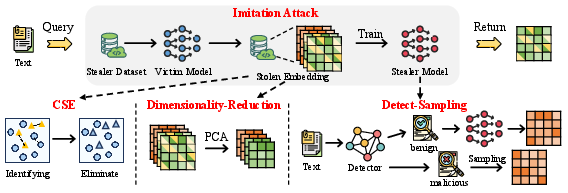
- The paper introduces SemMark, a semantic-aware watermarking scheme leveraging adaptive, region-specific injection using LSH and LOF for robust EaaS copyright protection.
- It maintains high task accuracy (approximately 93–95%) and embedding similarity (over 94%), ensuring minimal perturbation to downstream applications.
- The adaptive weighting and neural mapping techniques enable stealth and resilience against extraction and imitation attacks while keeping computational overhead low.
Adaptive Semantic-aware Watermarking for Embedding-as-a-Service Copyright Protection
Motivation and Background
Embedding-as-a-Service (EaaS) exposes text embeddings from proprietary LLMs via APIs, powering a range of NLP applications. However, EaaS is demonstrably susceptible to model extraction and imitation attacks, which allow adversaries to cheaply duplicate the service and infringe intellectual property. Existing watermarking defenses primarily fall into trigger-based and linear transformation-based methods; both inject signals largely disconnected from embedding semantics, sacrificing diversity, stealth, and sometimes utility. In "From Essence to Defense: Adaptive Semantic-aware Watermarking for Embedding-as-a-Service Copyright Protection" (2512.16439), a new semantic-based watermarking paradigm, SemMark, is introduced to address these limitations using adaptive, region-specific watermark injection.
Semantic-aware Watermarking Paradigm
The core advance of SemMark is the direct exploitation of semantic structure in embedding spaces using locality-sensitive hashing (LSH) to partition the semantic manifold. Watermark signals are generated dynamically by a neural mapping model conditioned on the embedding itself, and injected into selected semantic regions with adaptive weights computed using local outlier factor (LOF) density estimation. This design achieves region-specific watermarking, aligning injected signals with local semantic distributions and thereby maximizing stealthiness and diversity while minimizing perturbation.
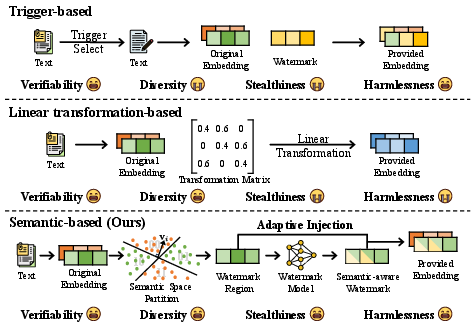
Figure 1: Comparison of the SemMark semantic-based watermark paradigm with trigger-based and linear transformation-based approaches, highlighting integration with semantic regions versus global or trigger-based watermarking.
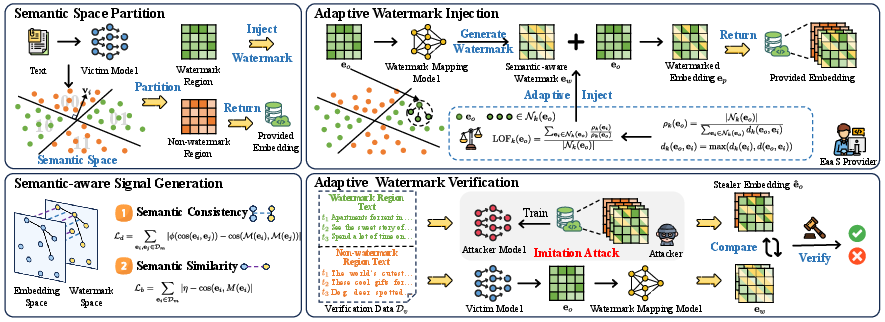
Figure 2: SemMark watermarking framework, showing region-based signal injection and adaptive weighting, with clear distinction of watermark and non-watermark regions.
Technical Architecture
Semantic Region Partitioning
Embeddings are reduced via PCA to mitigate the curse of dimensionality and then partitioned using cosine-preserving LSH. Each region in the space corresponds to a discrete hash bucket in {0,1}c, where c is the number of hyperplanes. Watermark regions are randomly sampled for injection, with proportion α controlling coverage.
Watermark Signal Generation
A residual feed-forward neural mapping M transforms the original embedding eo into a semantic-conditioned watermark ew. Two losses enforce:
- Semantic Consistency: Similar embeddings yield highly correlated watermarks, ensuring region robustness.
- Semantic Similarity: Watermarks remain close (controlled cosine similarity η) to their source embedding, preserving downstream utility.
Adaptive Weighting
Instead of fixed strength, weights uo for watermark injection are adaptively assigned based on local density: outlier embeddings (low local density by LOF) receive higher watermark strength, maximizing both stealth and negligible global distortion.
Watermark Verification
Verification compares standard texts (not crafted triggers) from both watermark and non-watermark regions using cosine similarity and L2 metrics between suspicious model outputs and mapped watermarks. KS-tests provide statistical evidence for distinguishing watermarked models.
Robustness and Attack Analysis
The authors introduce two new adversarial scenarios:
Empirical Evaluation
SemMark is evaluated against baseline methods (EmbMarker, WARDEN, EspeW, WET) under diverse attack scenarios across SST2, MIND, AGNews, and Enron Spam datasets. It consistently achieves:
- Task Accuracy: Watermarked embeddings retain nearly original classification accuracy, confirming utility preservation (∼93–95% across datasets).
- Similarity: Cosine similarity with original embedding remains high (>94%), outperforming linear transformation-based watermarks by wide margins.
- Watermark Verifiability and Stealth: KS-test p-values are <10−10 in region-based detection. SemMark is resilient to CSE, Detect-Sampling, and Dim attacks, where all baselines show degraded or undetectable signals in at least one scenario.
The effect of critical hyperparameters (α, δ, c) is systematically analyzed.
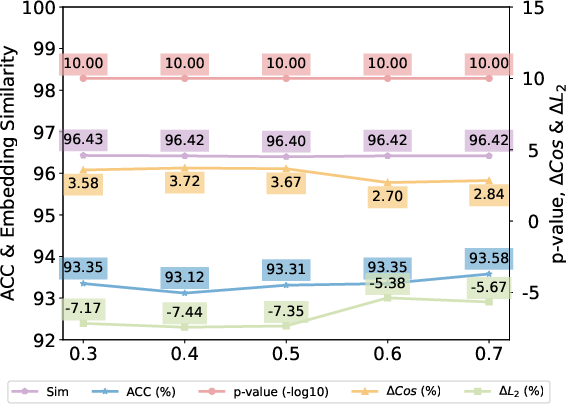
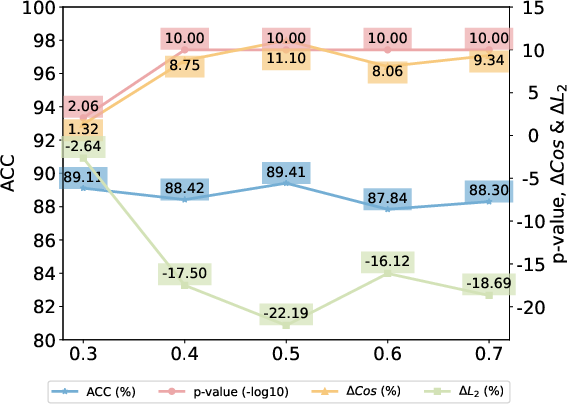
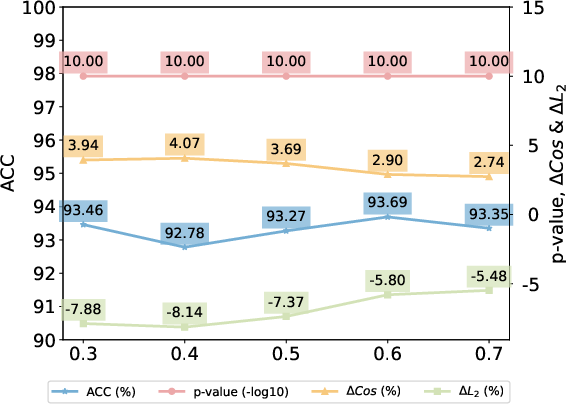
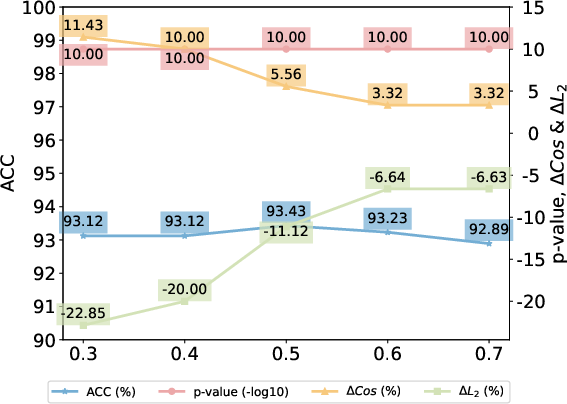
Figure 4: Effects of watermark proportion α on SST2 task, similarity, and detection performance, showing minimal utility loss and strong verifiability in all regimes.
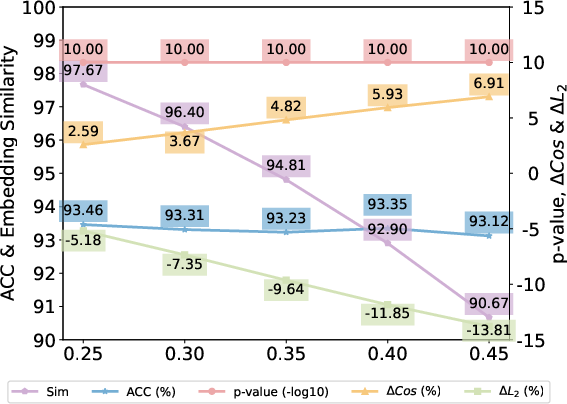
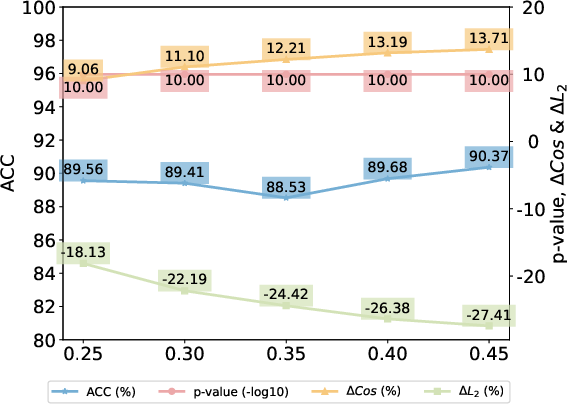
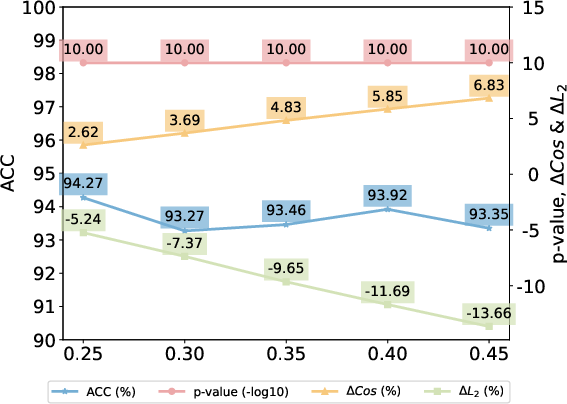
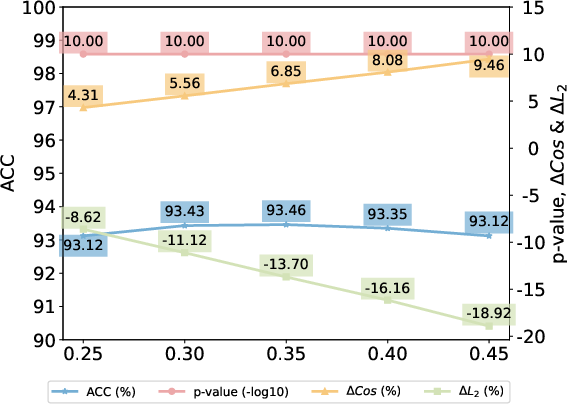
Figure 5: Effects of watermark strength δ on several metrics, revealing a monotonic improvement in verification metrics with tolerable impact on similarity due to adaptive weighting.
Further, SemMark’s mapping ensures verifiability even under strong adversarial conditions, and the adaptive weighting mechanism meaningfully improves the closeness between watermarked and original embeddings across all benchmarks.
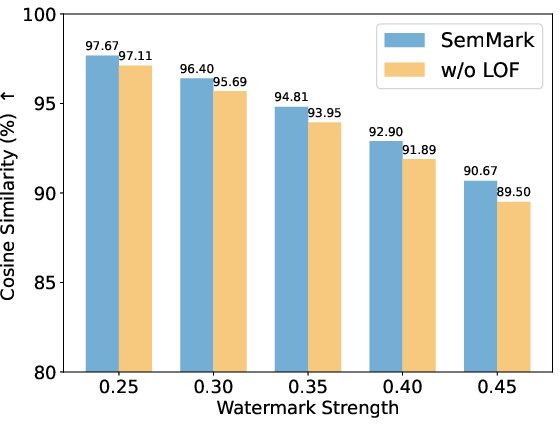
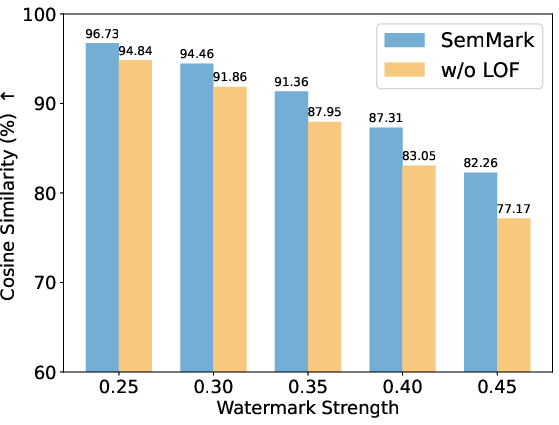
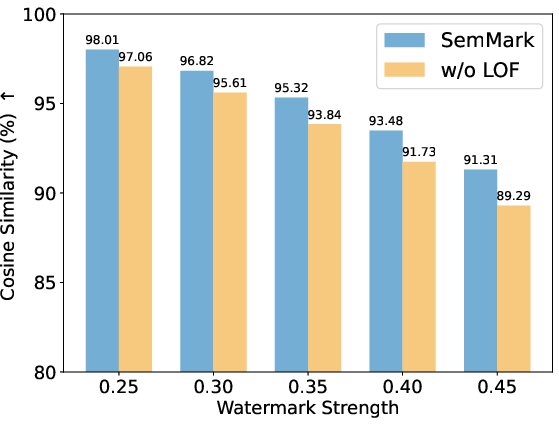
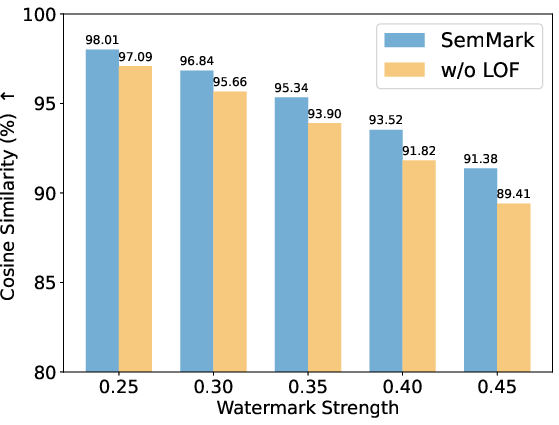
Figure 6: Cosine similarity analysis between SemMark watermarks and originals, indicating extremely high semantic preservation.
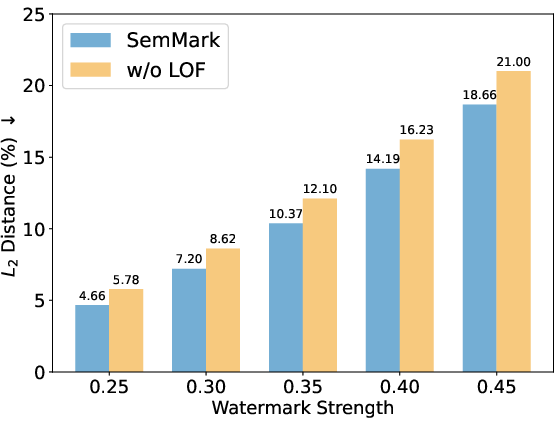
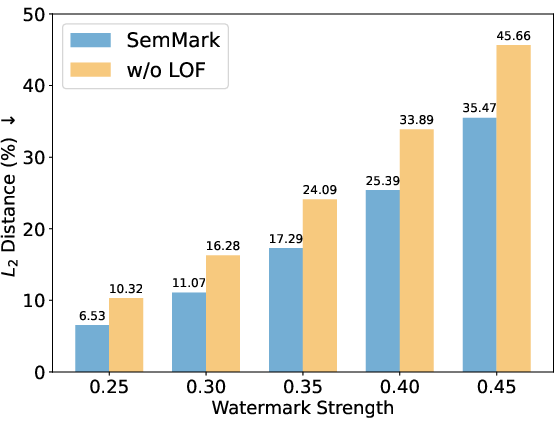
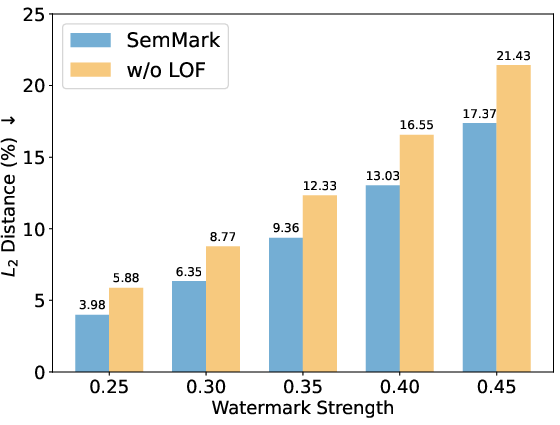
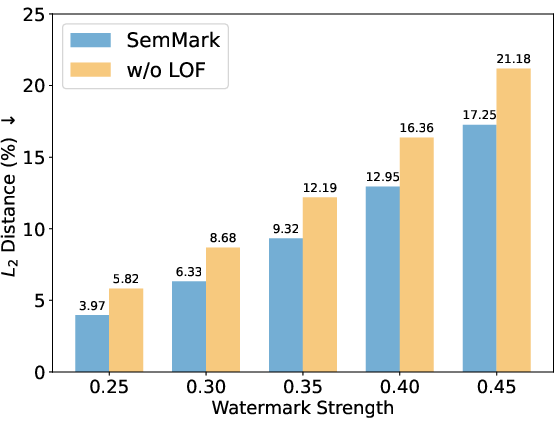
Figure 7: Square L2 distance analysis, showing minimal embedding perturbation due to adaptive weighting.
Computational Efficiency
Watermark injection constitutes less than 1–6% of total encoding time (mean ∼0.0005s per sample). Scalability is demonstrated across multiple high-dimensional embedding platforms, showing negligible additional cost, which renders the method suitable for production settings.
Implications and Future Directions
SemMark’s paradigm leverages intrinsic semantic structure—partitioning by LSH and region-specific mapping—to achieve highly adaptive, stealthy, and task-preserving watermarking. The avoidance of triggers and global transformations means watermarks cannot be removed via simple clustering, filtering, paraphrasing, or dimension manipulation. This approach opens substantial opportunities for copyright protection in commercial EaaS deployments, with implications for secure model hosting, ownership verification in adversarial environments, and forensic identification of stolen models.
Potential future work includes extending semantic-aware watermarking to multimodal embedding spaces (vision-language), broader attack resilience studies (e.g., continuous adversarial adaptation), and further refinement of region selection using dynamic semantic graphs. The paradigm also offers a template for watermarking in other foundation model APIs where outputs serve downstream services without user awareness.
Conclusion
"From Essence to Defense: Adaptive Semantic-aware Watermarking for Embedding-as-a-Service Copyright Protection" (2512.16439) presents a significant shift toward region-specific, semantic-aligned watermarking for embedding copyright protection. The combination of adaptive signal mapping and stealth verification provides robust resistance to state-of-the-art attacks while preserving downstream embedding utility and computational viability. This work represents an important advancement in practical IP protection for deployed LLM services, offering broad applicability and strong resilience characteristics.