- The paper demonstrates that post-hoc watermarking through LLM rephrasing, particularly using the Gumbel-max method, effectively embeds detectable signals while maintaining high semantic fidelity.
- It reveals a trade-off where larger models yield better text quality but lower watermark strength, whereas smaller models preserve detectability, especially in open-ended texts versus code.
- The study underscores the importance of decoding strategies like beam search and emphasizes challenges in multilingual and low-entropy domains, suggesting directions for future watermarking methods.
Evaluation of Post-Hoc Watermarking with LLM Rephrasing
Introduction
This paper presents an extensive empirical study of post-hoc watermarking through LLM-based paraphrasing, designed to embed detectable statistical signals in existing text data. Unlike generation-time watermarking constrained by API or system integration, the post-hoc paradigm allows flexible paraphrasing of arbitrary text, facilitating applications such as data copyright tracing, traitor-tracing, and membership evaluation in RAG/training corpora. The approach introduces new degrees of freedom in watermark embedding—most notably, adaptable decoding strategies and model selection—fundamentally transforming the fidelity-detectability trade-off.
The authors benchmark a broad suite of watermarking algorithms, paraphrasing models (spanning multiple families and scales), decoding/search strategies, and detection/aggregation procedures. Crucially, they distinguish between open-ended text (Wikipedia, books) and verifiable domains (code), exposing the circumstances under which existing watermarking algorithms succeed or fail and identifying optimal parameter regimes for practical deployment.
Figure 1: Post-hoc text watermarking through watermarked LLM rephrasing, empirically evaluating detection power, semantic fidelity, and the effect of scheme and compute allocation.
Watermarking Methodology
The post-hoc protocol involves chunking the input, rephrasing each chunk with an LLM under watermark-constrained decoding, and aggregating watermark evidence for statistical detection. The watermark is injected by biasing or perturbing token selection pseudorandomly (via a secret key and prior context), employing methods such as Green-Red, Gumbel-max, DiPMark, MorphMark, and SynthID-Text. Notably, the Gumbel-max method outperforms most alternatives in random sampling scenarios, establishing a robust Pareto frontier across text quality and watermark strength.
Detection is achieved through rigorous statistical hypothesis testing, using deduplication and private key search to guarantee correct false positive rates under the null distribution. Compute-enhanced modes—beam search, multi-candidate generation (WaterMax), and entropy-based filtering—allow further navigation of the quality-for-detectability trade-off, which is inaccessible to generation-time-only methods.
Empirical Results
Quality-Detectability Trade-Off
Extensive sweep experiments on LLM paraphrasers (notably Llama-3 and Qwen) demonstrate that under standard nucleus sampling regimes, Gumbel-max watermarking dominates the quality-detectability Pareto frontier on open-ended English prose. Alternative schemes (DiPMark, MorphMark, SynthID) yield strictly inferior frontiers unless search (e.g., beam search with biased scoring) is engaged.
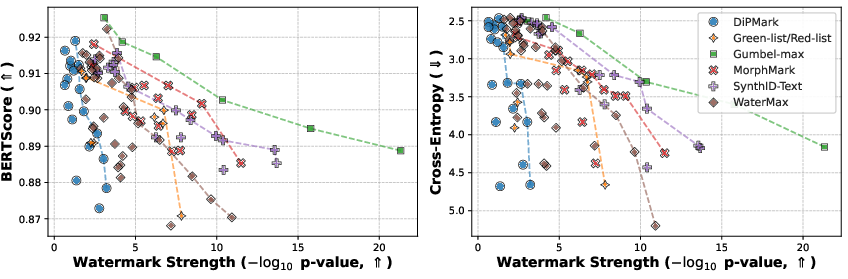
Figure 2: Detection quality trade-off for competing watermarking methods and parameter regimes, highlighting the dominance of Gumbel-max in median-case performance.
Qualitative rephrasing results confirm high semantic fidelity at strong detectability, as evidenced by high SBERT similarity, low perplexity, and extremely low p-values.
Model Family and Scale
Larger LLMs consistently generate semantically faithful paraphrases with lower perplexity. Paradoxically, they are less capable of embedding strong watermarks, since their outputs are less entropic and thus more resistant to substantial perturbation. At higher watermark strengths, only smaller, less capable models maintain detectability, indicating a clear trade-off between semantic accuracy and watermark channel capacity.
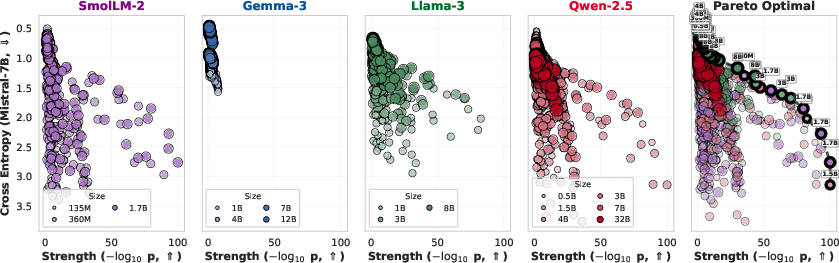
Figure 3: The effect of model family/scale on cross entropy and watermark strength; larger models improve quality but only smaller models reach high detection strength.
Decoding and Compute
Systematic decoding via beam search, especially with scoring biased toward watermarked likelihoods, consistently improves the trade-off over random sampling. WaterMax, which selects from multiple unperturbed candidates, achieves minimal watermarking power—further, it is not suitable for “radioactivity” checks (training/context membership inference), a unique post-hoc detection feature.

Figure 4: Beam search upshifts the Pareto frontier for robust watermarking methods, particularly with biased scoring that maximizes watermark evidence.
Entropy-aware detection brings only modest improvements and is generally not worth the additional complexity, except in marginal cases.
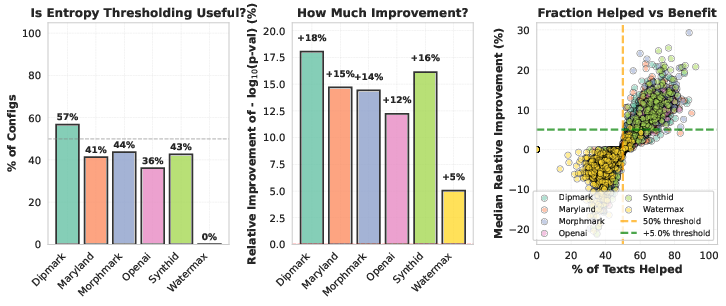
Figure 5: Modest, configuration-dependent benefit of entropy-aware token filtering at detection time; generally less than 20% improvement.
Watermarking in Code
For verifiable domains, especially code, watermarking is substantially constrained by the need to preserve functional correctness. Here, small models outperform larger ones for watermark detectability, but both face a tight utility wall: watermark strength ("detection power") and correctness ("pass@1") are mutually exclusive at high levels. This exposes a fundamental limitation: code is a low-entropy, high-stakes object and only weak watermarking is feasible without excessive degradation.
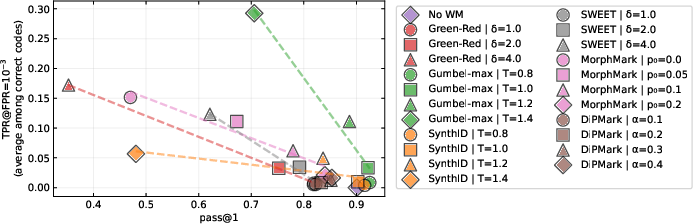
Figure 6: Pass@1 vs TPR at FPR=10−3 for various code watermarking methods; Gumbel-max again leads, but strong watermarking is unattainable for high correctness.
Size ablations demonstrate that, unlike in open-ended text, smaller models offer superior watermarking performance at equivalent generation operating points, but at diminished functional accuracy.
Multilingual Documents and Chunking
Non-English watermarking is possible but comes with a sharper degradation in semantic similarity to attain comparable detection strength. This reflects typical LLM training biases and highlights the need for language-specific adaptations. For long documents, context-aware chunked paraphrasing strictly improves semantic consistency and watermark detection.
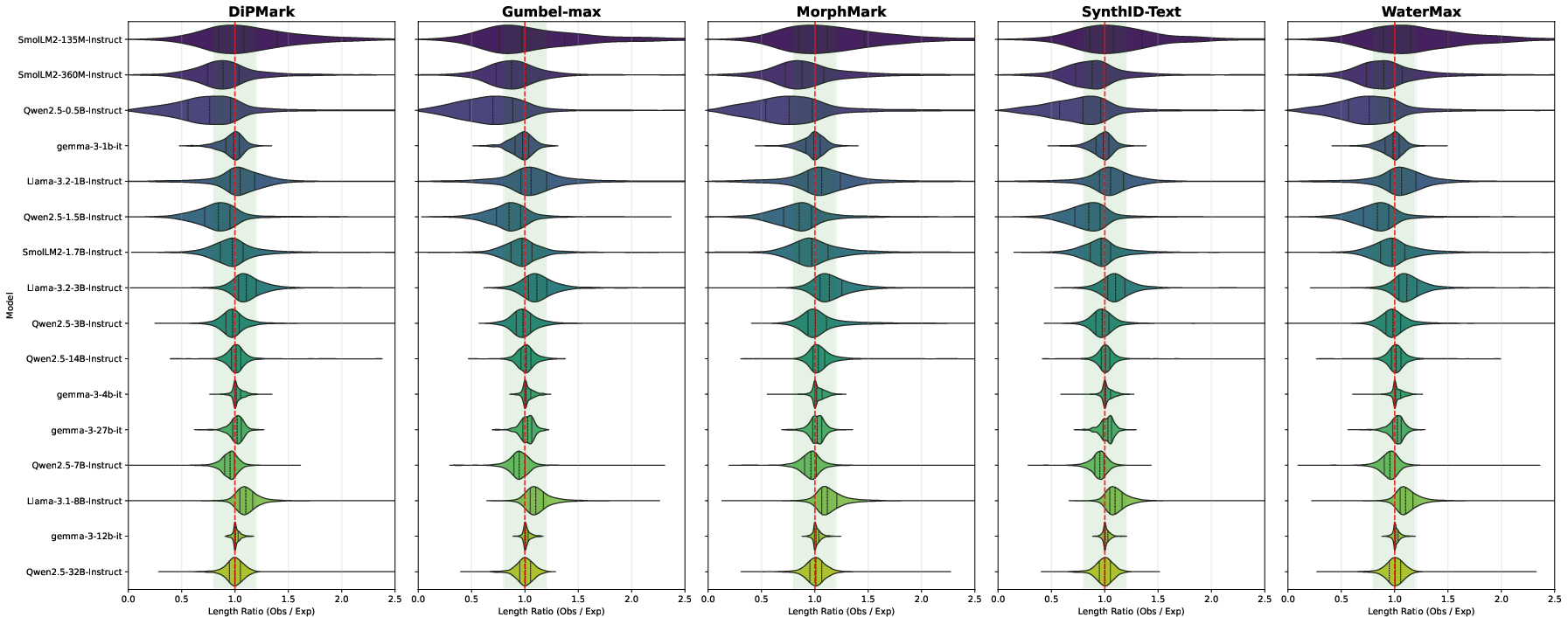
Figure 7: Distribution of the output-to-input length ratio across models and watermarking schemes; output stability is determined primarily by base model capacity.
Implications and Future Directions
The thorough empirical evidence delineates the zones of feasibility for post-hoc watermarking. Practically, post-hoc LLM watermarking is a viable, low-effort tool for copyright management, contamination tracing, and downstream membership inference in open-ended text. The need to balance rephrasing model capacity and watermark injection strength is paramount: "larger-is-better" does not hold when watermark detectability is the objective.
The critique of WaterMax clarifies that not all watermarking algorithms are suitable for robust post-hoc provenance tasks, especially those requiring "radioactivity" and adversarial settings. Furthermore, automated semantic-quality proxies are insufficient, especially in multilingual and highly-structured domains, motivating the inclusion of execution-validated correctness assessments (e.g., code) in future work.
The findings suggest two priority directions:
- Development of watermarking schemes adapted to low-entropy, verifiable domains (e.g., code) where current methods hit capacity-functionality walls.
- Advancement of cross-lingual watermark injection and detection mechanisms, potentially with adaptive LLM architectures or code-switching approaches.
Conclusion
This study establishes the empirical limits and design principles of post-hoc watermarking via LLM rephrasing. Robust watermarking is attainable in natural text through judicious selection of model scale, watermarking method (favoring Gumbel-max or beam-enhanced schemes), and compute allocation. In contrast, code and low-entropy domains remain major open challenges due to innate correctness constraints. The results provide strong guidance for practical watermarking deployments and catalyze research into next-generation post-hoc methods optimized for both traceability and utility.