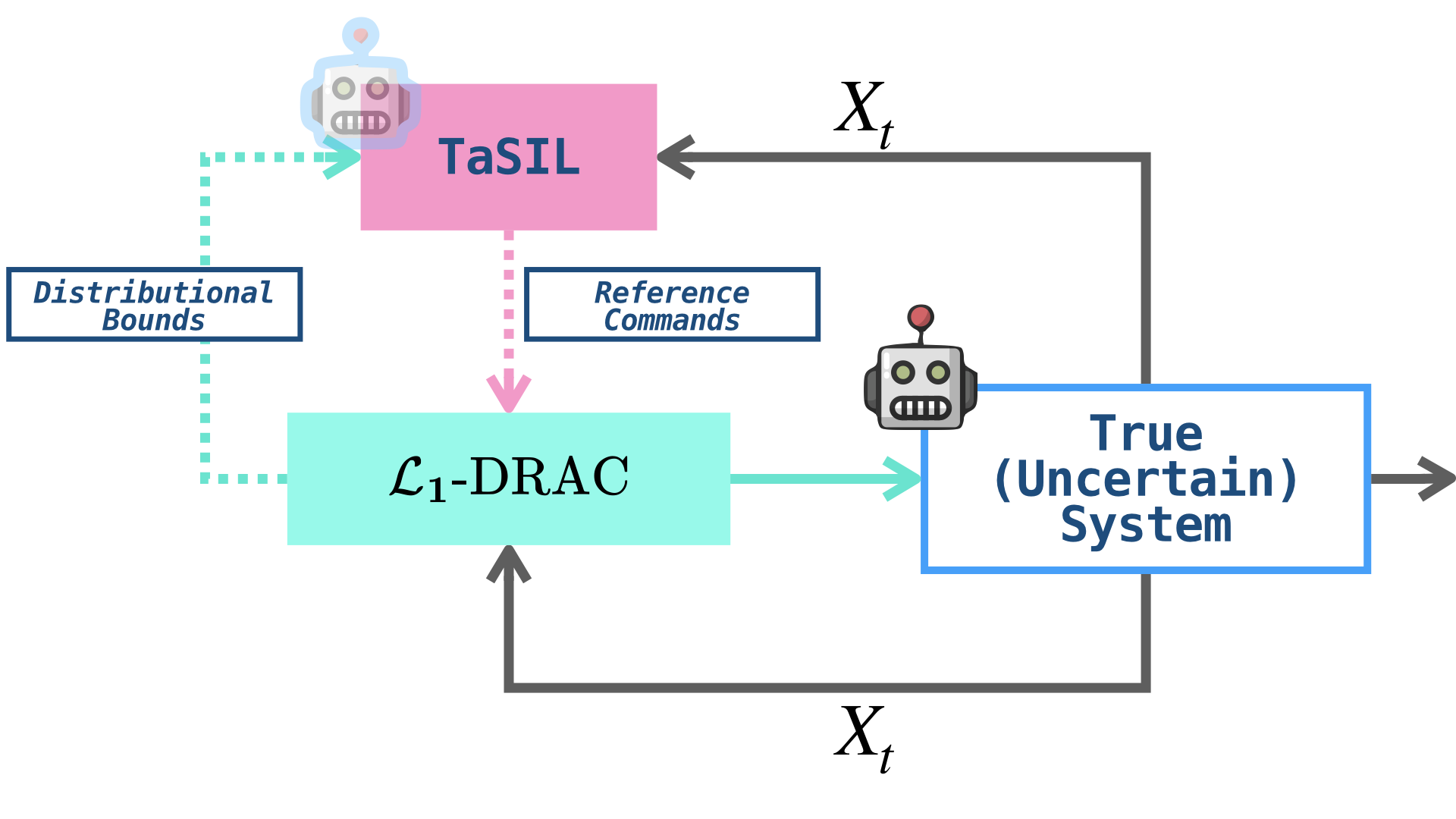
Figure 1: A layered control architecture integrating TaSIL and L, with TaSIL generating references for the distributionally robust low-level controller.
Sources and Types of Distribution Shift
The framework explicitly models distinct sources of distribution shift: (i) policy-induced shifts due to imperfect imitation learning, and (ii) uncertainty-induced shifts resulting from epistemic model discrepancies and aleatoric noise. The decomposition is formalized through joint trajectory processes and a Total Imitation Gap (TIG) metric, quantifying aggregate performance degradation between the uncertain (true) system and its nominal expert counterpart.
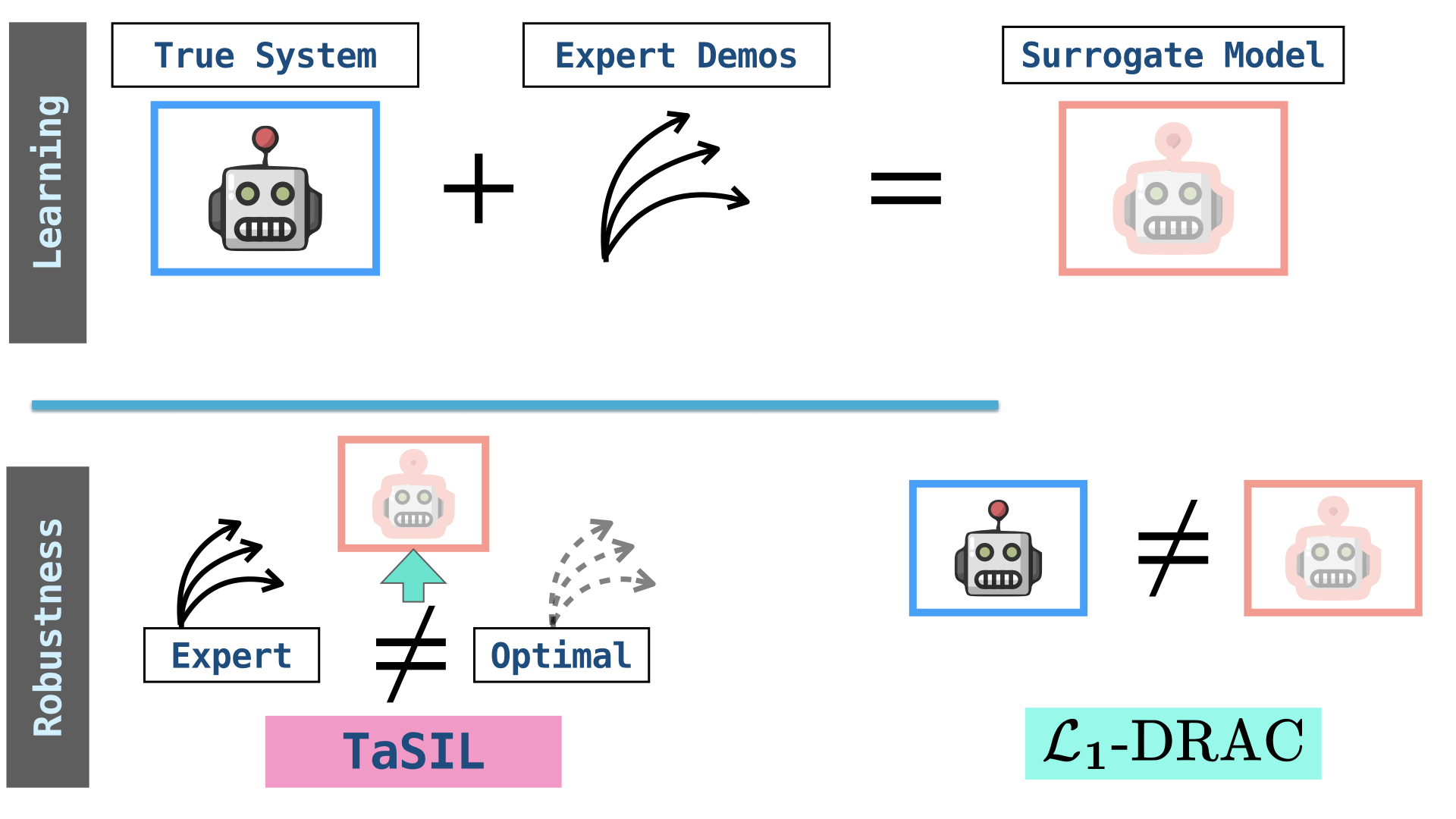
Figure 2: (Top) Expert demonstrations generated from the uncertain true system; (Bottom) TaSIL and L methodologies offer independent and unified robustness, respectively, against policy and uncertainty-induced shifts.
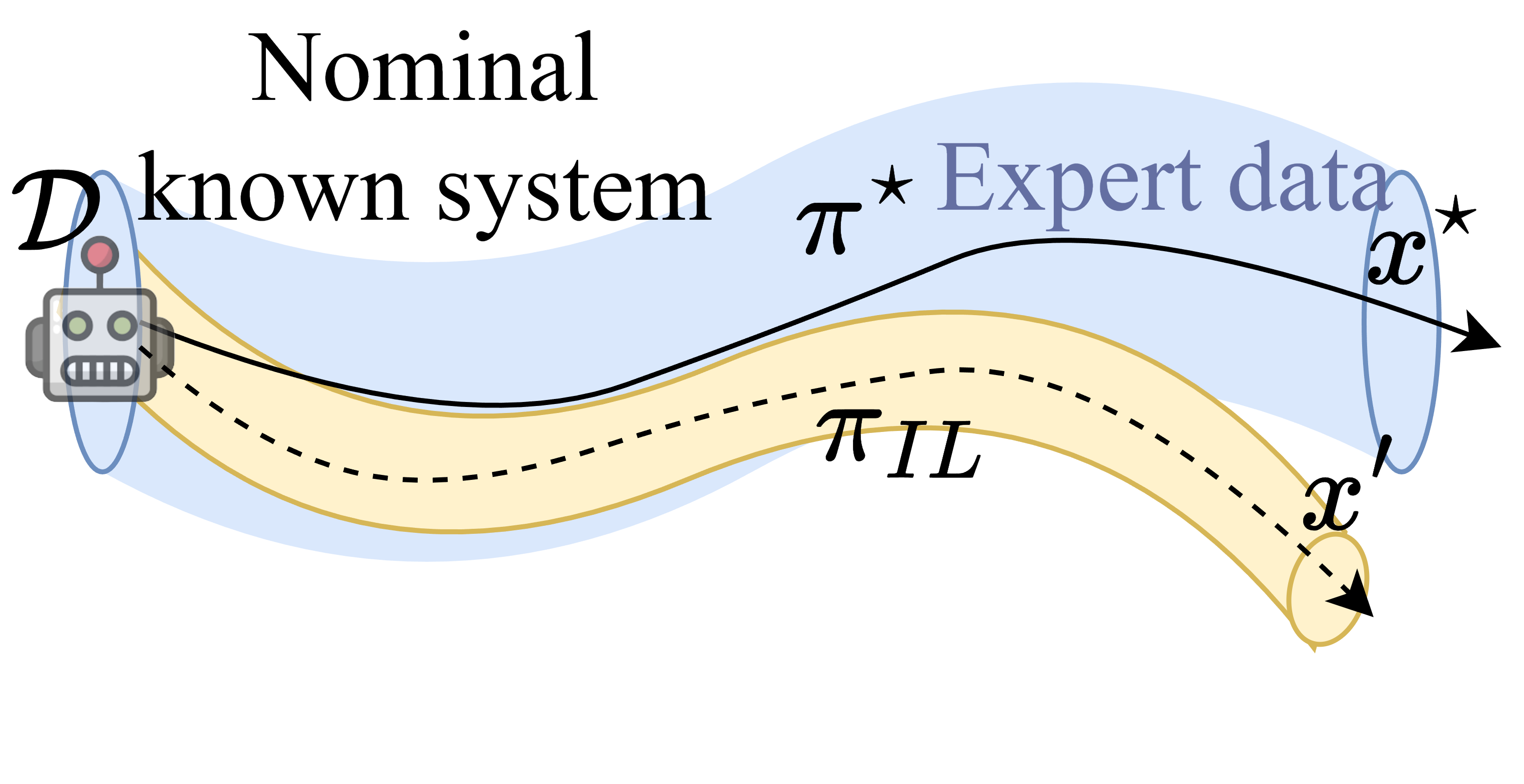
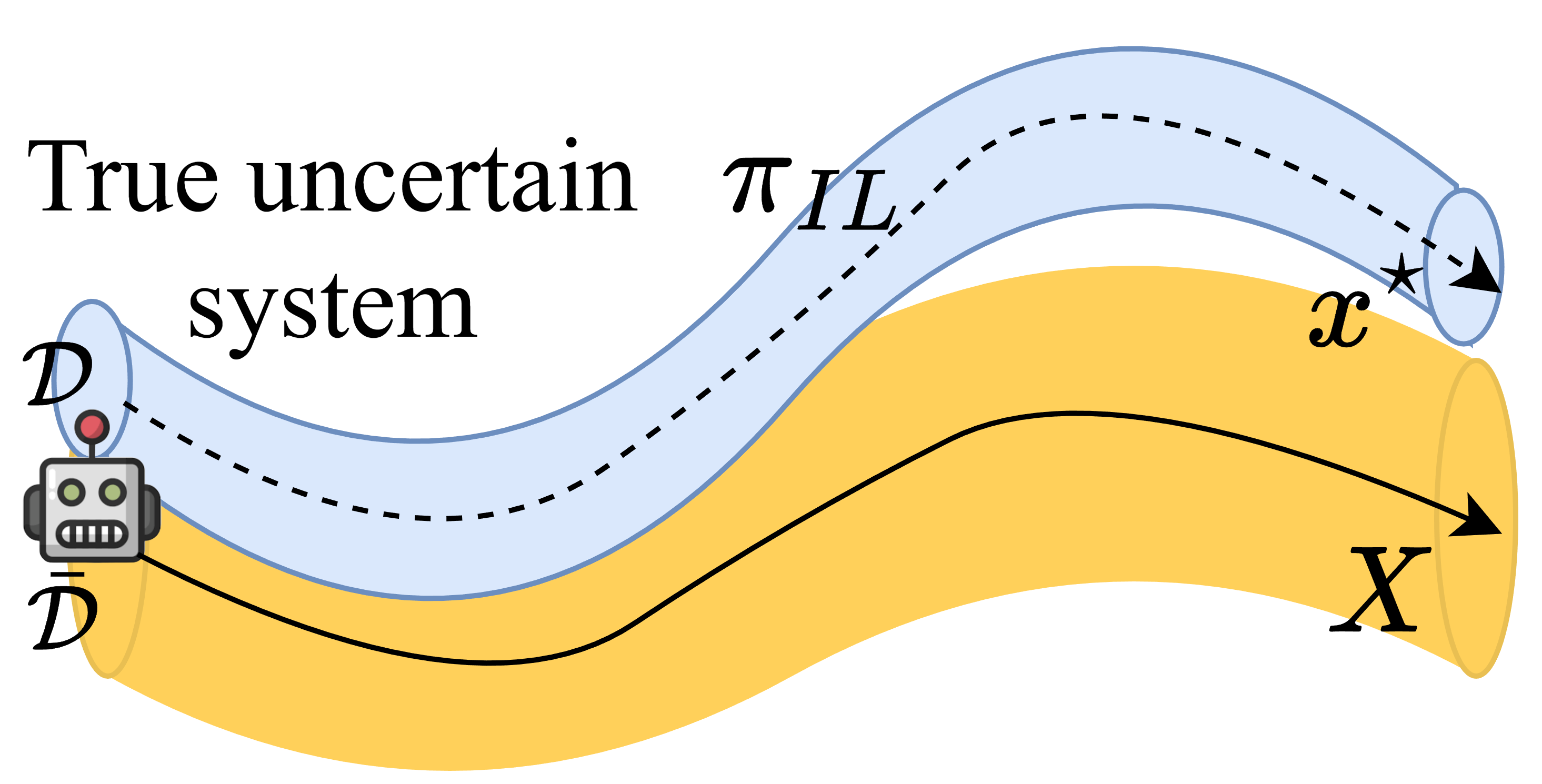
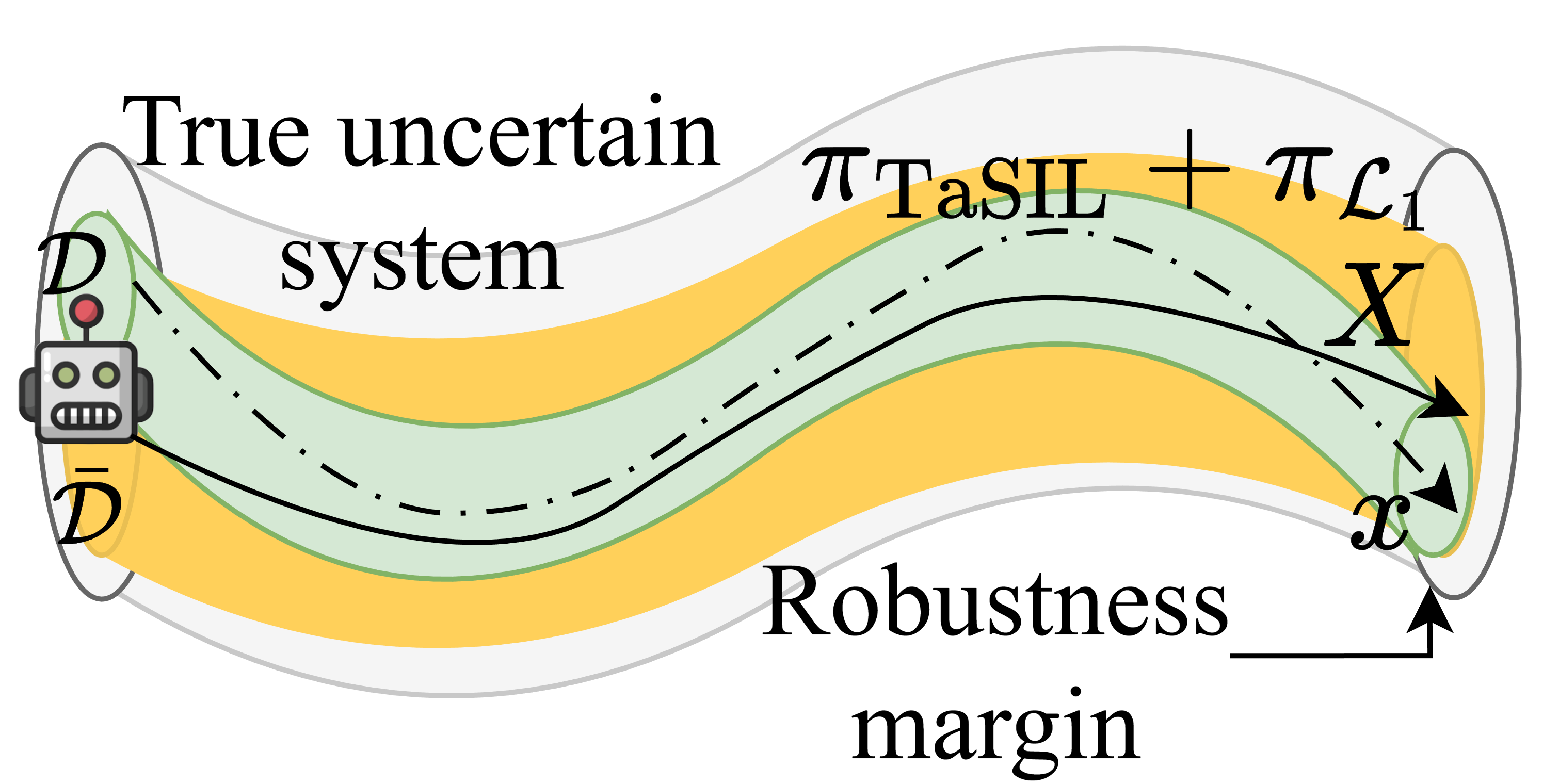
Figure 3: Illustration of policy-induced shift.
Theoretical Guarantees: Policy and Uncertainty Decoupling
By leveraging contraction properties in the nominal system and regularity assumptions on policy classes, the authors show the TIG can be decoupled into a sum of two terms: the policy-induced imitation gap (policy-IG) and the uncertainty-induced imitation gap (uncertainty-IG). TaSIL bounds the policy-IG by solving a derivative-matching optimization over expert trajectories, with sample complexity O(logn/n) and confidence scaling O(1/δ). L bounds the uncertainty-IG through robust adaptive feedback synthesized under Wasserstein ambiguity sets, providing a-priori certificates in distribution space that are independent of data-driven adversarial training. The interplay between TaSIL and L enables layered guarantees robust to both the compounding effects of policy errors and exogenous disturbances.
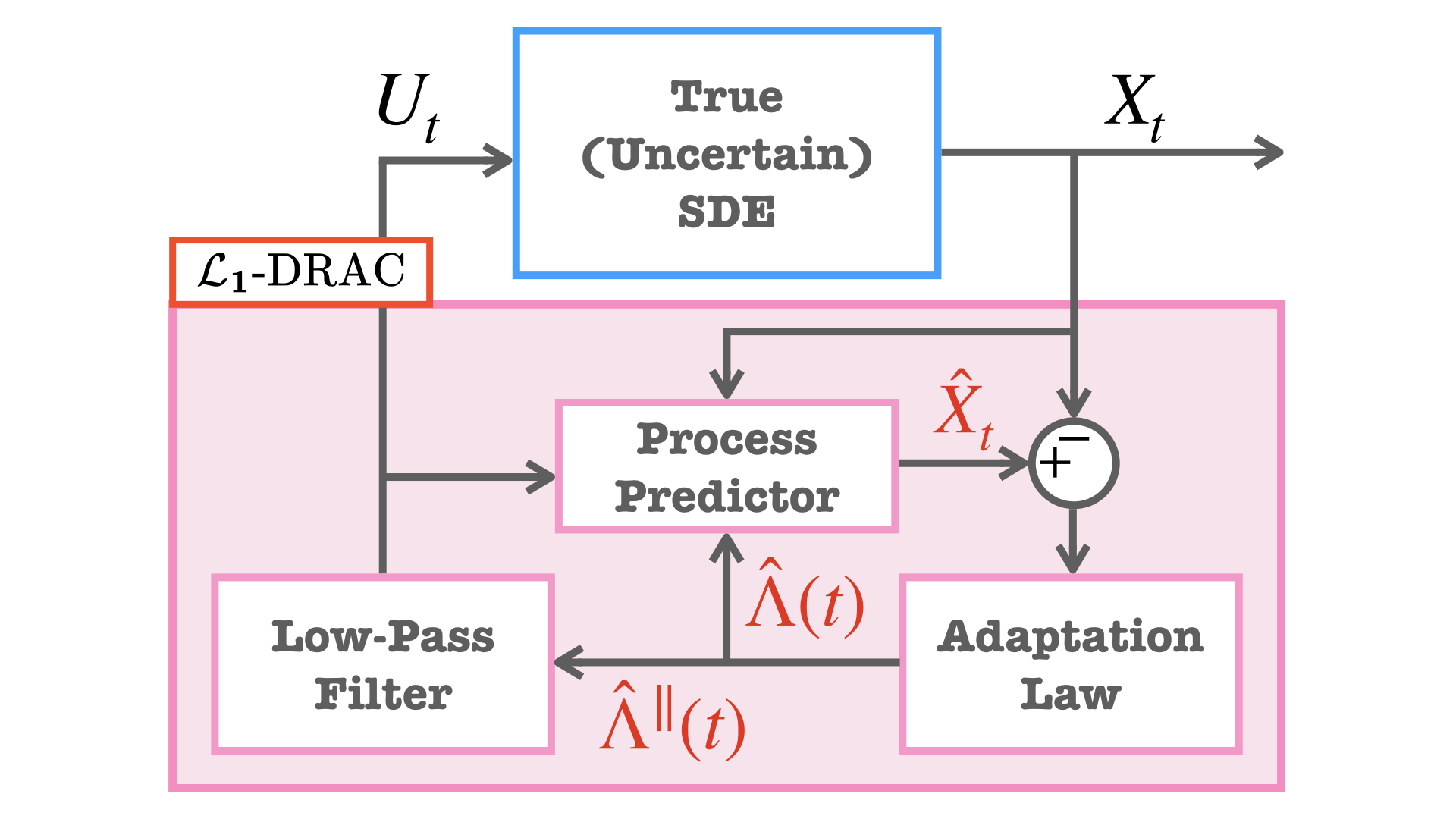
Figure 4: Architecture of the L controller, comprising a process predictor, adaptation law, and low-pass filter for sample-free distributional robustness.
Numerical Validation and Empirical Observations
Empirical evaluation involves a canonical uncertain system with a nominal model, independently perturbed by drift and diffusion uncertainties. Three regimes are analyzed:
- TaSIL on the nominal system: Minimal imitation gap, consistent with theoretical contraction-based reduction.
- TaSIL on the uncertain system: Uncertainty destabilizes the system and compounds the imitation gap.
- TaSIL + L on the uncertain system: Joint law stabilization with bounded imitation gap, confirming decoupled mitigation of both policy and uncertainty-induced components.
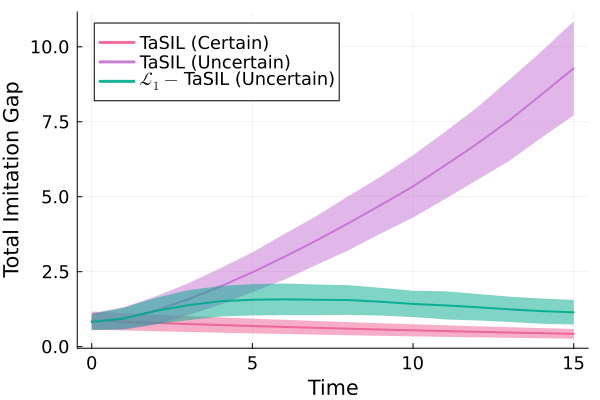
Figure 5: Comparison of total imitation gap for (i) TaSIL (nominal), (ii) TaSIL (uncertain), and (iii) TaSIL+L (uncertain). Only the layered approach preserves bounded gap under uncertainty.
Implications and Future Directions
The modular layered construction admits compositional certificates for certifiable autonomy pipelines, including integration of high-dimensional perception modules and data-driven components lacking independent robustness proofs. The authors' decoupled approach allows the use of standard TaSIL training, with distributional robustness achieved via the L controller without additional adversarial data augmentation. The results indicate potential for scalable, task-agnostic, certifiable autonomy architectures with distributional robustness guarantees rooted in probability measure theory and contraction analysis. Future work is expected to address more expressive bi-level contracts, scalable data-dependent certification, and extension to hierarchical architectures incorporating vision-based perception.
Conclusion
This manuscript provides an authoritative framework for distributionally robust imitation learning in uncertain dynamical systems, demonstrating that layered integration of TaSIL and L1-DRAC yields certifiable performance against a wide spectrum of distribution shifts. The provable separation and bounding of policy and uncertainty-induced gaps enable formal guarantees unattainable via monolithic IL or robust control approaches alone. The work establishes principled methodology for achieving certifiable autonomy, with direct implications for robust deployment of learning-based controllers in critical real-world applications.