Scalable Distributed Vector Search via Accuracy Preserving Index Construction
Abstract: Scaling Approximate Nearest Neighbor Search (ANNS) to billions of vectors requires distributed indexes that balance accuracy, latency, and throughput. Yet existing index designs struggle with this tradeoff. This paper presents SPIRE, a scalable vector index based on two design decisions. First, it identifies a balanced partition granularity that avoids read-cost explosion. Second, it introduces an accuracy-preserving recursive construction that builds a multi-level index with predictable search cost and stable accuracy. In experiments with up to 8 billion vectors across 46 nodes, SPIRE achieves high scalability and up to 9.64X higher throughput than state-of-the-art systems.
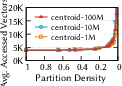



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making “vector search” fast and scalable when the data is huge (billions of items). Vector search is how many AI systems quickly find things that are similar—like matching a question to helpful documents or a photo to similar images. The authors introduce a new system called SPire that keeps search accurate while also being fast and able to handle lots of requests across many computers.
What problem are they trying to solve?
In simple terms: How do you search through billions of items quickly and accurately without overloading the computers?
More specifically, they want to:
- Keep accuracy high (find most of the true closest matches).
- Keep latency low (answers come back in milliseconds).
- Keep throughput high (handle lots of searches per second across many machines).
The big challenge is a trade-off:
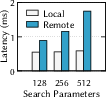
- If you split the data across many machines and connect everything tightly, you get good accuracy—but searches become slow because they have to “hop” across machines a lot.
- If you group data into larger chunks to reduce hopping, the “labels” for those chunks are less precise, so you end up reading far more data to maintain accuracy—which lowers throughput.
SPire aims to balance this trade-off.
How did they approach it?
Think of the data as points on a map. A classic vector search connects nearby points so you can “walk” from one to the next to find similar items. That works on one machine, but across many machines, all the back-and-forth “walking” (network hops) is slow.
SPire uses two key ideas to fix this:
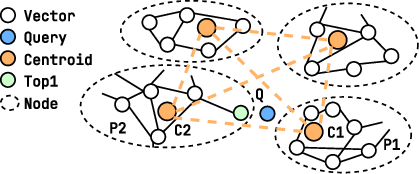
- Find the “just right” group size (balanced granularity)
- They group nearby points into “partitions,” each represented by a “centroid” (like a neighborhood sign).
- If partitions are too big, the sign doesn’t represent the neighborhood well, and you have to check many neighborhoods to be sure you didn’t miss anything—this means reading a ton of data and lowers throughput.
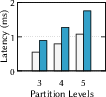
- If partitions are too small, you reduce reading but do more cross-machine hops—this increases latency.
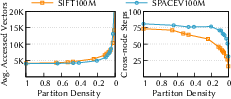
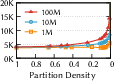
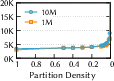
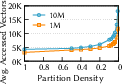
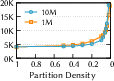
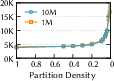
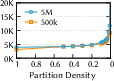
- They introduce a simple measure called partition density (how many partitions you have compared to how many vectors you have). Lower density = bigger partitions. They experimentally find a “sweet spot” where accuracy stays high without exploding the number of vectors you need to read, while also cutting down cross-machine communication.
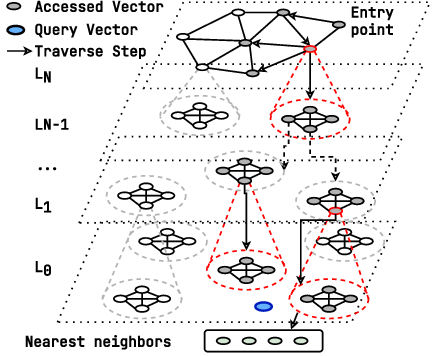
- Build a smart multi-level index that preserves accuracy
- They stack the partitions into levels, like a map with city → district → street:
- Top level: a small, memory-only index (fast to search).
- Lower levels: partitions and vectors stored on SSDs.
- A query starts at the top and picks several promising groups, then goes down one level and repeats—like zooming from city to district to street, but always keeping a few likely options to stay accurate.
- Crucially, they build each level in a way that preserves overall accuracy. They treat each level like a mini search problem and ensure the whole stack stays reliable.
- Cross-machine communication happens only when moving between levels, so the number of network round trips is bounded by how many levels there are. That keeps latency predictable.
In everyday terms: SPire chooses neighborhood sizes that are “just right,” then builds a layered map so searches take a few smart, predictable steps, instead of wandering all over the place or checking too many houses.
What did they find?
Here are the main results the authors report:
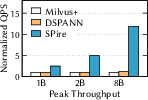
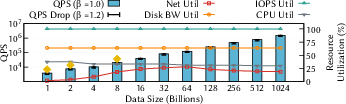
- SPire achieves up to 9.64× higher throughput than state-of-the-art systems, even at production scale (up to 8 billion vectors across 46 machines).
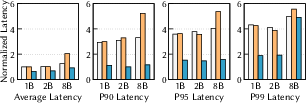
- It keeps latency low and stable, including tail latency (the slowest requests), at all scales they tested.
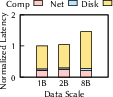
- It scales efficiently: the system often becomes limited by SSD speed (I/O), while still using less than 30% of network and less than 40% of CPU—leaving headroom to grow further.
- It’s practical to run: only the top level is kept in memory, while lower levels and the raw vectors are on SSDs. The top-level index is replicated across machines and can be rebuilt if needed, making it easier to scale and recover from failures.
They also show why this matters with a common baseline:
- If you simply split a classic graph-based index across machines, most of the search steps (over 80%) become cross-machine hops—very slow—so latency explodes. SPire avoids that.
Why is this important?
- Better user experience: Faster and more consistent responses for apps like search, recommendations, and retrieval-augmented generation (RAG).
- Lower costs at scale: Higher throughput per machine means fewer machines for the same workload.
- Predictable performance: Because the hierarchy bounds how many network steps happen, performance is easier to reason about and tune.
- Simpler operations: Keeping only the top level in memory and the rest on SSDs makes the compute layer stateless and easier to scale and recover.
In short, SPire shows a way to make huge vector databases both fast and accurate by:
- Picking the right group size to avoid wasted work.
- Building a layered, accuracy-preserving index so searches take a few smart, predictable steps rather than many slow, chatty ones across machines.
Knowledge Gaps
Below is a single, concise list of the paper’s knowledge gaps, limitations, and open questions that future work could address.
- Lack of a formal model for “partition density” and its relation to read cost: the paper claims vector reads are inversely proportional to density (c ∝ 1/D) but provides no proof, constants, or conditions under which this holds.
- No theoretical guarantees for the “balanced granularity” inflection point: the existence and stability of the threshold across distributions, metrics, and dimensionalities is empirical and dataset-specific.
- Missing methodology for selecting and tuning the “balanced” density in practice: how to profile efficiently on massive datasets, how much data to sample, how often to re-profile under drift, and how to automate the choice online.
- Unspecified per-level accuracy allocation and search parameterization: the paper asserts “accuracy-preserving” recursive construction but does not detail how to set per-level budgets (e.g., m, beam width) to meet a global recall target with guarantees.
- No end-to-end composition guarantee: it is unclear how per-level approximation errors compound and under what assumptions overall recall is maintained when descending the hierarchy.
- Height/depth of the hierarchy lacks formal derivation: the “log S” claim has no explicit linkage to branching factor, density, memory budget, and per-level parameters; a predictive formula is missing.
- Per-level parallelism and latency SLOs are assumed but not analyzed: how many partitions (m) can be probed in parallel without hurting tail latency, how to handle stragglers, and what is the impact on p95/p99.
- Cross-node communication bounds remain unclear: even with hierarchy, worst-case or adversarial query patterns that induce many cross-node hops are not characterized.
- Robustness under skew and hotspots is unaddressed: how the system handles highly non-uniform query distributions, hot partitions, and load imbalance across nodes.
- Update and mutability story is incomplete: there is no concrete mechanism for incremental inserts/deletes/upserts, rebalancing, or online re-clustering without large rebuilds.
- Elasticity details are missing: how partitions move during scale-out/in, how to keep indexes consistent while migrating, and what the operational costs are.
- Fault tolerance beyond top-level regeneration is unspecified: durability and recovery for on-SSD partition indices, handling partial or correlated SSD/node failures, and consistency guarantees during recovery.
- Storage layout and IO patterns are not described: how partitions are persisted, whether vectors are contiguous, how random IO is mitigated, and what prefetch/caching strategies are used at lower levels.
- Memory–IO trade-offs are unexplored: only the top level is cached in memory; the benefits/limits of caching lower-level partitions or vector blocks are not studied.
- Quantization and compression are absent: no discussion of PQ/OPQ or product quantized codes to reduce IO and CPU; how quantization would interact with the balanced granularity.
- Metric generality is unclear: results focus on L2/cosine-like settings; behavior for inner product (MIPS), non-Euclidean metrics, or normalized embeddings is not evaluated.
- Sensitivity to embedding properties is unknown: how anisotropy, outliers, high dimensionality (e.g., 2k–8k), or multimodal mixtures affect density thresholds and fidelity loss.
- Partitioning method dependence is not examined: reliance on k-means (or similar) is assumed; impact of alternative clustering (e.g., balanced k-means, spectral methods) on fidelity and the inflection point is open.
- Interaction with vector norm distribution and boundary effects is not analyzed: whether boundary replication or soft assignment across partitions could reduce fidelity loss without exploding reads.
- Scheduling and backpressure across levels are unspecified: how concurrent queries coordinate fetching m partitions per level, managing SSD queues, and preventing head-of-line blocking.
- Network variability and deployment environments are not covered: how performance changes with different network fabrics, RDMA/CXL availability, or cloud vs on-prem conditions.
- System bottleneck transitions are not mapped: when SSD becomes saturated, how to shift the design (e.g., more in-memory caching, fewer m, different density) to maintain throughput.
- Evaluation breadth is limited: mostly SPACEV/SIFT at 100M for key plots; reproducibility on diverse, real production-scale datasets (modalities, distributions, and varying k) remains to be shown.
- Dependence on recall@5 is narrow: how the balanced point and hierarchy behave for other k (e.g., k=1, k=100) and different recall targets (e.g., 0.95–0.99) is not studied.
- Mixed queries with filters/metadata constraints are not considered: how per-level selection integrates with attribute filters and whether density needs to be conditional.
- Integration with GPUs or accelerators is unaddressed: potential gains from offloading distance computations or batched scanning at lower levels are not explored.
- Security and multi-tenancy concerns are absent: isolation of tenants, data privacy, and performance isolation when sharing the hierarchy across users is not discussed.
- Construction-time costs and resource usage at scale are unspecified: wall-clock build time, CPU/IO/network utilization during bottom-up construction for multi-billion-scale datasets.
- Formal bounds on accuracy/latency/throughput trade-offs are missing: a principled framework to predict throughput and tail latency from density, m, and hardware parameters is needed.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s infrastructure and engineering practices by adopting the paper’s SPire design (balanced partition granularity + accuracy‑preserving recursive hierarchy; top-level in memory, lower levels on SSD; stateless compute tier).
- Sector: Software/AI infrastructure — Managed vector databases at billion-scale
- Application: Upgrade existing vector stores (e.g., HNSW/IVF-based backends in Milvus, Redis-Vector, Vespa, Elasticsearch, OpenSearch plugins) to a SPire-like index to achieve high recall with lower latency and up to order‑of‑magnitude higher throughput at 1–10B vectors.
- Tools/products/workflows: “SPire index” engine module; auto‑tuner to profile and pick balanced partition density; stateless query tier with replicated top-level index; SSD-backed partition store; rolling rebuilds.
- Assumptions/dependencies: High-quality embeddings; NVMe SSDs with sufficient IOPS; network RTTs within typical DC bounds; recall targets explicitly set (e.g., ≥0.9); batch index build or staged reindexing acceptable for updates.
- Sector: Retrieval-Augmented Generation (RAG) — Enterprise knowledge retrieval
- Application: Lower-cost, predictable-latency retrieval over multi‑billion document embeddings for LLMs (chatbots, copilots) with bounded cross-node hops and stable recall.
- Tools/products/workflows: RAG pipeline swap-in of SPire store; per-level parallel fetch of m partitions; autoscaling stateless compute tier; capacity planning via predictable per-level costs.
- Assumptions/dependencies: Embedding stability (distribution shifts modest); object/SSD storage for partitions; per-query SLOs ~10–20 ms are acceptable with 3–5 levels.
- Sector: E-commerce — Semantic search and recommendation
- Application: Similar item retrieval, substitute/complement matching, and personalization over billions of SKU embeddings with high throughput (sustainable QPS) during traffic spikes.
- Tools/products/workflows: SKU embedding pipelines writing to SPire; hot partitions cached; A/B routing between legacy IVF-HNSW and SPire; dashboarding latency/throughput/recall trade-offs.
- Assumptions/dependencies: SKU churn manageable with micro-batch ingestion; accuracy targets enforced via m and level depth; SSD capacity sized for partition fanout.
- Sector: Web search and content platforms — Near-duplicate detection and moderation
- Application: Scalable near-duplicate and similar-content detection (text, image, video) with controllable recall and bounded tail latency across billions of assets.
- Tools/products/workflows: Media embedding index using SPire; moderation queue powered by ANN matches; periodic rebalancing to maintain balanced density.
- Assumptions/dependencies: Cross-modal embeddings available; consistent hashing or locality-aware placement to reduce cross-node hops further.
- Sector: Advertising/Marketing tech — Real-time candidate retrieval
- Application: Low-latency, high-throughput embedding retrieval for ad ranking and lookalike audiences at large scale.
- Tools/products/workflows: Query broker issuing per-level parallel probes; backpressure using predictable per-level costs; horizontal compute scaling without data re-sharding.
- Assumptions/dependencies: Tight SLOs satisfied with shallow hierarchies (e.g., 3–4 levels); steady-state traffic with burst buffers on SSD.
- Sector: Security — Threat intelligence and anomaly detection
- Application: Similarity search over malware, binaries, and behavioral embeddings to accelerate incident response; phishing/site similarity at scale.
- Tools/products/workflows: SPire index embedded into SOC tooling; alert triage via nearest neighbor clusters; partition-level audit trails for forensics.
- Assumptions/dependencies: On‑prem or VPC deployment; privacy constraints; recall thresholds validated against false-positive cost.
- Sector: Healthcare/Pharma — Patient/protein/compound similarity (on-prem)
- Application: Similar cohort retrieval, protein embedding nearest neighbors, and compound similarity in regulated environments with predictable latency.
- Tools/products/workflows: On‑prem cluster with SPire; top-level replica sets for HA; snapshot/restore from SSD partitions; SOPs for periodic rebuilds.
- Assumptions/dependencies: Compliance (HIPAA/GxP): data residency; air-gapped or dedicated hardware; acceptance of micro-batch updates.
- Sector: Academia — Benchmarking and systems research
- Application: Use SPire as a baseline for distributed ANN studies (latency–throughput–accuracy curves; cross-node hop analysis; partition density inflection profiling).
- Tools/products/workflows: Open-source replication; dataset harnesses (SIFT100M, SPACEV100M, BIGANN); simulators for level depth vs memory budget.
- Assumptions/dependencies: Access to commodity clusters; standardized evaluation suites; reproducible profiling methods to discover the “balanced density.”
- Sector: IT/Operations — Elastic, stateless vector serving
- Application: Simplify ops with stateless compute nodes (only top-level in memory), fast recovery (rebuild from SSD), and elastic scale-out under load.
- Tools/products/workflows: Orchestrated compute pools; autoscaling policies keyed to per-level request rates; blue/green top-level replicas.
- Assumptions/dependencies: Reliable distributed storage; sufficient SSD bandwidth to stay I/O-bound; observability on per-level access patterns.
Long-Term Applications
These require further research, engineering, or ecosystem maturation (e.g., incremental updates, learned density selection, geo-distribution) before broad deployment.
- Sector: Hyperscale AI infrastructure — Trillion-vector global stores
- Application: 1012–1013 embedding search with ≤6 hierarchy levels and global anycast routing; regional top-levels with locality-aware partition placement.
- Tools/products/workflows: Geo-partitioned SPire; WAN-aware per-level probing; tiered caches; autoscaling across regions.
- Assumptions/dependencies: Cross-region latency budgets; object storage with high availability; automated hierarchy depth tuning per region.
- Sector: Streaming AI systems — Low-latency incremental indexing
- Application: Continual ingestion (inserts/deletes/updates) with accuracy preservation without full rebuilds.
- Tools/products/workflows: Online re-clustering for boundary partitions; background compaction; per-level drift detectors; versioned top-level graphs.
- Assumptions/dependencies: Algorithms for stable, incremental density maintenance; bounded rebalancing overhead; correctness under concurrent queries.
- Sector: Privacy/Compliance — Right-to-be-forgotten and auditability
- Application: Fast, provable deletions and lineage tracking across hierarchical partitions; selective reindexing.
- Tools/products/workflows: Partition-level tombstones; cryptographic attestations; compliance reports per level; data retention policies tied to hierarchy mapping.
- Assumptions/dependencies: Efficient partition GC; minimal accuracy impact from localized rebuilds.
- Sector: Energy-efficient AI — Cost-/power-optimized retrieval
- Application: Shift ANN compute to SSD I/O with bounded CPU and network use (<40% and <30% observed), tuning density for energy/QPS trade-offs.
- Tools/products/workflows: Power-aware auto-tuner for density and m; DVFS policies; green scheduling across tiers.
- Assumptions/dependencies: Accurate energy models per level; hardware telemetry; workload stability.
- Sector: Heterogeneous hardware — SmartNIC/DPU/CXL offload
- Application: Offload per-level scanning and distance ops to DPUs or CXL-attached memory for lower tail latency.
- Tools/products/workflows: Kernel-bypass NIC pipelines; in‑storage compute for partition filtering; DPU libraries for ANN primitives.
- Assumptions/dependencies: Mature offload APIs; data movement orchestration; cost-benefit vs SSD-bound baseline.
- Sector: Robotics/Autonomy — Real-time place and experience retrieval
- Application: Bounded-latency similarity search for visual place recognition or experience replay across large maps.
- Tools/products/workflows: On‑vehicle shallow hierarchies; roadside/edge SSD partition stores; m‑parallel partition fetch tuned to RTT.
- Assumptions/dependencies: Edge compute with NVMe; robust synchronization; safety-critical recall validation.
- Sector: Finance — Fraud/risk similarity networks
- Application: Large-scale entity embedding retrieval for KYC, AML, and fraud rings with interpretable, auditable per-level hops.
- Tools/products/workflows: Risk scoring pipelines that log per-level candidate paths; controllable recall dialed to compliance risk.
- Assumptions/dependencies: Strict audit requirements; explainability for ANN paths; careful handling of concept drift.
- Sector: AutoML/AutoIndex — Learned density and hierarchy planners
- Application: ML agents that predict the balanced partition density and m per dataset/workload to maximize QPS under SLOs.
- Tools/products/workflows: Profiling + Bayesian optimization; offline simulators of level-wise costs; closed-loop controllers.
- Assumptions/dependencies: Robust, low-overhead profilers; generalization across domains; safe guardrails for SLO adherence.
- Sector: Cross-modal knowledge bases — Unified multimodal retrieval
- Application: Joint text–image–video–audio embedding retrieval at web scale with shared hierarchical index and modality-aware m.
- Tools/products/workflows: Modality-tagged partitions; adaptive per-level routing; rebalancing for skewed modality mixes.
- Assumptions/dependencies: Strong cross-modal embeddings; mixed-partition fidelity characterization.
- Sector: Policy/standards — Benchmarking and SLO guidance for ANN at scale
- Application: Industry standards for recall/latency/throughput reporting with level-wise metrics and density disclosure.
- Tools/products/workflows: Open benchmarking suites and dashboards; certification criteria for managed vector services.
- Assumptions/dependencies: Community consensus; neutral testbeds; reproducible workloads.
Notes on feasibility across applications:
- Immediate viability comes from SPire’s demonstrated performance on up to 8B vectors across 46 nodes (up to 9.64× throughput gains) with bounded latency, SSD-first design, and stateless compute.
- Long-term items mainly depend on robust incremental maintenance, geo-awareness, hardware offload maturation, and standardized compliance/auditability—areas suggested but not directly solved by the paper’s current implementation.
Glossary
- Accuracy-preserving recursive construction: A bottom-up index-building method that maintains overall search accuracy across levels by recursively constructing and tuning each level. "it introduces an accuracy-preserving recursive construction that builds a multi-level index"
- Approximate Nearest Neighbor Search (ANNS): A search technique that returns near neighbors efficiently rather than exact ones, trading precision for speed. "Approximate Nearest Neighbor Search (ANNS)"
- Balanced partition granularity: A chosen partition size/density that avoids excessive reads (throughput penalties) while still reducing cross-node communication. "SPire identifies a balanced partition granularity that avoids significant throughput penalties."
- Best-first search: A graph traversal strategy that iteratively explores the most promising nodes first to find approximate neighbors. "queries use best-first search to locate top- neighbors approximately."
- B+-tree: A hierarchical data structure used as an analogy for multi-level traversal that explores multiple child partitions per step. "resembles that of a traditional B+-tree"
- Centroid: The representative vector of a partition or cluster used for routing queries at higher index levels. "elect partition centroids"
- Cross-node hops: Network transitions across machines during index traversal that increase latency. "cross-node hops in the proximity graph decrease gradually"
- Curse of dimensionality: The phenomenon where high-dimensional spaces make exact nearest neighbor search computationally expensive. "Due to the curse of dimensionality, exact nearest neighbor search is often expensive"
- Data-dependent network round trips: Latency-incurring network requests whose sequence depends on intermediate search results. "the number of data-dependent network round trips per query is bounded by the number of indexing levels"
- Divide-and-conquer strategy: A design that partitions datasets into manageable shards and uses their centroids to route queries. "This design employs a practical divide-and-conquer strategy"
- End-to-end accuracy: The overall accuracy across all levels of a hierarchical index that must be preserved during construction and search. "preserve the end-to-end accuracy"
- Fidelity loss: The misrepresentation error when a centroid poorly represents vectors in its partition, especially near boundaries. "vector clustering introduces fidelity loss."
- Graph-based indices: Vector search structures that connect nearby vectors in a proximity graph for efficient traversal. "graph-based indices, such as HNSW"
- HNSW: A specific high-accuracy, graph-based ANN index (Hierarchical Navigable Small World). "graph-based indices, such as HNSW"
- Hierarchical index: A multi-level structure where upper levels route queries to relevant lower-level partitions to control latency and scalability. "multi-level hierarchical index"
- Index sharding: Splitting a large index across multiple machines to scale to billions of vectors. "index sharding becomes necessary."
- KD-trees: Tree-based spatial indexes used as a hierarchical partitioning reference for vector data. "tree-based structures like KD-trees"
- Latency–Throughput Trade-off: The fundamental tension where lowering latency (fewer cross-node hops) can hurt throughput (more reads), given an accuracy target. "LatencyâThroughput Trade-off"
- Partition-based hierarchical design: A distributed layout that clusters vectors into partitions and connects their centroids across multiple levels. "partition-based hierarchical design"
- Partition density: A metric quantifying partition granularity, defined as partitions per vector; lower density means coarser partitions. "partition density of one degenerates into a pure proximity-graph index"
- Partition granularity: The size or fineness of partitions that impacts fidelity, reads, and cross-node communication. "partition granularity"
- Proximity graph: A graph that connects nearby vectors (or centroids) to enable ANN traversal. "The root (top) level maintains an in-memory proximity graph"
- Recall@5: An accuracy metric indicating the fraction of true nearest neighbors recovered among the top 5 results. "Recall@5=0.9"
- Remote Procedure Calls (RPCs): Networked calls required for cross-node traversal in a sharded index, contributing to latency. "Remote Procedure Calls (RPCs)"
- Retrieval-augmented generation (RAG): An AI paradigm that augments generative models with retrieved vector-based context. "retrieval-augmented generation (RAG)"
- Sharded dense graph: A highly connected graph split across machines that suffers significant remote communication overhead during traversal. "traversing in a sharded dense graph incurs significant remote communication costs"
- SLOs: Service Level Objectives specifying latency requirements for online vector search. "millisecond-level SLOs"
- Spatial locality: A placement strategy that co-locates nearby centroids to reduce cross-node connections. "using spatial locality to reduce cross-node connections"
- Tail latency (p99 latency): The 99th-percentile latency that reflects worst-case query times in production. "the p99 latency increases by two orders of magnitude"
- Top- neighbors: The K most similar vectors returned by a query according to the index traversal. "top- neighbors"
- Vector clustering: Grouping vectors into partitions (e.g., via k-means) to form higher-level centroids for routing. "vector clustering introduces fidelity loss."
- Vector reads: The I/O and computation required to fetch and evaluate vectors during search. "vector reads (with extra CPU cycles and disk IOs)"
Collections
Sign up for free to add this paper to one or more collections.

