Xiaomi MiMo-VL-Miloco Technical Report
Abstract: We open-source \textbf{MiMo-VL-Miloco-7B} and its quantized variant \textbf{MiMo-VL-Miloco-7B-GGUF}, a pair of home-centric vision-LLMs that achieve strong performance on both home-scenario understanding and general multimodal reasoning. Built on the MiMo-VL-7B backbone, MiMo-VL-Miloco-7B is specialized for smart-home environments, attaining leading F1 scores on gesture recognition and common home-scenario understanding, while also delivering consistent gains across video benchmarks such as Video-MME, Video-MMMU, and Charades-STA, as well as language understanding benchmarks including MMMU-Pro and MMLU-Pro. In our experiments, MiMo-VL-Miloco-7B outperforms strong closed-source and open-source baselines on home-scenario understanding and several multimodal reasoning benchmarks. To balance specialization and generality, we design a two-stage training pipeline that combines supervised fine-tuning with reinforcement learning based on Group Relative Policy Optimization, leveraging efficient multi-domain data. We further incorporate chain-of-thought supervision and token-budget-aware reasoning, enabling the model to learn knowledge in a data-efficient manner while also performing reasoning efficiently. Our analysis shows that targeted home-scenario training not only enhances activity and gesture understanding, but also improves text-only reasoning with only modest trade-offs on document-centric tasks. Model checkpoints, quantized GGUF weights, and our home-scenario evaluation toolkit are publicly available at \href{https://github.com/XiaoMi/xiaomi-mimo-vl-miloco}{https://github.com/XiaoMi/xiaomi-mimo-vl-miloco} to support research and deployment in real-world smart-home applications.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining the “Xiaomi MiMo-VL-Miloco Technical Report” in Simple Terms
Overview: What is this paper about?
This paper introduces MiMo-VL-Miloco-7B, a smart computer model that can “see” and “read” at the same time. It’s designed to work in homes: it understands what people are doing (like reading or working out) and recognizes hand gestures (like thumbs up or the “OK” sign). It runs locally on devices (not just in the cloud), which helps keep things fast and more private. The team also released a smaller, compressed version so it can run on less powerful hardware.
Key Objectives: What were the main goals?
In everyday language, the researchers wanted to:
- Build a home-focused AI that accurately recognizes common activities and gestures from video.
- Keep the model good at general tasks too (like understanding videos, screens, and text), not just home stuff.
- Make it efficient enough to run on home devices for speed and privacy.
- Share tools and models so others can use and improve them.
Methods: How did they build and train it?
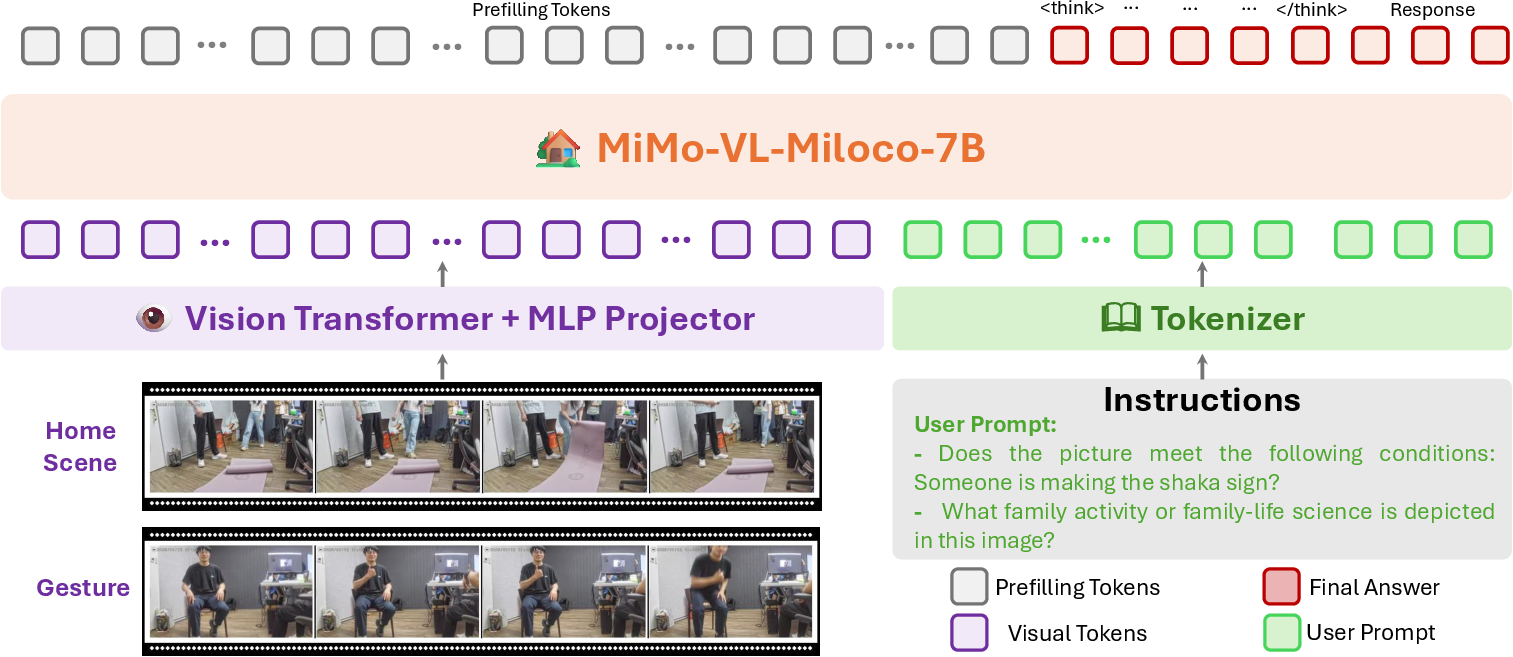
Think of this model like a three-part brain for understanding the world:
- A “vision part” (Vision Transformer) looks at images and video frames.
- A “connector” (projector) translates what it sees into a form the language part understands.
- A “language part” (LLM) reads instructions and explains or answers questions.
They used a two-stage training plan, like school followed by coaching:
- Supervised Fine-Tuning (SFT): “Classroom learning”
- The model is shown lots of labeled examples from home situations: people reading, working out, watching TV, playing games, using phones, and making gestures (thumbs up, OK, V sign, shaka, open palm).
- Chain-of-thought supervision: the model is taught to show its reasoning steps, like explaining how it knows someone is “reading” (e.g., “They’re holding a book and looking down at pages”).
- Token-budget-aware reasoning: the model also practices giving short, direct answers when speed matters. Tokens are just pieces of text; a “budget” means keeping answers short to be fast on-device.
- Reinforcement Learning (RL): “Coaching with rewards”
- After classroom training, the model practices tougher general tasks it started to forget (like video timing, GUI elements on screens, and math problems).
- They used a method called GRPO (Group Relative Policy Optimization). Simple idea: for the same question, the model tries several answers in a group, compares how good each is, and learns more from the better ones.
- Rewards are customized:
- Video timing: the model is rewarded when it pinpoints the correct time segment in a video.
- GUI grounding: it gets a higher reward when it draws a box that closely matches the correct spot on the screen.
- Math/reasoning: it’s rewarded when the final answer matches exactly.
- They filter training data to skip questions that are too easy or too hard, which stabilizes learning.
- They also provide a quantized version (GGUF), which is like compressing the model so it runs on smaller devices without using too much memory.
Main Findings: What did they discover?
This model is very strong at home tasks and competitive on general ones:
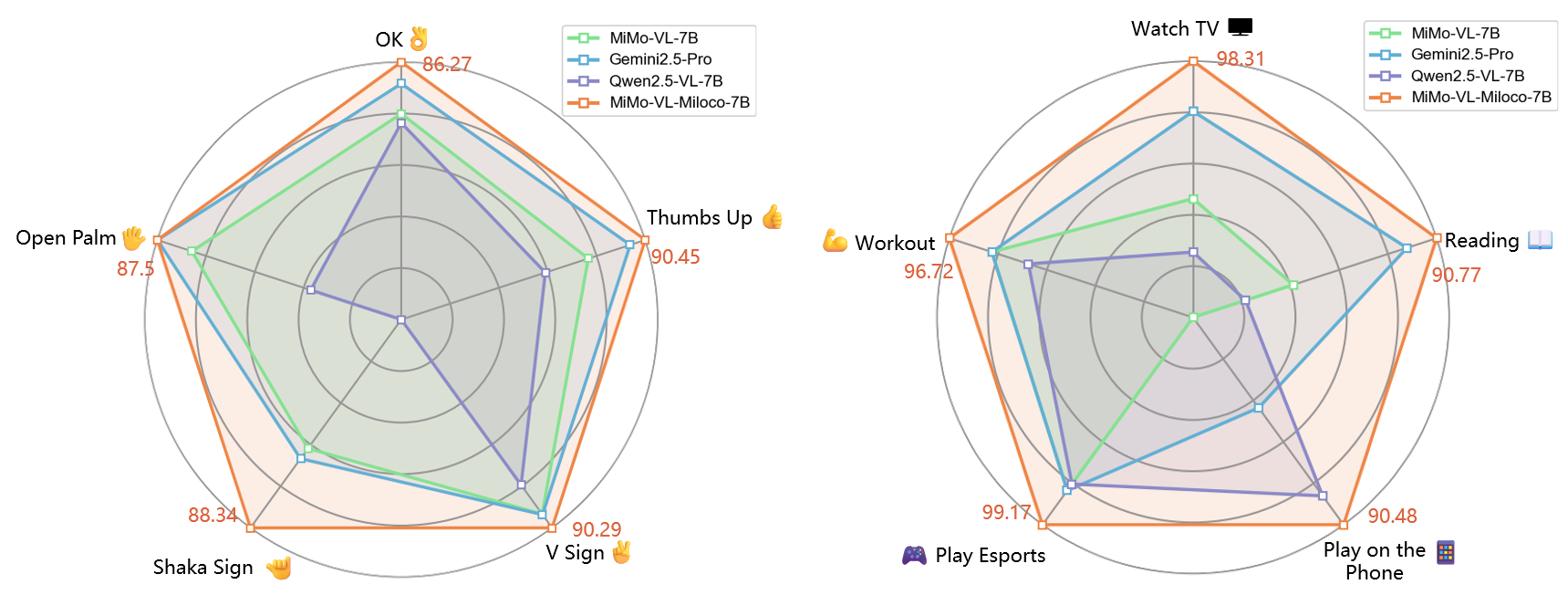
- Home activities and gestures: It achieved the highest scores across categories. For example:
- Activities: Watch TV (98.3), Play Esports (99.2), Workout (96.7), Reading (90.8), Play on the Phone (90.5).
- Gestures: OK (86.3), Thumbs Up (90.5), V Sign (90.3), Shaka (88.3), Open Palm (87.5).
- F1-score is a single number that balances “how often it’s right” and “how many it correctly finds.” Higher is better.
- Video understanding: It improved on public tests like Video-MMMU and Charades-STA, meaning it’s better at understanding what happens over time in videos.
- General multimodal tasks: It did very well on benchmarks like MMMU-Pro and MMLU-Pro (these are broad tests of understanding pictures, videos, and text across many subjects).
- Documents and OCR (reading text in images): It’s still good, though slightly behind its base model on a few document-heavy tasks. This is a small trade-off for being great at home scenarios.
Why is this important? Because it shows a model can be trained to be excellent at specific home tasks while still being strong at general understanding, all while running locally for privacy and speed.
Implications: What does this mean for the future?
- Smarter, safer home assistants: The model can react to what’s happening, not just follow simple rules. For example, if someone starts reading, it can turn on a reading lamp; if the baby cries at night, it can dim lights and send a quiet alert.
- Better privacy and low delay: Running on local devices means less data sent to the cloud and faster responses.
- Open ecosystem: By releasing the model, a smaller version, and tools, the authors help researchers and developers create real-world smart-home apps.
- Next steps: The team wants to add more senses (like audio and millimeter-wave signals), compress the model further, and make it even faster and more accurate.
In short, this paper shows how to build a home-focused AI that sees and thinks efficiently, protects privacy, and still performs well on general tasks—bringing us closer to helpful, context-aware smart homes.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of concrete gaps, uncertainties, and open questions that future work could address to make the claims, methods, and deployment of MiMo‑VL‑Miloco‑7B more complete and reproducible.
- Dataset transparency and reproducibility: No public release or detailed statistics of the proprietary home‑scenario dataset (size, splits, demographics, environments, camera models, resolutions, lighting, occlusions, multi‑person scenes), making it hard to assess bias and replicate results.
- Limited scenario coverage: Home activity and gesture categories are restricted to 5 activities and 5 gestures; it is unclear how the model performs on a broader, more diverse or culturally varied set of household activities and gestures.
- Cross‑household generalization: No evaluation under domain shifts such as different homes, furniture layouts, camera placements/angles, non‑MiJIA cameras, varying network conditions, or presence of pets/children.
- Robustness to visual challenges: Missing stress tests for low light, backlighting, motion blur, occlusion, clutter, reflections, and crowded scenes; no analysis of failure modes with confusion matrices or per‑condition breakdowns.
- Multi‑person and interaction handling: Unclear performance when multiple people are present, overlapping gestures occur, or activities involve interactions (e.g., passing objects, caregiving), including ambiguity resolution.
- Temporal fidelity: The 2 FPS sampling and max 256 frames are fixed, but there is no ablation on sampling rates, frame counts, or temporal resolution for fast actions, long‑duration activities, or streaming inputs.
- On‑device performance metrics: Absent measurements for latency, throughput, energy consumption, memory footprint, and thermal behavior on target edge hardware (CPU/NPU/GPU), both for full‑precision and
GGUFquantized variants. - Quantization impact: No reported accuracy/loss differences between full‑precision and
GGUFweights across tasks; missing guidance on bit‑width, quantization scheme, and hardware‑specific optimizations. - Token‑budget‑aware reasoning trade‑offs: No quantitative analysis of how token‑budget constraints affect accuracy, latency, and user experience; missing ablations on CoT length vs. performance and inference speed.
- CoT supervision details: Unspecified ratio/mixing of CoT vs. direct‑answer data, standardization procedures for reasoning templates, and their effect on hallucinations, faithfulness, and robustness across tasks.
- Controllability of reasoning: No mechanisms or evaluation for controlling when the model emits CoT vs. short answers; missing reliability checks (e.g., self‑consistency, verification) for long‑form reasoning outputs.
- Catastrophic forgetting quantification: The paper notes regressions after SFT, but lacks systematic retention metrics, trade‑off curves, and ablations on data weighting/scheduling or alternative continual learning strategies.
- RL setup clarity and reproducibility: The GRPO objective is typeset with malformed LaTeX; core hyperparameters (group size
G,epsilon,beta, KL penalty schedule, rollouts per query, learning rate, steps/epochs) and training compute are not specified. - Difficulty filtering criteria: The “difficulty‑aware” filter lacks a formal definition, thresholds, estimation procedure, and ablation showing its impact on convergence, stability, and knowledge retention.
- Reward design safety: Rewards cover accuracy and format compliance only; there is no safety‑aware reward shaping (e.g., penalizing harmful or overconfident outputs) or constraints to prevent reward hacking in multimodal tasks.
- GUI grounding generalization: Data sources for GUI grounding are not detailed; no evaluation across OS/browser/app diversity, DPI/resolution changes, localization/language variations, or dynamic UI states.
- Calibration and uncertainty: No confidence calibration, uncertainty estimation, or thresholding strategy to reduce false positives/negatives—critical for triggering home automation safely.
- End‑to‑end automation evaluation: Absent closed‑loop tests from perception to action in real homes (e.g., success rates, time‑to‑action, error recovery, user satisfaction), including safe fallback policies.
- Adversarial and spoofing robustness: No tests for adversarial frames, replay attacks, printed/onscreen gestures, or manipulation of camera feeds; no defense strategies discussed.
- Privacy/security practices: Data retention, encryption, on‑device logging, model updates, and access control policies are not specified; unclear compliance posture for sensitive home environments.
- Ethical and demographic coverage: No reporting on participant demographics or consent procedures; potential fairness issues remain unexplored (age, body types, cultural gesture variance, clothing/skin‑tone effects).
- Language and localization: While benchmarks include English/Chinese, it’s unclear how home‑scenario instructions and outputs generalize across languages, dialects, or code‑switching in real deployments.
- Sensor fusion roadmap: The model is vision‑only; concrete designs, synchronization, calibration, and fusion strategies for audio, mmWave, depth, or other sensors are not defined or evaluated.
- Activity granularity and segmentation: Gesture/activity outputs appear categorical; there is no support for temporal segmentation of activities, sub‑activity decomposition, or multi‑label concurrent activity detection.
- Spatial grounding in home scenes: The model does not expose structured outputs (e.g., 2D/3D keypoints, instance segmentation, room/zone mapping) that could improve reliability for downstream automation.
- Safety constraints in RL and inference: No formal guardrails, content filters, or constrained decoding policies tailored to home automation (e.g., “never trigger high‑risk actions without secondary confirmation”).
- Benchmark prompt and evaluation protocol: Missing exact prompts, seeds, decoding parameters, and judge configurations (especially for GPT‑4o‑judged tasks), limiting comparability and reproducibility.
- OCR/document trade‑offs: Not quantified systematically; lacking multi‑objective training that explicitly balances home specialization with document/OCR performance, plus ablations on data mixtures and losses.
- Training details and compute budget: SFT/RL steps, epoch counts, gradient clipping, optimizer schedules, data ordering, and total compute are absent—hindering replication and cost estimation.
- Real‑time/streaming integration: No API or pipeline details for streaming video, sliding‑window context, or backpressure handling in edge deployments.
- Safety‑critical task evaluation: The illustrative “baby cries after 10 p.m.” scenario relies on audio, yet audio sensing is not integrated or evaluated; a vision‑only system’s limitations in such tasks remain unaddressed.
- Maintenance and continual updates: No strategy for privacy‑preserving continual learning/federated updates, drift detection, rollback, or versioning in changing home environments.
- Human‑in‑the‑loop interaction: Absent mechanisms for user feedback, correction, or active learning to improve recognition in a specific household while safeguarding privacy.
- License and usage constraints: Dataset is not released; licensing and compliance requirements for deploying in different regions/jurisdictions are unspecified.
- Failure analysis: No qualitative case studies or error taxonomies for misrecognized gestures/activities; lacking guidance on when and why the model fails and how to mitigate those failures.
Practical Applications
Immediate Applications
The following applications can be deployed now using MiMo‑VL‑Miloco‑7B and its quantized GGUF variant, the released checkpoints, and the Xiaomi Miloco framework. Each item includes sector linkages, example tools/products/workflows, and feasibility notes.
- Context‑aware smart‑home automations (consumer electronics, energy)
- What: Trigger lights, audio, HVAC, and device states based on recognized home activities (e.g., Reading → turn on reading lamp; Workout → improve ventilation; Watch TV → dim lights) and simple hand gestures (Thumbs Up, OK, V Sign, Open Palm, Shaka).
- How: MiJIA camera stream → MiMo‑VL‑Miloco on edge device (GGUF) → event bus (e.g., Miloco, MQTT, Home Assistant) → automation rules.
- Dependencies/assumptions: Adequate camera placement/lighting; supported edge compute (e.g., NPU/GPU with enough VRAM for 7B or quantized footprint); user consent and on‑device storage policies; limited gesture vocabulary (5 gestures).
- Gesture‑based, speech‑free control for accessibility and quiet environments (consumer electronics, assistive tech)
- What: Control TV, smart speakers, and appliances with “Open Palm to pause,” “Thumbs Up to confirm,” etc.
- How: On‑device inference on hubs/set‑top boxes; bind recognized gestures to OS‑level or app intents.
- Dependencies/assumptions: Fixed, well‑lit field of view; discrete gesture set; latency budgets met by token‑budget‑aware reasoning mode.
- Privacy‑preserving event detection on cameras (security, compliance)
- What: Detect and summarize relevant events (e.g., “person reading,” “workout started,” “screen use after midnight”) locally without cloud streaming.
- How: Edge deployment of MiMo‑VL‑Miloco; temporal grounding for “when” queries over stored clips; generate concise summaries using token‑budget mode.
- Dependencies/assumptions: Local storage capacity; per‑household policy on retention; domain shift across households may require light calibration.
- Timeline search and video highlights for home cameras (software, consumer electronics)
- What: Query long recordings with natural language (“When did someone start reading?” “Find segments of workout”) using temporal grounding capabilities.
- How: Index video with periodic embeddings + predicted event spans; UI for timeline scrubbing; export short clips.
- Dependencies/assumptions: Frame sampling (2 FPS) and max‑frame limits; acceptable recall for defined activities; compute budget for long‑context processing.
- Prototyping of on‑device multimodal agents by developers and researchers (academia, software)
- What: Use open checkpoints, GGUF weights, and the home‑scenario evaluation toolkit to build/test edge VLM workflows, replicate experiments, and evaluate chain‑of‑thought/token‑budget strategies.
- How: Integrate with Gradio demo, Miloco framework, or Home Assistant; swap in custom camera feeds; run ablations on SFT vs GRPO.
- Dependencies/assumptions: Familiarity with quantized runtimes (e.g., llama.cpp derivatives), GPU/CPU support, and evaluation frameworks.
- GUI‑aware home app automation and RPA (software, robotics‑adjacent)
- What: Use the model’s GUI grounding strengths to automate navigation of smart‑home dashboards/mobile apps (e.g., locate “Thermostat” widget; tap “Night Mode”).
- How: Screen capture → GUI element grounding → action dispatch via ADB/UI automation; integrate with existing RPA pipelines.
- Dependencies/assumptions: Consistent UI layouts; access to device screen stream; alignment of predicted bounding boxes with actionable elements.
- Energy‑saving automations driven by occupancy/activity (energy, smart buildings)
- What: Reduce energy use by recognizing inactivity or switching contexts (e.g., stop HVAC boost when workout ends; turn off TV when no one is watching).
- How: Activity events → rules engine → smart plugs/thermostat APIs; build “context packs” per room.
- Dependencies/assumptions: Device integrations available; tolerable false‑positive/negative rates; user override mechanisms.
- At‑home study/attention cues and parental controls (education, consumer electronics)
- What: Detect reading vs phone usage to adjust lighting or send gentle nudges; limit app access when prolonged phone activity is detected in study periods.
- How: Local inference → time‑bounded counters → policy triggers (screen time controls, light color temperature shifts).
- Dependencies/assumptions: Non‑medical, non‑behavioral‑therapy use; opt‑in consent; activity taxonomy limited to tasks trained.
- Lightweight analytics for user experience research (academia, HCI/UX)
- What: Evaluate how token‑budget‑aware reasoning impacts latency/quality on edge; study CoT vs concise outputs in real use.
- How: Instrumentation in Miloco demo; log anonymized latency and accuracy under different budgets and prompts.
- Dependencies/assumptions: Proper anonymization; IRB/ethics review if human data is collected.
- Local multimodal assistants with general competence (software, consumer electronics)
- What: On‑device VLM for routine vision/video Q&A and household situational queries with solid performance on Video‑MMMU, MMLU‑Pro, DocVQA.
- How: “Quick mode” (token‑budget) for low‑latency answers; “deep‑reasoning mode” for complex queries; offline fallback when internet is unavailable.
- Dependencies/assumptions: Slightly weaker OCR/math vs base model in some cases; careful UX to route tasks appropriately.
Long‑Term Applications
These applications are feasible with further research, scaling, additional sensing, or ecosystem development.
- Multisensor household perception (audio + mmWave + video fusion) for robust context (consumer electronics, healthcare, smart buildings)
- What: Combine video, audio (crying detection), and mmWave for presence, fine‑grained spatial perception, and occlusion‑robust activity understanding.
- Potential products: “Holistic home sentinel” hubs; privacy‑preserving occupancy maps for HVAC zoning; infant‑care assistants.
- Dependencies/assumptions: New model architectures; synchronized multimodal data collection; on‑device fusion; regulatory approvals for RF sensing.
- Assistive domestic robotics that follow activity/gesture context (robotics, eldercare)
- What: Robots that interpret household activities/gestures to hand over items, adjust environment, or assist workouts.
- Potential workflows: VLM → semantic scene understanding → task planner → low‑level control.
- Dependencies/assumptions: Reliable grasping/navigation; safety certifications; expanded gesture and activity ontologies; robust temporal grounding in dynamic scenes.
- Proactive, routine‑learning household copilots (software, AI agents)
- What: Agents that anticipate user needs (e.g., preparing reading setup at habitual times) using long‑horizon video understanding and reinforcement learning.
- Potential tools: On‑device preference models; explainable policy learners constrained by token budget; federated personalization.
- Dependencies/assumptions: Continual learning without catastrophic forgetting; privacy‑preserving personalization; transparent opt‑out.
- Scalable, privacy‑first smart‑building management (energy, facilities)
- What: Aggregate on‑device event summaries across apartments/offices to optimize shared energy loads, lighting schedules, and maintenance.
- Potential products: Edge‑to‑edge building platforms that share only aggregated statistics; anomaly detectors for equipment usage.
- Dependencies/assumptions: Edge orchestration, secure aggregation, tenant consent; standardized event schemas; building‑level APIs.
- Clinical‑adjacent RPM and wellness insights (healthcare)
- What: Non‑medical indicators (reading duration, sedentary time, workout adherence) for wellness coaching or pre‑screening.
- Potential products: Wellness dashboards integrated with insurers/employers; home physio adherence trackers.
- Dependencies/assumptions: Not medical‑grade; bias and fairness audits; clinical validation and regulatory pathways for any medical claims.
- Education and focus support with richer activity taxonomy (education, EdTech)
- What: Broader set of study behaviors (note‑taking, whiteboard use, group study) and distractions inferred to adapt learning environments.
- Potential tools: Local study companions; ambient device policies guided by activity sequences; analytics for self‑reflection.
- Dependencies/assumptions: Expanded datasets and ontologies; student privacy safeguards; transparent, opt‑in usage.
- Standardization and policy frameworks for on‑device multimodal AI (policy, standards)
- What: Define evaluation suites and certification for edge VLM privacy, latency, and safety (inspired by the released toolkit).
- Potential outcomes: Device labels like “Edge‑AI Private,” procurement checklists, national/international standards.
- Dependencies/assumptions: Multi‑stakeholder bodies; reproducible benchmarks; auditable deployment pipelines.
- Federated, household‑specific fine‑tuning to reduce bias and domain shift (software, privacy tech)
- What: Personalize models to each home’s lighting/angles/gestures without centralizing video data.
- Potential workflows: Periodic on‑device SFT with GRPO‑style RL; secure aggregation of model deltas.
- Dependencies/assumptions: Efficient on‑device training; differential privacy; robust safeguards against model inversion.
- Advanced GUI agents for cross‑app automation beyond smart home (software, RPA)
- What: Generalize ScreenSpot capabilities to automate desktop/mobile apps for seniors or low‑vision users (paying bills, booking appointments).
- Potential products: Personal RPA companions with visual grounding; safety layers for sensitive actions.
- Dependencies/assumptions: Broader training for diverse GUIs; secure credential handling; human‑in‑the‑loop oversight.
- Sustainable edge AI operations (energy, green computing)
- What: Token‑budget‑aware reasoning and quantization strategies to minimize energy per inference at scale (ISPs, device OEMs).
- Potential tools: Dynamic budget controllers; eco‑mode profiles for home hubs; fleet‑level telemetry for energy KPIs.
- Dependencies/assumptions: Hardware‑software co‑design; standardized reporting; careful QoS trade‑offs.
Notes on Cross‑Cutting Assumptions and Risks
- Data and model generalization: The home activity/gesture set is limited; domain shift (camera angles, cultures) may reduce accuracy without adaptation.
- Privacy and ethics: Even on‑device processing requires clear consent, retention limits, and safeguards against function creep.
- Hardware constraints: Real‑time performance depends on local compute; quantized GGUF helps but may require NPUs or compact GPUs.
- Safety and reliability: False positives/negatives in automations must be mitigated with confirmations, fallbacks, and audit logs.
- Benchmark trade‑offs: Slight regressions in document‑centric OCR/math suggest routing those tasks to specialized models in multi‑agent setups.
Glossary
- AdamW: An optimization algorithm that adds decoupled weight decay to Adam for better generalization. "We utilize the AdamW\cite{kingma2014adam} optimizer with a total batch size of 128 and a learning rate of ."
- Advantage estimation: In reinforcement learning, the estimation of how much better an action is compared to a baseline; used to guide policy updates. "an algorithm that eliminates the need for a separate critic model by leveraging group-based advantage estimation."
- Backbone (model backbone): The core network component providing general capabilities that other modules build upon. "the LLM backbone, responsible for text comprehension and reasoning."
- Bounding box: A rectangular region used to localize objects/elements in an image or interface. "For GUI tasks, the model predicts a bounding box $B_{\text{pred}$."
- CenterAcc: A GUI-grounding metric measuring accuracy of predicted center positions relative to targets. "recording 89.8\%, 92.1\%, and 37.8\% CenterAcc on ScreenSpot~\cite{cheng2024seeclick}, ScreenSpot-v2~\cite{cheng2024seeclick}, and ScreenSpot-Pro~\cite{cheng2024seeclick}, respectively."
- Chain-of-thought (CoT) annotations: Annotated reasoning steps that explicitly describe how a model reaches an answer. "we move beyond simple label prediction by generating chain-of-thought (CoT) annotations."
- Chain-of-thought supervision: Training strategy that teaches models to produce explicit reasoning steps. "we further incorporate chain-of-thought supervision and token-budget-aware reasoning, enabling the model to learn knowledge in a data-efficient manner while also performing reasoning efficiently."
- Catastrophic forgetting: When a model loses previously learned capabilities after training on new tasks. "catastrophic forgetting of previously learned capabilities."
- Continual learning: A paradigm focused on learning sequentially without forgetting prior knowledge. "consistent with findings in continual learning literature\cite{cao2024generative}"
- Critic model: In actor–critic RL, the value estimator that evaluates actions; GRPO avoids using it. "an algorithm that eliminates the need for a separate critic model"
- Dynamic resolution strategy: Representing inputs with variable resolution or patching to balance detail and efficiency. "we adopt a dynamic resolution strategy, representing each input image with up to 4,096 patches of pixels and a maximum generation budget of 32,768 tokens."
- Edge deployment: Running AI models locally on devices with strict latency/privacy constraints. "which is important for latency-sensitive edge deployment \cite{zeng2024token, zheng2025review}."
- Edge devices: Local hardware (e.g., cameras, hubs) where models run without relying on the cloud. "call for compact models that can run locally on edge devices instead of relying solely on cloud inference"
- Exact Match (EM): A strict evaluation metric checking if a model’s final answer exactly equals the ground truth. "In text-only reasoning, MiMo-VL-Miloco-7B achieves an Exact Match (EM) score of 68.5 on MMLU-Pro~\cite{wang2024mmlu}"
- F1 score: The harmonic mean of precision and recall used to assess classification performance. "attaining leading F1 scores on gesture recognition and common home-scenario understanding"
- Frames per second (FPS): The rate at which video frames are sampled or processed. "For video benchmarks, frames are sampled at 2 FPS"
- GGUF: A quantization and weight storage format optimized for efficient local inference. "Model checkpoints, quantized GGUF weights, and our home-scenario evaluation toolkit are publicly available"
- Greedy search: A deterministic decoding strategy that selects the highest-probability token at each step. "greedy search is used for standard visual question answering tasks."
- Group Relative Policy Optimization (GRPO): A PPO-style RL algorithm that uses group-normalized advantages and avoids a critic network. "In the RL stage, we employ Group Relative Policy Optimization (GRPO), an algorithm that eliminates the need for a separate critic model by leveraging group-based advantage estimation."
- GUI agent: An agent that perceives and acts within graphical user interfaces via grounding and localization. "unlocking the model's potential as a GUI agent."
- GUI grounding: Aligning textual or task instructions with locations/elements within a graphical user interface. "specifically video understanding, GUI grounding, and complex multimodal reasoning."
- Intersection over Union (IoU): A metric measuring overlap between predicted and ground-truth regions or intervals. "The accuracy reward is calculated using the Intersection over Union (IoU) of the 1D time intervals:"
- KL-divergence penalty: A regularization term encouraging a policy to stay close to a reference distribution. "where and are hyperparameters controlling the clipping range and the KL-divergence penalty, respectively."
- LLM: A transformer-based model trained on large text corpora for language understanding and generation. "latent space of the LLM"
- Latent space: The embedding space where encoded features reside for downstream processing. "align visual encodings with the latent space of the LLM"
- LMMs-Eval: A framework for evaluating large multimodal models with consistent, task-specific logic. "We extend the LMMs-Eval framework~\cite{zhang2025lmms} to better support models capable of long-chain-of-thought (CoT) reasoning and refine task-specific evaluation logic"
- Maximum sequence length: The upper bound on the number of tokens the model can process in a sequence. "The maximum sequence length was set to 32,768"
- Multi-Layer Perceptron (MLP): A feedforward neural network used here as a projector to map visual features to text embeddings. "a projector composed of a Multi-Layer Perceptron (MLP), serving to align visual encodings with the latent space of the LLM"
- Multimodal LLM (MLLM): A model that processes and reasons over multiple modalities like text, images, and video. "multimodal LLMs have rapidly become the core infrastructure for modern AI systems"
- OCR: Optical Character Recognition, extracting text from images/documents. "OCR understanding, video understanding, and multimodal reasoning"
- Pass@1: The probability that the model solves a problem on its first attempt; common in code/math benchmarks. "it attains 95.2 Pass@1 on MATH500~\cite{hendrycks2021measuring}"
- Policy (reinforcement learning): The probability distribution over outputs/actions conditioned on inputs. "For each query , GRPO samples a group of outputs from the current policy ."
- Proximal Policy Optimization (PPO): A popular RL algorithm using clipped objective updates and typically a value network. "This approach reduces memory overhead and training complexity compared to standard PPO with a value network."
- Projector: A module that maps visual encoder outputs into the LLM’s embedding space. "a projector composed of a Multi-Layer Perceptron (MLP), serving to align visual encodings with the latent space of the LLM"
- Quantized variant: A lower-precision model version designed for efficient on-device inference. "We open-source MiMo-VL-Miloco-7B and its quantized variant MiMo-VL-Miloco-7B-GGUF"
- Reinforcement learning (RL): A training paradigm where models learn policies via rewards and interactions. "we apply GRPO-based reinforcement learning on top of the SFT model"
- Supervised fine-tuning (SFT): Training a pretrained model on labeled data to specialize it for target tasks. "In the first stage, we perform supervised fine-tuning (SFT) on curated data from home environments."
- Temporal dynamics: Time-dependent behavior and changes within video content. "These tasks bolster the model's robust understanding of temporal dynamics in long videos."
- Temporal Grounding Reward: A task-specific reward computing segment overlap (IoU) between predicted and ground-truth time intervals. "Temporal Grounding Reward."
- Temporal grounding: Linking textual queries to precise time segments within a video. "we focus on the temporal grounding task."
- Temperature (sampling): A decoding parameter controlling randomness; higher values produce more diverse outputs. "use a sampling strategy with temperature 0.6 and top-p 0.95."
- Token-budget-aware reasoning: Training to produce concise answers within a specified token budget, reducing latency. "we introduce token-budget-aware reasoning data for model training, which prompts the model to output direct answers without explicit reasoning steps."
- Tokenization: Converting text into discrete tokens for model input processing. "the instruction prompt is tokenized into text tokens."
- Top-p (nucleus sampling): Sampling from the smallest set of tokens whose cumulative probability exceeds p to balance quality and diversity. "use a sampling strategy with temperature 0.6 and top-p 0.95."
- Value network: The component in actor–critic RL that estimates expected returns; used by PPO but not GRPO. "compared to standard PPO with a value network."
- Vision Transformer (ViT): A transformer-based architecture for visual inputs using patch embeddings and self-attention. "a Vision Transformer (ViT) supporting native resolution, which encodes visual inputs"
- Visual question answering (VQA): A task where models answer questions about images or videos. "greedy search is used for standard visual question answering tasks."
- Visual tokens: Discrete embeddings representing visual patches/frames fed into the LLM. "forming visual tokens."
- Warmup ratio: The fraction of training steps during which the learning rate linearly increases to its target value. "we applied a warmup ratio of 0.03."
Collections
Sign up for free to add this paper to one or more collections.