- The paper presents a novel transformer-based diffusion model that integrates semantic text, initial pose, and goal cues to synthesize full-body, gaze-primed reach motions.
- The model, validated on over 23,000 curated sequences from multiple egocentric datasets, outperforms baseline methods in Prime and Reach Success metrics.
- Implications include advancements in embodied AI and robotics, though the approach currently limits motion synthesis to body and wrist coordination.
Synthesising Gaze-Primed Body Motion for Object Reach: A Formal Summary
Introduction
This work introduces a novel paradigm for human motion generation, focusing on the synthesis of full-body behavior exhibiting the anticipatory, gaze-primed reach and manipulation of objects as observed in naturalistic daily activities. While prior motion generation systems have successfully enabled text- and location-conditioned body motion synthesis, they typically lack accurate modeling of preparatory visuomotor behaviors such as gaze priming—where attention is shifted toward the target location/object prior to reach initiation. The authors assemble a large corpus of such sequences (over 23,000) from five public egocentric datasets, curate labeled prime-and-reach (P) instances, and design a conditional, text-guided diffusion model that generates realistic priming and reaching motion when conditioned on goal pose or target object.
Curating Gaze-Primed Motion Sequences
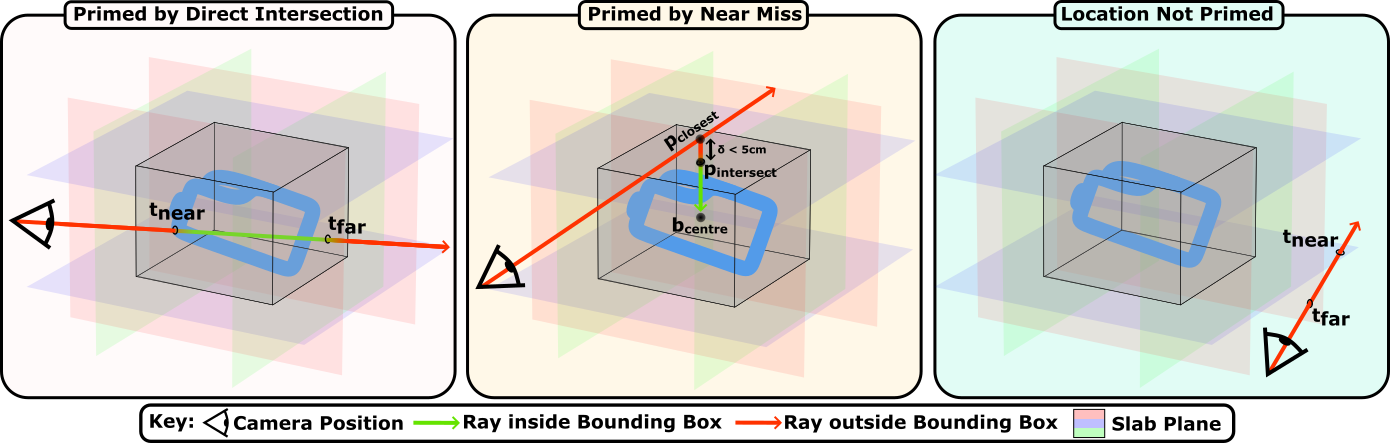
Human activities inherently involve anticipatory coordination. To enable learning of P\ motion, the authors devise a rigorous curation protocol which extracts instances where subject gaze precedes an object pickup or put-down by projecting tracked gaze rays into a reconstructed 3D scene and annotating timestamps where gaze intersected the target (utilizing the slab test method). Each motion fragment begins up to 2 seconds before priming and terminates after object interaction. The curated collection comprises 18,134 instances from HD-EPIC, supplemented by sequences from MoGaze, HOT3D, ADT, and GIMO, all aligned to standard joint representations.
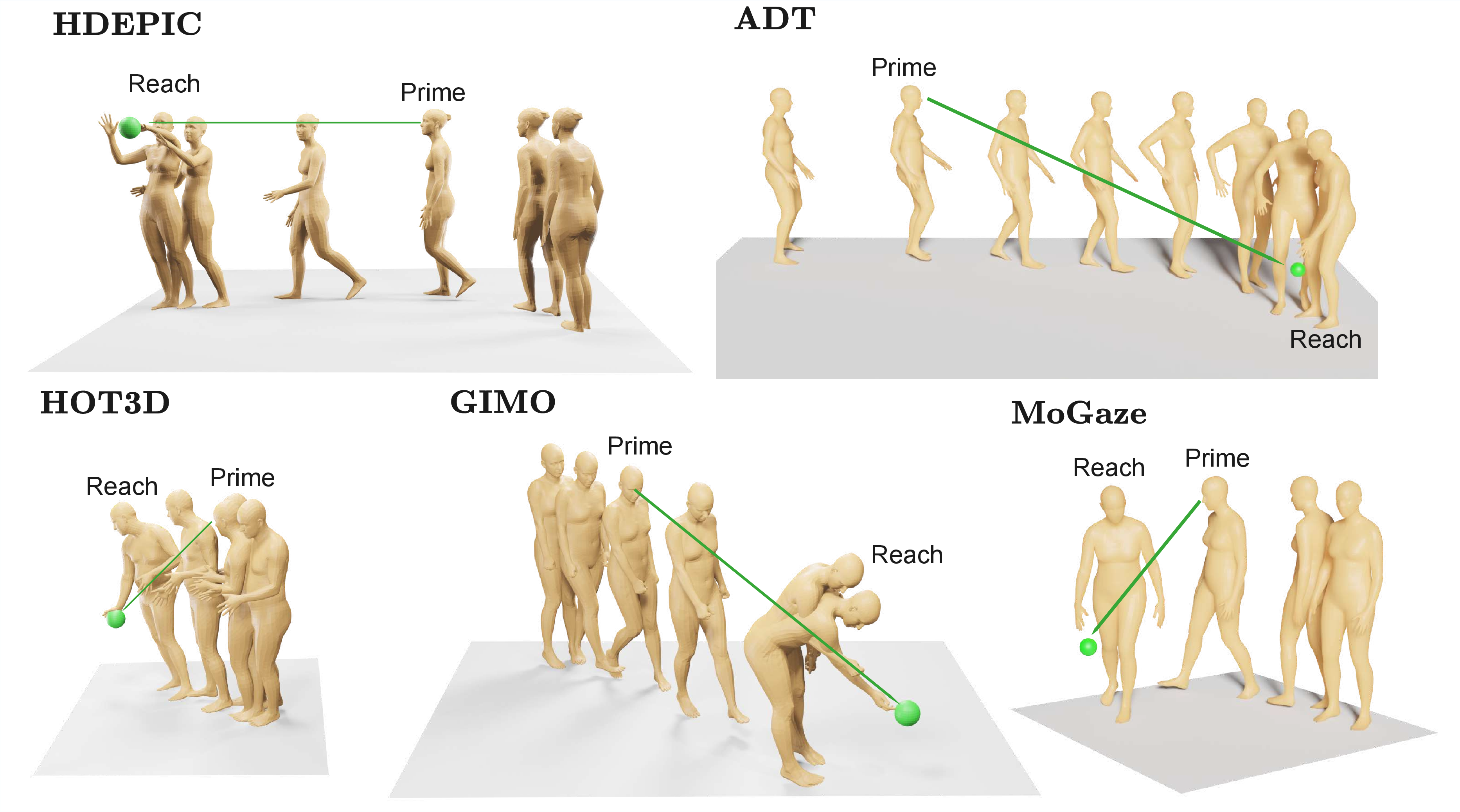
Figure 1: Examples of curated P\ motion sequences from five different datasets.
Central to the approach is a transformer-based diffusion model which synthesizes body motion by incremental denoising from initial noise, guided via the concatenation of three principal conditioning signals: (1) semantic text prompt, (2) initial body pose and velocity, and (3) either the target goal pose or target object location. The conditioning vector modulates each transformer decoder layer via cross-attention mechanisms, yielding an N-length motion trajectory.
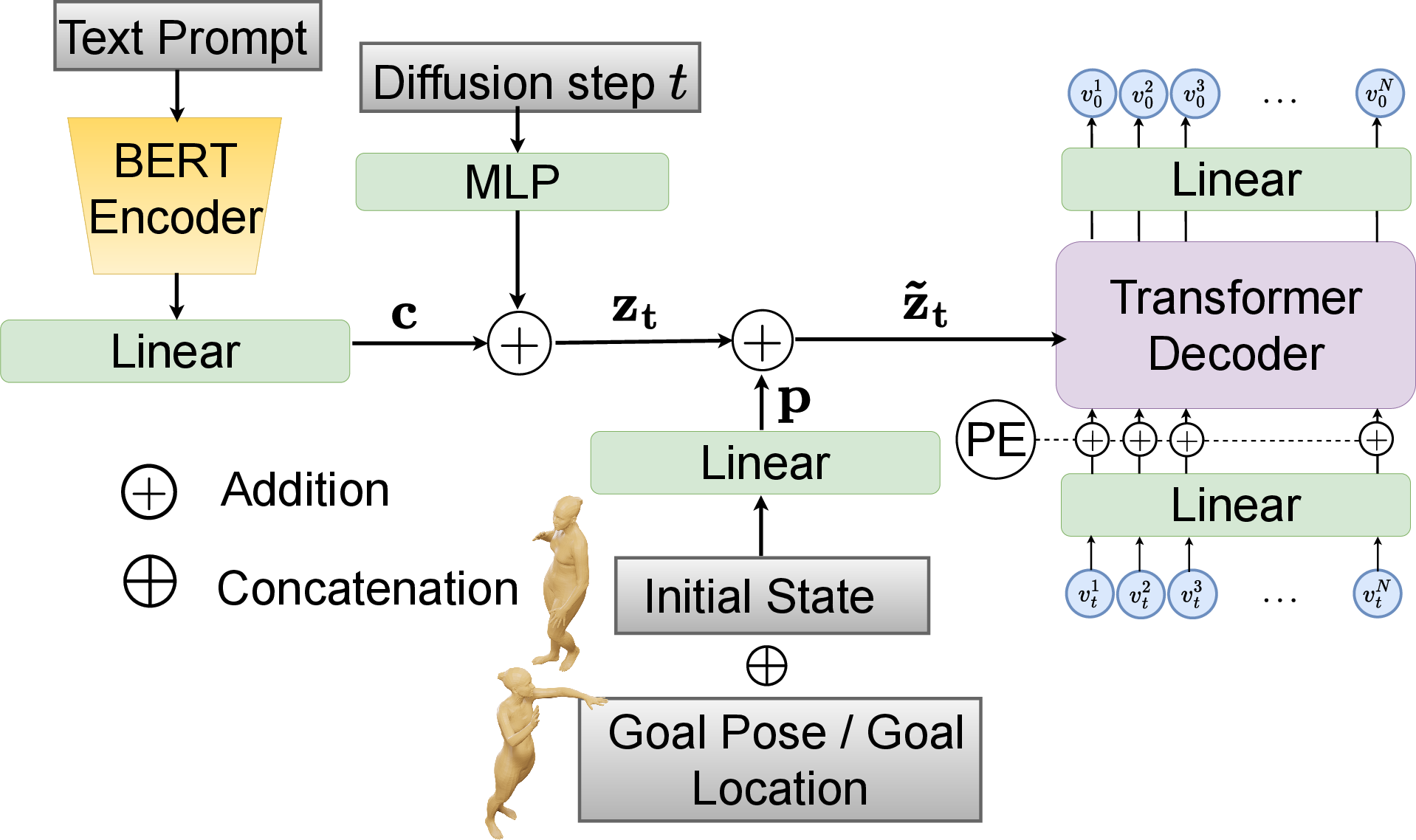
Figure 2: P\ motion diffusion model for goal-conditioned motion generation: concatenated initial state, goal, and text condition injected into decoder layers over multiple diffusion steps.
Pre-training is conducted on Nymeria—an extensive collection of egocentric, everyday activities—imparting the model with rich motor priors. Fine-tuning adapts the learned weights to each curated dataset, enabling the model to synthesize motion sequences with appropriately timed gaze priming and natural reach trajectory.
Evaluation Protocols and Baselines
Six metrics assess the generated trajectories: Prime Success (temporal angular congruence between predicted head orientation and ground-truth gaze at the annotated priming time), Reach Success (target proximity achieved by wrist), Location Error (pelvis-to-target displacement), Goal MPJPE (pose error at sequence end), mean MPJPE (averaged throughout sequence), and Foot Skating (sliding artifacts).
Baseline comparisons include:
- Static average pose;
- MDM (HumanML3D and Nymeria checkpoints, with and without fine-tuning);
- GMD (goal pose-conditioned motion diffusion);
- WANDR (location-conditioned autoregressive framewise synthesis).
Quantitative Results
The proposed P\ model achieves substantial improvements over baselines, especially in Prime Success and Reach Success:
- On HD-EPIC, goal-pose conditioning yields 66.3% Prime Success and 91.2% Reach Success; on object-location conditioning, 59.1% Prime Success and 89.5% Reach Success.
- On MoGaze, scores reach 35.3% Prime Success and 82.9% Reach Success (goal pose), and 48.5%/92.8% (object location).
- On HOT3D, Prime Success surpasses 75% and Reach Success 90%.
- Baseline methods lag: text-only MDM achieves ~5% Prime/1% Reach Success on HD-EPIC.
Notably, the model demonstrates a marked boost in priming ability—up to 18x over prior approaches—when leveraging goal pose as condition, and up to 5x when using only object location. Ablation studies reveal that inclusion of both initial pose and velocity is essential to accurately reproduce natural priming behavior.
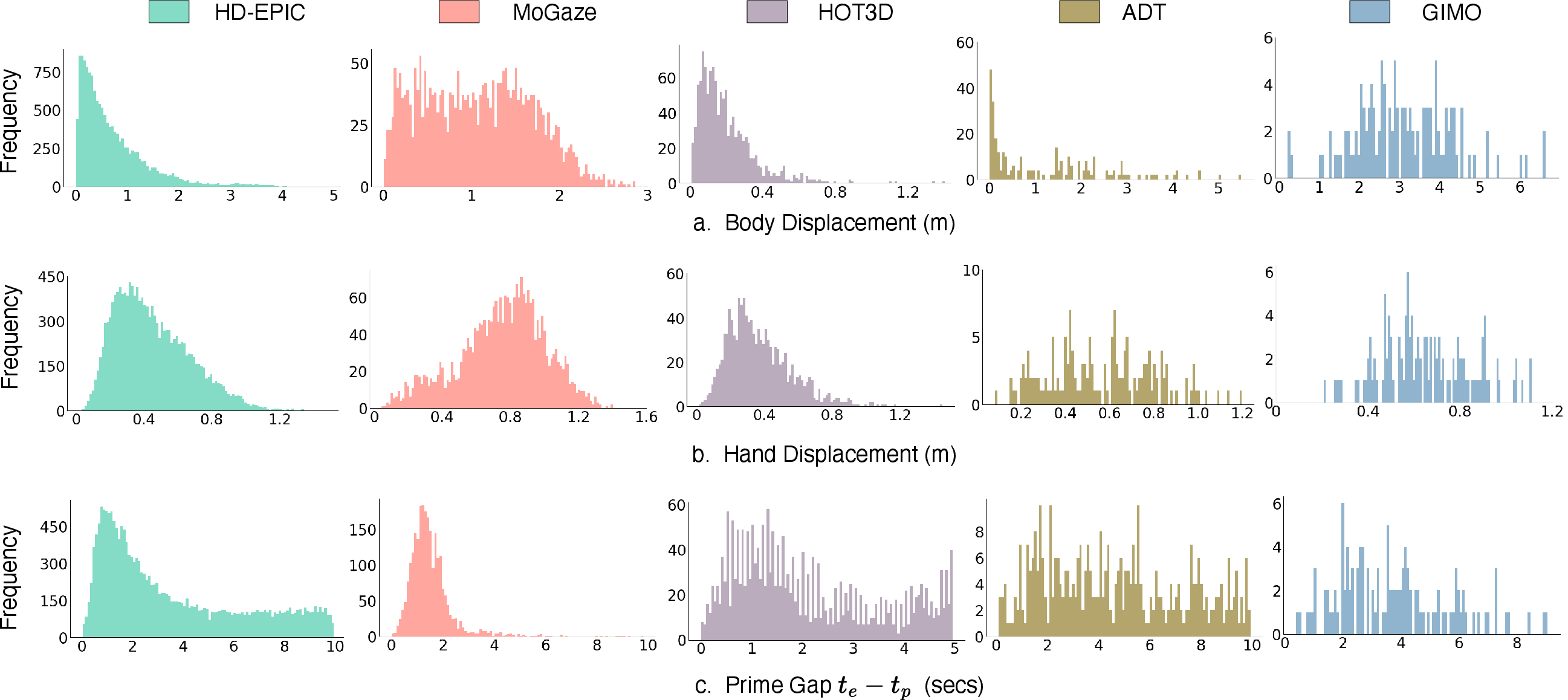
Figure 3: Histograms of body movement, hand movement, and prime gap in curated P\ sequences.
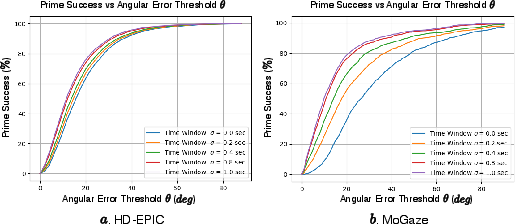
Figure 4: Varying time window σ and angular error threshold θ for Prime Success calculation on HD-EPIC and MoGaze.
Qualitative Analysis
Visualizations confirm that the P\ model produces natural full-body trajectories wherein gaze priming precedes object reach, matching timing and pose of real human performance. Conditioning on object location alone generates plausible reach trajectories but may introduce target-relative pose variations at sequence end. The model generalizes across diverse environments, handling varied spatial relations and pose configurations.

Figure 5: Qualitative results: ground truth, goal-pose conditioned, and object-location conditioned motion for initial, prime, and reach timesteps.
Technical Contributions and Limitations
Practical and Theoretical Implications
The presented pipeline enables realistic simulation of human preparatory behavior, with immediate applications in embodied AI, digital humans, and robotics (e.g., anticipatory reach planning for manipulation). The structured approach for modeling gaze-driven anticipation supports future research into hierarchical motor planning and joint attention in interaction contexts. Dataset curation and metric design set new technical standards for evaluating anticipation and goal-directed reach coordination.
Conclusion
The Prime and Reach framework offers an authoritative methodology and benchmark for synthesizing gaze-primed object-oriented motion, significantly improving prime and reach fidelity relative to prior art. The methodological advances in conditioning strategies and quantitative evaluation catalyze future exploration in multi-modal embodied AI, with extensions to fine-grained motor control, social interaction, and adaptive robotics.