- The paper presents GenEval 2 to address benchmark drift in text-to-image evaluation by introducing the Soft-TIFA metric for improved human alignment.
- It details an expanded benchmark with 800 templated prompts varying in compositional atomicity to enable granular and skill-targeted diagnosis.
- Empirical results reveal high atom-level correctness but low prompt-level accuracy, underscoring challenges in complex compositional reasoning.
GenEval 2: A Robust Response to Benchmark Drift in Text-to-Image Evaluation
Motivation and Problem Analysis
Existing benchmarks for text-to-image (T2I) models, particularly @@@@6@@@@, have facilitated rapid technical advances across the field. However, as contemporary T2I models surpass prior capabilities and leverage diverse data distributions, the utility and validity of static benchmarks have sharply declined. The authors diagnose a substantial benchmark drift: GenEval, which originally relied on a COCO-trained object detector and CLIP, is increasingly misaligned with human evaluation due to the disjoint output distributions of modern synthetic and multimodal models (Figure 1).
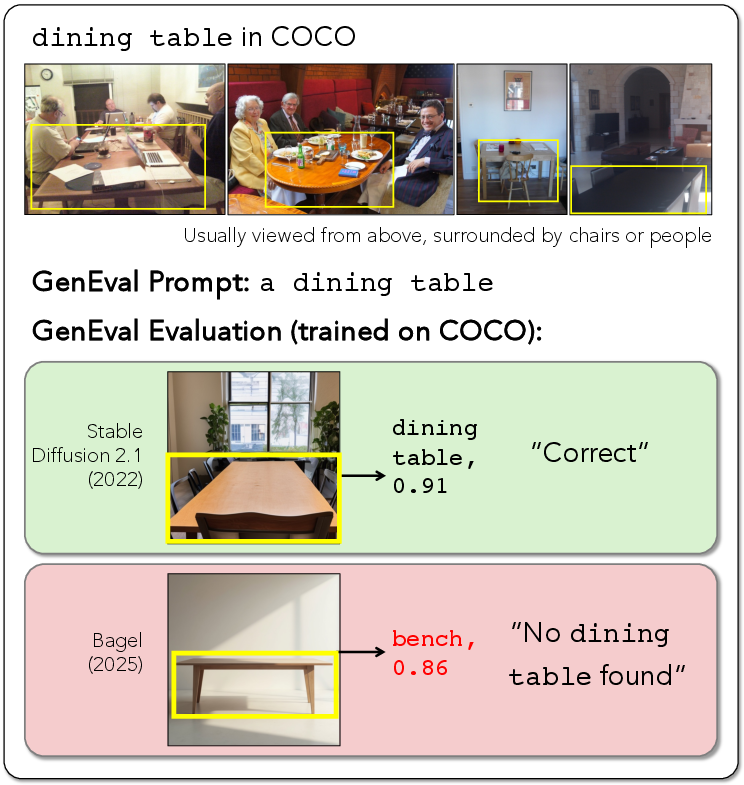
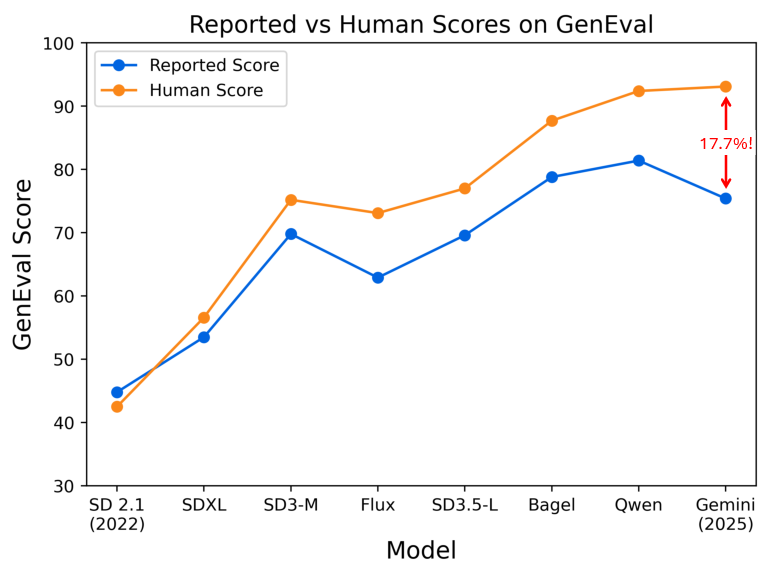
Figure 1: GenEval’s reliance on CLIP and COCO-based detector; as T2I models drift, the metric’s human alignment decreases and saturates at high human scores, concealing meaningful gains.
A large-scale annotation effort covering 8 key T2I models—spanning three years of development and state-of-the-art architectures—demonstrates absolute errors in model ranking as high as 17.7% compared to human judgment. The GenEval benchmark is shown to be saturated: Gemini 2.5 Flash Image achieves a 96.7% human score, and several recent models cluster near ceiling, undermining the benchmark’s differential power.
GenEval 2 Benchmark: Design and Composition
GenEval 2 directly addresses the documented deficiencies by expanding coverage, increasing compositional complexity, and enabling skill-targeted diagnosis. The benchmark consists of 800 templated prompts, systematically varying in atomicity (number of compositional “atoms”: objects, attributes, relations), object classes, attributions, and counting. Compared to GenEval—which covers basic color and position relations for COCO objects—GenEval 2 introduces:
- 40 objects (20 COCO, 20 external, split animate/inanimate)
- 18 attributes (colors, materials, patterns)
- 9 relations (including 3D prepositions, transitive verbs like “chasing”)
- 6 counts (ranging from 2 to 7)
- Prompt atomicity systematically varied from 3 to 10
All prompts are generated via templates, supporting atomic-level annotation and deterministic coverage, and are extendable via rewriting (using, e.g., GPT-4o-based expansion) to reflect typical usage in frontier T2I pipelines. Sample prompts and detailed annotation examples are showcased in Figure 2.

Figure 2: GenEval 2 prompt and annotation example: every atom (object, relation, attribute) is isolated for granular analysis; prompt-level correctness requires all atoms to be correctly generated.
Through a human annotation campaign (23,000+ discrete judgments), GenEval 2 quantifies both atom-level and prompt-level accuracy. Frontier models achieve up to 85.3% atom-level correctness but only 35.8% prompt-level accuracy—clarifying that high performance on simple prompts masks significant deficits on compositions requiring joint reasoning or fine-grained control.
Empirical Findings: Skill and Complexity Analyses
GenEval 2 exposes sharp performance gradients across different T2I competencies. Figure 3 visualizes average human scores on state-of-the-art models, decomposed by skill.
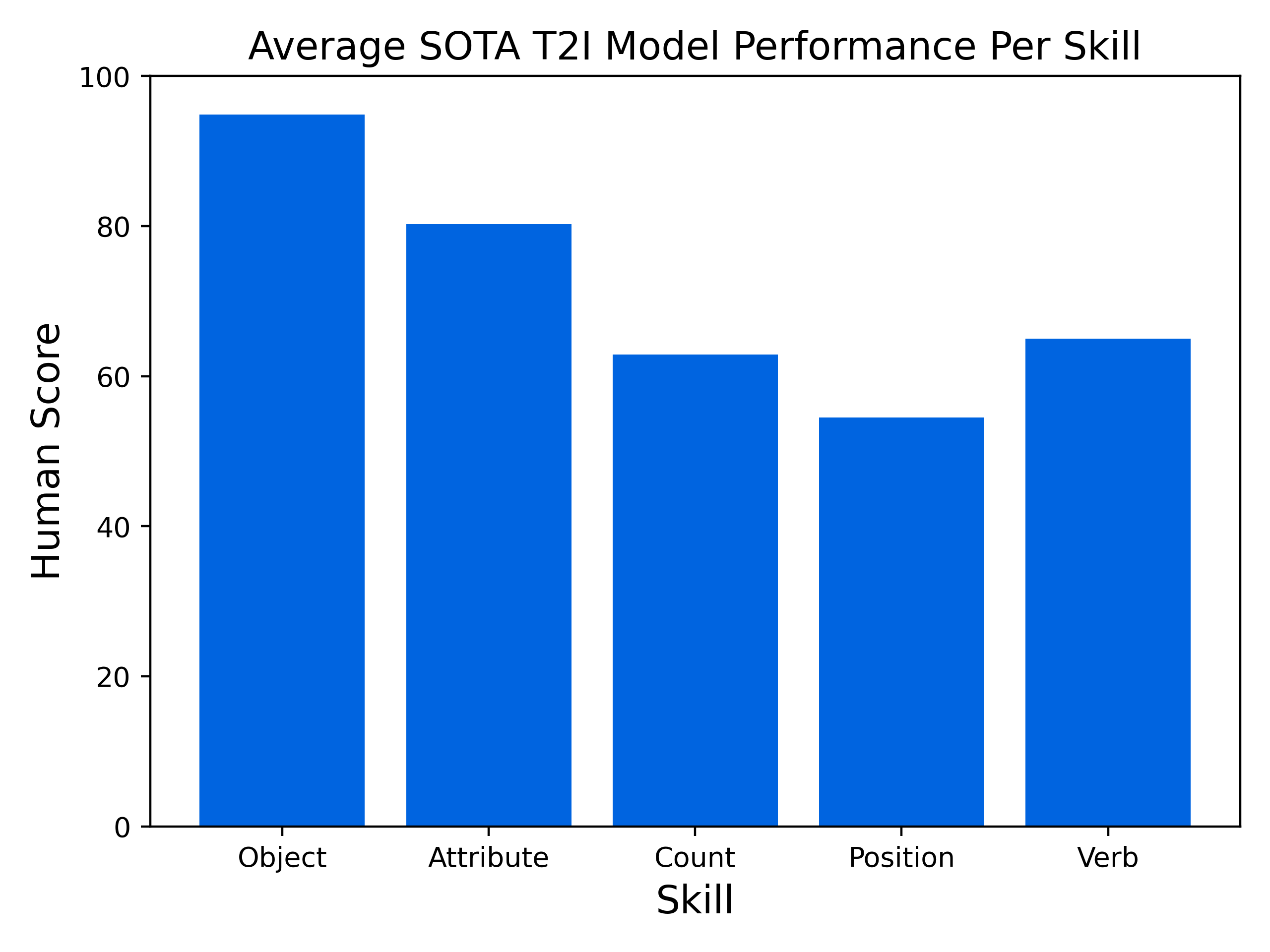
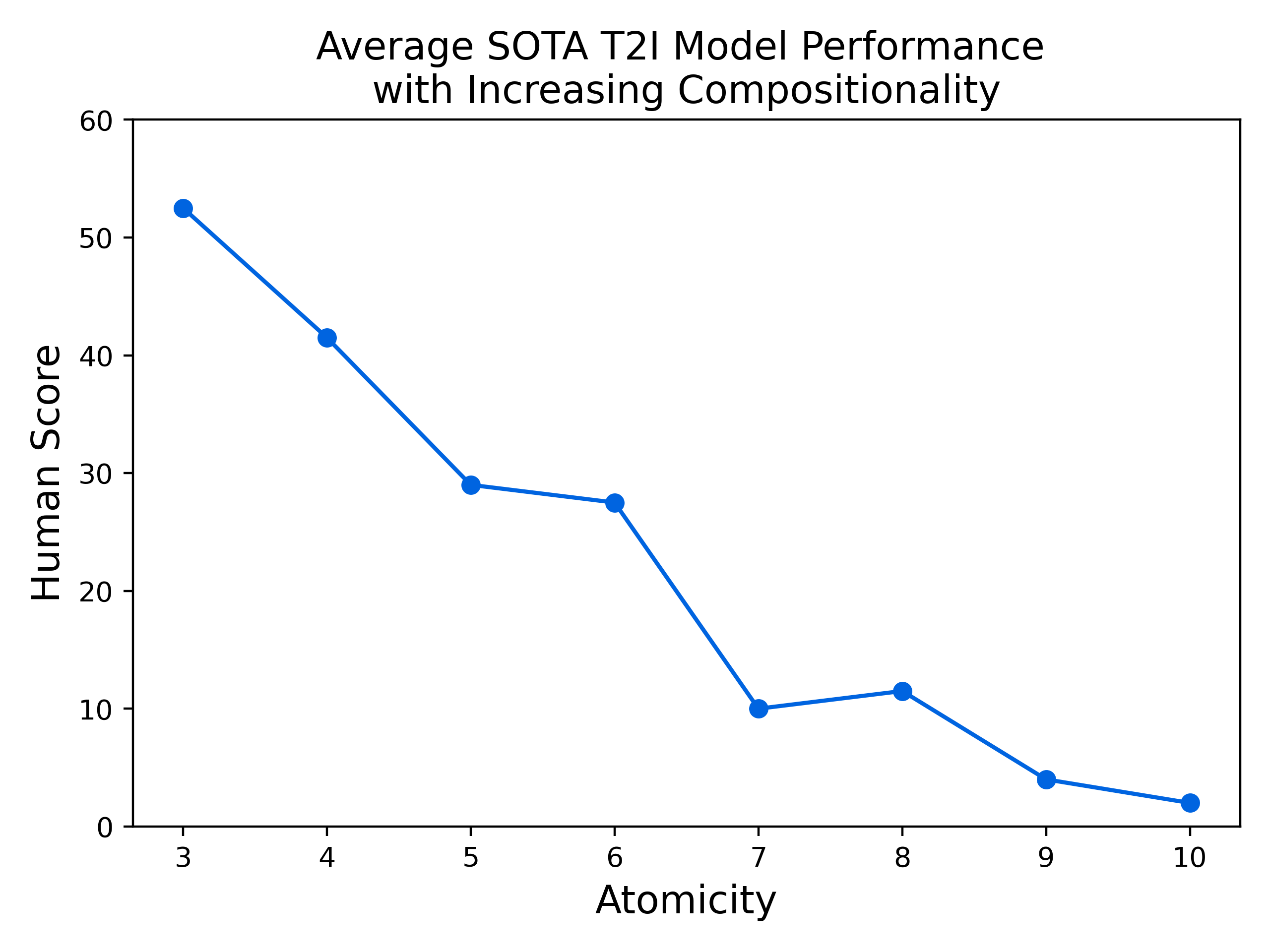
Figure 3: State-of-the-art models perform strongly on object and basic attribute recognition, but degrade substantially on count, spatial, and transitive verb relations.
Spatial relations, counting, and relational verbs remain unsolved challenges—even the best models fail to generalize robustly beyond object-level primitives. Complementary analysis (Figure 4) performed with atom means (AM) confirms this pattern.
Model performance degrades precipitously with prompt compositionality; at higher atomicity levels, prompt-level accuracy approaches zero, highlighting that existing architectures do not scale well with compounded conditions.
The Soft-TIFA Evaluation Metric
Recognizing that evaluation methods themselves are subject to drift when underlying distribution shifts, the authors introduce Soft-TIFA, a compositional, VQA-based evaluation framework. Unlike previous approaches that relied solely on a coarse VQA model for the whole prompt, Soft-TIFA decomposes each prompt into per-atom questions (using deterministic templates) and computes atom-level soft probabilities through a VQA model (Qwen3-VL-8B), aggregating them via arithmetic or geometric mean for atom-level and prompt-level assessment, respectively.
This approach retains several key properties:
- Full compositional coverage: No atoms are omitted, in contrast to previous LLM-generated question paradigms.
- Soft scoring: Reflects model uncertainty and avoids thresholding artifacts.
- Robustness to distribution shift: Breaking prompts into primitives reduces the susceptibility to drift when model distributions evolve.
Empirically, Soft-TIFA’s prompt-level geometric mean (GM) alignment with human annotation achieves an AUROC of 94.5%, outperforming VQAScore (92.4%) and TIFA (91.6%), and even surpasses GPT-4o-based VQAScore (91.2%) (Figure 5). This elevated alignment remains consistent across new VQA models, and is less sensitive to model release drift than monolithic approaches.
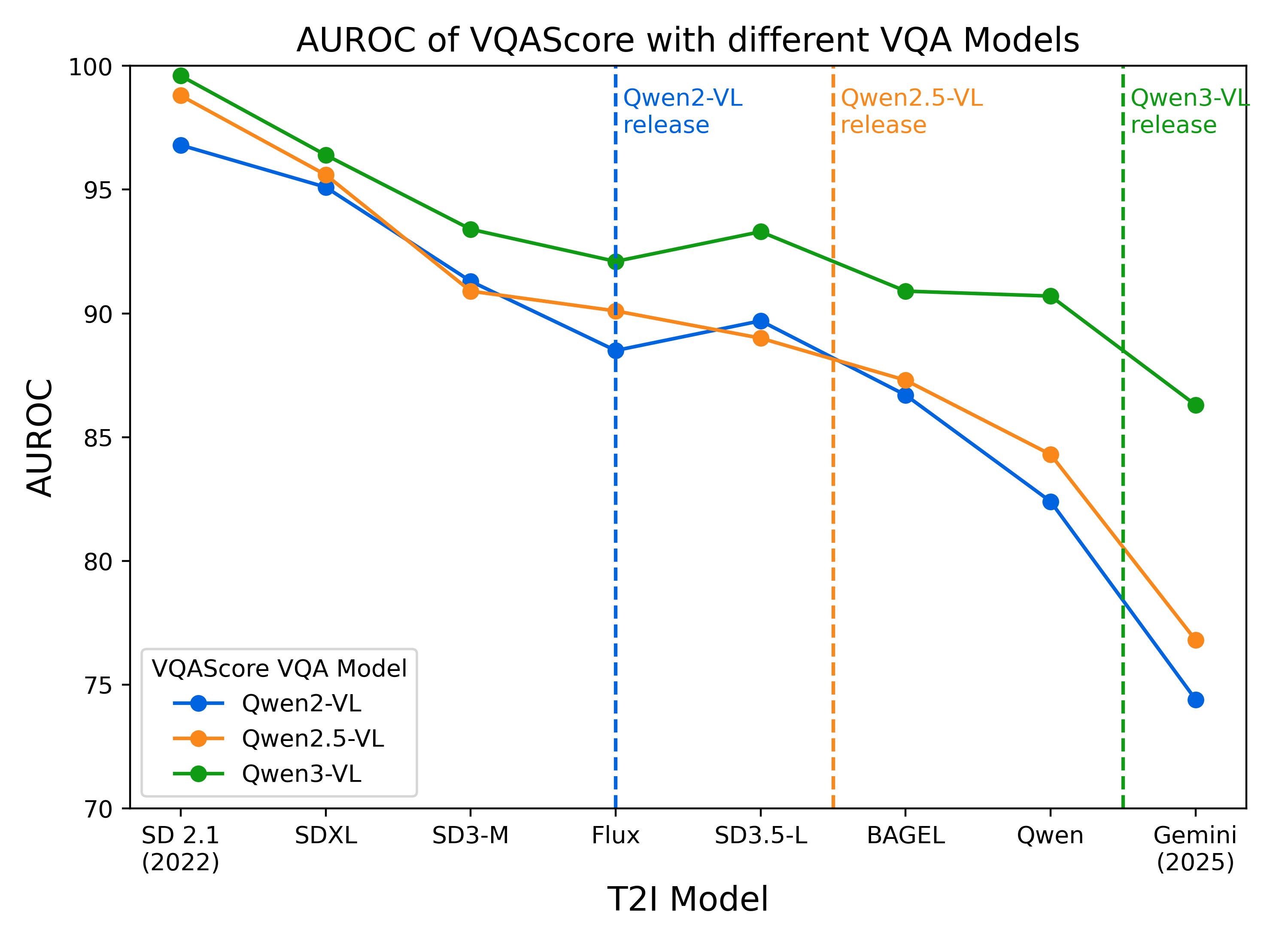
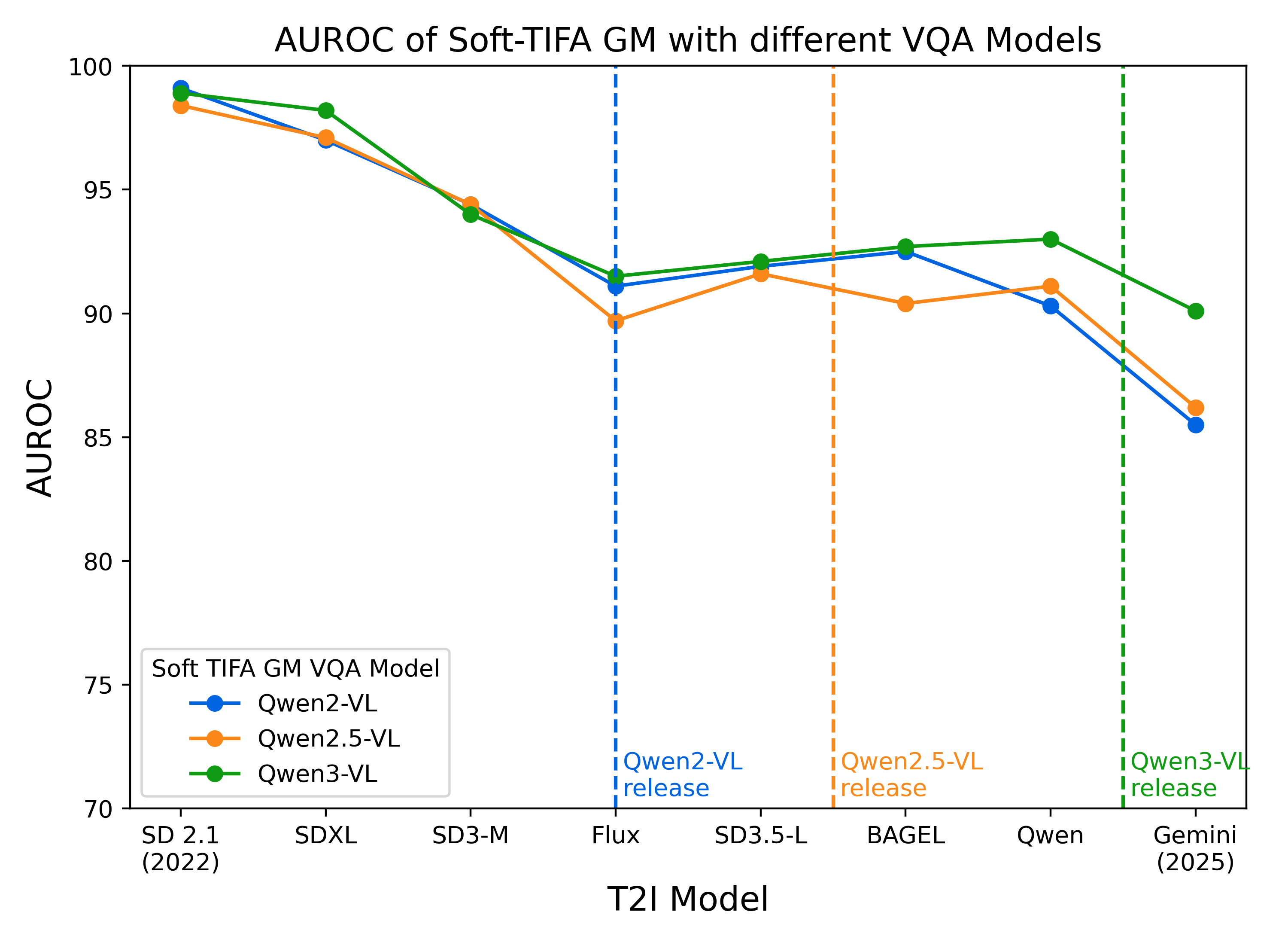
Figure 5: Human alignment (AUROC) of VQAScore and GM under varying VQA models: GM consistently outperforms VQAScore and remains robust as T2I outputs evolve.
Benchmark Drift: Theoretical and Practical Implications
This work rigorously demonstrates that benchmark drift is not artifact-specific but structural: as T2I models become more capable (including generation of out-of-domain or highly synthetic compositions), static evaluation pipelines fail both in ranking and absolute quantification due to poor coverage and model-induced distribution shift. Figure 6 illustrates a typical failure: a detector, having never seen certain objects in unorthodox contexts, mislabels a correctly generated entity.
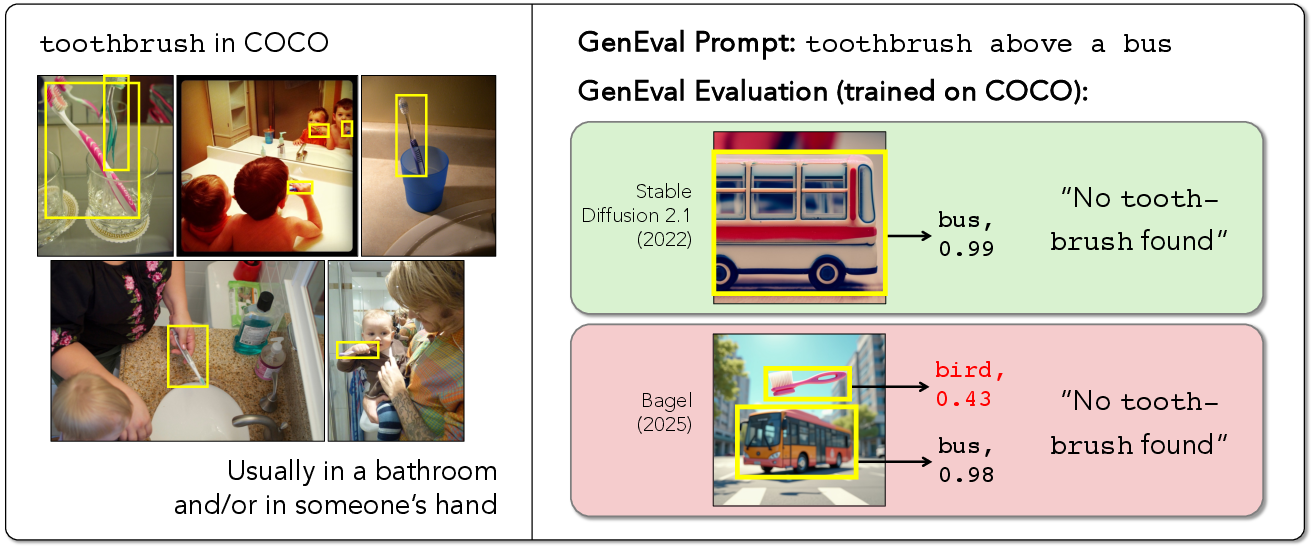
Figure 6: Failure case where COCO-trained detector mislabels a toothbrush as a bird due to context mismatches, leading to spurious metric outcomes in GenEval.
The GenEval 2 pipeline and Soft-TIFA metric deliver a more adequate response, but the authors urge the community that continuous benchmarking and metric updating are essential. Reliance on closed-source APIs (such as GPT-4o) exacerbates reproducibility issues given potential deprecation or undisclosed changes, reinforcing the recommendation to leverage high-performing, open-source VLMs for sustained, transparent evaluation.
Conclusion
GenEval 2 provides a challenging, fine-grained, and compositional benchmark for systematically auditing text-to-image model progress, exposing meaningful limitations in state-of-the-art architectures undetectable by prior generations of evaluation. The Soft-TIFA metric sets a new standard for robustness and human alignment in T2I evaluation, mitigating (though not eliminating) the impact of continual benchmark drift. Theoretical and practical progress in T2I now requires routine auditing and adaptation of benchmarks and metrics, aligned with the evolution of T2I model capabilities.
References
All findings, benchmark descriptions, and empirical results are drawn from "GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation" (2512.16853).

